







Regarding neural network parameters as relation embeddings for knowledge graph completion
关于神经网络参数作为知识图完成的关系嵌入
发表于:The Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI-20)
摘要:我们研究知识图中学习实体和关系嵌入的任务,以预测缺失的链接。先前关于链接预测的平移模型利用平移特性但缺乏足够的表达能力,而基于卷积神经网络的模型(ConvE)利用了神经网络的巨大非线性拟合能力,但忽略了平移特性。在本文中,我们提出了一种新的知识图嵌入模型ParamE,它可以一起利用这两个优点。在ParamE中,头实体嵌入,关系嵌入和尾实体嵌入分别被视为神经网络的输入,参数和输出。由于网络中的参数可以有效地将输入转换为输出,因此将神经网络参数作为关系嵌入使得参数更具表达性和平移性。另外,ParamE中的实体和关系嵌入分别来自特征空间和参数空间,这与实体和关系被映射到两个不同空间的本质是一致的。我们评估了ParamE在标准FB15k-237和WN18RR数据集上的性能,实验表明ParamE可以显着优于现有的最先进模型,如ConvE,SACN,RotatE和D4-STE/Gumbel。

在ParamE中,头实体嵌入,关系嵌入和尾实体嵌入被视为神经网络的输入,参数和输出。所提出的模型变得更加表达和翻译,因为参数在将输入转换为输出方面做得很好。关于神经网络参数,关系嵌入可以帮助头实体嵌入和关系嵌入具有更多层次的交互。在图1中,我们将ParamE与ConvE进行比较。头部实体和关系在ConvE中一起馈入神经网络,但是ParamE将关系视为传递函数参数而不是输入。
模型的主要思想是将神经网络参数视为关系嵌入,这使得ParamE具有表达性和平移性。除了神经网络参数之外,架构还在神经网络的性能中起着重要作用。为了确认ParamE是否是不同体系结构的通用体系结构,我们实现了具有三种不同体系结构的ParamE:多层感知器,卷积层和门结构层,称为ParamE-MLP,ParamECNN,ParamE-gate。在本节中,我们将介绍三个参数模型。
ParamE-MLP
多层感知器,也称为前馈神经网络,是典型的深度学习方法。前馈网络定义映射Y=f(h;r)并学习导致最佳函数近似的参数的值,其中h表示输入。在ParamE-MLP中,h是头实体嵌入,r是关系嵌入,y是头实体嵌入和关系嵌入的交互结果。接下来,y与所有实体嵌入具有相似性匹配,并且我们期望y和尾部实体嵌入的匹配获得最高分数。
具体而言,参数MLP使用三层前馈神经网络。整个过程如下所示:
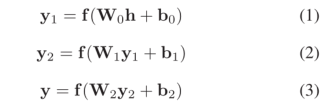
W0,W1,W2分别是第一,第二,第三隐藏层的权重;b0,b1,b2分别是第一,第二,第三隐藏层的偏差;d是嵌入维度,d1,d2,d3是第一,第二,第三隐藏层的维度,f表示非线性函数。
以三元组(Chatou,isLocatedIn,France)为例,头部实体(Chatou)的嵌入为h,关系的嵌入(isLocatedIn)是由以下组成的集合:W0,W1,W2,b0,b1,b2;然后得到y,将头实体嵌入和关系嵌入的交互结果y投影到嵌入维度中,并通过内积与尾实体t(France)的嵌入具有相似性,其得分函数为:
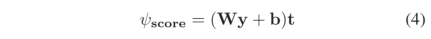
ParanE-CNN
在ParanE-CNN中,首先将嵌入h的头部实体重塑为矩阵,然后矩阵与两个卷积层相互作用,关系嵌入r是卷积层权重的集合。具体过程如下:
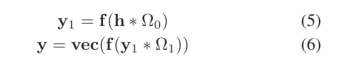
Ω0∈Rl1×1×n1×n2表示第一卷积层的参数,l1是输出通道的数量,k1和k2是卷积核的大小;Ω1∈Rl2×l1×n3×n4表示第二卷积层的参数,l1表示输入通道的数量,l2表示输出通道的数量,k3和k4表示卷积核的大小;f是激活功能;将张量重塑为向量的运算向量,∗ 代表卷积操作。
在三元组(Chatou,isLocatedIn,France)中,头部实体(Chatou)的嵌入是h,关系isLocatedIn的嵌入是Ω0和Ω1的集合。随后的投影层和相似性匹配与参数MLP相似。
ParamE-Gate
在参数门中,h仍然表示头实体嵌入,并且使用一个门结构来过滤信息,具体信息流如下:
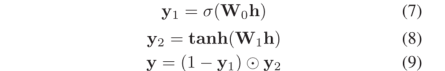
σ是sigmoid函数,W0,W1为权重。对于三元组(Chatou,isLocatedIn,France),实体(Chatou)嵌入是h,关系(isLocatedIn)嵌入是W0,W1的集合。在等式7中,S形操作将y1中的每个元素设置为0和1之间。然后在等式9中,(1−y1)是门,控制y2允许通过多少信息。随后的投影层和相似性匹配也与参数MLP相似
虽然ParamE MLP,ParamE CNN,ParamE Gate具有不同的网络体系结构,但它们的主要思想是相同的,即将神经网络参数视为关系嵌入。它们可以用以下评分函数进行总结:
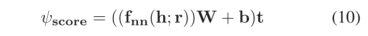
其中fnn表示神经网络,ParamE-MLP对应于多层感知器,ParamE-CNN对应于卷积层,ParamE-Gate对应于门结构层,未来可以探索更多的网络架构,h是头部实体嵌入和输入到神经网络,r是关系嵌入和神经网络参数,W是投影层的参数,t是尾部实体嵌入。
在得到真三元组和假三元组的分数之后,我们使用sigmoid函数σ(·)将每个分数设置在0和1之间,这可以表示为
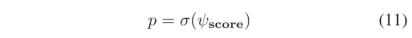
损失函数是二元交叉熵损失,与ConvE相同。整个信息流过程如图2所示

ParamE说明:以三元组(Chatou,isLocatedIn,France)为例,在ParamE中,网络首先加载关系嵌入(isLocatedIn)作为其参数,然后将头实体嵌入(Chatou)馈入网络,并将输出矢量化并通过线性层投影到嵌入维度。然后,结果与所有实体嵌入进行矩阵乘法以获得logits。最后,在logit上的sigmoid函数之后生成分数。
由于参数是基于关系的,因此训练过程与以前的模型不同,并且参数是按关系训练的。我们首先根据关系类型将三元组划分为不同的组,换句话说,一组中的三元组具有相同的关系。然后,我们计算每组中三元组的数量与所有三元组的数量之比,并且训练过程是逐组的。对于一个纪元,迭代次数为n,批量大小为b。在一个时期进行训练时,我们根据每组的比例随机选取一组进行训练,一个时期的选择次数为n。对于一次迭代,我们从相应的组中随机选择b个三元组作为输入,并且网络加载关系嵌入作为其参数。经过一次迭代训练后,网络参数将被保存用于下一次加载。
链接预测实验结果:

个人总结:这篇文章应该说是大道至简,用简单粗暴的方法取得了还不错的效果,本文算是在ConvE的思想上进行的延伸,不过其训练过程需要将同一关系的三元组放在一起进行训练,对于三元组较少的关系的泛化性能是未知的。
















 691
691











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









