






开篇回答标题问题:字符编码识别错误
计算机通过编码表来识别和解析字符编码。编码表是一个映射表,将字符与对应的编码值进行关联。
当计算机接收到一串二进制数据时,它会根据所使用的编码方式来解析这些数据。计算机会根据编码规则,将连续的二进制位组合成字符,并根据编码表将这些字符转换为对应的字符编码。
-
在UTF-8编码中,汉字"我"的二进制表示为:11100100 10111000 10010000。 在UTF-16编码中,汉字"我"的二进制表示为:01001110 01000001。 在UTF-32编码中,汉字"我"的二进制表示为:0000 0110 0010 0001 0001 0000 0000 0000。 在GBK编码中,汉字"我"的二进制表示为:11010110 10110001。 在Big5编码中,汉字"我"的二进制表示为:10110010 10110001。
这么多字符集导致的冲突就就会发生乱码现象
字符集发展史
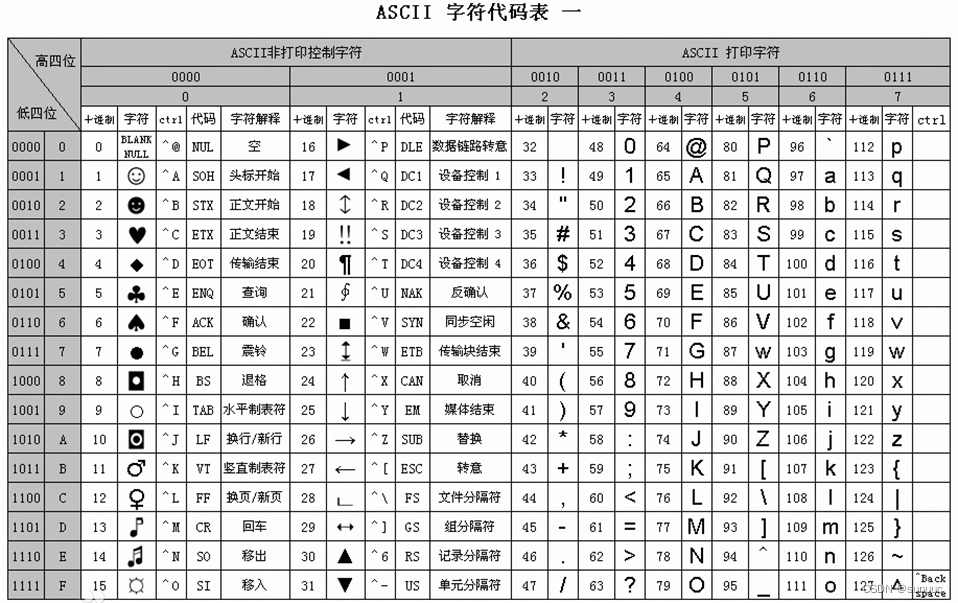
字符集有一个发展历史,ASCII 是最早出现的字符集,仅含有 128 个字符,但局限于英文字母和部分符号,无法适用于非英语国家和地区,即便是后来拓充成 ASICII 字符集也不够用
后来各个国家和地区都推出了自己的字符集,如中国大陆推出的GBK
但各地标准不统一,同一个编码在不同字符集里对应的很可能是完全不同的字符,这就导致乱码现象,最终才出现相关组织意推出囊括全球的大一统字符集 UCS 和 Unicode
目前主流的字符集是 Unicode,采取 UTF-8 编码方式
ASCII
开始,计算机只在美国用。八位的字节一共可以组合出256(2的8次方)种不同的状态。英文字母算上大小写加数字,和一些符号,256个字符对于美国人足够了
附:ASCII码表:
GBK
计算机发展到中国是,中国庞大的几万数字库原来的编码库空间当然远远不够,这就有了GBK编码,每个汉字两个字节存储,并且GBK编码能正常显示美国的ASCII编码的内容
UTF-32
由于很多国家都有自己的编码标准,字符集非常乱,所以终于有人出手了统一了
那就是Unicode Transformation Format (UTF)
UTF-32就采用每个字符一刀切的4个字节的储存形式(4个字节为32位,因此是UTF-32)。
UTF-32格式下,每个字符会读取4个字节,然后按标准转化为字符。
这种格式的好处在于,读取效率尤其高。计算机只管4个字节4个字节地读,不需要考虑其他。而缺点就在于,空间占用率过大。

对于美国而言,常用的字符已包含在ASCII中,也就是说一个字节就能满足大多数使用场景。而UTF-32的格式下,即便是ASCII中的字符,也要占用4个字节,是原来的4倍。他们当然不乐意了。
UTF-8
然后就有了现在流通的UTF-8,
UTF-8是最常用的一种Unicode转换格式。也是最灵活的一种格式。
UTF-8解决了UTF-32占用空间过大的问题。8即是8位,代表着读取单位为8bit,即1个字节。
ASCII的字符只用这1个字节便可以转换,而其他字符则由多个字节组成。
由于采用了这种组合式的做法。UTF-8编码的每个字节需要用字节开头的几位来告诉计算机一些信息,比如这个字节是某个字符的首字节,由多少个字节组成,亦或者这个字节是别的字符的后续。
















 1605
1605











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









