







1 简介
LFW人脸数据集主要用于测试模型准确率。数据库中共有13233张图像和5749人。 每张图片都是250x250 jpg。目前LFW数据集不用作训练,主要用于测试。因此本文主要讲解其测试协议。
程序使用pytorch
LFW官方网址:http://vis-www.cs.umass.edu/lfw/
本次实验测试MobileFaceNet模型在LFW上的准确率。
lfw数据集(已经对齐并且大小为112×112):
链接:https://pan.baidu.com/s/1Sy0EkKRfb0xHRgq1iao2qg
提取码:1rf3
2 数据集准备
2.1 LFW数据集下载
下载地址:http://vis-www.cs.umass.edu/lfw/lfw.tgz
2.2 人脸预处理
下载的LFW数据集是250×250的图像,我们需要将其进行人脸预处理操作(人脸检测+人脸对齐),具体方法可以看我另一个博客。
https://blog.csdn.net/qq_41684249/article/details/111302649
三、测试协议
3.1 pair.txt
下载地址:http://vis-www.cs.umass.edu/lfw/pairs.txt
该文件将数据库随机分为10组,我们随机选择300个匹配对和300个每组中不匹配的对。使用此拆分,可以使用10倍交叉验证得出数据库的性能。
pair.txt文件的格式如下:
- 第一行显示套数后跟每套匹配对的数量(相等到每组不匹配对的数量)。
- 匹配对格式如下:
name n1 n2
表示匹配对name人的第n1和第n2张图。 - 不匹配对格式如下:
name1 n1 name2 n2
表示不匹配对name1人的第n1张图和name2人的第n2张图。
3.2 具体流程
- 处理LFW原始数据集,具体方法见:https://blog.csdn.net/qq_41684249/article/details/111302649
- 使用python,pytorch进行数据读取。
- 送入预训练网络MobileFaceNet,得到特征。输入112×112的对齐人脸图像,提取的特征为512维。
- 将LFW测试集所有图像进行特征提取。
- 通过cosine距离/欧式距离计算两张人脸的相似度。通过最优阈值得到准确率。
- 最优阈值的选取:先将训练数据分为10组,然后选取其中一组,计算其余九组的最大ROC得到最优阈值,这个最优阈值作为该组的阈值,算出该组的准确率。这样重复十次。得到最终的准确率。具体请看程序。
四、程序
4.1 MobileFaceNet
预训练模型见博客。
博客链接:https://blog.csdn.net/qq_41684249/article/details/115357756?spm=1001.2014.3001.5501
4.2 配置文件config.py
只需将这个配置文件对应修改就行。
img_list.txt和pairs.txt文件见第一部分。
# 测试协议txt文件
PAIRS_FILE_PATH = "/home/malidong/workspace/dataset/lfw/pairs.txt"
# 预处理后的数据集地址
CROPPED_FACE_FOLDER = "/home/malidong/workspace/dataset/lfw/112×112"
# 包含数据集所有相对路径的txt文件地址
IMAGE_LIST_FILE_PATH = "/home/malidong/workspace/dataset/lfw/img_list.txt"
# 模型输出维度
FEAT_DIM = 512
# 深度卷积层核大小
OUT_H = 7
OUT_W = 7
# 预训练模型地址
MODEL_PATH = "/home/malidong/workspace/mobilefacenet/Epoch_17.pt"
# 设备选择
DEVICE = "cuda"
4.3 数据集加载文件test_dataset.py
import os
import cv2
import numpy as np
from torch.utils.data import Dataset
import torchvision.transforms as transforms
class CommonTestDataset(Dataset):
def __init__(self, image_root, image_list_file):
'''
普通测试数据集加载
:param image_root: 数据集根目录
:param image_list_file: txt文件,包含所有图片相对路径
'''
self.image_root = image_root
self.image_list = []
image_list_buf = open(image_list_file) # 开始读取文件
line = image_list_buf.readline().strip() # 读取一行
while line:
self.image_list.append(line)
line = image_list_buf.readline().strip() # 继续读取下一行
# 预处理
self.transform = transforms.Compose([
transforms.ToTensor(), # 0-1
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 归一化
])
def __len__(self):
return len(self.image_list)
def __getitem__(self, index):
short_image_path = self.image_list[index] # 图片相对路径
image_path = os.path.join(self.image_root, short_image_path) # 图片路径
image = cv2.imdecode(np.fromfile(image_path, dtype=np.uint8), cv2.IMREAD_UNCHANGED) # 读取图片
#image = cv2.resize(image, (128, 128))
image = self.transform(image) # 预处理
return image, short_image_path # 图片 相对路径(相当于图片身份,用于查询)
4.4 lfw评估程序lfw_evaluator.py
import torch
import numpy as np
import torch.nn.functional as F
class LFWEvaluator(object):
def __init__(self, data_loader, pairs_file, device):
'''
LFW测试协议 先将所有的数据集进行特征提取,然后在测试
:param data_loader: 数据集加载
:param pairs_file: 测试txt文件地址
:param device: 设备
'''
self.data_loader = data_loader
self.device = device
self.pair_list = self.pairsParser(pairs_file)
def pairsParser(self, pairs_file):
'''
读取pair.txt文件内容
