









目录
1 HQL操作之–DML命令
数据操纵语言DML(Data Manipulation Language),DML主要有三种形式:插入(INSERT)、删除(DELETE)、更新(UPDATE)。
事务(transaction)是一组单元化操作,这些操作要么都执行,要么都不执行,是一个不可分割的工作单元。
事务具有的四个要素:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability),这四个基本要素通常称为ACID特性。
- 原子性。一个事务是一个不可再分割的工作单位,事务中的所有操作要么都发生,要么都不发生。
- 一致性。事务的一致性是指事务的执行不能破坏数据库数据的完整性和一致性,一个事务在执行之前和执行之后,数据库都必须处于一致性状态。
- 隔离性。在并发环境中,并发的事务是相互隔离的,一个事务的执行不能被其他事务干扰。即不同的事务并发操纵相同的数据时,每个事务都有各自完整的数据空间,即一个事务内部的操作及使用的数据对其他并发事务是隔离的,并发执行的各个事务之间不能互相干扰。
- 持久性。事务一旦提交,它对数据库中数据的改变就应该是永久性的。
1.1 Hive 事务
Hive从0.14版本开始支持事务 和 行级更新,但缺省是不支持的,需要一些附加的配置。要想支持行级insert、update、delete,需要配置Hive支持事务。
Hive事务的限制:
- Hive提供行级别的ACID语义
- BEGIN、COMMIT、ROLLBACK 暂时不支持,所有操作自动提交
- 目前只支持 ORC 的文件格式
- 默认事务是关闭的,需要设置开启
- 要是使用事务特性,表必须是分桶的
- 只能使用内部表
- 如果一个表用于ACID写入(INSERT、UPDATE、DELETE),必须在表中设置表属性 : “transactional=true”
- 必须使用事务管理器 org.apache.hadoop.hive.ql.lockmgr.DbTxnManager
- 目前支持快照级别的隔离。就是当一次数据查询时,会提供一个数据一致性的快照
- LOAD DATA语句目前在事务表中暂时不支持
HDFS是不支持文件的修改;并且当有数据追加到文件,HDFS不对读数据的用户提供一致性的。为了在HDFS上支持数据的更新:
- 表和分区的数据都被存在基本文件中(base files)
- 新的记录和更新,删除都存在增量文件中(delta files)
- 一个事务操作创建一系列的增量文件
- 在读取的时候,将基础文件和修改,删除合并,最后返回给查询
1.2 Hive 事务操作示例
-- 这些参数也可以设置在hive-site.xml中
SET hive.support.concurrency = true;
-- Hive 0.x and 1.x only
SET hive.enforce.bucketing = true;
SET hive.exec.dynamic.partition.mode = nonstrict;
SET hive.txn.manager =
org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
-- 创建表用于更新。满足条件:内部表、ORC格式、分桶、设置表属性
create table zxz_data(
name string,
nid int,
phone string,
ntime date)
clustered by(nid) into 5 buckets
stored as orc
tblproperties('transactional'='true');
-- 创建临时表,用于向分桶表插入数据
create table temp1(
name string,
nid int,
phone string,
ntime date)
row format delimited
fields terminated by ",";
-- 数据
name1,1,010-83596208,2020-01-01
name2,2,027-63277201,2020-01-02
name3,3,010-83596208,2020-01-03
name4,4,010-83596208,2020-01-04
name5,5,010-83596208,2020-01-05
-- 向临时表加载数据;向事务表中加载数据
load data local inpath '/home/hadoop/data/zxz_data.txt' overwrite
into table temp1;
