







目录
- INTRODUCTION
- BACKGROUND AND MOTIVATION
- DESIGN OVERVIEW
- DETAILED DESIGN
- IMPLEMENTATION
- EVALUATION
- DISCUSSION
- RELATED WORK
- CONCLUSION
今天分享的论文《Efficient Distributed Secure Memory with Migratable Merkle Tree》来自2023年HPCA。
作者团队(IPADS)发现,当前分布式可信计算并不高效,体现在(1)当前的可信执行环境局限于单节点的内存保护以及(2)跨节点的通信需要基于安全信道(如SSL)进行不同层次被多次加解密。由此,本文提出了可迁移默克尔树(MMT)来减少机密分布式计算中的安全数据传输开销。该架构扩展自“蓬莱”TEE的完整性保护树结构(OSDI’21),使其能够跨越多个节点,同时对完整性保护子树增加了迁移的原语。
该工作也是IPADS实验室十余年来继 CloudVisor [SOSP’11]、HyperCoffer [HPCA’13]、SeCage [CCS’15]、vTZ [USENIX ATC’17]、Penglai [OSDI’21]、TwinVisor[SOSP’21] 等工作之后,在可信执行环境领域的又一成果;同时也是基于“蓬莱”RISC-V开源TEE研究平台的工作之一。

INTRODUCTION
TEE大多采用基于硬件的内存保护引擎,如Intel MEE、BMT、Vault和Mountable MT,为物理内存提供强大的安全保障,防御内存欺骗、别名、拼接和重放攻击。同时,最近的一些研究指出,使用可扩展的完整性树方案可以支持高达512GB的enclave内存。
然而,现有的Enclave都是为了保护单个节点上的内存而设计的,并不能很好地满足分布式应用程序的需求。由于计算节点之间的网络被认为是不可信的,现有系统必须求助于软件安全通道,例如TLS / SSL,以保护数据传输的机密性、完整性和新鲜度,并使用本地内存保护引擎重建远程节点中的完整性树。例如,VC3[47]部署了基于加密的协议来保护安全的分布式MapReduce计算; Civet [59] 使用加密保护检查 enclave 接口和输入; Graviton [61]和HIX [35]利用AES-SHA3/OCBAES算法来保护CPU和GPU之间传输的敏感数据。
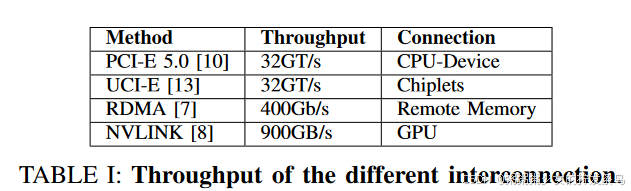
众所周知,基于加密的方法在数据传输期间会产生大量开销。表一显示了不同互连的最大带宽。最先进的基于 RDMA 的 NIC [7] 可以提供 400 Gbps 带宽,并将往返延迟降低至微秒。此外,最新的PCI-E 5.0/6.0标准[10]、[11]、CXL[4]和NVLink[8]可以支持超过800Gbps的带宽[10],但是AES-SHA3等加密算法已经吞吐量要低得多,即使对于最先进的基于 FPGA 的 AES/GCM 加速器也只能实现 2∼40 Gbps 的吞吐量 [2], [15], [58]。 Graviton还表明,与CPU和GPU节点之间直接内存复制相比,AES-SHA3算法会带来10∼20倍的开销。 sRDMA [58] 扩展了 RDMA 协议以加密和验证 RDMA 数据包中的有效负载,但牺牲了 RDMA 带宽(与最大 400 Gbps RDMA 带宽相比,sRDMA 仅 10 Gbps)。
为了在分布式飞地之间实现(接近)线性的安全数据传输速度,我们的想法是扩展内存保护引擎,该引擎已经可以保护物理内存的机密性、完整性和新鲜度,从一个节点到多个节点。通过重用硬件保护机制,不需要额外的基于加密的操作,一个Enclave可以通过PCIe、RDMA等各种连接直接将数据传输到另一个Enclave。
