






标题测试用例8要素
- 用例编号
- 用例标题
- 用例级别
- 测试项目
- 测试输入
- 预置条件
- 执行步骤
- 预期结果
测试用例的设计方法?
1、等价类划分法;2、边界值分析法;3、错误推测法;4、判定表法;5、正交实验法;6、场景图法;7、正交实验设计法;8、错误推测法。
-
等价类划分法
- 等价类可以分为有效等价类和无效等价类; 如:有效的等价1=1;无效的等价1=2;
边界值分析法
这种方法专注于输入或输出范围的边界,选择正好等于、刚刚大于、刚刚小于边界的值作为测试用例;
- 等价类可以分为有效等价类和无效等价类; 如:有效的等价1=1;无效的等价1=2;
-
错误推测法
- 依靠经验或直觉推测程序中可能存在的错误,并针对性地设计测试用例来揭露这些错误
-
判定表法
- 适用于逻辑判断复杂的场景
-
正交实验法
- 通过设计特殊的表格(正交表),在各因素互相独立的情况下,用较少的测试用例覆盖全面的测试范围。正交表的特征是“均匀分布,整齐划一”
-
场景图法(流程图)
- 现在的软件几乎都是用事件触发来控制流程的,事件触发时的情景便形成了场景,而同一事件不同的触发顺序和处理结果就形成事件流。这种在软件设计方面的思想也可以引入到软件测试中,可以比较生动地描绘出事件触发时的情景,有利于测试设计者设计测试用例,同时使测试用例更容易理解和执行。场景法是基于软件业务的测试方法,测试人员把自己当成最终用户,尽可能真实地模拟用户在使用此软件的操作情形。
-
正交实验设计法
- 正交试验设计法(Orthogonal Experimental Design)是从大量的试验点中挑选出适量的、有代表性的点,应用依据伽罗瓦理论导出的“正交表”,合理地安排试验的一种科学的试验设计方法,是研究多因素、多水平的一种设计方法。它是根据正交性从全面试验中挑选出部分有代表性的点进行试验,这些有代表性的点具备“均匀分散、齐整可比”的特点,正交试验是一种基于正交表的,高效率、快速、经济的试验设计方法。
- 正交试验分析法包括以下常用术语:
指标:通常把判断试验结果优劣的标准叫做试验的指标。
因子:是指所有影响试验指标的条件。
因子的状态:是指影响试验因子的因素,也称之为因子的水平。
- 正交试验分析法包括以下常用术语:
- 正交试验设计法(Orthogonal Experimental Design)是从大量的试验点中挑选出适量的、有代表性的点,应用依据伽罗瓦理论导出的“正交表”,合理地安排试验的一种科学的试验设计方法,是研究多因素、多水平的一种设计方法。它是根据正交性从全面试验中挑选出部分有代表性的点进行试验,这些有代表性的点具备“均匀分散、齐整可比”的特点,正交试验是一种基于正交表的,高效率、快速、经济的试验设计方法。
-
错误推测法
- 在测试程序时,人们可以根据经验或直觉推测程序中可能存在的各种错误,从而有针对性地编写检查这些错误的测试用例的方法。 这种方法没有固定的形式,依靠的是经验和直觉,很多时候,我们都会不知不觉的使用到
说一下响应行中的状态码都有哪些
- 200表示服务器返回的数据成功
- 3xx重定向
- 301永久重定向
- 302临时重定向
- 4xx客户端发生了错误
- 403 访问数据被禁止 404 页面找不到了
- 5xx 服务器出现了错误 500 服务器语法出现错误 502 服务器挂了 503无法完成数据请求
- 面试官追问:200一定是表示成功的吗?
- 回答:并不是,状态码为200 首先能确定的是该接口通了,要想表示成功的话,还得需要看返回的数据与预期结果是否一致,若一致才能表示成功。
- 面试官追问:200一定是表示成功的吗?
接口有哪些请求方式
- get post delete put(资源存放的位置)
get和post的区别
- get是以明文形式发送,post是加密的方式发送
- get传输数据会有字节限制,post没有限制
- get参数是在url后面进行拼接的,post可以支持多种格式数据是放在body中
- get要比post速度快,get一般是在提交时使用,post一般在请求时使用
- get的默认端口443,post的默认端口80
你是如何做接口的功能测试的?