insert into table zxz_data select * from temp1;
-- 检查数据和文件
select * from zxz_data;
dfs -ls /user/hive/warehouse/mydb.db/zxz_data ;
-- DML 操作
delete from zxz_data where nid = 3;
dfs -ls /user/hive/warehouse/mydb.db/zxz_data ;
insert into zxz_data values ("name3", 3, "010-83596208",
current_date); -- 不支持
insert into zxz_data values ("name3", 3, "010-83596208", "2020-
06-01"); -- 执行
insert into zxz_data select "name3", 3, "010-83596208",
current_date;
dfs -ls /user/hive/warehouse/mydb.db/zxz_data ;
insert into zxz_data values
("name6", 6, "010-83596208", "2020-06-02"),
("name7", 7, "010-83596208", "2020-06-03"),
("name8", 9, "010-83596208", "2020-06-05"),
("name9", 8, "010-83596208", "2020-06-06");
dfs -ls /user/hive/warehouse/mydb.db/zxz_data ;
update zxz_data set name=concat(name, "00") where nid>3;
dfs -ls /user/hive/warehouse/mydb.db/zxz_data ;
-- 分桶字段不能修改,下面的语句不能执行
-- Updating values of bucketing columns is not supported
update zxz_data set nid = nid + 1;
2 元数据管理与存储
2.1 Metastore
在Hive的具体使用中,首先面临的问题便是如何定义表结构信息,跟结构化的数据映射成功。所谓的映射指的是一种对应关系。在Hive中需要描述清楚表跟文件之间的映射关系、列和字段之间的关系等等信息。这些描述映射关系的数据的称之为Hive的元数据。该数据十分重要,因为只有通过查询它才可以确定用户编写sql和最终操作文件之间的关系。
Metadata即元数据。元数据包含用Hive创建的database、table、表的字段等元信息。元数据存储在关系型数据库中。如hive内置的Derby、第三方如MySQL等。
Metastore即元数据服务,是Hive用来管理库表元数据的一个服务。有了它上层的服务不用再跟裸的文件数据打交道,而是可以基于结构化的库表信息构建计算框架。
通过metastore服务将Hive的元数据暴露出去,而不是需要通过对Hive元数据库mysql的访问才能拿到Hive的元数据信息;metastore服务实际上就是一种thrift服务,通过它用户可以获取到Hive元数据,并且通过thrift获取元数据的方式,屏蔽了数据库访问需要驱动,url,用户名,密码等细节。
metastore三种配置方式
-
内嵌模式
内嵌模式使用的是内嵌的Derby数据库来存储元数据,也不需要额外起Metastore服务。数据库和Metastore服务都嵌入在主Hive Server进程中。这个是默认的,配置简单,但是一次只能一个客户端连接,适用于用来实验,不适用于生产环境。
**优点:**配置简单,解压hive安装包 bin/hive 启动即可使用;
**缺点:**不同路径启动hive,每一个hive拥有一套自己的元数据,无法共享。 -
本地模式
本地模式采用外部数据库来存储元数据,目前支持的数据库有:MySQL、Postgres、Oracle、MS SQL Server。教学中实际采用的是MySQL。
本地模式不需要单独起metastore服务,用的是跟Hive在同一个进程里的metastore服务。也就是说当启动一个hive 服务时,其内部会启动一个metastore服务。Hive根据 hive.metastore.uris 参数值来判断,如果为空,则为本地模式。
**缺点:**每启动一次hive服务,都内置启动了一个metastore;在hive-site.xml中暴露
的数据库的连接信息;
**优点:**配置较简单,本地模式下hive的配置中指定mysql的相关信息即可。

