










本帖子这是本人在刷算法题的一些小抄,避免忘记!
从Leetcode截图来的题目类型标签。

1.排序类
排序类的算法是比较经典的考察内容,也是比较核心的考察内容,主要有快排,归并,堆排,基数排序这几种,基于这几种衍生出的题目可谓是千变万化。
1.1快排
快速排序是面试喜欢常考的题目之一,不仅对快排的理解,还考察对考生的编码能力。快排的核心方法就是parttion()方法,平均时间复杂度为O(n * logn)。
根绝parttion()方法的的思想可以除很多变种题目。
1.正确的完成快速排序代码,快排的核心就是parttion(left , right int)int方法,要熟记参数与返回值以及内部写法,还有partition和quickSort(left , right int)void方法怎么串起来。
2.无序数组的第k大的值,parttion()每次可以定位一个值到最终的位置上,根据最终位置和k进行比较,左移还是右移,parttion()+二分就能在底时间复杂度找出目标值。
3.数组正负数前后分离,也可以采用类似partition的思想,设置一个标志位,表示正数的起点,遍历数组,当为正数则不处理,当为负数,则当前位置和标志位进行交换元素值,标志位加加。
public class Main {
public static void main(String[] args) {
int []nums = new int[]{1,3,5,7,9,10,2,4,6,8};
quickSort(nums,0,nums.length-1);
System.out.println(Arrays.toString(nums));
}
public static void quickSort(int []nums , int left , int right){
if (left >= right)return;
int mid = partition(nums , left , right);
quickSort(nums,left,mid-1);
quickSort(nums,mid+1,right);
}
public static int partition(int []nums , int left , int right) {
int flag = left;
int index = left+1;
for (int i = index ; i <= right ; i++){
if(nums[flag] > nums[i]){
swap(nums,index,i);
index ++;
}
}
swap(nums,flag , index - 1);
return index - 1;
}
private static void swap(int[] nums, int i, int j) {
int tep = nums[i];
nums[i] = nums[j];
nums[j] = tep;
}
}1.2堆排
堆排序也是面试黄金出题点,首先考察考生对堆数据结构的理解,然后考察考生能否快速正确的写出堆排序。大根堆指的是根节点都比子节点大,而小根堆则是根节点都比子节点小,只能确定一个最值,取出了最值之后,需要调整堆,然后得到下一个最值。
常见题型和变种题。
1.正确写出堆排,堆排序,可以采用数组的方式去模拟根节点和左右子节点,注意up和down的写法,能正确快速的写出来。堆排的写法步骤:先进行堆的初始化,对数组的折半向上进行down操作,每次取出最值,放到数组的末尾,数组的长度进行减一,然后从0的位置进行down操作,直到所有的数完成排序。
2.无序数组求第k大的数,思想每次求的是最值,可以逐步到第k大就能求出来。
3.优先队列,根据堆排序实现一个优先队列,优先队列有push和pop操作,pop出来的是最值,思想是根据堆排序去处理,push的时候从添加到数组的末尾,然后对末尾进行up操作,删除的时候,现将最值(首位)和末尾进行交换,记录最值,然后删除末尾,然后对首位进行down操作,最后返回最值。
// 堆排序
public class Main {
public static void main(String[] args) {
int []nums = new int[]{1,3,5,7,9,10,2,4,6,8};
heapSort(nums);
System.out.println(Arrays.toString(nums));
}
public static void heapSort(int []nums){
int len = nums.length;
initHeap(nums,len);
int index = len -1;
for (int i = 0 ; i < len ; i++){
swap(nums, 0 ,index);
heapfying(nums , 0 , index);
index --;
}
}
private static void initHeap(int[] nums, int len) {
for (int i = len / 2 -1 ; i >= 0 ; i--){
heapfying(nums, i , len);
}
}
private static void heapfying(int[] nums, int i, int len) {
int left = 2 * i + 1;
int right = 2 * i + 2;
int max_index = i;
if(left < len && nums[max_index] < nums[left]){
max_index = left;
}
if(right < len && nums[max_index] < nums[right]){
max_index = right;
}
if(max_index != i){
swap(nums,max_index,i);
heapfying(nums,max_index,len);
}
}
private static void swap(int[] nums, int i, int j) {
int tep = nums[i];
nums[i] = nums[j];
nums[j] = tep;
}
}// 上升与下降
private static void swap(int[] nums, int i, int j) {
int tep = nums[i];
nums[i] = nums[j];
nums[j] = tep;
}
private static void up(int []nums , int index ){
int farther = (index - 1 ) / 2 ;
if (farther >= 0 && nums[index] < nums[farther]){
swap(nums , index , farther );
up(nums , farther);
}
}
private static void down(int []nums , int index){
int left = index * 2 + 1;
int right = index *2 + 2;
int max_index = index;
if (left < nums.length && nums[max_index] < nums[left]){
max_index = left;
}
if (right < nums.length && nums[max_index] < nums[right]){
max_index = right;
}
if (max_index != index){
swap(nums , max_index , index);
down(nums , max_index);
}
}1.3归并排序
归并排序虽然写起来不难,但是出题点应该是最多的一个了,很多问题的变种,如果要优化时间复杂度,就必须采用归并的思想。
常见题型和变种题。
1.实现归并排序,将数组进行拆分,递归的的认为两部分有序之后,在将两个有序的部分进行合并起来。注意方法的参数mergeSort(int left , right , int [] nums),sort(int left, mid , right , int [] nums)将两个有序数组进行合并。
2.n个有序链表变成一个链表,采用归并排序。注意mergeSort(ListNode [] lists)的写法.