我们做接口测试一般注重三个方面,分别是入参、结果、数据库所谓入参,就是先要根据接口文档确定我们要请求的 url地址,参数,响应结果 等等,将这些信息填写到postman或jmeter当中,模拟请求的发送我们还需要注意结果,也就是发送完请求之后,得到的结果,比如我要看一下我的接口的状态码是不是接口文档上的200,返回的json数据是不是和接口文档的示例数据一致,等等。
如何判断前后端的bug?
- 可以使用F12开发者工具或抓包工具,查看接口返回,如果接口响应的数据不正确,那就很可能是后端的问题,如果请求参数正确或者接口响应数据正确但是页面上显示不对,就是前端的问题。
- 使用F12开发者工具,是在Network下的All中找到所对应的接口,在Response中查看
- 使用抓包工具直接在当前接口响应体中查看校验;
- 面试题:给你一个web网站 怎么测试?
- 先测功能,全覆盖pm的需求,包含关联业务,以及一些异常的情况。
- 在测专项 我会从web网站的 效率性 兼容性 及易用性去做测试,
- 效率性主要是对网站的时间响应效率进行测试,我一般使用的是F12开发者工具在Timing中查看校验某接口的时间响应效率时间是否满足企业要求达到的指标(一般要求为不能超过1s);
- 兼容性主要包含:不同的操作系统、不同的浏览器、相同的浏览器不同的版本、不同的网络几个方面去进行测试;
- 易用性主要是对产品好不好用、使用起来的操作是否方便、界面美不美观、布局合不合理等提出一些意见性的问题;
接口文档都有哪些内容
- 正式服务器地址和测试服务器地址(url的前半部分)
- 接口名称,接口介绍,请求方式
- 入参:
- 名称,类型,是否必填,示例值,注释
- 返回值
- 状态码
- 返回的字段的名称,类型,注释
- 示例的接口地址
公司是如何做自动化的,用了什么框架,如何挑选用例?
**自动化的占比 - 20-30 **
如果说的单元测试的框架的话,我们会用 unittest,它是python自带的一个单元测试框架,主要能够解决我们多个用例的批量执行问题,我们会让测试的模块继承testcase,然后再setup中去打开浏览器/手机程序,在teardown中关闭浏览器/手机程序,还有最终就是编写test开头的方法,我们一个方法就是一个用例 我们的报告用的是一个第三方的叫做 HTMLTestRunner,只需要将运行unittest的时候使用这个runner就可以了。
```python
使用Selenium调用WebDriver代替人工测试
from selenium import webdriver
# 启动浏览器, 打开百度页面
driver = webdriver.Chrome()
url = 'https://www.baidu.com/'
driver.get(url)
# 关闭当前标签页
driver.close()
# 退出浏览器
driver.quit()
常用的元素定位方式
id
name
class_name
tag_name
link-text
partial(破手)_link_text
xpath
css
Linux基本命令
- 查看某文件的前n行
- head -n 文件名
- 默认显示10行
- 查看某文件的后n行
- tail -n 文件名
- 默认显示10行
- 一般用来看日志 tail -f 日志名.log
- 查看进程
- ps -aux | grep 要查询的程序名
- a:all 查看全部
- u:user 显示用户名
- x:查找全部进程
- 杀死进程
- 强制杀死
- kill -9 进程号(PID)
- 普通杀死进程
- kill 进程号(PID)
- 强制杀死
- cat 查看文件中的内容
- 格式:cat 文件名1 文件名2…
- grep-搜索文本中的内容
- find-查询文件
- 命令格式:find 路径 -name 文件名、目录名
- cd / 切换到系统根目录
- ls 显示当前目录
- ls -a 显示所有文件或目录(包含隐藏的文件)
- ls -l 缩写成ll 文件和目录的详情信息
- mkdir 创建子目录
- rmdir删除“空”的子目录
- rm -rf 不询问递归删除
- rm -rf * 删除所有文件
- vi/vim编辑器 Esc切换到命令行模式
- 切换到插入模式:按 i 、o、a
- :wq!保存并退出 :q!
