








 本文详细介绍如何使用Chrome浏览器注册并登录起点中文网账号,通过安装browsercookie和pycryptodome库来获取网站的cookie,进而实现自动化操作,如访问个人书架等功能。
本文详细介绍如何使用Chrome浏览器注册并登录起点中文网账号,通过安装browsercookie和pycryptodome库来获取网站的cookie,进而实现自动化操作,如访问个人书架等功能。
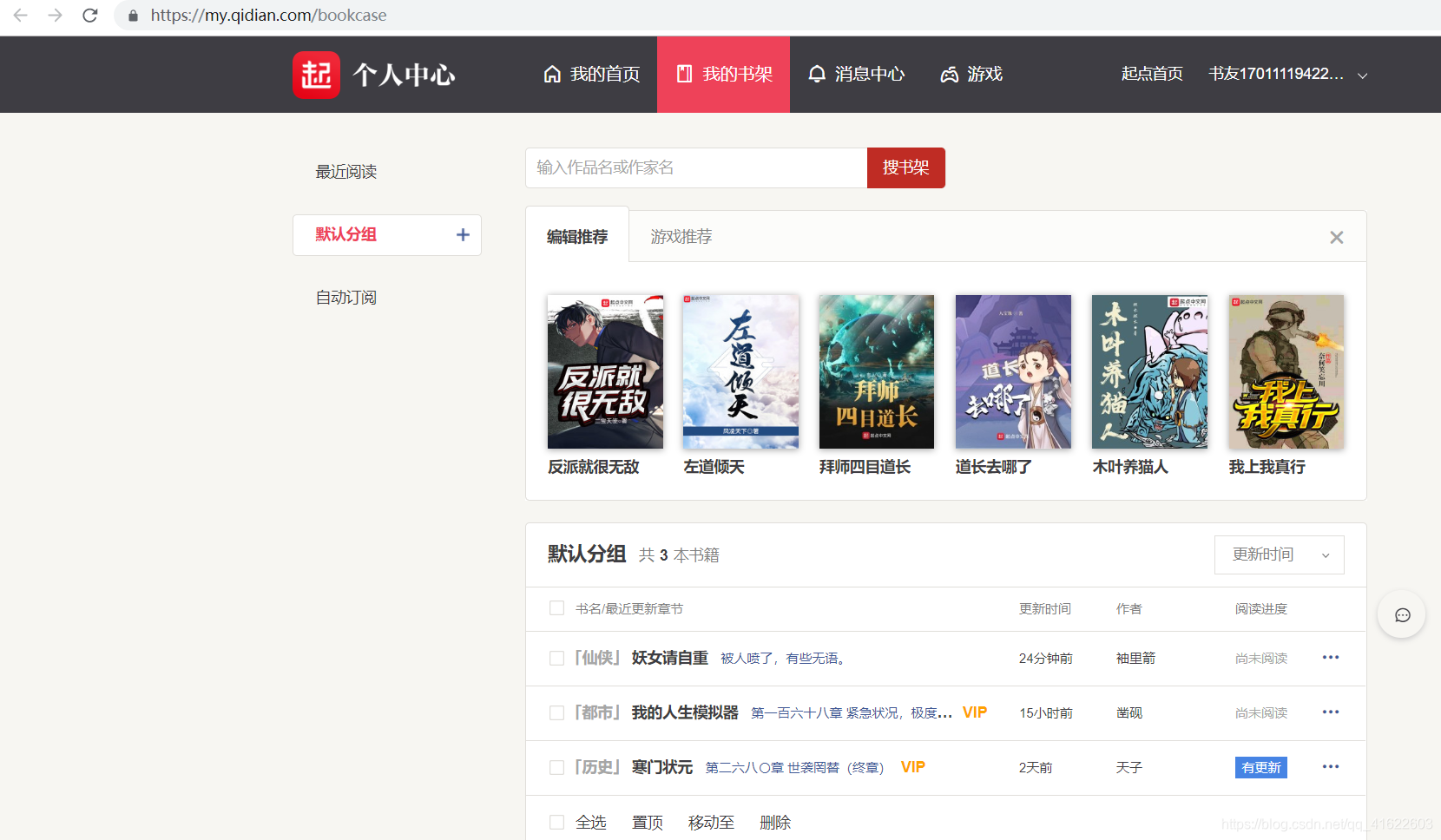
首先要注册一个起点中文网账号,并通过Chrome浏览器登录上去(登陆前勾选自动登陆),访问我的书架页面,如下图