-
远程模式
远程模式下,需要单独起metastore服务,然后每个客户端都在配置文件里配置连接到该metastore服务。远程模式的metastore服务和hive运行在不同的进程里。在生产环境中,建议用远程模式来配置Hive Metastore。
在这种模式下,其他依赖hive的软件都可以通过Metastore访问Hive。此时需要配置hive.metastore.uris 参数来指定 metastore 服务运行的机器ip和端口,并且需要单独手动启动metastore服务。metastore服务可以配置多个节点上,避免单节点故障导致整个集群的hive client不可用。同时hive client配置多个metastore地址,会自动选择可用节点。

metastore内嵌模式配置
1、下载软件解压缩
2、设置环境变量,并使之生效
3、初始化数据库
schematool -dbType derby -initSchema
4、进入hive命令行
5、再打开一个hive命令行,发现无法进入
metastore远程模式配置
配置规划:
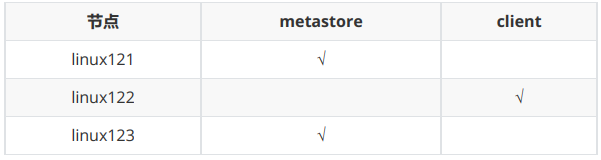
配置步骤:
- 将 linux123 的 hive 安装文件拷贝到 linux121、linux122
- 在linux121、linux123上分别启动 metastore 服务
# 启动 metastore 服务
nohup hive --service metastore &
# 查询9083端口(metastore服务占用的端口)
lsof -i:9083
# 安装lsof
yum install lsof
- 修改 linux122 上hive-site.xml。删除配置文件中:MySQL的配置、连接数据库的用户名、口令等信息;增加连接metastore的配置:
<!-- hive metastore 服务地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://linux121:9083,thrift://linux123:9083</value>
</property>
- 启动hive。此时client端无需实例化hive的metastore,启动速度会加快。
# 分别在linux121、linux123上执行以下命令,查看连接情况
lsof -i:9083
- 高可用测试。关闭已连接的metastore服务,发现hive连到另一个节点的服务上,仍然能够正常使用。
2.2 HiveServer2
HiveServer2是一个服务端接口,使远程客户端可以执行对Hive的查询并返回结果。目前基于Thrift RPC的实现是HiveServer的改进版本,并支持多客户端并发和身份验证,启动hiveServer2服务后,就可以使用jdbc、odbc、thrift 的方式连接。
Thrift是一种接口描述语言和二进制通讯协议,它被用来定义和创建跨语言的服务。它被当作一个远程过程调用(RPC)框架来使用,是由Facebook为“大规模跨语言服务开发”而开发的。

HiveServer2(HS2)是一种允许客户端对Hive执行查询的服务。HiveServer2是HiveServer1的后续 版本。HS2支持多客户端并发和身份验证,旨在为JDBC、ODBC等开放API客户端提供更好的支持。
HS2包括基于Thrift的Hive服务(TCP或HTTP)和用于Web UI 的Jetty Web服务器。
HiveServer2作用:
- 为Hive提供了一种允许客户端远程访问的服务
- 基于thrift协议,支持跨平台,跨编程语言对Hive访问
- 允许远程访问Hive
HiveServer2配置
- 修改集群上的 core-site.xml,增加以下内容:
<!-- HiveServer2 连不上10000;hadoop为安装用户 -->
<!-- root用户可以代理所有主机上的所有用户 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
- 修改 集群上的 hdfs-site.xml,增加以下内容:
<!-- HiveServer2 连不上10000;启用 webhdfs 服务 -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
- 启动linux123上的 HiveServer2 服务
# 启动 hiveserver2 服务
nohup hiveserver2 &
# 检查 hiveserver2 端口
lsof -i:10000
# 从2.0开始,HiveServer2提供了WebUI
# 还可以使用浏览器检查hiveserver2的启动情况。http://linux123:10002/
- 启动 linux122 节点上的 beeline
Beeline是从 Hive 0.11版本引入的,是 Hive 新的命令行客户端工具。
Hive客户端工具后续将使用Beeline 替代 Hive 命令行工具 ,并且后续版本也会废弃掉 Hive 客户端工具。
!connect jdbc:hive2://linux123:10000
use mydb;
show tables;
select * from emp;
create table tabtest1 (c1 int, c2 string);
!connect jdbc:mysql://linux123:3306
!help
!quit
如果此时连接hive报错,如下图:
报错内容提示hive没有/tmp目录的权限,赋予权限即可:
hdfs dfs -chmod 777 /tmp

