









本文代码基于系列八代码的基础上修改
1.安装redis
pip install -U redis==2.10.6
2.配置数据库连接信息
在settings.py文件加入数据库连接,属性名没有规定可以随便起
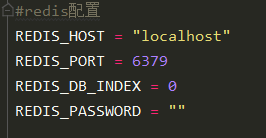
3.获取数据库配置,连接数据库

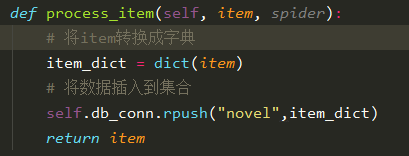
4.执行数据库操作
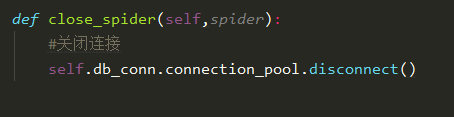
5.关闭客户端连接
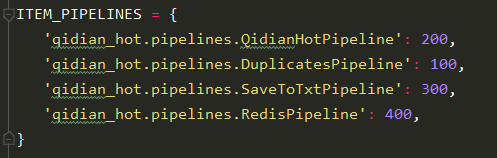
6.加入到数据清洗的管道
完整代码
class RedisPipeline(object):
def open_spider(self,spider):
#第一个参数是settings.py里的属性,第二个参数是获取不到值的时候的替代值
host = spider.settings.get("REDIS_HOST","localhost")
port = spider.settings.get("REDIS_PORT",6379)
db_index = spider.settings.get("REDIS_DB_INDEX",0)
db_psd = spider.settings.get("REDIS_PASSWORD","")
#连接数据库
self.db_conn = redis.StrictRedis(host=host,port=port,db=db_index,password=db_psd)
def process_item(self, item, spider):
# 将item转换成字典
item_dict = dict(item)
# 将数据插入到集合
self.db_conn.rpush("novel",item_dict)
return item
def close_spider(self,spider):
#关闭连接
self.db_conn.connection_pool.disconnect()















 2460
2460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