mergetSort := func(ListNode [] nums)ListNode{ if (len(nums) == 0){ return nil } if (len(nums) == 1){ return nums[0] } if (len(nums)== 2){ return sort(nums[0] , nums[1]) } return sort(mergetSort(nums[:len(nums)]) , mergetSort(nums[len(nums):])) }3.一个链表的排序,采用归并对链表排序,链表的排序和对数组的排序非常相似,但是要找到中点,然后进行分割是容易出错的。
4.逆序数,在进行两个有序数组进行合并的时候可以计算出逆序的个数。

import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int []nums = new int[]{1,3,5,7,9,10,2,4,6,8};
mergeSort(nums , 0 , nums.length-1);
System.out.println(Arrays.toString(nums));
// sort(new int []{1,3,2,4}, 0 , 1 , 3);
}
public static void mergeSort(int []nums , int left , int right){
if (left >= right)return;
int mid = left + (right - left) / 2;
mergeSort(nums , left , mid);
mergeSort(nums , mid+1 , right);
sort(nums , left , mid , right);
}
public static void sort(int[] nums, int left , int mid , int right) {
int tep [] = new int[right - left + 1];
int i = left ;
int j = mid + 1;
int index = 0;
while(i <= mid && j <= right){
if(nums[i] > nums[j]){
tep [index] = nums[j];
j ++;
index ++;
}else{
tep [index] = nums[i];
i ++;
index ++;
}
}
while(i <= mid ){
tep [index] = nums[i];
i ++;
index ++;
}
while(j <= right){
tep [index] = nums[j];
j ++;
index ++;
}
index = 0;
for (i = left ; i <= right; i++){
nums[i] = tep[index++];
}
}
}1.4 基数排序
基数排序是一个很不起眼的排序算法,时间复杂度为o(n),空间复杂度也为o(n),虽然不起眼,但是非常重要。基数排序的思想,是按照位进行排序的,先从最低位在到最高位位置进行排序,注意写法,写法思想也涵盖了计数排序。例题:力扣,如果涉及到要排序的数组中包含负数,可以将所有元素加一个变大的偏移量,将所有的数变成正数。
// 只适合正数
public static void radixSort(int []nums){
int n = nums.length;
int tep[] = new int[n];
int count [] = new int[10];
int max = 0;
for (int i = 0 ; i < nums.length; i++){
max = Math.max(max , nums[i]);
}
for (int radix = 1 ; radix <= max; radix *= 10){
for (int i = 0 ; i < nums.length; i++){
count[nums[i] / radix % 10] ++;
}
// 注意点一:这里存在一个累加和
for (int i = 1; i < 10; i++){
count[i] += count[i-1];
}
// 注意点二:从后往前进行遍历,可以保证稳定
for (int i = nums.length - 1; i >= 0; i--){
int index = nums[i] / radix % 10;
tep[--count[index]] = nums[i];
}
System.arraycopy(tep , 0 , nums , 0 , nums.length);
Arrays.fill(count , 0);
}
}1.5 桶排序
桶排序的核心思想是将满足条件的一组数放到同一个桶中,桶的数量和桶的条件可以前边万化。 例题:220. 存在重复元素 III
此处运用了桶排序的思想,题目描述:数组中是否存在abs(i-j)<=k,且abs(nums[i]-nums[j])<=t,如果采用暴力的方法则超时,换种思路,将满足abs(nums[i]-nums[j])<=t条件的放到同一个桶中,且桶存储数组的下标,且相邻的两个桶之间可能存在满足条件的一对值。桶的个数为t+1个。
func getID(x, w int) int { // 获取桶的编号
if x >= 0 {
return x / w
}
return (x+1)/w - 1 // 负数获取桶的编号,因为需要从0开始算,且上面包含了0这种情况,所以先加1后减1
}2.遍历类
遍历类,主要有深度优先遍历和广度优先遍历两个经典的算法,在很多涉及到枚举、暴力的场合都比较适用,在使用两种方法的时候,如何做到剪枝减少时间复杂度是非常重要的,还有一些特殊的场景下面,如何去做枚举去重。还有在特殊情况下面去,双向dfs和双向bfs能降低非常大的时间复杂度。
2.1深度遍历DFS
深度优先遍历是一种思想,拿树来说的话,它就像先序遍历一样。在实际的面试当中,dfs出现的频率非常高,典型的是树的操作、排列组合、岛屿问题等。
常见题型和变种题。
1.排列组合问题,基本的排列组合问题用常见的dfs写法就能满足要求,但是一些特殊条件下面,比如要枚举的数组中有重复的元素,如何去重呢?:比如有一个包含重复的数组,求全排列的可能种数,这种题目就涉及到了去重,深度优先遍历的时候是对每个index的时候进行枚举,可以先对数组进行排序,然后枚举index位置的时候,此轮不能取重复的一个数if(i > 0 &&dp[i] != dp[i-1]),表示为index = 0的时候,值可以取1,但是下一个同一轮的时候,index对应位置的值就不能取1了。
2.经典的还有岛屿问题,最大岛屿,多少个岛屿都可以通过dfs来做。
3.树的遍历。
4.双向dfs,主要原因需要遍历的集合太大了,会超时,如果采用双向dfs的话,可以降低一半的时间复杂度,先处理一半的集合,将处理结果记录好,然后在处理后一半的集合并得出结果。例题:leecode:力扣,将2n长度的数组,分为两个大小为n的数组,使得两数组相差最少。如果数据集不大的话,可以直接用dfs枚举,但是此题数据集大小为30,可以采用双向dfs来做。思想:对前n个数进行dfs遍历,分别取正和取负数,然后添加到map[int][]int的map对象中,key是取正数的个数,value是表示前n个数取key个整数的值的集合。遍历完之后对map的val进行升序。然后对后n个数同样进行dfs,递归出后时候,后n个数和前n个数要满足取得正数之后为n,使得两数相加为最小,此处可以采用后n个取得之后的-cur,到前n个取得的list中进行二分查找,找出一个使得加上cur最小的数。
public void dfs(){
// 1.递归出口
// 2.访问
// 3.dfs()//继续递归下去
}2.2广度遍历BFS
广度优先遍历,也是常考的算法之一,让人联想到了数的层次遍历,其实拓扑排序也算是广度遍历的一种,广度遍历的考察也是及其广泛的。
常见题型和变种题。
1.数的层次遍历、
2.变种题目:解密码。
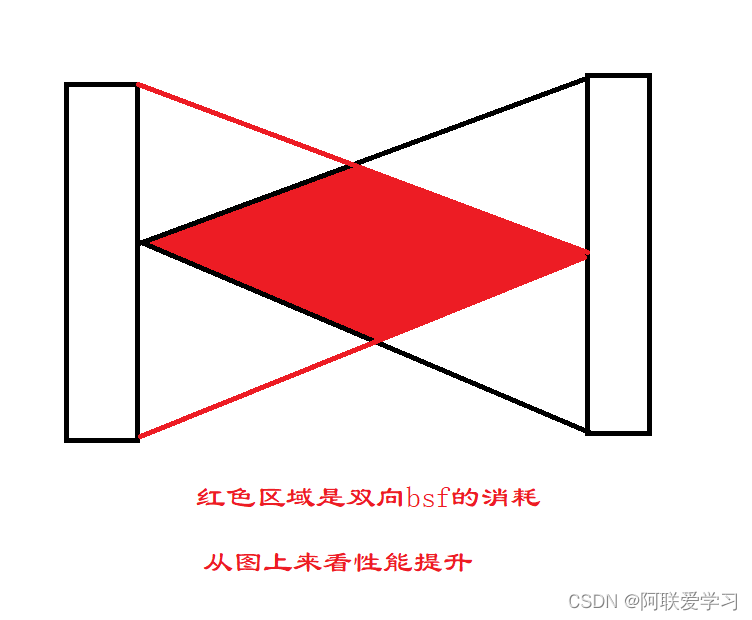
3.双向bfs,双向bfs不是真正的两边同时使用bfs,实际上只有一个bfs,只不过bfs的时候可以选择从开头出发,也可以选择从末尾出发,每次选择的是集合小的一方出发,能够极大的降低时间复杂度。
4.多源点bfs,普通的bfs只有一个源点先进队列,而图的bfs需要将多个源点放入队列,然后进行广度扩展。
public static void bfs(){
LinkedList<> que = new LinkedList();
que.add(root)
while (!que.isEmpty()){
int size = que.size();
for (int i = 0 ; i < size ; i++){
int cv = que.getFirst();
que.removeFirst();
// 将cv的子节点加入que
}
}
}3.搜索类
3.1 二分类
二分方法作为降低时间复杂度常用的方法之一,一般涉及到数组查找提升性能,就能使用二分法,二分法一定要要求数组有序,在特殊的问题的时候,不需要有序。还有二分的变种,求二分求左边界和二分求有边界的情况。
3.1.1 二分搜索
二分搜索可以灵活使用在答案成线性分布的情况,可以用来逼近答案,类似于求数的平方根,逐渐逼近答案,还适用非线性的场合下面。
public static int binarySearch(int []nums , int target){
int left = 0;
int right = nums.length -1;
while (left <= right){
int mid = left + (right - left) / 2;
if(target == nums[mid]){
return mid;
}else if (target > nums[mid]){
left = mid + 1;
}else if (target < nums[mid]){