然而,由于不可信的网络(或互连),将现有的单节点内存保护引擎扩展到多个节点具有挑战性。首先,硬件内存保护引擎依赖于密封在CPU内的基本元数据,例如,完整性树的根和onetime-pad被密封在CPU中用于内存加密和完整性检查。元数据无法在不受信任的网络中安全传输。其次,中间人可以轻松地在不受信任的网络中发起重放(例如,使用陈旧的数据包)或重新排序攻击(例如,交换数据包的顺序)。例如,虽然 TDX [6] 使用 MKTME 来保证物理内存的机密性和完整性(使用MAC加密数据),它放弃了新鲜度保护。由于网络不安全,攻击者更容易在网络而不是物理内存中发起重放攻击。
本文提出了可迁移默克尔树(MMT),它将数据和元数据传输到远程节点,而无需软件参与(例如重新加密)。 MMT 的一个关键见解是(单节点)硬件内存保护已经为不受信任的 DRAM 提供了机密性、完整性和新鲜度保证,这些 DRAM 可以在不受信任的网络中重复用于保护。为此,我们首先将单个完整性树扩展到跨越多个节点的完整性森林,并打破 CPU 绑定的加密元数据的限制。此外,我们设计了一种新的协议:MMT closure delegation,来保护在不可信网络中传输的数据。它可以安全地将完整性子树根、节点和数据传输到远程节点,从而防止泄露secret或重放攻击。最后,我们实现了一个小型且可信的模块来管理安全区和可信硬件模块。它隐藏硬件实现的细节,并负责本地和远程飞地之间的连接。
我们已经在 Gem5 [20] 中实现了 MMT 系统的原型以及所有软件组件。我们扩展了 Gem5 中的内存控制器以支持 MMT 控制器,并添加了一个新设备:PCI 连接器,它可以使用类似 RDMA 的机制连接两个节点并触发 MMT closure delegation。我们还实现了一个基于蓬莱飞地[25]的安全监视器,它配置安全硬件模块并管理本地/远程飞地。评估结果表明,与仅使用CPU的安全通道相比,MMT可将数据传输性能加速高达169倍,与AES加速器相比可实现13倍的加速。对于现实世界的安全分布式应用程序,MMT 可以在不同工作负载下使 MapReduce 的端到端性能提高 12%∼58%,并使用 GAS 模型 [29] 将 PageRank 提高 35%。
BACKGROUND AND MOTIVATION
Hardware-based Memory Protection
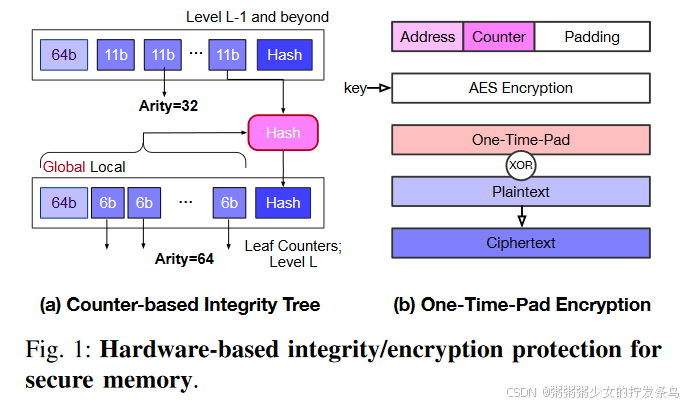
如图1所示,现代内存保护引擎使用基于计数器的完整性树[28]、[44]、[45]、[49]、[51]、[56]来提供完整性/新鲜度保护,并且利用计数器模式加密[38]、[45]、[49]-[51]、[53]、[54]来保证安全内存的机密性。同时,内存保护引擎还在安全存储中保留了一个加密密钥,该密钥无法在CPU外部访问(例如efuse)。
完整性、加密和新鲜度检查需要一些额外的元数据,例如完整性树节点、地址和MAC。现代内存保护引擎采用counter-mode加密来保证机密性。
如图 1(b) 所示,内存引擎首先利用内存地址和counter来生成one-time-pad (OTP)。稍后,它将使用该 OTP 对明文进行 XOR 运算以生成密文。
对于完整性保护,内存引擎构建了覆盖所有安全内存的完整性树。每个完整性树节点包含多个计数器以及相应的哈希值。哈希值是使用父节点中的counter和当前节点中的所有counter计算的(对 OTP 和Galois Field (GF) 点积结果进行异或)。对于每个写入请求,counter都会增加。因此,如果父节点受到保护,攻击者就无法篡改其子节点或伪造有效的哈希值,并且递归地,数据内存也受到保护。在此过程中,只有 XOR 操作处于关键路径,其他操作(如 AES 计算和点积)可以与 DRAM 读取重叠。
Demand of Distributed Confidential Computing
Security guarantee for both code and data.
