







第十五章 电商产品评价
15.1 背景与挖掘目标
对消费者的文本评论数据进行内在信息的数据挖掘分析。建模目标:
1)分析某一热水器的用户情感倾向;
2)从评论文本中挖掘出该热水器的优点与不足;
3)提炼不同品牌热水器的卖点。
15.2 分析方法与过程
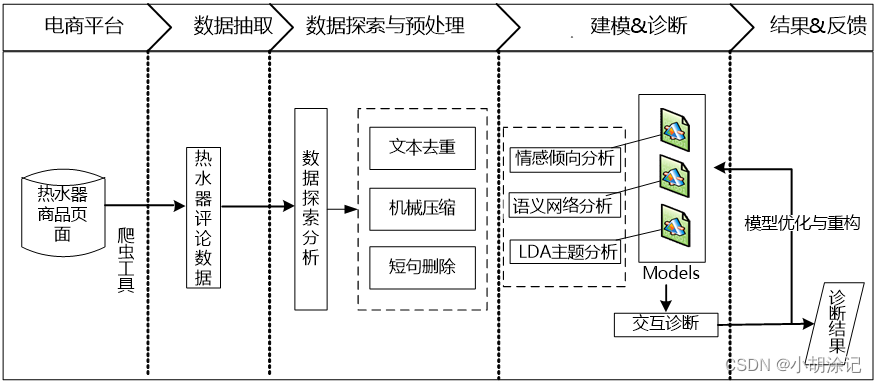
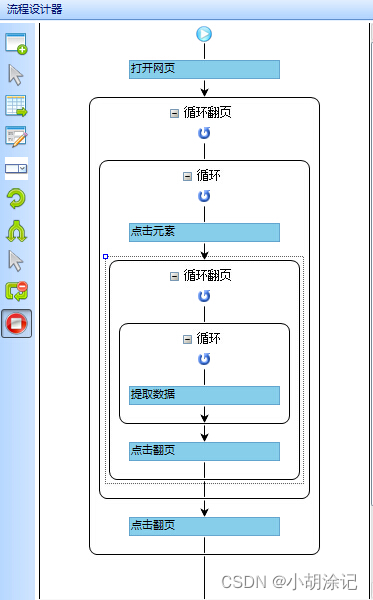
1、评论数据采集
书中用到的是八爪鱼采集器对JD商城进行热水器评论的数据进行采集。
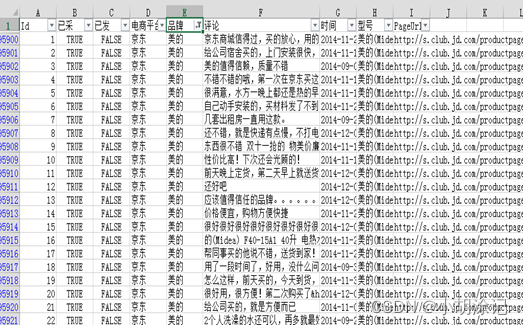
##只抽取需要的数据
setwd("F:/数据及程序/chapter15/示例程序")
Data <- read.csv("./data/huizong.csv", header = TRUE, encoding = 'utf-8')
colnames(Data) <- c("x1", "x2", "x3", "x4", "x5", "x6", "x7", "x8", "x9")
index <- which(Data$x5 == "美的")
meidi_jd <- Data[index, 6]
write.table(meidi_jd, "./tmp/meidi_jd.txt", row.names = FALSE)
2、评论预处理
文本去重: 编辑距离去重、Simhash算法去重,但是在这里存在一定的缺陷,书中采用的是去除完全重复的评论,对于重复的评论只做唯一保留。
机械压缩去词: 对重复词过多的评论进行删除,这一步需要人工参与。
短句删除: 删除过短的评论数据,去掉没有意义的评论。
3、文本评论分词
R中的“jiebaR”分词包。
4、模型构建
情感倾向性模型:考虑“词汇鸿沟”无法反映语义关联的问题,采用神经网络语言模型NNLM和N-gram语言模型——word2vec,每个词都可以表示成一个实数向量。
评论子集的人工标注与映射:人为对评论的正负项进行标注,或者python中snownlp的sentiment功能做简单机器标注。
在对评论情感倾向性分析并分类的这部分,书中说可以用武汉大学开发的免费反剽窃系统“ROSTCM6”,其在情感倾向性分析使用的是基于优化的情感词典的方法,准确性会高于词向量加神经网络的模式。
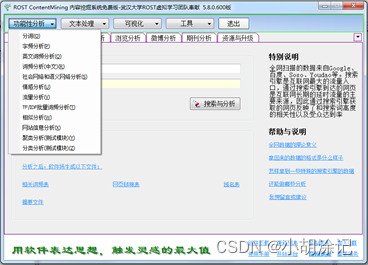
基于LDA模型的主题分析,在基于语义网络的评论分析进行初步数据感知后,需要对主题的特征词出现频率进行量化。TF、TF-IDF这类方法没有考虑文字背后的语义关联,用LDA这样的主题模型可以达到想要的效果,LDA属于无监督的生成式主题概率模型。LDA中的参数估计是用的MCMC中的Gibbs吉布斯抽样。
setwd("F:/数据及程序/chapter15/示例程序")
Data <- readLines("./data/meidi_jd.txt", encoding = "UTF-8")
length(Data)
# 删除重复值
Data1 <- unique(Data)
length(Data1)
##删除前缀评分代码
# 把“数据及程序”文件夹拷贝到F盘下,再用setwd设置工作空间
setwd("F:/数据及程序/chapter15/示例程序")