right = mid - 1;
}
}
return -1;
}3.1.2 leftBound
注意写法,在题目中一般出现为最多、对少的字样可以考虑这种方法。
public static int leftBound(int []nums , int target){
int left = 0;
int right = nums.length -1;
while (left <= right){
int mid = left + (right - left) / 2;
if(target == nums[mid]){
right = mid - 1;
}else if (target > nums[mid]){
left = mid + 1;
}else if (target < nums[mid]){
right = mid - 1;
}
}
if (left >= nums.length || nums[left] != target){
return -1;
}
return left;
}3.1.3 rightBound
与leftBound相对应的。
public static int rightBound(int []nums , int target){
int left = 0;
int right = nums.length -1;
while (left <= right){
int mid = left + (right - left) / 2;
if(target == nums[mid]){
left = mid + 1;
}else if (target > nums[mid]){
left = mid + 1;
}else if (target < nums[mid]){
right = mid - 1;
}
}
if (right < 0 || nums[right] != target){
return -1;
}
return right;
}3.2 图类
3.2.1dijkstra算法
dijkstra算法不适用于边值为负的情况。
迪杰斯特拉算法主要特点是从起始点开始,采用贪心算法的策略,每次遍历到始点距离最近且未访问过的顶点的邻接节点,直到扩展到终点为止。

public class Main {
public static void main(String[] args) {
int [][] distance = new int[][]{{1,2,3},{2,3,1},{0,4,3},{2,4,4},{1,4,6}};
System.out.println(dijkstra(distance, 5, 1, 4));
}
/*
* 单源最短距离-dijkstra算法
* int[][] distance距离
* int n总结点数
* int src源点
* int dest目标点
*
* */
public static int dijkstra(int[][] distance, int n, int src, int dest) {
int []costs = new int[n];
boolean []visited = new boolean[n];
final int INF = 1000*1000+1;
Arrays.fill(costs,INF);
costs[src] = 0;
for (int []cv : distance){
int i = cv[0];
int j = cv[1];
int cost = cv[2];
if (i == src){
costs[j] = cost;
}
}
visited[src] = true;
for (int t = 1 ; t <= n - 1; t++){
int post = 0;
int min = Integer.MAX_VALUE;
for (int k = 0 ; k < n; k++){
if(!visited [k] && min > costs[k]){
min = costs[k];
post = k;
}
}
visited[post] = true;
for (int []cv : distance){
int i = cv[0];
int j = cv[1];
int cost = cv[2];
if (post == i && !visited[j] && costs[j] > costs[i] + cost){
costs[j] = costs[i] + cost;
}
}
}
return costs[dest] == INF ? -1 : costs[dest];
}
}3.2.2bellman ford算法
bellman ford算法也是一种单源最短路径算法,可以始于权值为负数的情况,可以适用于限定步数的最短路径,可以限定松弛的次数,原本的cost的数组表示松弛了一次。
public class Main {
public static void main(String[] args) {
int [][] distance = new int[][]{{1,2,3},{2,3,1},{0,4,3},{2,4,2},{1,4,6}};
System.out.println(bellmanFord(distance, 5, 1, 4));
}
/*
* 单源最短距离-bellman ford算法
* int[][] distance距离
* int n总结点数
* int src源点
* int dest目标点
*
* */
public static int bellmanFord(int[][] distance, int n, int src, int dest) {
int []costs = new int[n];
final int INF = 1000*1000+1;
Arrays.fill(costs,INF);
costs[src] = 0;
for (int t = 1 ; t <= n - 1; t++){ // 进行松弛计算
boolean flag = true;
for (int []cv : distance){
int i = cv[0];
int j = cv[1];
int cost = cv[2];
if (costs[j] > costs[i] + cost){
costs[j] = costs[i] + cost;
flag = false;
}
}
if (flag){
return costs[dest] == INF ? -1 : costs[dest];
}
}
for (int []cv : distance){ // 若经过n-1还没松弛完则代表有回路
int i = cv[0];
int j = cv[1];
int cost = cv[2];
if (costs[j] > costs[i] + cost){
return -1;
}
}
return costs[dest] == INF ? -1 : costs[dest];
}
}3.2.3克鲁斯卡尔
需求:是构造最小生成树,思想:将长度进行排序,在根据查并集的思想,慢慢将所有的节点都加进来。
class Solution {
public int minCostConnectPoints(int[][] points) {
int totalCost = 0;
PriorityQueue<int[]> pq = new PriorityQueue<int[]>((a, b) -> a[2] - b[2]);
int n = points.length;
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
int cost = Math.abs(points[i][0] - points[j][0]) + Math.abs(points[i][1] - points[j][1]);
pq.offer(new int[]{i, j, cost});
}
}
UnionFind uf = new UnionFind(n);
while (uf.getCount() > 1) {
int[] edge = pq.poll();
int point0 = edge[0], point1 = edge[1], cost = edge[2];
if (uf.find(point0) != uf.find(point1)) {
totalCost += cost;
uf.union(point0, point1);
}
}
return totalCost;
}
}
class UnionFind {
private int[] parent;
private int[] rank;
private int count;
public UnionFind(int n) {
parent = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
}
rank = new int[n];
this.count = n;
}
public void union(int x, int y) {
int rootx = find(x);
int rooty = find(y);
if (rootx != rooty) {
if (rank[rootx] > rank[rooty]) {
parent[rooty] = rootx;
} else if (rank[rootx] < rank[rooty]) {
parent[rootx] = rooty;
} else {
parent[rooty] = rootx;
rank[rootx]++;
}
count--;
}
}
public int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]);
}
return parent[x];
}
public int getCount() {
return count;
}
}3.2.4 多源最短路径Floyd算法
多源头Floyd最短路径算法包含动态规划的思想。
public class floyd {