为了实现分布式机密计算,我们需要保护代码和数据的机密性和完整性。一些最先进的技术[34]、[36]、[47]、[59]、[63]、[64]选择硬件飞地来保护云中的分布式计算。 Enclave可以在隔离环境中执行时保护代码和数据的机密性,但不能保证它们的完整性。因此,用户需要验证输入数据的完整性并证明执行代码的测量。尽管与完全基于加密的方法相比,使用硬件飞地具有更好的性能,但对输入数据的安全检查给分布式计算带来了较高的开销。
Large-scale data transfer.
分布式计算是大数据处理的基础。在计算过程中,每个节点都会与其他节点进行通信并传输大量消息。通信开销是分布式计算的关键指标之一。传统的分布式计算可以使用全局可共享的文件/内存池来传输消息。 MapReduce[23]将中间键值结果存储在分布式文件系统中,一个MapReduce任务将传输超过758TB[27]的中间结果。图计算[30]、[40]、[41]利用快速网络连接来收集来自邻居的消息(例如,GNN [27]需要在一个时期内传输72GB消息)。同时,随着RDMA等快速互连机制的演进,分布式计算可以进一步减少通信开销,提高端到端性能。
Inefficiency of Secure Channel over Untrusted Interconnection
Limited throughput over secure channel mechanism.
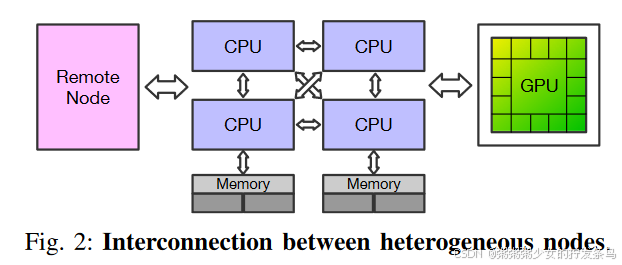
安全通道机制的吞吐量有限。异构节点之间的互连如图2所示。最新的互连实现了超过 400Gbps 的带宽,并将往返延迟降低到微秒级,如表 1 所示。然而,这些互连面临着严峻的挑战:数据传输没有保护。因此,用户必须利用基于加密的操作(即安全通道)来保护不可信网络中的数据。安全通道[12]可以防止数据传输过程中的窃听和篡改。它首先执行密钥交换协议(例如,Diffie-Hellman [5])以生成只有发送者和接收者知道的密钥。然后,发送方将使用 AEAD 算法 [1](例如 AES-GCM)来保护相关数据,接收方可以检查加密和未加密消息的完整性。然而,AEAD算法的吞吐量远小于互连机制,这使性能降低了几个数量级[42],[68],[69]。
Establish the secure channel between enclaves.
由于Enclave内存被加密,NIC驱动程序无法直接读取/写入Enclave内存。最先进的 enclave 设计 [3]、[6]、[14]、[17]、[22] 使用共享且不受信任的内存缓冲区将 I/O 消息复制到 enclave 内存之外。然后,NIC 驱动程序可以读取共享缓冲区中的内容并将其发送到远程 enclave。由于网络是不可信的,飞地需要自己对消息进行加密和验证。因此,与没有任何安全保证的通信通道相比,Enclave之间使用的安全通道需要额外的两次内存副本,一次加密和一次解密,这被认为是耗时的。
DESIGN OVERVIEW
Design Goals
Performance.
我们的系统应该消除将安全内存传输到远程节点时重新加密的开销,并使互连的最大吞吐量饱和。
Security.
我们的系统应该实现与安全通道机制相同的安全保证(即传输数据的机密性、完整性和新鲜度)。
Compatibility.
我们的系统应该隐藏用户应用程序的硬件细节,并继承分布式机密计算的编程范式,例如消息传递。
Threat model
我们系统的 TCB 仅包含 CPU 和大多数特权软件(例如 Arm 中的 EL3 监视器)。其他硬件(例如 PCI-e 设备、NIC、内存)和软件(例如 REE 中的主机操作系统)不受信任,可能被攻击者利用。
Physical attacks.