# 读入数据
Data1 <- readLines("./data/meidi_jd_process_end_负面情感结果.txt", encoding = "UTF-8")
Data2 <- readLines("./data/meidi_jd_process_end_正面情感结果.txt", encoding = "UTF-8")
for (i in 1:length(Data1)) {
Data1[i] <- unlist(strsplit(Data1[i], "\\t"))[2]
}
for (i in 1:length(Data2)) {
Data2[i] <- unlist(strsplit(Data2[i], "\\t"))[2]
}
write.table(Data1, "./tmp/meidi_jd_neg.txt", row.names = FALSE)
write.table(Data2, "./tmp/meidi_jd_pos.txt", row.names = FALSE)
#对两个文本进行分词,保存成两个txt文档,并和停用词文档一起作为LDA程序的输入
##分词代码
# 加载工作空间
library(jiebaRD)
library(Rcpp)
library(jiebaR)
setwd("F:/数据及程序/chapter15/示例程序")
Data1 <- readLines("./data/meidi_jd_pos.txt", encoding = "UTF-8")
Data2 <- readLines("./data/meidi_jd_neg.txt", encoding = "UTF-8")
cutter <- worker()
cutter <= Data1
cutter2 <- worker()
cutter2 <= Data2
write.table(cutter <= Data1, "./tmp/meidi_jd_neg_cut.txt", row.names = FALSE)
write.table(cutter2 <= Data2, "./tmp/meidi_jd_pos_cut.txt", row.names = FALSE)
##LDA代码
# 加载工作空间
library(NLP)
library(tm)
library(slam)
library(wordcloud)
library(topicmodels)
# R语言环境下的文本可视化及主题分析
setwd("F:/数据及程序/chapter15/示例程序")
Data1 <- readLines("./data/meidi_jd_pos_cut.txt", encoding = "UTF-8")
Data2 <- readLines("./data/meidi_jd_neg_cut.txt", encoding = "UTF-8")
stopwords <- unlist (readLines("./data/stoplist.txt", encoding = "UTF-8"))
# 删除stopwords
removeStopWords = function(x, words) {
ret <- character(0)