2.3 HCatalog
HCatalog 提供了一个统一的元数据服务,允许不同的工具如 Pig、MapReduce 等通过 HCatalog 直接访问存储在 HDFS 上的底层文件。HCatalog是用来访问Metastore的Hive子项目,它的存在给了整个Hadoop生态环境一个统一的定义。
HCatalog 使用了 Hive 的元数据存储,这样就使得像 MapReduce 这样的第三方应用可以直接从 Hive 的数据仓库中读写数据。同时,HCatalog 还支持用户在MapReduce 程序中只读取需要的表分区和字段,而不需要读取整个表,即提供一种逻辑上的视图来读取数据,而不仅仅是从物理文件的维度。
HCatalog 提供了一个称为 hcat 的命令行工具。这个工具和 Hive 的命令行工具类似,两者最大的不同就是 hcat 只接受不会产生 MapReduce 任务的命令,主要接受DDL命令(建表,查表)。
# 进入 hcat 所在目录。$HIVE_HOME/hcatalog/bin
cd $HIVE_HOME/hcatalog/bin
# 执行命令,创建表
./hcat -e "create table default.test1(id string, name string, age
int)"
# 长命令可写入文件,使用 -f 选项执行
./hcat -f createtable.txt
# 查看元数据
./hcat -e "use mydb; show tables"
# 查看表结构
./hcat -e "desc mydb.emp"
# 删除表
./hcat -e "drop table default.test1"
2.4 数据存储格式
Hive支持的存储数的格式主要有:TEXTFILE(默认格式) 、SEQUENCEFILE、RCFILE、ORCFILE、PARQUET。
- textfile为默认格式,建表时没有指定文件格式,则使用TEXTFILE,导入数据时会直接把数据文件拷贝到hdfs上不进行处理;
- sequencefile,rcfile,orcfile格式的表不能直接从本地文件导入数据,通常将数据先导入到textfile格式的表中, 然后再从表中用insert导入sequencefile、rcfile、orcfile表中。
行存储与列存储
行式存储下一张表的数据都是放在一起的,但列式存储下数据被分开保存了。
行式存储:
点:数据被保存在一起,insert和update更加容易,大多数数据库都使用行存储(mysql/orical)
缺点:选择(selection)时即使只涉及某几列,所有数据也都会被读取
列式存储:
优点:查询时只有涉及到的列会被读取,效率高
缺点:选中的列要重新组装,insert/update比较麻烦
TEXTFILE、SEQUENCEFILE 的存储格式是基于行存储的;
ORC和PARQUET 是基于列式存储的。

TextFile
Hive默认的数据存储格式,数据不做压缩,磁盘开销大,数据解析开销大。 可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
create table if not exists uaction_text(
userid string,
itemid string,
behaviortype int,
geohash string,
itemcategory string,
time string)
row format delimited fields terminated by ','
stored as textfile;
load data local inpath '/home/hadoop/data/useraction.dat'
overwrite into table uaction_text;
SEQUENCEFILE
SequenceFile是Hadoop API提供的一种二进制文件格式,其具有使用方便、可分割、可压缩的特点。 SequenceFile支持三种压缩选择:none,record,block。Record压缩率低,一般建议使用BLOCK压缩。
RCFile
RCFile全称Record Columnar File,列式记录文件,是一种类似于SequenceFile的键值对数据文件。RCFile结合列存储和行存储的优缺点,是基于行列混合存储的RCFile。
RCFile遵循的**“先水平划分,再垂直划分”**的设计理念。先将数据按行水平划分为行组,这样一行的数据就可以保证存储在同一个集群节点;然后在对行进行垂直划分。