我们只信任片上硬件模块(例如CPU、内存控制器),任何其他片外硬件组件和设备都是不可信的,包括互连接口、内存和网络。攻击者可能通过在总线或网络中插入恶意微控制器来发起片外物理攻击,例如间谍、切片和重放攻击。
Privileged software attacks.
我们采用与TrustZone/CCA/Keystone类似的软件威胁模型,广泛应用于机密计算。攻击可能会触发 REE 的软件攻击,例如损害主机内核或获得对用户应用程序的完全控制。然而,运行在最高特权模式(例如Arm中的EL3、RISC-V中的M模式)的固件无法被包含。此外,TEEOS 值得信赖,但在我们的设计中是可选的。
我们的系统不考虑旁路攻击[39]、[60]、[65]、[66]和DoS攻击。
Challenges
与非安全内存不同,安全内存不能直接发送给其他人,因为远程节点无法解密和验证传输的加密内存。此外,攻击者可以拦截网络中的数据包、交换数据包的顺序或重新使用过时的数据包来发起重放或重新排序攻击。综上所述,MMT需要解决以下挑战:
C1: How to decouple the memory protection from the CPU-bound secret in a single node?
一些安全假设在单个节点中保持,但在多个节点中失败。例如,在单个节点中,可以使用唯一的物理地址作为内存加密中的一次性密码(OTP),并且加密密钥被密封在硬件中,不能在多个节点之间传输。
C2: How to securely transfer the secure memory to the remote node without re-encryption?
如果我们只是将安全内存发送到远程,远程内存引擎无法解密和验证传输的内存。更重要的是,由于连接是不安全的,我们需要保护secret并防御数据传输过程中的重放攻击。
C3: How to hide the hardware details and provide the suitable primitive for distributed computation?
新的硬件扩展不能使用户应用程序的实现复杂化,也不能打破分布式机密计算的范式,例如使用消息传递进行通信。
So…
在本文中,我们提出了可迁移默克尔树(MMT),它可以将加密的内存安全地传输到远程节点,而无需软件重新加密。
首先,我们提出了一个新的抽象:可以跨越多个节点的完整性森林。同时,采用全局证明机制来验证每个想要加入分布式机密计算的节点(第IV-A节)。
其次,我们设计了一个新的传输单元:MMT closure ,它集成了数据和元数据。远程节点可以根据MMT closure 对传输存储器进行解密和验证。为了免受不可信网络中的重放/重新排序/泄露攻击的影响,我们还设计了一种协议:MMT closure delegation,将 MMT closure安全地传输到远程节点(第 IV-B2 节)。