1.安装browsercookie和依赖库
pip install browsercookie
pip install pycrptodome
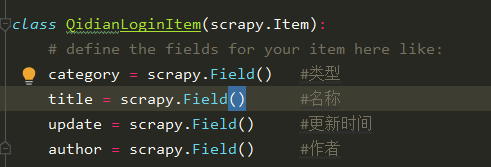
2.items.py里封装需要获取的数据
*3.获取浏览器中起点中文网的cookie
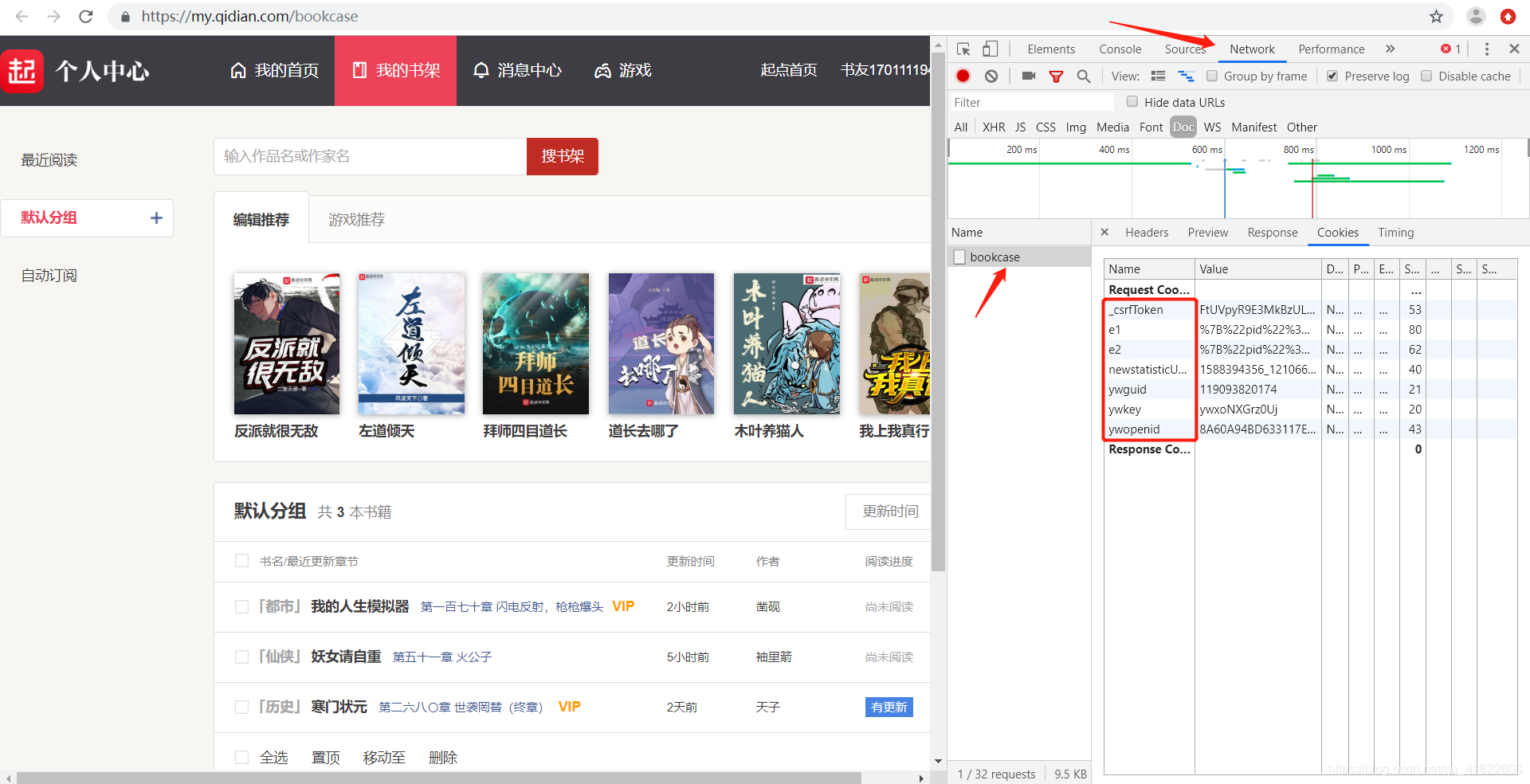
(1)找到需要的cookie的name
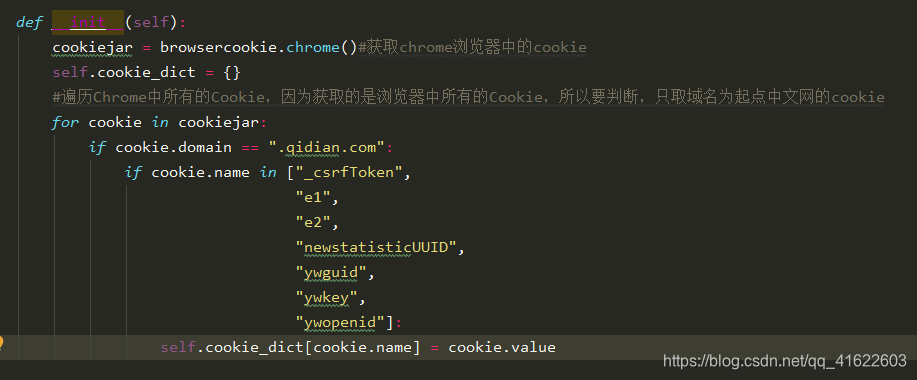
(2)把需要用到的name值保存到字典里
