







四台主机间的Hadoop高可用安装详细步骤,已搭建成功(基于Linux CentOS 6.5)
前言
(从零开始,此为VMware虚拟机下的Linux CentOS 6.5安装的Hadoop2.6.5以及这半个月来的踩坑记录~)
以下操作均在已装配好四台Centos Linux之后,并且可以ping 通外网以及四台主机之间的连接。
什么是Hadoop高可用(HA)?
Hadoop是一个开源的框架,可编写和运行分布式应用处理大规模数据,是专为离线和大规模数据分析而设计的 。
在HADOOP1.0时代,整个集群中仅有一台NameNode结点,如果该结点丢失或数据发生损坏,会对整个集群造成不可恢复的损失,为了解决这一问题,社区研发出了SecondaryNamenode用以备份NameNode中的元数据,然而使用该组建后,当集群发生损坏时,集群恢复工作的时间相当缓慢,并不能满足商业上的使用。
在HADOOP2.0时代,社群重新定义了NameNode的设计层级,改用Service来对集群进行管理。Hadoop HA使用多个NameNode组成一个服务,每一个服务中有两台或以上的NameNode,NameNode们的功能完全一致,但是同一时间仅有一台处于Active状态,其他处于Standby状态,当Active集群发生故障时,能在秒级时间内进行切换。
一、Hadoop部署
HA安装方案

如果机器数量紧缺,可使用如下方法:
- 可以只用3个Zookeepr和JournalNode。
- Slave可以和NameNode部署在同一结点 。
- 但两台Namenode和Resourcemanager须分开。
二、安装jdk、Hadoop,并配置环境
准备安装包工具集:
点此百度云下载,提取码:nt9d
1. 分发jdk。分别执行以下命令,指在当前目录下将文件jdk-7u67-linux-x64.rpm发送到到node2、node3、node4的当前目录下。
scp jdk-7u67-linux-x64.rpm node3:`pwd`
scp jdk-7u67-linux-x64.rpm node4:`pwd`
scp jdk-7u67-linux-x64.rpm node5:`pwd`
并在Xshell的全部会话栏里输入ll,看jdk是否发送成功。或也可以直接用Xftp拷贝文件到其他三台的目录里。
2. 分别在node3、4、5上执行rpm安装命令
rpm -i jdk-7u67-linux-x64.rpm
3.配置环境
vi + /etc/profile # 从末行编辑
(在vi编辑器里按i编辑按Esc键退出编辑模式保存并退出输入命令:wq)
然后分别修改JAVA_HOME和PATH
(或也可以用Xftp打开此目录直接文本编辑并保存)
export JAVA_HOME=/usr/bin/java
export PATH=$PATH:$JAVA_HOME/bin
重新执行刚修改的初始化文件,使之立即生效
source /etc/profile
4.在node03上cd /etc,在此目录下把profile文件分发到node2、3、4上。
scp profile node04:`pwd`
利用Xshell全部会话栏,source /etc/profile
利用Xshell全部会话栏,jps,看2、3、4这三台机子的jdk是否装好。
三、ssh免密码登陆
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa # 以DSA方式生成密钥放在.ssh/id_dsa,需要密码
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys # 将每个节点的公钥发送到 其他节点,每个节点的id_rsa.pub分别导入authorized_keys
vi /etc/ssh/sshd_config # 修改配置文件
service sshd restart # 重启服务
ssh (主机名/ip) # 免密测试
四、同步所有主机的时间
date # 查看当前时间
如果不同步,则
- yum 进行时间同步器的安装
yum -y install ntp
- 执行同步命令 (和阿里云服务器时间同步)
ntpdate time1.aliyun.com
五、配置文件
cd /opt/cjt/hadoop-2.6.5/etc/hadoop #进入到Hadoop的安装目录
(使用vi\vim编辑器或者直接替换文本文件皆可)
1. hdfs-site.xml的配置:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/cjt/hadoop/ha/jn</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
配置core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>
</configuration>
2. core-site.xml的配置
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>
</configuration>
3.