- dd 快速删除一行
- / 查找
- r替换
- cp 复制
- mv 移动
- touch 创建文件
python相关问题
- 数字–int类
number = 1
print(number)
- 布尔值–bool类
foo = True
bar = False
- 字符串–str类
str1 = 'abc'
- 列表–list类
a = ['cui', 'zhang', 'wu', 'li' 'zhu']
1.len()函数可以获取列表的长度(列表中元素的个数),超出最大索引值会报错
2.查询
功能:访问list列表中元素值
语法:列表名[索引]
下标从0开始,最大值为len(a)-1
3.切片
语法:print(a[开始:结束:步长])
“开始”和“结束”为空的时候,默认是全选,“步长”为空时默认是1,负数是右向左取。
4.增加 append insert
append()列表后面添加元素
5.追加
extend()方法还可以在列表的末尾一次性追加另一个序列中的多个值。
6.指定位置添加
insert()指定位置添加元素
语法:a.insert(索引, 参数)
7.修改
直接通过索引修改内容
语法:a[索引] = 参数
8.删除(remove pop del)
语法:remove()---------- 删除某个元素,如果有重复,删除的是第一次出现的元素,如果元素不存在会报错
pop(索引)删除列表末尾的元素
del()直接删除变量
- 元组–tuple类
元组为不可变数据类型,相关的方法较少,主要是index() 和 count(),以及内置函数len()
1.访问
语法:index(x): 返回元素 x 在元组中第一次出现的索引。
count(x): 统计元素 x 在元组中出现的次数
len(x): 获取元组的长度
2.元组的拼接和重复
通过+和*进行拼接和重复
- 字典–dict类
1.字典是一种可变的容器,可以存储任意类型的数据
2.字典中的每个数据都是用"键" (key) 进行索引,而不像序列可以用下标进行索引
3.字典中的数据没有先后关系,字典的存储是无序的
4.字典是python中唯一的映射类型,采用键值对(key-value)的形式存储数据。key必须是不可变类型,如:数字、字符串、元组。
5.字典的表示方式是以{} 括起来,以冒号(:)分割的键值对,各键值对之间用逗号分隔开
6.字典的键一般是唯一的,如果重复最后的一个键值对会替换前面的
#增
dic1 = {'name': 'cgk'}
dic1['age'] = '20'
print(dic1)
#键存在,不改动,返回字典中相对应的键对应的值
a = dic1.setdefault('age', 30)
print(a)
print(dic1)
#键不存在,在字典中增加新的键值对,并返回相应的值
b = dic1.setdefault('hobby', 'girl')
print(b)
print(dic1)
#查
dic4 = {'name': 'cgk', 'age': '20', 'hobby': 'girl'}
print(dic4['name']) #通过键查找
print(dic4.values()) #打印全部值
print(dic4.keys()) #打印全部键
print(dic4.items()) #打印全部键值对
# 打印全部键,转成列表形式
print(list(dic4.keys()))
dic4 = {'name': 'cgk', 'age': '20', 'hobby': 'girl'}
dic4['age'] = 30 #更新
dic4['school'] = '北大' #添加
print(dic4)
dic4 = {'name': 'cgk', 'age': '20', 'hobby': 'girl'}
dic5 = {1: "1", 'age': "30"}
dic4.update(dic5) #把dic5加进dic4里面,如果有重复的键,则覆盖
print(dic4)
#删
dic5 = {'name': 'cgk', 'age': '20', 'hobby': 'girl', 'school': '北大'}
del dic5['name'] #删除键是name的条目
print(dic5)
red = dic5.pop('hobby') #通过pop删除键是hoppy的条目,并返回删除的值
print(red)
print(dic5)
dic5.clear() #清空字典
print(dic5)
del dic5 #直接删除字典
- 集合–set类
s3 = set('abcdefg') # 生成了无序集合
不可变集合(frozenset)
# 不可变集合
set_data_1 = frozenset('abcdef')
print(set_data_1) # frozenset({'e', 'f', 'c', 'a', 'd', 'b'})
增加数据(add、update)
add():将元素添加到集合中。
注意:如果该元素已经存在,则add()方法不会添加该元素。
s1 = {10, 20}
s1.add(100)
s1.add(10)
print(s1) # {100, 10, 20}
update():用于修改当前集合,可以添加新的元素或集合到当前集合中,如果添加的元素在集合中已存在,则该元素只会出现一次,重复的会忽略。
a = {"apple", "banana", "cherry"}
b = {"google", "microsoft", "apple"}
a.update(b)
print(a) # {"apple", "banana", "cherry", "google", "microsoft"}
remove(),删除集合中的指定数据,如果数据不存在则报错
s1 = {10, 20}
s1.remove(10)
print(s1)
s1.remove(10) # 报错
print(s1)
discard(),删除集合中的指定数据,如果数据不存在也不会报错。
注意:这个方法与remove()方法不同,因为如果指定的元素不存在,remove()方法会引发错误,而discard()方法则不会。
s1 = {10, 20}
s1.remove(10)
print(s1)
s1.remove(10)
print(s1)
pop(),随机删除集合中的某个数据,并返回这个数据。
注意:此方法返回删除的集合元素,没有参数。当集合为空时再次使用pop方法会报错!