:param pairs_file: 测试txt文件地址
:return: (图1 图2 标签),是一个list列表文件。标签为0表示不同,标签为1表示相同。
'''
test_pair_list = [] # 创建一个list
pairs_file_buf = open(pairs_file) # 读取文件
line = pairs_file_buf.readline() # 跳过第一行 因为第一行是无关的内容
line = pairs_file_buf.readline().strip() # 读取一行,去除首尾空格
while line: # 只要文件有内容,就会读取
line_strs = line.split('\t') # 按空格分割
if len(line_strs) == 3: # 如果是3元素,则表示两张人脸是同一个人
person_name = line_strs[0] # 第一个元素是姓名
image_index1 = line_strs[1] # 第二个元素是第一张图的索引
image_index2 = line_strs[2] # 第三个元素是第二张图的索引
image_name1 = person_name + '/' + person_name + '_' + image_index1.zfill(4) + '.jpg' # 得到第一张人脸的地址
image_name2 = person_name + '/' + person_name + '_' + image_index2.zfill(4) + '.jpg' # 得到第二张人脸的地址
label = 1 # 标签为1表示是同一个身份
elif len(line_strs) == 4: # 表示两张人脸是不同的人
person_name1 = line_strs[0] # 第一个人的姓名
image_index1 = line_strs[1] # 第一个人的索引
person_name2 = line_strs[2] # 第二个人的姓名
image_index2 = line_strs[3] # 第二个人的索引
image_name1 = person_name1 + '/' + person_name1 + '_' + image_index1.zfill(4) + '.jpg' # 得到第一张人脸的地址
image_name2 = person_name2 + '/' + person_name2 + '_' + image_index2.zfill(4) + '.jpg' # 得到第二张人脸的地址
label = 0 # 标签为0表示不同身份
else:
raise Exception('Line error: %s.' % line)
test_pair_list.append((image_name1, image_name2, label)) # 存入list中
line = pairs_file_buf.readline().strip() # 读取下一行
return test_pair_list
def extract_feature(self, model, data_loader):
'''
提取所有测试集人脸特征
:param model: 要测试的模型
:param data_loader: 数据集
:return: 字典形式 图片名字(相对路径):提取的特征
'''
model.eval() # 测试模式,如果不写,会对bn层有影响
image_name2feature = {} # 字典
with torch.no_grad(): # 不进行梯度下降
for batch_idx, (images, filenames) in enumerate(data_loader): # 读取数据
images = images.to(self.device) # 图片
features = model(images) # 特征
features = F.normalize(features) # 特征归一化 用于求余弦相似度
features = features.cpu().numpy()
for filename, feature in zip(filenames, features):
image_name2feature[filename] = feature # 存入字典
return image_name2feature
def test(self, model):
'''
测试程序
:param model: 测试模型
:return: 准确率和方差
'''
image_name2feature = self.extract_feature(model, self.data_loader)
mean, std = self.test_one_model(self.pair_list, image_name2feature)
return mean, std
def test_one_model(self, test_pair_list, image_name2feature, is_normalize = True):
'''
获取模型的LFW测试准确率
:param test_pair_list: 测试pair.txt文件
:param image_name2feature: 存入特征的字典
:param is_normalize: 是否已经归一化,如果已经归一化,就True,无需在进行归一化。
:return: 准确率、方差
'''
subsets_score_list = np.zeros((10, 600), dtype = np.float32) # 余弦相似度
subsets_label_list = np.zeros((10, 600), dtype = np.int8) # 标签
for index, cur_pair in enumerate(test_pair_list): # 图1 图2 标签
cur_subset = index // 600 # 对600取整 一共6000对,分成10组
cur_id = index % 600 # 对600取余
image_name1 = cur_pair[0] # 图1
image_name2 = cur_pair[1] # 图2
label = cur_pair[2] # 标签 0表示不同 1表示相同
subsets_label_list[cur_subset][cur_id] = label # 存入标签
feat1 = image_name2feature[image_name1] # 图1的特征
feat2 = image_name2feature[image_name2] # 图2的特征
if not is_normalize: # 归一化
feat1 = feat1 / np.linalg.norm(feat1)
feat2 = feat2 / np.linalg.norm(feat2)
cur_score = np.dot(feat1, feat2) # 余弦相似度(即得分)
subsets_score_list[cur_subset][cur_id] = cur_score # 存入余弦相似度
subset_train = np.array([True] * 10)
accu_list = []
for subset_idx in range(10): # 一组一组算
test_score_list = subsets_score_list[subset_idx] # 一组的余弦相似度