hadoop-env.sh
mapred-env.sh
yarn-env.sh
最后依次修改上面三个.sh文件中的JAVA_HOME,等于号后面都改成绝对路径,这里是/usr/java/jdk1.7.0_67
4.配置slaves文件
这里写装有DataNode的主机名:
node2
node3
node4
六、安装与配置Zookeeper
这里需要将Zookeeper安装在node2、node3和node4三台主机上,先在node2上操作:
1. 解压安装zookeeper
tar xf zookeeper-3.4.6.tar.gz -C /opt/cjt
2. 修改zookeeper的配置文件
cd /opt/cjt/zookeeper-3.4.6/conf
3. 给zoo_sample.cfg改名
cp zoo_sample.cfg zoo.cfg
4. 配置zoo.cfg文件
修改为:
dataDir=/var/cjt/zk
并在末尾追加:
server.1=node2:2888:3888
server.2=node3:2888:3888
server.3=node4:2888:3888
其中2888主从通信端口,3888是当主挂断后进行选举机制的端口
5. 将Zookeeper发送到其他结点
scp -r zookeeper-3.4.6/ node3:`pwd`
scp -r zookeeper-3.4.6/ node4:`pwd`
发送完可以用 ll /opt/cjt 敲回车检查是否分发成功了。
6. 创建刚配置文件中的路径
给每台机子创建刚配置文件里的路径 mkdir -p /var/cjt/zk
node2:
echo 1 > /var/cjt/zk/myid
cat /var/cjt/zk/myid
node3:
echo 2 > /var/ cjt /zk/myid
cat /var/ cjt /zk/myid
node4:
echo 3 > /var/ cjt /zk/myid
cat /var/ cjt /zk/myid
7. 在/etc/profile里面配置
片段如下(目的是在PATH中追加了:$ZOOKEEPER_HOME/bin):
export ZOOKEEPER_HOME=/opt/cjt/zookeeper-3.4.6
export PATH=$PATH:/usr/java/jdk1.7.0_67/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin
(注意:Linux中分隔是 : 和 /)
8. 然后在把/etc/profile分发到其他node3、node4
scp /etc/profile node3:/etc
scp /etc/profile node4:/etc
在node2、3、4全部命令里
source /etc/profie
这步千万别忘!可免重新登录
验证source这句是否完成,输入zkCli.s,按Tab可以把名字补全zkCli.sh即可。
9. 启动zookeeper