第三,我们设计了一个可信的微型模块:MMT以最高特权模式进行监控,组织所有安全硬件,并建立远程节点之间的连接。为了可扩展性,我们不改变分布式计算中的通信原语:消息传递(第 IV-C 节)。
DETAILED DESIGN
我们提出了一种新的内存保护抽象:可迁移默克尔树(MMT),以保护不可信网络中的分布式物理内存和消息。为了实现这一点,我们首先在多个节点之间建立一个完整性森林,然后将每个 Merkle 子树扩展到 MMT 方案。
Multiple-Nodes Integrity Tree
首先,我们在多个节点之间建立相互信任。全局权威节点将对每个想要加入分布式计算的参与节点进行验证。其次,构建完整性森林来保护不同节点之间的分布式内存。
1) Global Attestation:
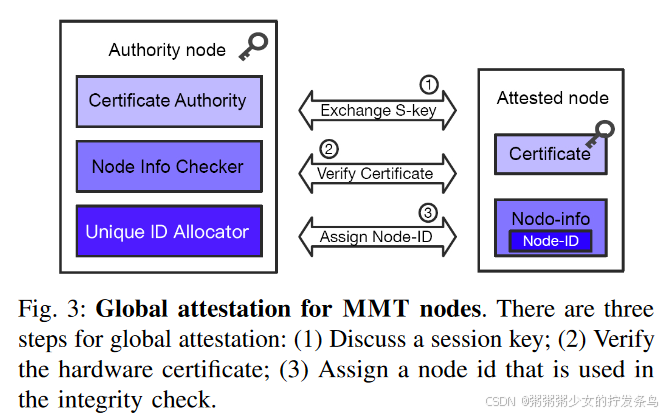
如图3所示,当MMT系统启动时,它首先会向全局权威节点证明自己(称为全局证明)。全局认证包括三个阶段。
首先,被证明的节点向权威节点(作为证明服务器)生成密钥协商消息并讨论会话密钥(例如,Diffie Hellman),该会话密钥保护不可信网络中的敏感数据。
其次,被证明的节点向权威节点发送制造商证书(用机器密钥密封)。权威节点使用制造商的公钥验证证书,并向被证明的节点响应证书颁发机构(CA)报告。
最后,被证明节点向权威节点发送节点相关消息。节点相关消息包含软件模块的度量、节点元信息等。权威节点收到这些消息后,检查软件度量,并向被证明节点响应一个全局唯一的节点id。该节点 ID 对于生成完整性森林至关重要(请参阅第 IV-A2 节)。
2) Integrity Forest:
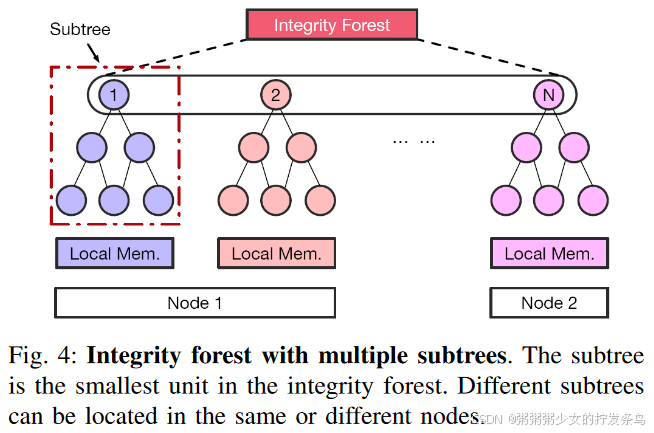
然而,仅有全局证明还不够。现代内存加密引擎利用完整性树来保证安全内存的机密性、完整性和抗重放攻击。因此,为了实现分布式安全内存,我们提出了完整性森林,其中包含来自多个节点的子树,如图4所示。
硬件支持的内存保护在密码计算中有两个重要因素:内存地址和counter。这两个因素保证任何one-time-pad只能使用一次。然而,当考虑跨多个节点的分布式内存时,物理内存地址将会重复,这违反了安全假设(OTP 只能使用一次)。为了解决这个问题,我们在内存保护中使用全局唯一地址来代替真实的物理地址。全局唯一地址由两部分组成:全局唯一节点id和单调数。在全局证明阶段从权威节点接收全局唯一的节点id,并且由硬件为每个物理地址生成单调编号。因此,我们不需要在运行时同步地址信息。更重要的是,这个全局唯一的地址仅在完整性检查期间由硬件使用,并且对软件是透明的。开发人员不需要改变应用程序的编程模型或牺牲分布式程度。所有完整性子树跨越多个节点,构成一个大的完整性森林,保护分布式安全内存。
Summary:
为了将完整性树扩展到多个节点,我们提出了两种技术:全局证明和完整性森林。全局证明保证所有节点都经过验证并获得全球唯一的标识。经过全局认证后,被认证的节点可以将自己的认证报告发送给其他节点,并与远程节点建立相互信任。完整性森林包含多个节点之间的子树,保证了分布式安全内存的安全假设。