s1 = {10, 20, 30, 40, 50}
del_num = s1.pop()
print(del_num)
print(s1)
clear()方法删除集合中的所有元素。
x = {"a", "b", "c"}
print(x)
x.clear()
print(x) # set()
查找数据(in、not in)
in:判断数据在集合序列
not in:判断数据不在集合序列
s1 = {10, 20, 30, 40, 50}
print(10 in s1) #True
print(10 not in s1) #False
python列表常用方法
1.append()---------列表后面添加元素
2.insert()---------向指定的下标处添加元素
3.pop()---------删除元素
4.count()------返回的是某个元素在列表里面的个数
5.extend() -------合并列表
6.index()--------返回的是元素在列表中的第一个位置
7.remove()---------- 删除某个元素,如果有重复,删除的是第一次出现的元素,如果元素不存在会报错
8.sort()-------进行排序(从小到大 int类型)可以对字母进行排序(ASCII值)类型不能混
9.reverse()-------将列表进行翻转
10.clear() -------清除元素
11.copy()----- 浅拷贝对象 不等价与 =
python冒泡排序
# 通用方法
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
arr = [5, 2, 8, 1, 9]
print(bubble_sort(arr))
# 简单的排序
a=[100,97,4,89,34,2]
for i in range(len(a)-1):
for j in range(len(a)-i-1):
if a[j] > a[j+1]:
a[j+1],a[j] = a[j],a[j+1]
print(a)
# 使用python中的函数,
#sort()直接在原列表上进行排序
#sorted()返回一个新的排序列表,需要新的变量接收
numbers = [4, 2, 9, 1, 5]
numbers.sort()
print(numbers)
numbers = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
sorted_numbers = sorted(numbers) # 返回一个新的排序列表
print(sorted_numbers) # 输出: [1, 1, 2, 3, 3, 4, 5, 5, 5, 6, 9]
fruits = ["apple", "banana", "cherry", "date"]
fruits.sort()
print(fruits) # 输出:['date', 'apple', 'cherry', 'banana']
#倒叙使用reverse()函数
my_list = [1, 2, 3, 4, 5]