全部会话:zkServer.sh start
接着用 zkServer.sh status 查看每个zookeeper节点的状态
Tips:如果不能启动,把/etc/profile里的JAVA_HOME改
成绝对路径。
10. 启动JournalNode
目的是为了使两台namenode间完成数据同步
在node2、3、4三台机子上分别把JournalNode启动起来
hadoop-daemon.sh start journalnode
用命令 jps 检查进程是否启动了
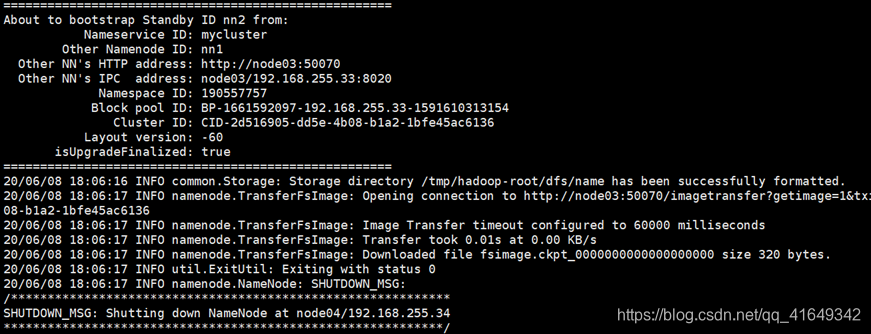
七、给另一台NameNode同步数据
我们要给另一台namenode同步一下数据,用以下命令
hdfs namenode -bootstrapStandby
八、格式化ZKFC
1. 执行命令
hdfs zkfc -formatZK
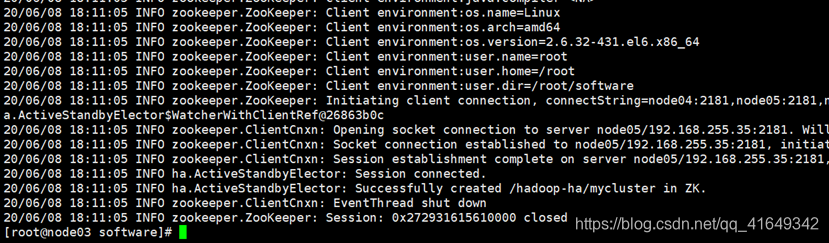
在node2上执行 zkCli.sh 打开Zookeeper客户端看Hadoop-HA是否打开

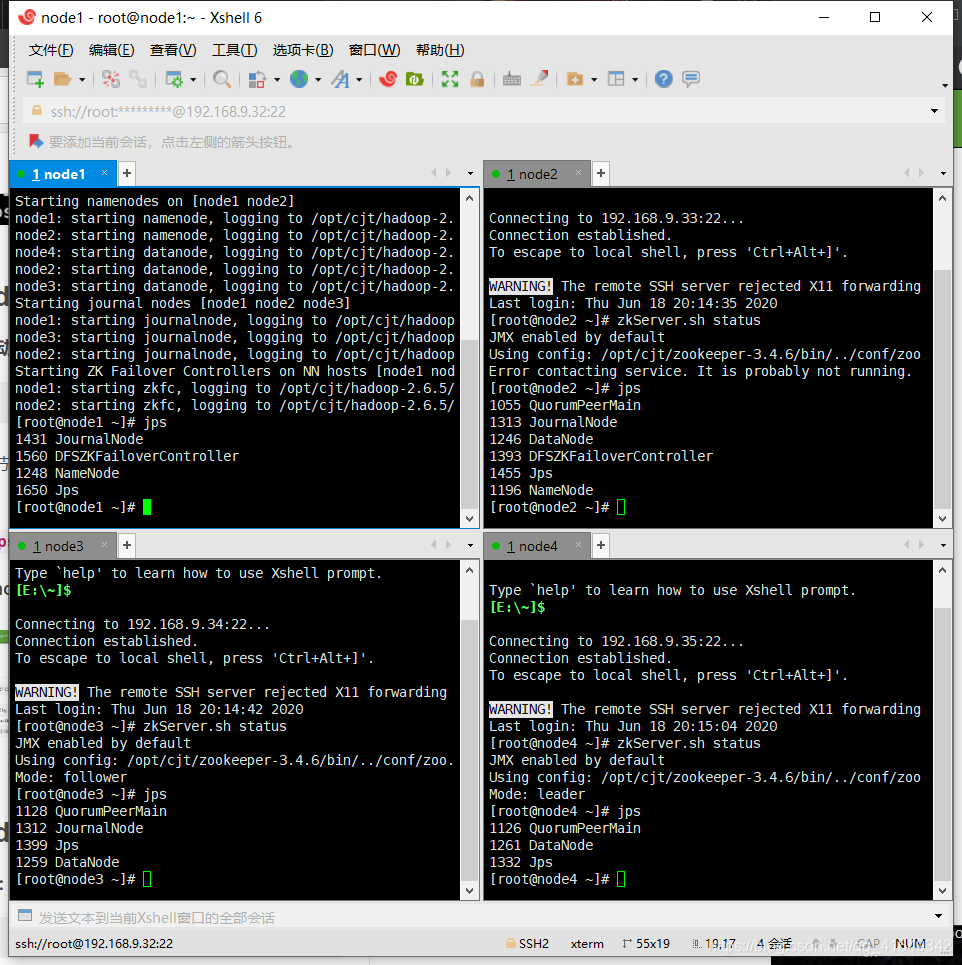
九、启动hdfs集群
1. 在node1上启动hdfs集群:
start-dfs.sh
Tips:如果那个节点没起来到hadoop目录下去看那个node的日志文件log
2. 用全部命令 jps 查看已启用的进程:
3.用浏览器访问node1:50070和node2:50070