static int max = 66666;// 别Intege.max 两个相加越界为负
public static void main(String[] args) {
int dist[][] = {
{ 0, 2, 3, 6, max, max },
{ 2, 0, max, max,4, 6 },
{ 3, max, 0, 2, max, max },
{ 6, max, 2, 0, 1, 3 },
{ max, 4, max, 1, 0, max },
{ max, 6, max, 3, max, 0 } };// 地图
// 6个
for (int k = 0; k < 6; k++)// 加入滴k个节点
{
for (int i = 0; i < 6; i++)// 松弛I行
{
for (int j = 0; j < 6; j++)// 松弛i列
{
dist[i][j] = Math.min(dist[i][j], dist[i][k] + dist[k][j]);
}
}
}
// 输出
for (int i = 0; i < 6; i++) {
System.out.print("节点"+(i+1)+" 的最短路径");
for (int j = 0; j < 6; j++) {
System.out.print(dist[i][j]+" ");
}
System.out.println();
}
}
}
3.2.5拓扑排序
拓扑排序是一个经典的判断环的算法,主要步骤:计算出节点的入度,每次遍历入度为0的结点,并且将该节点的下一个节点的入度减一,直到所有的结点都已经访问到。
3.2.6欧拉回路
欧拉回路问题是将所有路径全部走一遍,形成一个回路。欧拉回路是典型的一笔画的算法,确定起点了之后,向前走一步会放到最后,中间的步数会放到dfs深度遍历中去完成。如下图所示:在题一和题三,先确定了起点,然后选出了下一条边,并且同时去收缩下一跳的集合,直到所有的都遍历完。
例题:力扣
代码的写法 func (){ for (i := range next){ 下一个节点没访问过 dfs()//继续访问 //加到一个栈中 , 最后结果的话,需要将栈进行逆序输出 }

4.技巧类
4.1大数类
在算法题中,大数会以两种方式存在,第一种,数字的累乘或者平方,且对一个目标值取余,这种情况可能会溢出。第二种,就是64位整型无法存储大数,必须要用字符串来存储,那么这些大数的相乘操作也是一个考点!
4.1.1快速幂
快速幂是指求a和b的幂的值,并且对一个上限进行取余,如果直接取幂的话则会溢出,必须分步求之。可以将b拆分为2进行,并且在循环的过程中对a进行倍乘放大,在循环过程中对结果取余。(注意和大树乘的区别)
public static int quickPow(int a , int b){
final int INF = 1000000+1; // 超过范围对res取余
int res = 1;
a = a % INF;
while (b != 0){
if ((b & 1) == 1){
res = res * a;
res %= INF;
}
b = b >> 1;
a = a * a;
a = a %INF;
}
return res;
}4.1.2快速乘
快速乘和快速幂的场景是一样的,在循环的时候有点区别。
public static int bigNumberMultiply(int a , int b){
final int INF = 1000000+1; // 超过范围对res取余
int res = 0;
int tep = a;
while (b != 0){
if ((b & 1) == 1){
res += tep;
res %= INF;
}
b = b >> 1;
tep = tep * a;
}
return res;
}4.1.3 大数相乘
这里是两个字符串进行相乘,求结果,这也是常考的类型之一。这里采用的思想是将问题进行分解,两个大数相乘可以分解为一个数字与另一个大数相乘和两个大树相加。
// 字符串和数字相乘
String StringMultiplyByNumber(String s , int number){
}
// 两个字符串相加
String twoStringAdd(String s1 , String s2){
}
// 模拟操作
String twoStringMultiply(String s1 , String s2){
String res = "";
for (int i = 0 ; i < s2.length(); i++){
String cv = StringMultiplyByNumber(s1 , s2.charAt(i));
// cv后面得补i个零
for (int j = 0 ; j < i ; j++){
cv = cv + "0";
}
res = twoStringAdd(cv , res);
}
return res;
}4.1.4大数相除
大数指的是用字符串或者数组表示的数字,那么超级大的两个数相除的结果如何去求呢,其实这可以可以将除法转换成减法(翻倍的减法,10倍或者百倍),然后去计算相减。
4.1.5 中文大数
还有一种的大数类型,就是字符串和数字之间的转换,其核心点就是在于对万的处理上面,可以对万进行分割,然后分别对千位进行转换,最后就是添加一些特别的条件,比如亿的单位等等。
s := "八十万亿九千七百四五十万三千二百十三"
numberDict := map[string]int64{"一": 1, "二": 2, "三": 3, "四": 4, "五": 5, "六": 6, "七": 7, "八": 8, "九": 9, "零": 0}
unitDict := map[string]int64{"千": 1000, "百": 100, "十": 10}
cn2digit := func(s string) (bool, int64) {
if len(s) == 0 {
return false, 0
}
flag := false
var res, cv int64
for _, val := range s {
if v, e := numberDict[string(val)]; e {
cv = v
} else if v, e := unitDict[string(val)]; e {
if cv == 0 {
cv = v
} else {
cv = cv * v
}
res += cv
cv = 0
} else if string(val) == "亿" {
flag = true
}
}
return flag, res + cv
}
nums := strings.Split(s, "万")
var res int64
for i := 0; i < len(nums); i++ {
f, v := cn2digit(nums[i])
res = res * 10000
if f {
res = res * 1000000000
}
res = res + v
}
fmt.Println(res)4.2 质数类
4.2.1 质数分布规律
质数分布规律可以快速判断一个数是否为质数,大于等于5的质数分布在6的倍数左右,但是六的倍数左右不一定是质数。
public static boolean isPrime(int n){
if (n == 2 || n == 3 || n == 5)return true;
if (n == 4 || n == 1)return false;
if (n % 6 != 5 && n % 6 != 1)return false;
for (int i = 5 ; i <= Math.sqrt(n) ; i += 6){
if (n % i == 0 || n % n + 2 == 0){
return false;
}
}
return true;
}4.2.2 求质数的方法
常见的求质数的方法,有直接暴力判断,或者通过质数的倍数是合数进行筛选排除。
4.3概率类
概率类的算法主要是通过随机数变形的一些考察。
4.3.1水塘抽样法
水塘抽样可以应对变化的范围,取出随机值。
public static int waterPool(int n){
Random r =new Random();
int res = 0;
for (int i = 1 ; i <= n; i++ ){
if (r.nextInt(i) == 0){
res = i;
}
}
return res;
}4.3.2彩票调度算法
彩票调度算法是一个带有权值比重的随机算法,权值比重越高取到的概率则越大。
public static int lotteryTicket(int []nums){
int sum = 0;
for (int i : nums){
sum += i;
}
int target = new Random().nextInt(sum);
int cur = 0;
for (int i = 0 ; i < nums.length; i++){
cur += nums[i];
if (cur - 1 >= target){
return i;
}
}
return 0;
}
public static void main(String[] args) {
int []nums = new int[]{1,2,3};
int zero = 0;
int one = 0;
int two = 0;
for (int i = 0 ; i < 100; i++){
int flag = lotteryTicket(nums);
switch (flag){
case 0 : zero++;break;
case 1: one++;break;
case 2:two++;break;
default: break;
}
}
System.out.println(zero + ":" + one + ":" + two);
}
4.3.3已知rand7求rand10
这里需要一个转换,已知一个randn的随机函数,求randm,公式为:n * (randn - 1)+ randn 。根据公式对m取余进行。