test_label_list = subsets_label_list[subset_idx] # 一组的标签
subset_train[subset_idx] = False # 改为False
train_score_list = subsets_score_list[subset_train].flatten() # 其余9组的余弦相似度
train_label_list = subsets_label_list[subset_train].flatten() # 其余9组的标签
subset_train[subset_idx] = True # 改为True
best_thres = self.getThreshold(train_score_list, train_label_list) # 用其余9组得出阈值
positive_score_list = test_score_list[test_label_list == 1] # 将标签为1的放入一个余弦相似度列表
negtive_score_list = test_score_list[test_label_list == 0] # 将标签为0的放入一个余弦相似度列表
true_pos_pairs = np.sum(positive_score_list > best_thres) # 计算结果正确的数量
true_neg_pairs = np.sum(negtive_score_list < best_thres) # 计算结果正确的数量
accu_list.append((true_pos_pairs + true_neg_pairs) / 600) # 计算每组最后结果
mean = np.mean(accu_list) # 取平均值
std = np.std(accu_list, ddof=1) / np.sqrt(10) # 方差
return mean, std
def getThreshold(self, score_list, label_list, num_thresholds=1000):
'''
得到最佳阈值
:param score_list: 余弦相似度list
:param label_list: 标签list
:param num_thresholds: 只需n次得到最优roc
:return:
'''
pos_score_list = score_list[label_list == 1] # 将标签为1的放入一个余弦相似度列表
neg_score_list = score_list[label_list == 0] # 将标签为0的放入一个余弦相似度列表
pos_pair_nums = pos_score_list.size # 数量
neg_pair_nums = neg_score_list.size # 数量
score_max = np.max(score_list) # 最大余弦相似度
score_min = np.min(score_list) # 最小余弦相似度
score_span = score_max - score_min # 相减
step = score_span / num_thresholds # 切分成num_thresholds个
threshold_list = score_min + step * np.array(range(1, num_thresholds + 1)) # 得到一个切分后的阈值list
fpr_list = []
tpr_list = []
for threshold in threshold_list: # 一个个试
fpr = np.sum(neg_score_list > threshold) / neg_pair_nums # 错误/负样本数
tpr = np.sum(pos_score_list > threshold) /pos_pair_nums # 正确/正样本数
fpr_list.append(fpr)
tpr_list.append(tpr)
fpr = np.array(fpr_list)
tpr = np.array(tpr_list)
best_index = np.argmax(tpr-fpr) # 取最大值
best_thres = threshold_list[best_index]
return best_thres # 得到最大阈值
4.5 主程序test_lfw.py
import os
from prettytable import PrettyTable
from torch.utils.data import DataLoader
from test_dataset import CommonTestDataset
from MobileFaceNets import MobileFaceNet
import config
from lfw_evaluator import LFWEvaluator
if __name__ == '__main__':
# 参数预加载
pairs_file_path = config.PAIRS_FILE_PATH
cropped_face_folder = config.CROPPED_FACE_FOLDER
image_list_file_path = config.IMAGE_LIST_FILE_PATH
feat_dim = config.FEAT_DIM
out_h = config.OUT_H
out_w = config.OUT_W
model_path = config.MODEL_PATH
device = config.DEVICE
# 设置gpu
os.environ["CUDA_VISIBLE_DEVICES"] = "0, 1"
# 测试数据集加载
data_loader = DataLoader(CommonTestDataset(cropped_face_folder, image_list_file_path),
batch_size=1024, num_workers=16, shuffle=False)
# 模型加载
model = MobileFaceNet(feat_dim, out_h, out_w)
model = model.load_model(model, model_path)
# lfw评估类加载
lfw_evaluator = LFWEvaluator(data_loader, pairs_file_path, device)
# 评估
mean, std = lfw_evaluator.test(model)
# 显示
accu_list = [(os.path.basename(model_path), mean, std)]
pretty_tabel = PrettyTable(["model_name", "mean accuracy", "standard error"])
for accu_item in accu_list:
pretty_tabel.add_row(accu_item)
print(pretty_tabel)
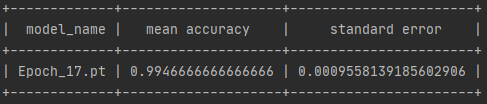
五、测试结果


















 1789
1789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











