






☆ 问题描述
| 相关问题 | 地址 |
|---|---|
| python使用进程池多进程时,如何打印错误信息 | 博客园 |
在python机器学习中,我想要进行自动调参,这需要比较大的运算能力,但是我发现cpu的性能总是不能跑满,原来是我用了多线程,python对于多线程的支持并不是很好可以看廖雪峰
python多线程为什么不能把多核CPU的性能吃满?
因为Python的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁:Global Interpreter Lock,任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
GIL是Python解释器设计的历史遗留问题,通常我们用的解释器是官方实现的CPython,要真正利用多核,除非重写一个不带GIL的解释器。
所以,在Python中,可以使用多线程,但不要指望能有效利用多核。如果一定要通过多线程利用多核,那只能通过C扩展来实现,不过这样就失去了Python简单易用的特点。
不过,也不用过于担心,Python虽然不能利用多线程实现多核任务,但可以通过多进程实现多核任务。多个Python进程有各自独立的GIL锁,互不影响。
目前python团队已经计划在3.13版本以后删除GIL锁CSDN链接
★ 解决方案
把多线程改成多线程
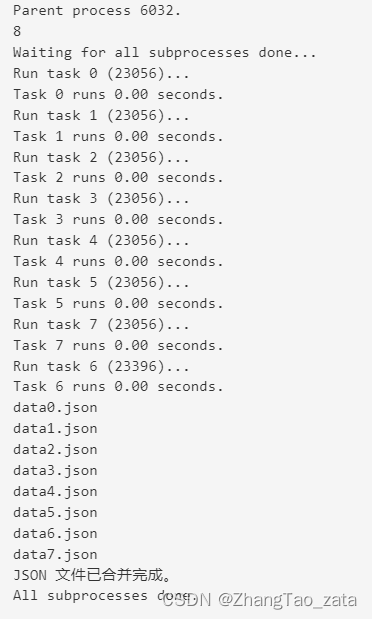
一个例子,根据自己核心数创建进程,然后把数据写入json文件中最后合并
from multiprocessing import Pool
import multiprocessing
import os, time, random
import json
def long_time_task(name):
print('Run task %s (%s)...' % (name, os.getpid()))
start = time.time()
# 需要保存的数据
data = {
"name": str(name)
}
# 将数据写入JSON文件
with open('data'+str(name)+'.json', 'w') as f:
json.dump(data, f, indent=4)
end = time.time()
print('Task %s runs %0.2f seconds.' % (name, (end - start)))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Pool()
# 获取CPU的核心数
cpu_cores = multiprocessing.cpu_count()
print(cpu_cores)
for i in range(cpu_cores):
p.apply_async(long_time_task, args=(i,))
print('Waiting for all subprocesses done...')
p.close()
p.join()
files = []
file_path = os.path.dirname(__file__)
for file in os.listdir(file_path):
if file.find('data') != -1:
files.append(file)
merged_data = []
# 遍历每个文件,读取并解析 JSON 数据,然后添加到合并后的数据列表中
for file_name in files:
with open(file_name, 'r') as file:
print(file_name)
data = json.load(file)
merged_data.append(data)
# 将合并后的数据写入新的 JSON 文件
with open('merged.json', 'w') as merged_file:
json.dump(merged_data, merged_file, indent=4)
print('JSON 文件已合并完成。')
print('All subprocesses done.')
加进程锁
from multiprocessing import Process, Queue, Pool
import multiprocessing
import os, time, random
def write1(q, lock):
lock.acquire() # 加上锁
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
lock.release()
def write2(q, lock):
lock.acquire() # 加上锁
for value in ['D', 'E', 'F']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
lock.release()
if __name__ == '__main__':
q = Queue()
manager = multiprocessing.Manager()
lock = manager.Lock()
pw1 = Process(target=write1, args=(q, lock))
pw2 = Process(target=write2, args=(q, lock))
# 启动子进程pw,写入:
pw1.start()
pw2.start()
# pr.start()
pw1.join()
pw2.join()
# pr.join()
print('所有数据都写入并且读完')
✅ 总结














 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