node1截图:
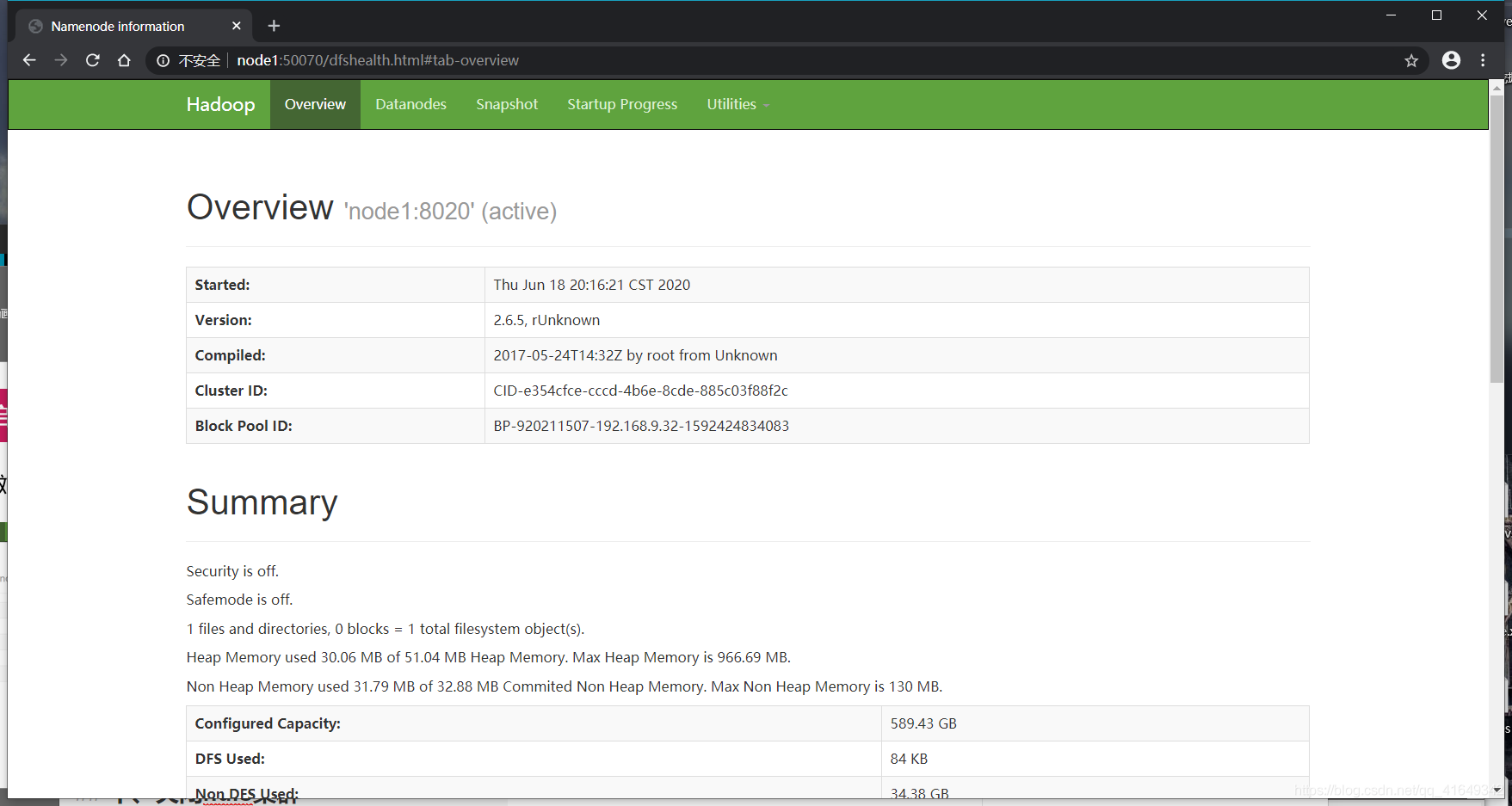
node2截图: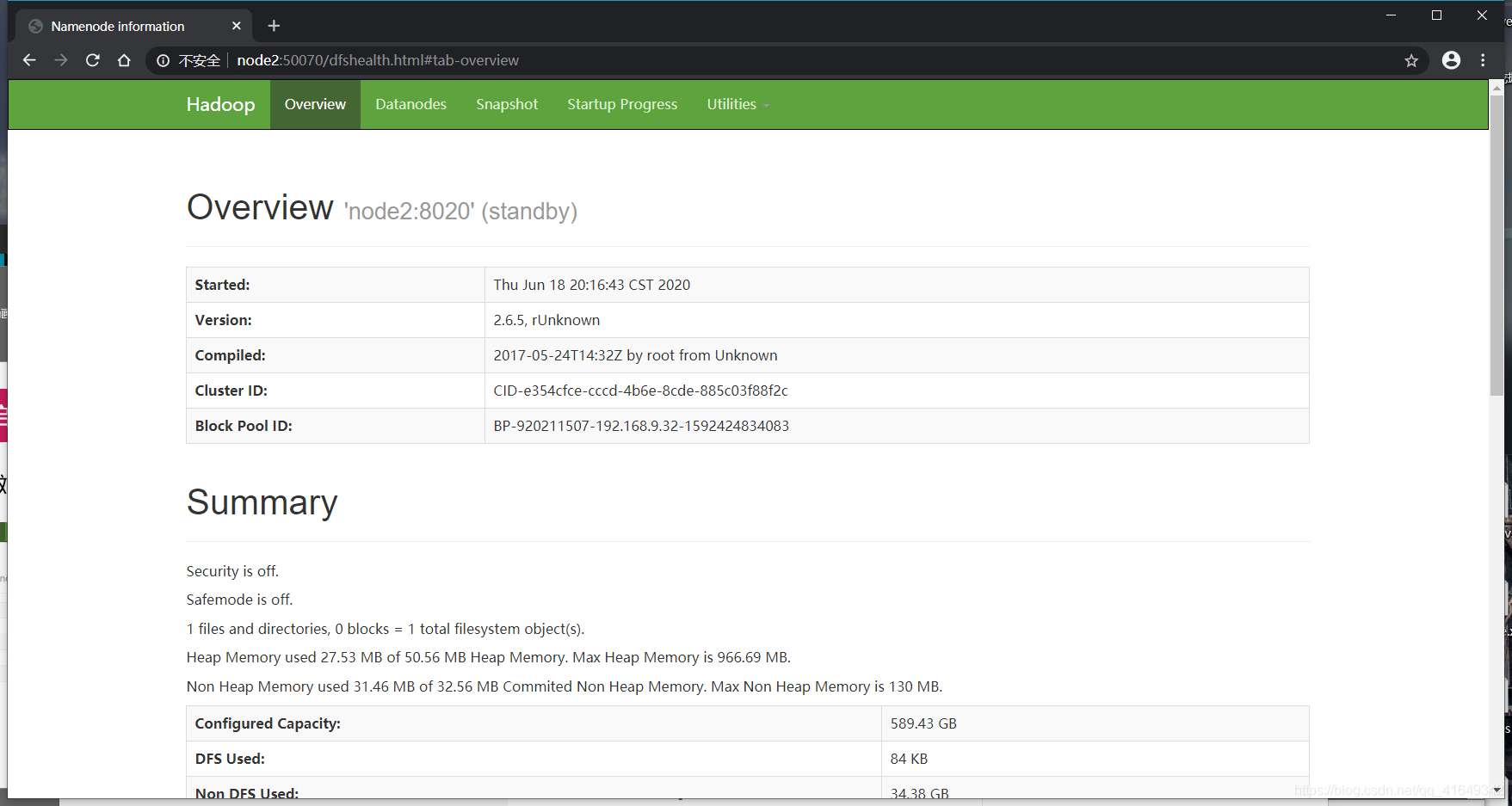
十、关闭hdfs集群
1. 关闭集群命令:
stop-dfs.sh
2. 关闭zookeeper命令:
zkServer.sh stop
十一、为MapReduce做准备
1. 把mapred-site.xml.template留个备份,并重命名
(这样保险起见,当然也可以直接改)
cp mapred-site.xml.template mapred-site.xml
2. 在mapred-site.xml里添加如下property
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3. 先在node1的Hadoop目录下配置yarn-site.xml中的<configuration></configuration>体中添加如下property:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node3</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node4</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>