my_list.reverse()
print(my_list)
records = [
{'name': 'Alice', 'age': 25},
{'name': 'Bob', 'age': 30},
{'name': 'Charlie', 'age': 22}
]
# 根据年龄升序排序
sorted_records = sorted(records, key=lambda x: x['age'])
print(sorted_records)
# 根据年龄降序排序
sorted_records = sorted(records, key=lambda x: x['age'], reverse=True)
print(sorted_records)
python去重
#使用set()函数进行去重
data = [1, 2, 2, 3, 4, 4, 5]
unique_data = list(set(data))
print(unique_data)
# 输出:[1, 2, 3, 4, 5]
# 如果需要保持原始数据的顺序并去重,你可以使用sorted函数。
data = [1, 2, 2, 3, 4, 4, 5]
unique_data = sorted(set(data), key=data.index)
print(unique_data)
python编写乘法表
# 双重循环 for-for
# 使用 for 循环遍历 1 到 9 中的每个数字
for i in range(1, 10):
# 使用嵌套的 for 循环遍历 1 到 i+1 中的每个数字
for j in range(1, i+1):
# 打印一个形如 j × i = i*j 的字符串,并以制表符结尾,不换行
print(f'{j}x{i}={i*j}\t', end='')
# 打印一个空行,以实现乘法口诀表的垂直排列
print()
python算法二分查询
# 二分搜索是一种在有序数组中查找某一特定元素的搜索算法。搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半。
def search(my_list, num):
low = 0
high = len(my_list) - 1
while low <= high:
mid = int((low + high) / 2)
guess = my_list[mid]
if guess == num:
return mid
elif guess > num:
high = mid - 1
else:
low = mid + 1
return None
my_list = [2, 3, 4, 1, 7, 8]
num = 2
search(my_list, num)
SQL常见语法
可在线练习的sql语法地址:https://www.sql-practice.com/
- 查询语法
select [字段/*] from [表名] - 创建数据库
CREATE DATABASE 数据库名; - 插入语法
