







1、 随机梯度下降法
参考:自己的决策树和随机森林的部分代码
批梯度下降法(Batch Gradient Descent ),小批梯度下降 (Mini-Batch GD),随机梯度下降 (Stochastic GD)
1、梯度下降最常见的三种变形 BGD,SGD,MBGD,这三种形式的区别就是取决于我们用多少数据来计算目标函数的梯度。
#coding:utf-8
#设损失函数 loss=(w+1)^2, 令w初值是常数5。反向传播就是求最优w,即求最小loss对应的w值
import tensorflow as tf
#定义待优化参数w初值赋5
w = tf.Variable(tf.constant(5, dtype=tf.float32))
#定义损失函数loss
loss = tf.square(w+1)#tf.square()是对a里的每一个元素求平方
#定义反向传播方法
train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)
#生成会话,训练40轮
with tf.Session() as sess:
init_op=tf.global_variables_initializer()#初始化
sess.run(init_op)#初始化
for i in range(40):#训练40轮
sess.run(train_step)#训练
w_val = sess.run(w)#权重
loss_val = sess.run(loss)#损失函数
print ("After %s steps: w is %f, loss is %f." % (i, w_val,loss_val))#打印



2、带动量的梯度下降法代码解析
import numpy as np
def BatchGradientDescentM(x, y, step=0.001, iter_count=500, beta=0.9):
length, features = x.shape #获取X的尺寸
# 初始化参数和动量以及整合 x'
data = np.column_stack((x, np.ones((length, 1))))#X里面多增加一列常数
w = np.zeros((features + 1, 1))#初始化权重
v = np.zeros((features + 1, 1))#初始化动量
# 开始迭代
for i in range(iter_count):
# 计算动量
v = (beta * v + (1 - beta) * np.sum((np.dot(data, w) - y) * data, axis=0).reshape((features + 1, 1))) / length
# 更新参数
w -= step * v
return w
def Momentum(x, y, step=0.01, iter_count=1000, batch_size=4, beta=0.9):
length, features = x.shape
# 初始化参数和动量以及整合 x'
data = np.column_stack((x, np.ones((length, 1))))
w = np.zeros((features + 1, 1))
v = np.zeros((features + 1, 1))
start, end = 0, batch_size
# 开始迭代
for i in range(iter_count):
v = (beta * v + (1 - beta) * np.sum((np.dot(data[start:end], w) - y[start:end]) * data[start:end], axis=0).reshape((features + 1, 1))) / length
w -= step * v
start = (start + batch_size) % length #%是取余数
if start > length:
start -= length
end = (end + batch_size) % length
if end > length:
end -= length
return w
##牛顿动量
def Nesterov(x, y, step=0.01, iter_count=1000, batch_size=4, beta=0.9):
length, features = x.shape
data = np.column_stack((x, np.ones((length, 1))))
w = np.zeros((features + 1, 1))
v = np.zeros((features + 1, 1))
start, end = 0, batch_size
for i in range(iter_count):
# 先更新参数
w_temp = w - step * v
# 再计算梯度与速度
v = (beta * v + (1 - beta) * np.sum((np.dot(data[start:end], w_temp) - y[start:end]) * data[start:end], axis=0).reshape((features + 1, 1))) / length
w -= step * v
start = (start + batch_size) % length
if start > length:
start -= length
end = (end + batch_size) % length
if end > length:
end -= length
return w
if __name__=="__main__":
# 批量梯度下降
print(Momentum(x, y, batch_size=(x.shape[0] - 1)))
# 小批量梯度下降
Momentum(x, y, batch_size=5)
# 随机梯度下降
Momentum(x, y, batch_size=1)

Gamma公式展示 Γ ( n ) = ( n − 1 ) ! ∀ n ∈ N \Gamma(n) = (n-1)!\quad\forall n\in\mathbb N Γ(n)=(n−1)!∀n∈N 是通过 Euler integral
Γ ( z ) = ∫ 0 ∞ t z − 1 e − t d t . \Gamma(z) = \int_0^\infty t^{z-1}e^{-t}dt\,. Γ(z)=∫0∞tz−1e−tdt.
3、SGD+Momentum
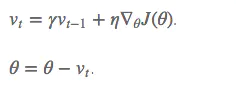
vt表示之前所有步奏积累的动量和。在梯度更新过程中,对再梯度点处具有相同方向的维度,增大其动量项,对于在梯度处改变方向的维度,减少其动量项。
dx=computes_gradient(x)
v_t=rtho*old_v-a*dx
x+=v_t
4、加速梯度下降法:Nesterov Accelerated Gradient(NAG)
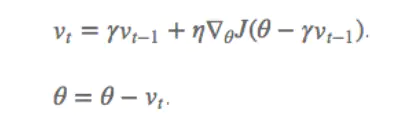