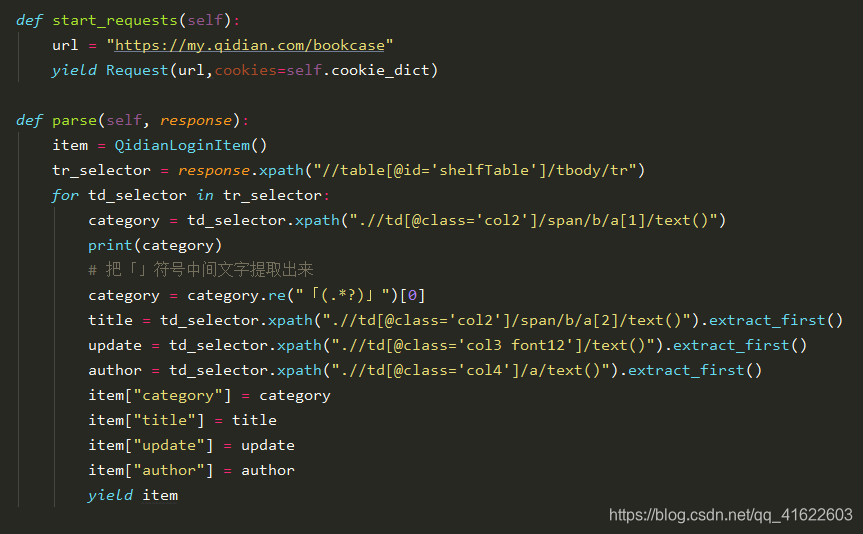
4.请求和解析数据

首先要注册一个起点中文网账号,并通过Chrome浏览器登录上去(登陆前勾选自动登陆),访问我的书架页面,如下图
pip install browsercookie
pip install pycrptodome
(1)找到需要的cookie的name
(2)把需要用到的name值保存到字典里
 215
1万+
6128
215
1万+
6128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