public static int rand10(){
Random r = new Random();
int res = 7 * (r.nextInt(7)- 1) + (r.nextInt(7));
while(res >41){
res = 7 * (r.nextInt(7)- 1) + (r.nextInt(7));
}
return res % 10 == 0?10:res % 10;
}4.4数学类
4.4.1牛顿迭代法开平方
记住迭代公式:x1 = (x0 + n / x0) / 2;
public static double newTon(int n){
double x0 = n / 2;
double x1 = (x0 + n / x0) / 2;
while (Math.abs( x1 - x0 ) > 0.000001){ // 两个数子靠的非常接近的时候就是目标
x0 = x1;
x1 = (x0 + n / x0) / 2;
}
return x1;
}4.4.2计算圆周率
蒙特卡洛算法,一个方形,边长为2r,里面有一个直径为2r的圆,其面积之比为4/派,可以采用随机数,生成x,y,若x*x+y*y<1则表示在圆内,否则在圆外,通过比值等于4/派可以近似求出派,随机数的次数越大,则越精确!与此题思想一样的,还有给出x,y坐标,和半径,随机给出落在圆内部的点:解题思路是先存在(-1,1)的随机函数,然后只要随机数x、y满足x * x * y * y < 1则表示。

public static double pai(int n){
Random r = new Random();
double hit= 0;
for (int i = 1 ; i <= n ; i++){
double x , y ;
x = r.nextDouble();
y = r.nextDouble();
if (x * x + y * y < 1){
hit++;
}
}
return 4 * (hit) / n;
}4.4.3计算润年
四年一润,百年不润,四百年一润
4.4.4 博弈思想
n个石子,两个人取,每次可以取1-m个石子,谁取到最后一个石子就赢得比赛,取的局面为(m+1)的时候必输,且为(m+1)的倍数时候也必输。
例如:10个石头,m = 3 , 可以先取2个,剩余8个,队首无论怎么去必输。
4.5 工具类
4.5.1 查并集
查并集是一个非常好的工具类,涉及到一些集合的并集的时候可以考虑到查并集,在最少生成树的时候,也可以用查并集来做,按照线段的路径大小进行排序,先连接小的在连接大的。注意写法,findRoot()、connect()、isConnect().
import java.util.Random;
class unionFind{
int count; // 连通分量的个数
int parent[]; //指向父节点
int []size; // 节点重量
public unionFind (int n){
size = new int[n];
parent = new int[n];
for (int i = 0 ; i < n ; i++){
size[i] = 1;
parent[i] = i;
}
count = n;
}
public void union(int p , int q){
int r1 = findRoot(p);
int r2 = findRoot(q);
if (r1 == r2)return;
if (size[r1] > size[r2]){
parent[r2] = r1;
size[r1] += size[r2];
}else{
parent[r1] = r2;
size[r2] += size[r1];
}
count --;
}
public boolean isConnect(int p , int q){
return findRoot(p) == findRoot(q);
}
public int findRoot(int p){
int res = parent[p];
while (res!=parent[res]){
res = parent[res];
}
return res;
}
public int getCount(){
return count;
}
}4.5.2 树状数组
树状数组,一种二进制数组,单点修改区间求和的操作比较高效,也可以处理一些特殊的问题,比如逆序数等。树状数组有几个关键的函数需要特别记忆,lowbit(),query(),update()三个方法。还有二维树状数组,可以快速的求出(x,y)到(1,1)的矩阵和。
func lowbit(x int)int {
return x & (-x)
}
func (this *TwoBinaryTree)add (x , y int , val int){
for i := x ; i <= this.m; i += lowbit(i){
for j := y ; j <= this.n; j += lowbit(j){
this.c[i][j] += val
}
}
}
func (this *TwoBinaryTree)query(x , y int)int {
res := 0
for i := x; i > 0 ; i -= lowbit(i){
for j := y ; j > 0; j-=lowbit(j){
res += this.c[i][j]
}
}
return res
}4.5.3 线段树
线段树适合于数组的单点修改或者批量修改,求区间和或者求区间最值。核心写法:build、update、以及query的写法。
单点修改,求区间和
// 单点修改,区间求和
package alian;
public class Main {
public static void main(String[] args) {
int [] nums = new int[]{2,4,1,5};
SegementTree segementTree = new SegementTree(nums);
System.out.print(segementTree.query(0 , 0 , 1) + " ");
System.out.print(segementTree.query(0 , 1 , 2)+ " ");
System.out.print(segementTree.query(0 , 0 , 3)+ " ");
System.out.print(segementTree.query(0 , 2 , 3)+ " ");
System.out.print(segementTree.query(0 , 2 , 2)+ " ");
System.out.println();
segementTree.update(0 , 1 , 10);
System.out.print(segementTree.query(0 , 0 , 1) + " ");
System.out.print(segementTree.query(0 , 1 , 2)+ " ");
System.out.print(segementTree.query(0 , 0 , 3)+ " ");
System.out.print(segementTree.query(0 , 2 , 3)+ " ");
System.out.print(segementTree.query(0 , 2 , 2)+ " ");
}
}
class Node {
int left;
int right;
int value;
}
class SegementTree {
Node[] tree = null;
int []nums = null;
public SegementTree(int nums[]){
this.nums = nums;
tree = new Node[4 * nums.length];
for (int i = 0 ; i < 4 * nums.length; i++){
tree[i] = new Node();
}
//初始化线段树
build(0 , 0 , nums.length - 1);
}
// 初始化,从根节点开始找
public void build(int pos , int left , int right){
tree[pos].left = left;
tree[pos].right = right;
if (left == right){
tree[pos].value = nums[left];
return;
}
int mid = left + (right - left) / 2;
build(2 * pos + 1, left , mid);
build(2 * pos + 2, mid + 1, right);
tree[pos].value = tree[2*pos + 1].value + tree[2*pos + 2].value;
}
// 从根节点开始找
public void update(int pos , int index , int val){
if (tree[pos].left == tree[pos].right && tree[pos].left == index){
tree[pos].value = val;
return;
}
int mid = tree[pos].left + (tree[pos].right - tree[pos].left) / 2;
if (index <= mid){
update(pos * 2 + 1 , index , val);
}else {
update(pos * 2 + 2 , index , val);
}
// 更新当前节点的区间的和
tree[pos].value = tree[pos * 2 + 1].value + tree[pos * 2 +2].value;
}
// 区间查询,表示查询left-right的区间值,一般从根节点开始查