4. 分别分发mapred-site.xml和yarn-site.xml 到node2、3、4当前目录下
scp mapred-site.xml yarn-site.xml node2:`pwd`
scp mapred-site.xml yarn-site.xml node3:`pwd`
scp mapred-site.xml yarn-site.xml node4:`pwd`
5. 由于node3和node4都是ResourceManager,所以它俩应该相互免密钥
(一)node3上免密钥登录node4:
在node3的.ssh目录下生成密钥
ssh-keygen -t dsa -P '' -f ./id_dsa
并追加到自己authorized_keys
cat id_dsa.pub >> authorized_keys
用ssh localhost验证看是否需要密码,登录成功后别忘了 exit
将node3 的公钥分发到nod4
scp id_dsa.pub node4:`pwd`/node3.pub
在node4的.ssh目录下,追加node3.pub
cat node3.pub >> authorized_keys
在node3上 ssh node4 ,试验是否可免密钥了
(二)同理,实现node4上免密钥登录node3:
在node4的.ssh目录下生成密钥
ssh-keygen -t dsa -P '' -f ./id_dsa
并追加到自己authorized_keys
cat id_dsa.pub >> authorized_keys
用ssh localhost验证看是否需要密码,登录成功后别忘了 exit
将node4 的公钥分发到node3
scp id_dsa.pub node3:`pwd`/node4.pub
在node3的.ssh目录下,追加node4.pub
cat node4.pub >> authorized_keys
在node4上 ssh node3 ,试验是否可免密钥了
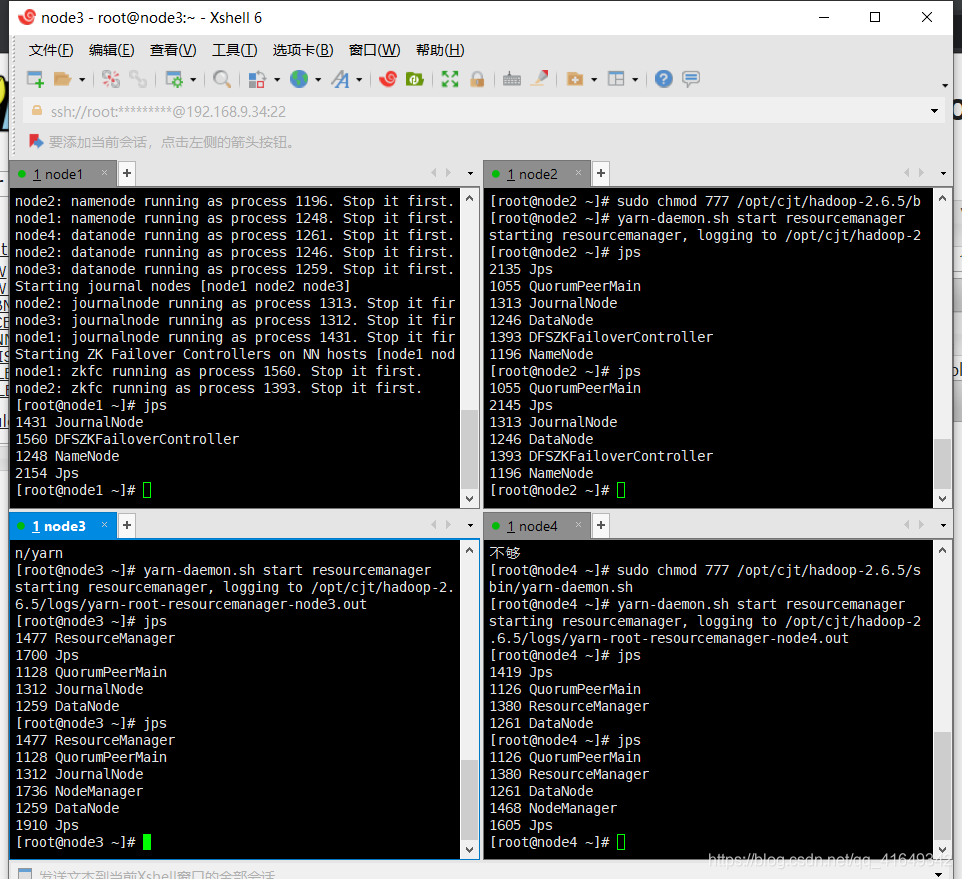
7 .启动
- 启动zookeeper,全部会话:
zkServer.sh start - 在node1上启动hdfs:
start-dfs.sh - 在node1上启动yarn:
start-yarn.sh - 在node3、4上分别启动ResourceManager,
yarn-daemon.sh start resourcemanager
5.全部会话 jps ,检查已启动的进程全不全
8. 在浏览器URL访问node3:8088,查看ResourceManager管理的内容**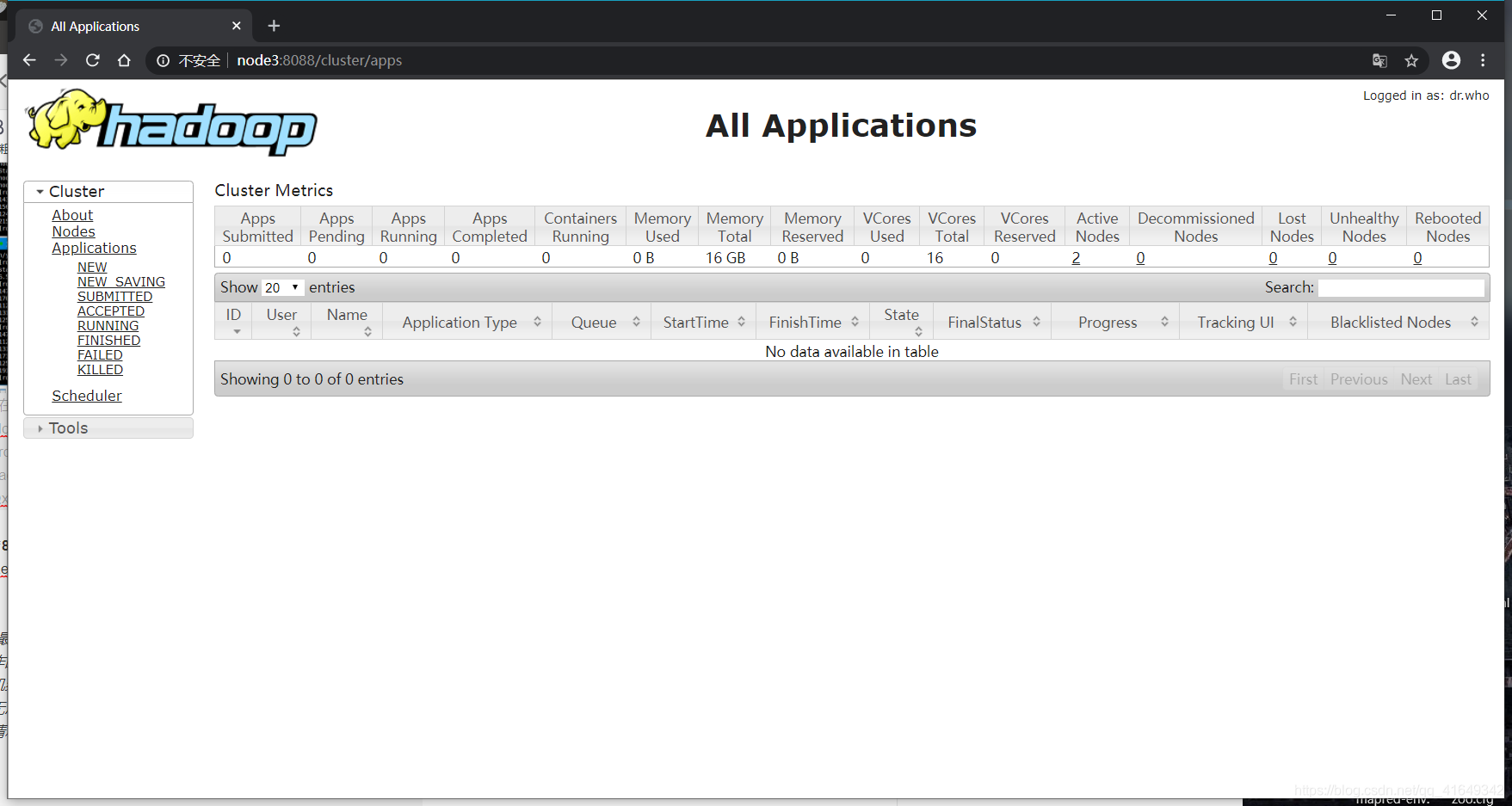
跑个Wordcount试试:
1.cd /opt/cjt/hadoop-2.6.5/share/hadoop/mapreduce
2.在hdfs里建立输入目录和输出目录
hdfs dfs -mkdir -p /data/in
hdfs dfs -mkdir -p /data/out