MMT Scheme
MMT是完整性森林中的一棵子树,可以迁移到不可信网络中的多节点。
1) MMT root:
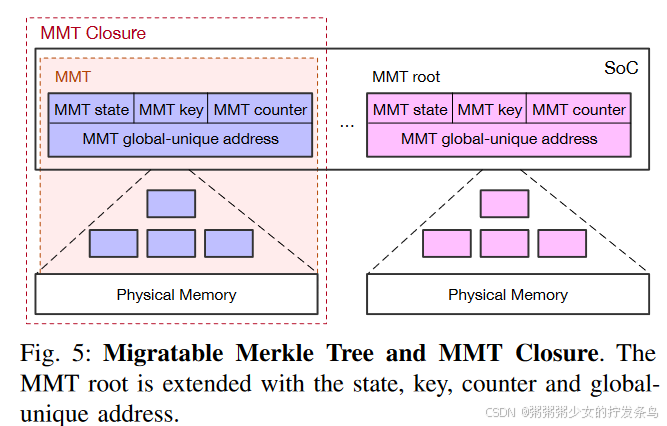
为了迁移Merkle树,MMT用额外的元数据扩展了树根,如图5所示。MMT有四种状态:有效、无效、发送/只读和等待;有效状态意味着 MMT 处于活动状态并对内存访问执行安全检查。无效状态意味着MMT未被分配或回收,该内存被视为非安全内存。发送和等待状态用于传输安全内存。如果MMT状态为发送,则该内存范围内的内容不可修改(只读);同时,等待状态与发送状态一起工作,等待远程传输的内存。
除了 MMT 状态之外,MMT 根还通过密钥和全局唯一地址进行扩展。与密封在硬件中的传统加密密钥不同,MMT 密钥是用户定义的secret,用于内存加密和身份验证过程。如果两个应用程序同意相同的 MMT 密钥,则它们都可以解密和验证相同的安全内存。在这里,我们将加密密钥从可信硬件解耦到用户空间(类似于 TLS 握手),因为用户可以灵活地信任分布式系统中的不同节点。全局唯一地址在全局证明后初始化,如果MMT状态更改为有效,则全局唯一地址将被重新分配。值得注意的是,全局唯一地址的值对软件是透明的,因此系统仍然使用物理地址来管理内存。除了密钥和地址之外,MMT 根还包含一个根counter以保证其新鲜度。当将 MMT 状态更改为有效/无效时,用户可以设置/清除初始化的根counter。
2) MMT closure delegation:
MMT closure 包含解密和认证过程中使用的所有数据和元数据(即树节点、根和数据 MAC)。在这里,我们提出了一种新的数据传输原语:MMT closure delegation。
假设有两个节点:接收者和发送者。传统方法中,发送方和接收方需要建立一条安全通道,之后发送方可以通过该安全通道将secret数据发送给接收方。然而,使用安全通道会带来昂贵的开销,包括重新加密和额外的内存复制。相反,MMT closure delegation将安全内存和相应的元数据直接传输到远程。但是,如果我们不仔细设计这个过程,就会出现一些安全问题,例如篡改MMT根和重放攻击。
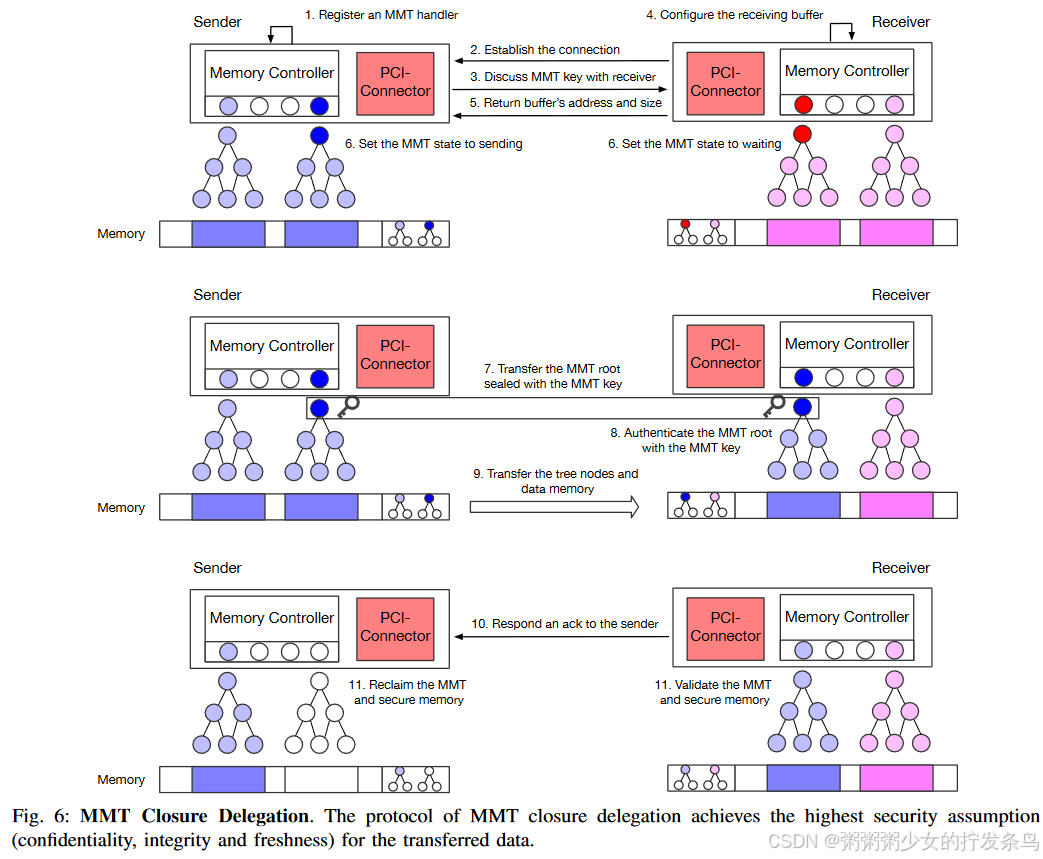
如图6所示,我们安全地设计了MMT closure delegation,以保证不可信网络中的安全假设。
1. Connect to the remote node:
首先,发送方注册一个连接处理程序(类似于RDMA连接中的QP)并向接收方发送MMT密钥交换请求。在就相同的 MMT 密钥达成一致后,发送器/接收器获取安全缓冲区(查找空闲内存区域并将 MMT 状态更改为对给定根counter有效)并设置相同的 MMT 密钥。最后,接收方用缓冲区地址和大小响应发送方。