insert into 表名 values(值,值); insert into 表名(字段,字段) values(值,值) - 更新数据
update 表名 set 要跟新的字段=值 where 条件; - 删除数据
delete from 表名 where="值" #删除表里的某一行
DROP TABLE 表名 #删除表里的内容,包括表结构和数据
DROP DATABASE 库名 #删除库,不管存不存在 - 多条件查询
select * from 表名1,表名2 where 表名1.字段=表名2.字段 and .....; - 内关联查询
select * from 表名1 inner join 表名2 on 表名1.id=表名2.id ;(内连接) # 查出两张表所有的数据,没有数据的使用NULL展示
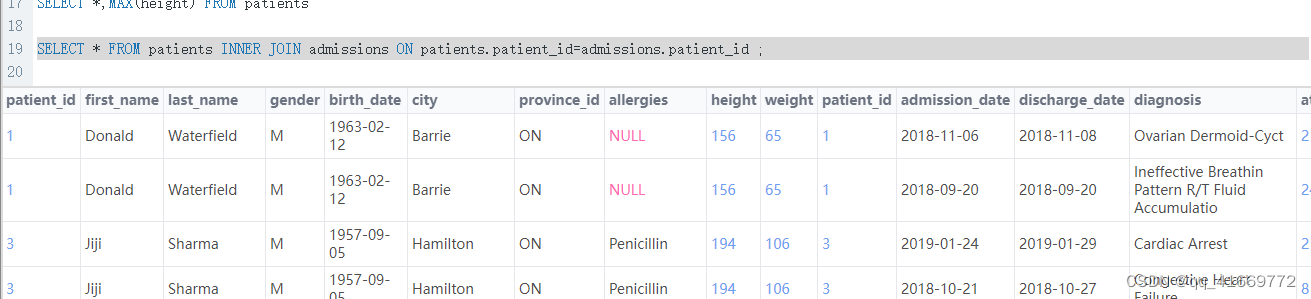
- 左连接查询
select * from 表名1 left join 表名2 on 表名1.id=表名2.id ;(左连接) # 查出两张表所有数据,左边表中的数据都展示,右边没有数据的null填充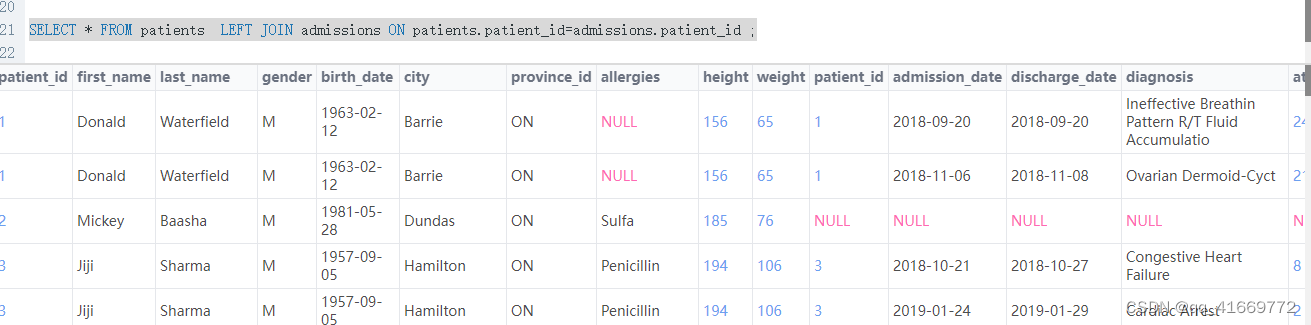
- 右连接查询
select * from 表名1 right join 表名2 on 表名1.id=表名2.id ;(右连接) # 右边表中的数据都展示,左边没有数据的null填充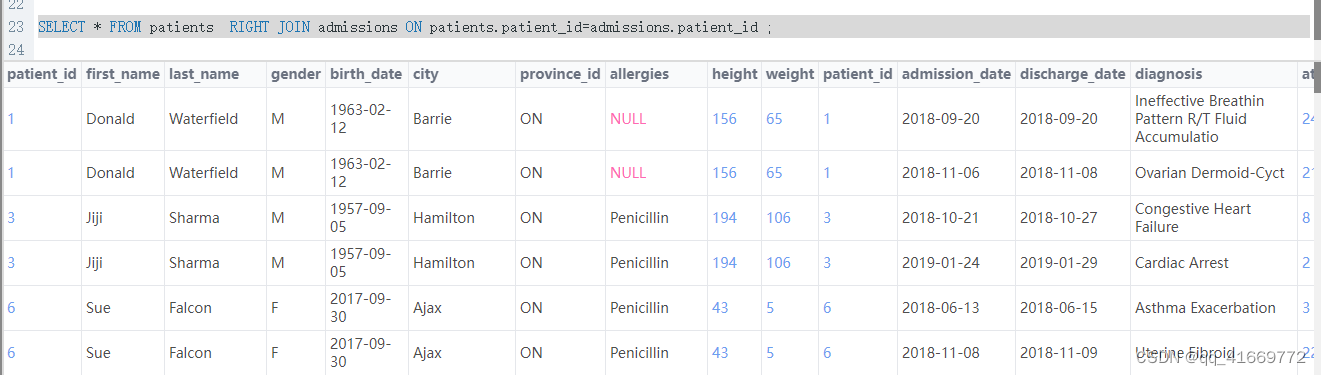
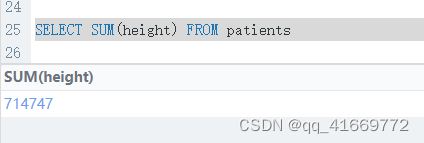
- 求和函数sum
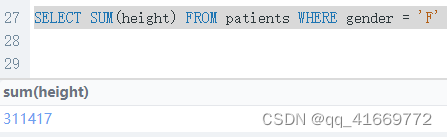
select SUM(height) from patients # 查出height列的所有数据的和
select sum(height) from patients where gender = 'F' # 加上条件的查询
- 查询最大的数MAX
select max(height) from patients; - 查询最小的数MIN
select min(height) from patients; - 统计条数COUNT
select count(first_name) from patients
select count(height) from patients where gender = 'M' # 可以加条件进行查找 - 分组查询GROUP BY
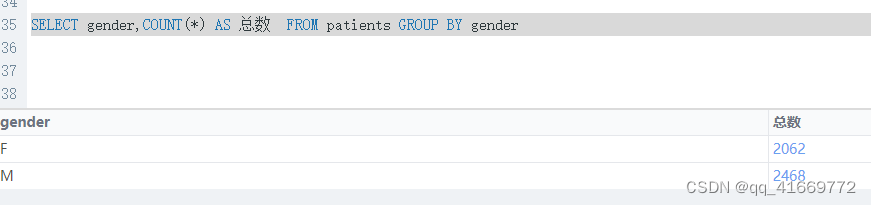
select gender,count(*) AS 总数 from patients group by gender
- 求平均数
select avg(height) from patients

















 913
913











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