3.将要统计数据的文件上传到输入目录并查看
hdfs dfs -put ~/Baby.txt /data/in
hdfs dfs -ls /data/in
- 运行wordcount:
(注意:此时的/data/out必须是空目录)
hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /data/in /data/out/result
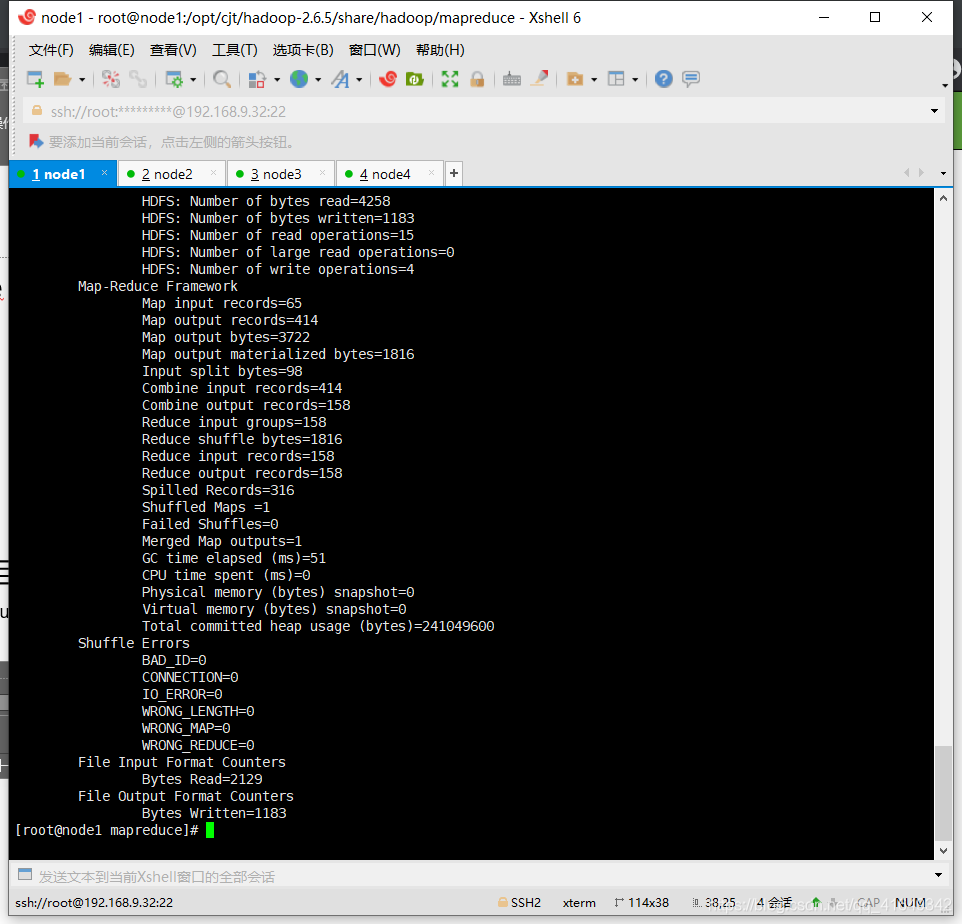
问题出现的解决措施:
1.启动进程时候经常会出现permission denied(权限不够)的问题,sudo chmod 777 /后面加提示进程权限不够的路径,例如sudo chmod 777 /opt/cjt/hadoop-2.6.5/sbin/yarn-daemon.sh ,多回车几次就可以。
2.我发现大多数人都能碰到VMware经常莫名黑屏无法操作的情况,根治办法就是 编辑→首选项→设备,启用虚拟打印机给勾上,这样虚拟机就不会一直因为找不到外设而卡在那里无法操作了,删lck文件等操作只是负责因强制关闭而打不开的情况*
注:本系列为大数据开发课程Hadoop学习笔记,部分取自课堂。初步学习过程中难免会疏漏或表述不当之处,还请予指正!














 4102
4102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