利用动量项rvt-1更新参数θ,通过计算(θ-rvt-1)得到参数未来位置的近似值,计算参数未来近似值位置的梯度。可以抽象为球滚落,一般盲目的沿着某个斜率方向,结果并不一定能令人满意,我们希望有一个较为智能的球,能够在积极判断下降的方向,这样在途中遇到斜率上升的时候能够减速。 NAG 可以使 RNN 在很多任务上有更好的表现
5、Adagrad (Adaptive gradient algorithm)、Adadelta
这个算法就可以对低频的参数做较大的更新,对高频的做较小的更新,也因此,对于稀疏的数据它的表现很好,很好地提高了 SGD 的鲁棒性,例如识别 Youtube 视频里面的猫,训练 GloVe word embeddings,因为它们都是需要在低频的特征上有更大的更新。
Adagrad其实是对学习率进行了一个约束。即:


6、Adam:Adaptive Moment Estimation
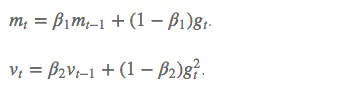
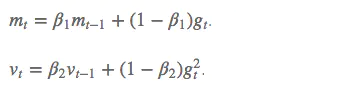
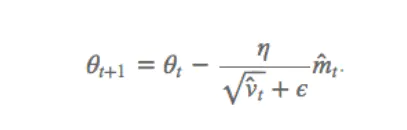


超参数设定值:
建议 β1 = 0.9,β2 = 0.999,ϵ = 10e−8
实践表明,Adam 比其他适应性学习方法效果要好。
7、如何选择优化算法
如果数据是稀疏的,就用自适用方法,即 Adagrad, Adadelta, RMSprop, Adam。
RMSprop, Adadelta, Adam 在很多情况下的效果是相似的。
Adam 就是在 RMSprop 的基础上加了 bias-correction 和 momentum,
随着梯度变的稀疏,Adam 比 RMSprop 效果会好。
整体来讲,Adam 是最好的选择。
很多论文里都会用 SGD,没有 momentum 等。SGD 虽然能达到极小值,但是比其它算法用的时间长,而且可能会被困在鞍点。
如果需要更快的收敛,或者是训练更深更复杂的神经网络,需要用一种自适应的算法。
8、二阶梯度算法
1、Hessian,牛顿法
1、凸函数
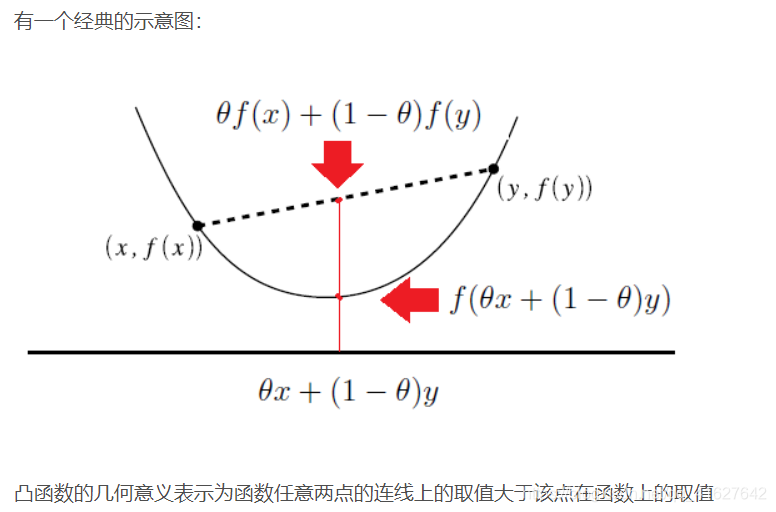
Hessian矩阵与牛顿法
上面提到了函数的二阶导数是Hessian矩阵,Hessian矩阵经常用于牛顿法优化方法中。牛顿法是一种迭代求解方法,有一阶和二阶方法,主要应用在两个方面:1、求方程的根, 2、 最优化方法

