







文章目录
一、多任务编程
1、什么叫多任务
就是操作系统可以同时运⾏多个任务。
打个⽐⽅,你⼀边在⽤浏览器上⽹,⼀边在听歌,⼀边在⽤Word赶作业,这就是多任务,⾄少同时有3个任务正在运⾏。还有很多任务悄悄地在后台同时运⾏着,只是桌⾯上没有显示⽽已
2、单核CPU如何实现多任务
操作系统轮流让各个任务交替执⾏,每个任务执⾏0.01秒,这样反复执⾏下去。 表⾯上看,每个任务交替执⾏,但CPU的执⾏速度实在是太快了,感觉就像所有任务都在同时执⾏⼀样

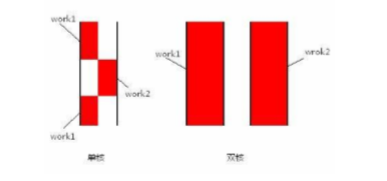
三个执行实例A,B,C在单个CPU上交替执行
逻辑上表现为三个执行实例并发执行
但实质物理上任然是串行执行
串行:一个处理完再一个
并发和并行:
并发:处理多个任务,不一定同时
例如:你正在吃饭,吃到一半电话响,去接电话,接完后继续吃饭
并行:同时处理多个任务
例如:边吃饭边打电话
3、多核CPU如何实现多任务
真正的并⾏执⾏多任务只能在多核CPU上实现,但是,由于任务数量远远多于CPU 的核⼼数量,所以,操作系统也会⾃动把很多任务轮流分配到每个核⼼上执⾏。
二、多进程编程
1、进程的创建
(1)程序和进程的区别
程序:编写完的代码,没有运行
进程:正在运⾏着的代码,需要运⾏的环境等
(2)进程的五状态模型:

创建(created)-----就绪(ready)-----运行(running)-----阻塞(waiting)-----结束(terminated)
(3)创建子进程
Python的os模块中的fork()函数,用来创建子进程
但是只能用在linux系统中

fork()函数理解:
- 执⾏到os.fork()时,操作系统会创建⼀个新的进程复制⽗进程的所有信息到⼦进程中
- 普通的函数调⽤,调⽤⼀次,返回⼀次,但是fork()调⽤⼀次,返回两次
- ⽗进程和⼦进程都会从fork()函数中得到⼀个返回值,⼦进程返回是0,⽽⽗进程中返回⼦进程的 id号
多进程中,每个进程中所有数据(包括全局变量)都各有拥有⼀份,互不影响
import os
import time
print('当前进程的pid:',os.getpid()) # 就是这个.py文件
print('当前进程的父进程pid:',os.getppid()) # 实在pycharm中运行的,父进程id就是pycharm的id
money = 100
p = os.fork() # fork函数有两个返回值:1.返回0 2.返回子进程的id
if p == 0:
money = 200
print('这是子进程返回的信息,子进程的id为:',os.getpid())
print('子进程中的money:',money) # 200
else:
print('这是父进程返回的信息,返回子进程id:%s,父进程id:%s' %(p, os.getppid()))
print('父进程中的money:',money) # 100 子进程中修改变量,不会影响父进程的内容2、多进程编程
Windows没有fork调⽤,由于Python是跨平台的, multiprocessing模块就是跨平台版本 的多进程模块。
multiprocessing模块提供了⼀个Process类来代表⼀个进程对象。
Process([group [, target [, name [, args [, kwargs]]]]])
target:表示这个进程实例所调⽤对象;就是进程要执行的内容
args:表示调⽤对象的位置参数元组;
kwargs:表示调⽤对象的关键字参数字典;
name:为当前进程实例的别名;
group:⼤多数情况下⽤不到;
Process类常⽤⽅法:
is_alive() : 判断进程实例是否还在执⾏;
join([timeout]) : 是否等待进程实例执⾏结束,或等待多少秒;
start() : 启动进程实例(创建⼦进程);
run() : 如果没有给定target参数,对这个对象调⽤start()⽅法时,就将执 ⾏对象中的run()⽅法;
terminate() : 不管任务是否完成,⽴即终⽌;
Process类常⽤属性:
name:当前进程实例别名,默认Process-N,N为从1开始计数;
pid:当前进程实例的PID值
多进程编程方法一:实例化对象
from multiprocessing import Process
import time
def task1():
print('正在听音乐。。。')
time.sleep(0.5)
def task2():
print('正在编程。。。')
time.sleep(1)
def no_multi():
for i in range(2):
task1()
for i in range(5):
task2()
def use_multi():
processes = [] # 列表里存放子进程
for i in range(2):
p = Process(target=task1)
p.start()
#p.join() # 但是也不能直接写在这里,这样就和不用多进程一样了,一个一个的执行
processes.append(p)
for i in range(5):
p = Process(target=task2)
p.start()
#p.join()
processes.append(p)
# 所有子进程任务创建好后,等待每一个进程的任务结束
#[process.join() for process in processes]
for process in processes:
process.join()
if __name__ == '__main__':
start_time = time.time()
#no_multi() # 6.0704591274261475
use_multi() # 1.2190418243408203
end_time = time.time()
print(end_time - start_time )对于join() 方法的理解:
- 在主进程的任务与子进程的任务彼此独立的情况下,
主进程的任务先执行完毕后,主进程还需要等待子进程执行完毕,然后统一回收资源。 - 如果主进程的任务在执行到某一个阶段时,需要等待子进程完毕后才能继续执行,
就需要有一种机制能够让主进程检测子进程是否运行完毕,
在子进程执行完毕后才继续执行,否则一直在原地阻塞,这就是join方法的作用。
join()的作用:
在进程中可以阻塞主进程的执行, 直到等待子线程全部完成之后, 才继续运行主线程后面的代码
例如:
# 写一个简单的
def use_multi():
p1 = Process(target=task1)
p2 = Process(target=task2)
p1.start()
#p1.join() # 如果写在这里,就是执行一个等待一个,
# 等p1进程结束后,才能向下执行,也就是相当于一条一条执行,没有用到多进程
p2.start()
p1.join() # 等待p1进程执行结束
p2.join() # 等待p2进程执行结束
# 其实此时的p1,p2是在同时进行,他俩都start开启了,等待他们结束的时间是最长进程的那个时间
# 就不是在一个一个等了,一起等多进程编程方法二:创建子类,继承的方式
就是重写run() 方法,run()方法里就是要执行的任务
from multiprocessing import Process
import time
class myprocess(Process):
""" 创建自己的进程,父类是Process"""
""" 当任务需要传参数时,在这里写"""
def __init__(self,music_name):
super(myprocess,self 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