public int query(int pos , int left , int right){
if (tree[pos].left >= left && tree[pos].right <= right){
return tree[pos].value;
}
int mid = tree[pos].left + (tree[pos].right - tree[pos].left) / 2;
int res = 0;
if (left <= mid){
res += query(2 * pos + 1 , left , right);
}
if (right > mid) {
res += query(2 * pos + 2 , left , right);
}
return res;
}
}

单点修改,求区间最值
// 单点修改,求区间最值
package alian;
public class Main {
public static void main(String[] args) {
int [] nums = new int[]{2,4,1,5};
SegementTree segementTree = new SegementTree(nums);
System.out.print(segementTree.query(0 , 0 , 1) + " ");
System.out.print(segementTree.query(0 , 1 , 2)+ " ");
System.out.print(segementTree.query(0 , 0 , 3)+ " ");
System.out.print(segementTree.query(0 , 2 , 3)+ " ");
System.out.print(segementTree.query(0 , 2 , 2)+ " ");
System.out.println();
segementTree.update(0 , 1 , 10);
System.out.print(segementTree.query(0 , 0 , 1) + " ");
System.out.print(segementTree.query(0 , 1 , 2)+ " ");
System.out.print(segementTree.query(0 , 0 , 3)+ " ");
System.out.print(segementTree.query(0 , 2 , 3)+ " ");
System.out.print(segementTree.query(0 , 2 , 2)+ " ");
}
}
class Node {
int left;
int right;
int value;
}
class SegementTree {
Node[] tree = null;
int []nums = null;
public SegementTree(int nums[]){
this.nums = nums;
tree = new Node[4 * nums.length];
for (int i = 0 ; i < 4 * nums.length; i++){
tree[i] = new Node();
}
//初始化线段树
build(0 , 0 , nums.length - 1);
}
// 初始化,从根节点开始找
public void build(int pos , int left , int right){
tree[pos].left = left;
tree[pos].right = right;
if (left == right){
tree[pos].value = nums[left];
return;
}
int mid = left + (right - left) / 2;
build(2 * pos + 1, left , mid);
build(2 * pos + 2, mid + 1, right);
tree[pos].value = Integer.max(tree[2*pos + 1].value , tree[2*pos + 2].value);
}
// 从根节点开始找
public void update(int pos , int index , int val){
if (tree[pos].left == tree[pos].right && tree[pos].left == index){
tree[pos].value = val;
return;
}
int mid = tree[pos].left + (tree[pos].right - tree[pos].left) / 2;
if (index <= mid){
update(pos * 2 + 1 , index , val);
}else {
update(pos * 2 + 2 , index , val);
}
// 更新当前节点的区间的和
tree[pos].value =Integer.max(tree[pos * 2 + 1].value , tree[pos * 2 +2].value);
}
// 区间查询,表示查询left-right的区间值,一般从根节点开始查
public int query(int pos , int left , int right){
if (tree[pos].left >= left && tree[pos].right <= right){
return tree[pos].value;
}
int mid = tree[pos].left + (tree[pos].right - tree[pos].left) / 2;
int res = Integer.MIN_VALUE;
if (left <= mid){
res = Integer.max(res ,query(2 * pos + 1 , left , right));
}
if (right > mid) {
res = Integer.max(res , query(2 * pos + 2 , left , right));
}
return res;
}
}

区间修改,lazy标记,延迟更新。
class segmentTree {
int tree[]; // 从0下标开始
int lazy[];
int nums[];
int n;
public segmentTree(int [] nums){
this.n = nums.length;
this.nums = nums;
this.tree = new int[4 * n];
this.lazy = new int[4 * n];
build(0 , 0 , n - 1);
}
public void build(int pos , int left , int right){ // pos表示tree的下标,left和right表示,pos点对应的区间
if (left == right) {
tree[pos] = nums[left];
return;
}
int mid = left + (right - left) / 2;
build(pos * 2 + 1 , left , mid);
build(pos * 2 + 2 , mid + 1 , right);
tree[pos] = tree[2 * pos + 1] + tree[2 * pos +2];
}
public void pushDown (int pos , int left , int right){ // 将pos的lazy标记传递给 [l - r]区间 , 只传递一代
if (lazy[pos] == 0){
return;
}
int mid = left + (right - left) / 2;
tree[pos * 2 + 1] += (mid - left + 1) * lazy[pos]; // 将父节点的lazy标记下传
lazy[pos*2 + 1]+=lazy[pos]; // 标记也下传
tree[2*pos + 2]+=(right -mid - 1 + 1) * lazy[pos];//右儿子
lazy[2*pos + 2]+=lazy[pos];
lazy[pos]=0;
}
// 区间进行修改 pos 表示当前节点位置 , left , right 表示当前节点对应的左右下标
public void update(int pos , int left , int right , int x , int y , int val){
// 无交集
if(x>right||y<left)return;
// 包含
if(x<=left&&right<=y)
{
tree[pos]+=(right-left + 1)*val;//有(r-l+1)个数
lazy[pos]+=val;//标记我懒了
return;
}
int mid=(left+right)>>1;
pushDown(pos,left,right);//先传递父亲的标记
update(pos*2 +1,left,mid,x,y,val); // 更新左边
update(pos*2+2,mid+1,right,x,y,val); // 更新右边
tree[pos]=tree[pos*2 + 1]+tree[pos*2+2];
}
// x , y 表示查询区间
public int query(int pos , int left , int right , int x , int y ){
if(x>right||y<left)return 0;
if(x<=left&&right<=y)return tree[pos];
int mid=(left+right)>>1;
pushDown(pos,left,right);//先传递父亲的懒
return query(pos*2 + 1,left,mid,x,y)+query(pos*2+2,mid+1,right,x,y);
}
}4.5.4 差分数组
差分数组适合区间修改,单点求值的操作,对一个区间进行修改的时候,区间首位+1,区间末尾的后一位进行-1.
