







Stanford NLP提供了一系列自然语言分析工具,它们是:
- 分词:StanfordTokenizer、StanfordSegmenter
- 词性标注: StanfordPOSTagger
- 命名实体识别: StanfordNERTagger
- 句法分析: StanfordParser
- 依存句法分析: StanfordDependencyParser, StanfordNeuralDependencyParser
如何在windows下使用StanfordParser 呢?
一、安装JDK,配置环境变量
1.下载JDK

下载完成之后,解压,双击.exe文件下一步下一步即可,可以不使用默认安装目录,自己设置目录。
2.配置环境变量
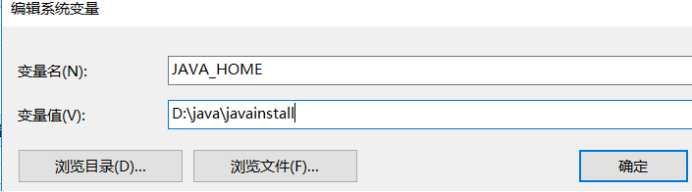
a.新建-->变量名-->”JAVA_HOME”,变量值-->JDK的安装路径 (我的JDK安装路径为”D:\java\javainstall” ,如下图所示)

b.新建-->变量名-->”CLASSPATH”,变量值--> “%JAVA_HOME%\lib”
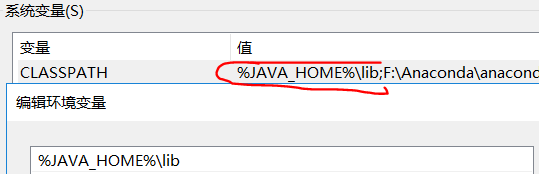
c.编辑-->变量名”Path”,增加变量值--> “%JAVA_HOME%\bin”

3.检验是否安装配置成功
输入cmd,进入dos界面,输入Java。如果显示如下图所示,说明安装配置成功。

二、下载StanfordParser,配置环境变量

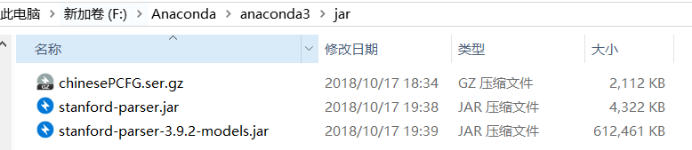
需要三个文件:
- stanford-parser-3.9.2-models.jar
- stanford-parser.jar
- chinesePCFG.ser.gz(中文句法分析)
注意:如果是英文句法分析,需要englishPCFG.ser.gz,而不是chinesePCFG.ser.gz
获取上述三个文件:解压刚下载的压缩包(stanford-parser-full-2018-10-17.zip),从中找到stanford-parser-3.9.2-models.jar和stanford-parser.jar文件。再将stanford-parser-3.9.2-models.jar文件解压,chinesePCFG.ser.gz文件就藏在stanford-parser-3.9.2-models.jar文件中,一直单击\edu\stanford\nlp\models\lexparser,就可以找到chinesePCFG.ser.gz文件。
在python.exe所在目录,新建文件夹jar,将上述三个文件放于jar文件中,如下图所示:
2.配置环境变量:
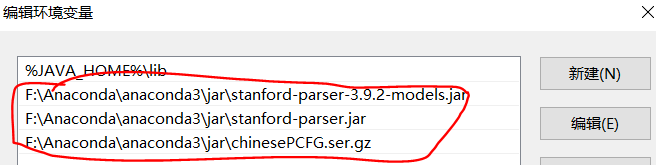
Stanford NLP是由java开发的,Stanford Parser模型被包含在jar文件中。去访问该模型的最简单的方式是:将该jar文件放到java的CLASSPATH中。
将上述三个文件的路径放于CLASSPATH环境变量中,如下图所示:
三、安装NLTK库,配置环境变量
NLTK (Natural language toolkit)是一个最受欢迎的开源自然语言处理库,为提供Standford NLP接口,它是用python语言编写的,依托python来安装。
1.安装NLTK
a.用pip命令安装nltk(最简单的安装方式): pip install nltk
b.运行python命令
c.输入import nltk
d.输入nltk.download()

e.弹出下图所示窗口,选中book模块,此模块包含了很多数据案例和内置函数。在python.exe所在目录,新建nltk_data文件夹,book下载目录,如下图所示:

2.配置环境变量
编辑-->变量名”Path”,增加变量值--> “F:\Anaconda\anaconda3\nltk_data”

3.检验是否安装配置成功
输入cmd,进入dos界面,输入pyhton,打开python编辑器,输入from nltk.book import *。如果显示如下图所示,说明安装配置成功。

四、使用StanfordParser进行中文句法分析
import os
from nltk.parse import stanford
os.environ['STANFORD_PARSER'] = "F:\\Anaconda\\anaconda3\\jar\\stanford-parser.jar"
os.environ['STANFORD_MODELS'] = "F:\\Anaconda\\anaconda3\\jar\\stanford-parser-3.9.2-models.jar"
parser=stanford.StanfordParser(model_path="F:\\Anaconda\\anaconda3\\jar\\chinesePCFG.ser.gz")
sent = parser.raw_parse("我 爱 NLP")
for line in sent:
line.draw()
运行结果:
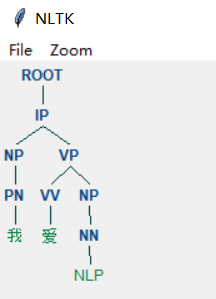
ROOT:要处理文本的语句
IP:简单从句
NP:名词短语
VP:动词短语
PN:代词
VV:动词
NN:常用名词















 2580
2580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