index <- 1
it_max <- length(x)
while (index <= it_max) {
if (length(words[words == x[index]]) <1) ret <- c(ret, x[index])
index <- index + 1
}
ret
}
# 删除空格、字母
Data1 <- gsub("([a~z])", "", Data1)
Data2 <- gsub("([a~z])", "", Data2)
# 删除停用词
sample.words1 <- lapply(Data1, removeStopWords, stopwords)
sample.words2 <- lapply(Data2, removeStopWords, stopwords)
# 构建语料库
corpus1 = Corpus(VectorSource(sample.words1))
# 建立文档-词条矩阵
sample.dtm1 <- DocumentTermMatrix(corpus1, control = list(wordLengths = c(2, Inf)))
# 主题模型分析
Gibbs = LDA(sample.dtm1, k = 3, method = "Gibbs",
control = list(seed = 2015, burnin = 1000, thin = 100, iter = 1000))
# 最可能的主题文档
Topic1 <- topics(Gibbs, 1)
table(Topic1)
# 每个Topic前10个Term
Terms1 <- terms(Gibbs, 10)
Terms1
# 负面评价LDA分析
# 构建语料库
corpus2 = Corpus(VectorSource(sample.words2))
# 建立文档-词条矩阵
sample.dtm2 <- DocumentTermMatrix(corpus2, control = list(wordLengths = c(2, Inf)))
# 主题模型分析
library(topicmodels)
Gibbs2 = LDA(sample.dtm2, k = 3, method = "Gibbs",
control = list(seed = 2015, burnin = 1000, thin = 100, iter = 1000))
# 最可能的主题文档
Topic2 <- topics(Gibbs2, 1)
table(Topic2)
# 每个Topic前10个Term
Terms2 <- terms(Gibbs2, 10)
Terms2
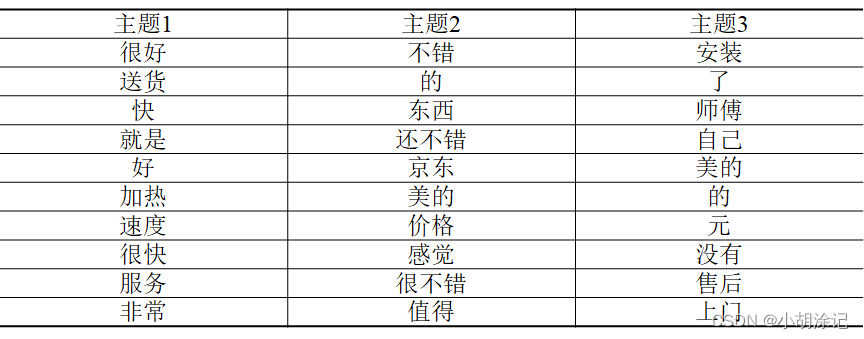
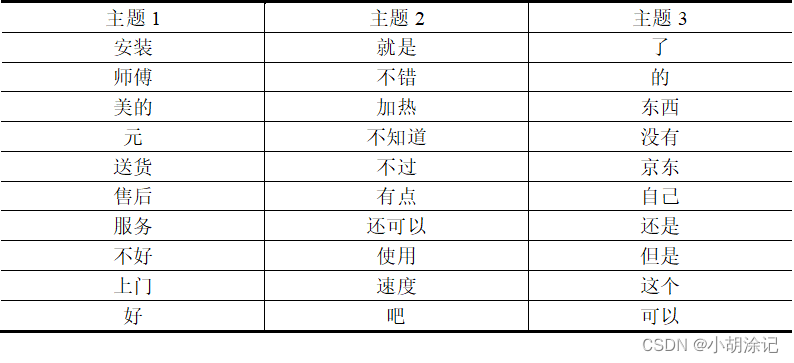
最后能得到正面和负面的潜在主题词表,结合业务情况可以得到分析结果。
【至此,这本书就算我大致看完了,有一些处理方法和分析角度是以前在教材类书籍中没有见过的。很好的实践工具书】















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