4.5.5 哈希
哈希是一个可以实现o(1)查询和存储的数据结构,用来存储临时变量可以减少很大的时间复杂度。比如:在树的题目中要求有多少竖直路径和等于target,则可以在遍历的时候记录前缀和聚能满足要求。
// 比较有名的字符串转哈希的算法
func BKDRHash(s string)int {
seed := 31 //31 131 1313 13131 131313 etc..
res := 0
for i := range s {
res += res * seed + int(s[i])
}
return res % math.MaxInt32
}根据上述的哈希算法可以快捷的比较两个字符串是否相等,可以极大的减少时间复杂度,例题所示:力扣
TreeMap
TreeMap底层用的是红黑树,可以找到比k小的数,还可以统计比k小的数。
public SortedMap<K,V> headMap(K toKey) { return headMap(toKey, false); } /** * @throws ClassCastException {@inheritDoc} * @throws NullPointerException if {@code fromKey} is null * and this map uses natural ordering, or its comparator * does not permit null keys * @throws IllegalArgumentException {@inheritDoc} */ public SortedMap<K,V> tailMap(K fromKey) { return tailMap(fromKey, true); } public Map.Entry<K,V> ceilingEntry(K key) { return exportEntry(getCeilingEntry(key)); } public K ceilingKey(K key) { return keyOrNull(getCeilingEntry(key)); } public K floorKey(K key) { return keyOrNull(getFloorEntry(key)); }
4.5.6动态规划
4.5.7 单调栈
单调栈问题难起来是非常难的,代码技巧性很强,比如最大的矩形和区间最小树*区间和的最大值。
4.5.8 贪心
4.5.9 欧几里得算法
最小公倍数,gcb方法,辗转相除法。
4.6.0 后缀数组
后缀数组适合求字符串相关的大杀器,sa[i]表示排名为i的后缀数组的起始下标,rk[i]表示以i开始的后缀数组的排名,height[i]表示排名第i和上一个排名最长共同前缀长度,其中有一个性质是height[i] >= height[i-1] +1。难点在于求sa和height。
在这里可以考虑直接用内置的API求sa。
1.我们可以根据(len - sa[i] - height[i])(0 <= i < s.length())求出有多少种子串。
2.还可以求出包含重复子串的最长子串。
class Main {
public static void main(String[] args) {
//0123456
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
sc.nextLine();
String s = sc.nextLine();
// b a n ba an ban ""
// a 5
// ana 3
// anana 1
// banana 0
// na 4
// nana 2
// sa[i] 后缀排名为地i位的后缀索引
Integer []sa = new Integer[s.length()];
for (Integer i = 0 ; i < s.length(); i++){
sa[i] = i;
}
Arrays.sort(sa , (o1 , o2) -> {
String s1 = s.substring(o1);
String s2 = s.substring(o2);
if (s1.compareTo(s2) >= 0){ // 直接进行排序
return 1;
}else {
return -1;
}
});
// rk[i] 表示以i开始的后缀数组的排名
int []rk = new int[s.length()];
for (int i = 0; i < s.length(); i++){
rk[sa[i]] = i;
}
int k = 0;
// height[i] 的含义为 排名第i和排名第i-1的后缀字符串的最长公共前缀
// 性质:height[i] >= height[i-1] + 1 ,
int []height = new int[s.length()];
for (int i = 0; i < s.length(); i++) {
if (rk[i] == 0) continue; // rk[i] 排名不是首位
int j = sa[rk[i] - 1]; // sa[rk[i] - 1] 表示以当前i开始的后缀字符串的上一个排名的后缀字符串的开始索引
k = k > 0 ? k - 1 : k;
while (i + k < s.length() && j + k < s.length() && s.charAt(i + k) == s.charAt(j + k))
k++;
height[rk[i]] = k; // 以i开始的后缀数组,排名为rk[i]的,与前一位排名的后缀字符串的最长前缀的长度
}
// System.out.println(Arrays.toString(sa));
// System.out.println(Arrays.toString(rk));
// System.out.println(Arrays.toString(height));
int res = 0 ;
for (int i = 0 ; i < s.length(); i++){
res = res + s.length() - sa[i] - height[i];
}
System.out.println(res);
// System.out.println(new Solution().longestDupSubstring(s));
}
}
4.6.1 KMP
KMP算法用来求字符串和模式串之间的匹配,求模式串在字符串出现的位置,核心就是在匹配的时候,让模式串尽量根据之前成功的记录,回退的最小。next[i]表示下标为0-i的字符串的最长前缀和后缀公共长度。关键在于求next数组。
class KMP {
public static void main(String[] args) {
System.out.println(KMP("abasdab", "asd", 2));
}
public static int KMP(String Str,String Sub,int pos){
if (Str == null || Sub == null){
return -1;
}
if (pos >= Str.length() || pos < 0){
return -1;
}
int i = pos;
int j = 0;
int[] next = new int[Sub.length()];
getNext(next,Sub);
while(i < Str.length() && j < Sub.length()){
if (j == -1 || Str.charAt(i) == Sub.charAt(j)){
i++;
j++;
}else {
j = next[j];
}
}
if (j >= Sub.length()){
return i-j;
}else {
return -1;
}
}
public static void getNext(int[] next,String sub){
next[0] = -1;
next[1] = 0;
int i = 2;
int j = 0;
//由于我们设定好了next数组前两位的值
//所以我们使用我们上面所讲到的逻辑就可以很好的完成我们的填充
while(i < next.length){
if (j ==- 1 || sub.charAt(j) == sub.charAt(i-1)){
next[i] = j+1;
i++;
j++;
}else {
j = next[j];
}
}
}
}next[i]表示长度为i的字符串的最长公共前后缀的公共长度。
getNext := func (s string )[]int{
next := make([]int , len(s) + 1)
next[0] = -1
next[1] = 0
i := 2 // 实际的位置上
j := 0 // 表示索引
for i < len(next){
if j == -1 || s[i - 1] == s[j] { // i - 1 表示实际的索引位置 , j只是起着索引的作用
next[i] = j + 1
i++
j++
}else {
j = next[j]
}
}
return next