- 一张表可以包含多个HDFS block
- 在每个block中,RCFile以行组为单位存储其中的数据
- row group又由三个部分组成
第一部分是用于在block中分隔两个row group的16字节的标志区
第二部分是存储row group元数据信息的header
第三部分才是实际数据区,表中的实际数据以列为单位进行存储
ORCFile
ORC File,它的全名是Optimized Row Columnar (ORC) file,其实就是对RCFile做了一些优化,在hive 0.11中引入的存储格式。这种文件格式可以提供一种高效的方法来存储Hive数据。它的设计目标是来克服Hive其他格式的缺陷。运用ORC File可以提高Hive的读、写以及处理数据的性能。ORC文件结构由三部分组成:
- 文件脚注(file footer)(紫色区域):包含了文件中 stripe 的列表,每个stripe行数,以及每个列的数据类型。还包括每个列的最大、最小值、行计数、求和等信息
- postscript(白色区域):压缩参数和压缩大小相关信息
- 条带(stripe):ORC文件存储数据的地方。在默认情况下,一个stripe的大小为250MB
Index Data:索引信息,是一个轻量级的index,默认是每隔1W行做一个索引。包括该条带的一些统计信息,以及数据在stripe中的位置索引信息
Rows Data:存放实际的数据。先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个stream来存储
Stripe Footer:条带脚注,存放stripe的元数据信息

ORC在每个文件中提供了3个级别的索引:文件级、条带级、行组级。借助ORC提供的索引信息能加快数据查找和读取效率,规避大部分不满足条件的查询条件的文件和数据块。使用ORC可以避免磁盘和网络IO的浪费,提升程序效率,提升整个集群的工作负载。
create table if not exists uaction_orc(
userid string,
itemid string,
behaviortype int,
geohash string,
itemcategory string,
time string)
stored as orc;
insert overwrite table uaction_orc select * from uaction_text;
Parquet
Apache Parquet是Hadoop生态圈中一种新型列式存储格式,它可以兼容Hadoop生态圈中大多数计算框架(Mapreduce、Spark等),被多种查询引擎支持(Hive、Impala、Drill等),与语言和平台无关的。
Parquet文件是以二进制方式存储的,不能直接读取的,文件中包括实际数据和元数据,Parquet格式文件是自解析的。

- 一个文件由多个行组(Row group)和元数据(Footer)构成构成。
- Row group:
- 写入数据时的最大缓存单元
- MR任务的最小并发单元
- 一般大小在50MB-1GB之间
- Column chunk:
- 存储当前Row group内的某一列数据
- 最小的IO并发单元
- Page:
- 压缩、读数据的最小单元
- 获得单条数据时最小的读取数据单元
- 大小一般在8KB-1MB之间,越大压缩效率越高
- Footer:
- 数据Schema信息
- 每个Row group的元信息:偏移量、大小
- 每个Column chunk的元信息:每个列的编码格式、首页偏移量、首索引页偏移量、个数、大小等信息
文件存储格式对比测试
# 检查文件行数
wc -l uaction.dat
# 获取文件中少量数据
head -n 1000 uaction.dat > uaction1.dat
tail -n 1000 uaction.dat > uaction2.dat
文件压缩比(ORC > Parquet > text)
hive (mydb)> dfs -ls /user/hive/warehouse/mydb.db/ua*;
#orc
13517070 /user/hive/warehouse/mydb.db/uaction_orc/000000_1000
#parquet
34867539 /user/hive/warehouse/mydb.db/uaction_parquet/000000_1000
#original
90019734 /user/hive/warehouse/mydb.db/uaction_text/useraction.dat
执行查询(orc 与 parquet类似>>txt)
在生产环境中,Hive表的数据格式使用最多的有三种:TextFile、ORCFile、Parquet。
- TextFile文件更多的是作为跳板来使用(即方便将数据转为其他格式)
- 有update、delete和事务性操作的需求,通常选择ORCFile
- 没有事务性要求,希望支持Impala、Spark,建议选择Parquet















 1109
1109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