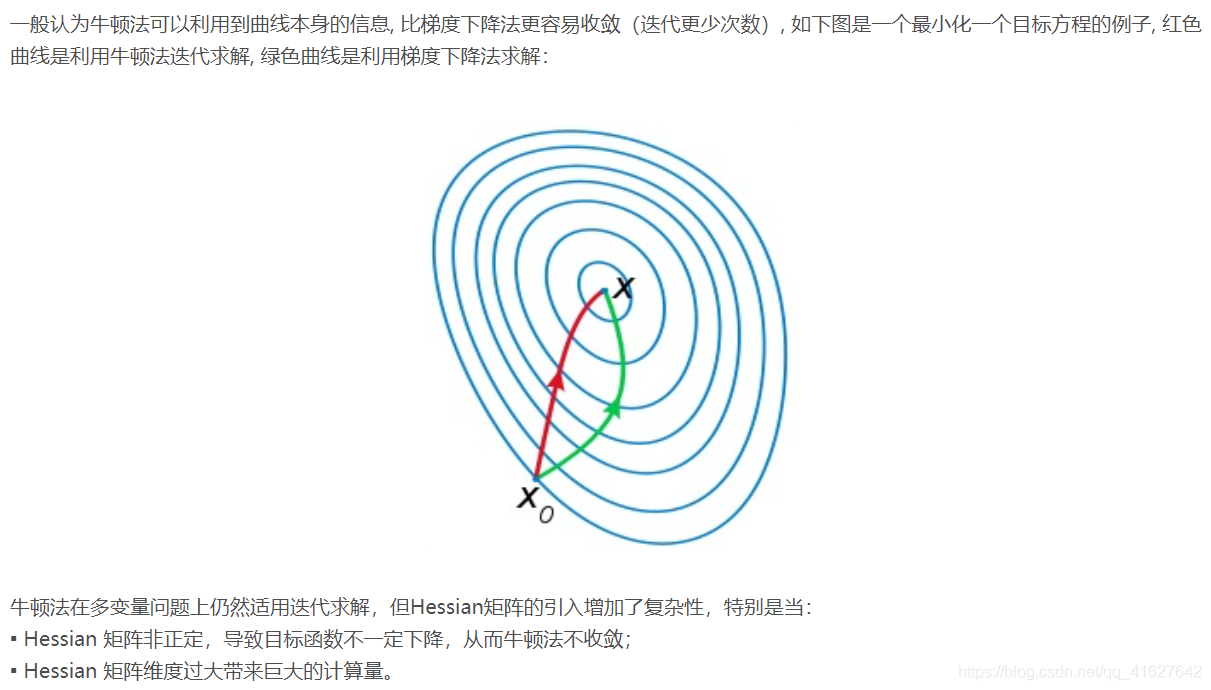
针对这个问题,在牛顿法无法有效执行的情况下,提出了很多改进方法,比如 拟牛顿法(Quasi-Newton Methods)可以看作是牛顿法的近似。拟牛顿法只需要用到一阶导数,不需要计算Hessian矩阵 以及逆矩阵,因此能够更快收敛,关于拟牛顿法这里不再具体展开,也有更深入的 DFP、BFGS、L-BFGS等算法,大家可以自行搜索学习。总体来讲,拟牛顿法都是用来解决牛顿法本身的复杂计算、难以收敛、局部最小值等问题。
论文 Second Order Optimization Made Practical
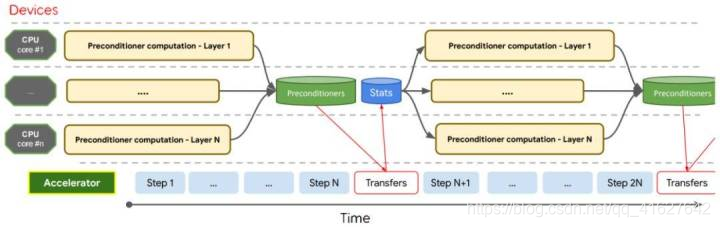
1、摘要
研究者表示,为了缩短理论和实际优化效果之间的差距,该论文提出了一种二阶优化的概念性验证,并通过一系列重要的算法与数值计算提升,证明它在实际深度模型中能有非常大的提升。具体而言,在训练深度模型过程中,二阶梯度优化 Shampoo 能高效利用由多核 CPU 和多加速器单元组成的异构硬件架构。并且在大规模机器翻译、图像识别等领域实现了非常优越的性能,要比现有的顶尖一阶梯度下降方法还要好。















 9810
9810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