}4.6.2 红黑树
go语言实现红黑树,类似Java中的TreeMap
package main
import (
"fmt"
"github.com/emirpasic/gods/trees/redblacktree"
)
func main() {
rbTree := redblacktree.NewWithStringComparator()
rbTree.Put("2" , 2)
rbTree.Put("1" , 1)
rbTree.Put("3" , 3)
fmt.Println(rbTree.Left())
fmt.Println(rbTree.Right())
cv := rbTree.Iterator()
for cv.Next() {
fmt.Println(cv.Key() , cv.Value())
}
}
4.6.3 Rabin-Karp算法
Rabin-Karp算法是一种哈希算法,将一个字符串转换成数字形式,便于快速判断两个字符串是否相等,其中base一般为31、131等,同时还得注意如果哈希后的数字太大要记得取模MOD。
5.热门题型类
5.1 树
5.1.1 求二叉树的的重心
树的重心定义为,一个节点到左右其他节点的距离之和最短。这个考察了动态规划的思想。
5.2 动态规划
5.2.1数位dp
1.求winder数,winder表示为一个数字的位置上连续的两个数之差要大于等于2,给出范围[LEFT,RIGHT]求winder的个数。
此题可以考虑用dfs暴力或者用数位dp。
// winder数 数位dp的方法
func getWindyNumber(x int)int { // 计算的是1 - x-1满足条件的
if x == 0 {
return 0
}
nums := []int{}
for x != 0 {
nums = append(nums , x % 10)
x /= 10
}
n := len(nums)
dp := make([][]int , n + 1) // dp[i][j] 表示长度为i,且最高位置为j的windy总数
for i := 0; i <= n; i++{
dp[i] = make([]int , 10)
}
for i := 0 ; i <= 9 ; i++{
dp[1][i] = 1
}
for i := 2; i <= n ; i++{ // 长度为i
for j := 0 ; j <= 9; j++{ // 首位为0 - 9
for k := 0 ; k <= 9 ; k++{
if math.Abs(float64(j - k)) >= 2 {
dp[i][j] += dp[i-1][k]
}
}
}
}
res := 0
// 先计算长度为 1 - n -1
for i := 1; i <= n - 1; i++{
for j := 1; j <= 9 ; j ++{
res += dp[i][j]
}
}
// 计算长度为n的,且最高位小于最大位
for i := 1; i < nums[n-1]; i++{
res += dp[n][i]
}
// 计算长度为n,贴着放的情况
for i := n - 1; i >= 1; i--{
for j := 0; j <= nums[i - 1] - 1; j++{
if math.Abs(float64(nums[i] - j)) >= 2 {
res += dp[i][j]
}
}
if math.Abs(float64(nums[i - 1] - nums[i])) < 2 {
break
}
}
//fmt.Println(dp)
return res // 加上0
}
//1 12324566
//1459689
//winder数 dfs方法
//func main() {
// end := "12324566"
// res := 0
// max := func (i , j int)int {
// if i > j {
// return i
// }
// return j
// }
// myabs := func (i , j int)int {
// if i > j {
// return i - j
// }
// return j - i
// }
// var dfs func (step int , last int , cv int , flag bool)
// dfs = func (step int , last int , cv int , flag bool){
// if step == len(end) {
// res++
// //fmt.Print(cv , " ")
// return
// }
// cvMax := 0
// if flag {
// cvMax = max(cvMax , int(end[step] - '0'))
// }else {
// cvMax = max(cvMax , 9)
// }
// for i := 0 ; i <= cvMax ; i++{
// if cv == 0 || myabs(i , last) >= 2 {
// dfs(step + 1 , i , cv * 10 + i , flag && i == cvMax)
// }
// }
// }
// dfs(0 , -2 , 0 , true)
// fmt.Println()
// fmt.Println(res)
//}
5.3 熟记例题
总有那么些算法值得你去记忆它,默写它,因为它们都太高频了。
5.2.1 LRU
lru是先进先出算法,主要记忆点就是如下图所示。

package alian;
import java.util.HashMap;
class Main{
public static void main(String[] args) {
LRU lru = new LRU(3);
lru.set("1",new Integer(1));
lru.set("2",new Integer(2));
System.out.println(lru.get("1") != null);
lru.set("3",new Integer(3));
System.out.println(lru.get("3") != null);
lru.set("4",new Integer(4));
System.out.println(lru.get("1") == null);
}
}
class LRU{
HashMap<String , Node> map ;
Node head,tail;
int n ;
int size ;
public LRU(int n) {
map = new HashMap<>();
head = new Node();
tail = new Node();
head.next = tail;
tail.pre = head;
size = 0;
this.n = n;
}
class Node{
String key;
Object val;
Node pre;
Node next;
}
public Node get(String key){
if (!map.containsKey(key)){
return null;
}
Node cv = map.get(key);
// cv从双链表中断开
Node pre1 = cv.pre;
Node next1 = cv.next;
pre1.next = next1;
next1.pre = pre1;
//插入到head之后
head.next.pre = cv;
cv.next = head.next;
head.next = cv;
cv.pre = head;
return cv;
}
public void set(String key , Object val){
if (!map.containsKey(key)){
Node cv = new Node();
cv.key = key;
cv.val = val;
size++;
head.next.pre = cv;
cv.next = head.next;
head.next = cv;
cv.pre = head;
map.put(key , cv);
if (size > n){
size --;
Node tep = tail.pre.pre;
map.remove(tail.pre.key);
tep.next = tail;
tail.pre = tep;
}
}else {
Node cv = map.get(key);
cv.val = val;
Node pre1 = cv.pre;
Node next1 = cv.next;
pre1.next = next1;
next1.pre = pre1;
head.next.pre = cv;
cv.next = head.next;
head.next = cv;
cv.pre = head;
}
}
}
5.2.2 LFU
lfu是在lru基础上的算法,增加了一个访问的频次。
















 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