2. Waiting phase:
连接建立后,接收方会将接收缓冲区的MMT状态设置为等待;发送方将传输缓冲区的MMT状态设置为发送(该内存区域是只读的,直到整个协议完成)。之后,接收方等待传输的 MMT closure。
3. Securely Delegate the MMT Closure:
为了实现这一目标,我们需要在 MMT closure delegation期间保证安全假设(即机密性、完整性和新鲜度)。 MMT closure delegation有两个方面:
(1)如何传递MMT根和树节点;
(2)如何传输内存中的数据。
与单节点内存保护类似,我们首先要保证MMT根不被恶意篡改。不幸的是,在 MMT delegation期间网络是不可信的,因此攻击者可以轻松伪造恶意的 MMT 根值,从而违反安全假设。为了保护不可信网络中的MMT根,发送方使用MMT密钥来密封根值(使用MAC值加密),并且接收方可以使用相同的本地MMT密钥来解密和验证该MMT根。因此,攻击者无法在委托期间篡改 MMT 根。同时,不需要加密中间树节点,因为它们以明文形式存储在内存中。对于第二个方面,数据存储器的机密性和完整性由相应的MMT来保证。因此,数据存储器可以传输到远程,而无需任何额外的基于加密的保护。
4. Ack:
当接收方接受所有传输的安全内存和 MMT 节点时,它将 MMT 状态更改为有效/只读,并向发送方的节点发送一条 ack 消息。如果需要,发送者将使原始传输的 MMT 失效(更多详细信息请参阅§V-B2)。之后,MMT closure delegation就完成了。
Defend Against Replay Attacks:
除了机密性和完整性保护,MMT closure delegation还可以防御重放和重新排序攻击。虽然Merkle树可以保护安全内存免受单个节点的重放攻击,但它没有考虑内存在网络中传输的场景。
在不可信网络中,攻击者可以轻松地(1)重复使用过时的 MMT closure,并与目标节点具有相同的 MMT 密钥; (2)交换MMT closure顺序。
MMT closure delegation利用基于counter的新鲜度检查和单调地址排序来防御重放和重新排序攻击。首先,当目标节点接收到传输的 MMT closure时,它将用本地counter检查 MMT closure中的counter,并拒绝任何具有较小或相同counter值的传入 MMT closure。对于每个写请求,硬件都会增加counter的值,以保证任何更改都会导致新的版本号。另外,当MMT状态改变为有效时,用户可以用给定值初始化根counter。据此,我们可以保证发送方的counter值总是大于接收方的counter值,并且总是增加的在delegation期间。其次,目标节点将检查两个相邻MMT中全局唯一地址的单调性。保证后者的MMT根中的地址大于前者。由于counter和地址是密封的(使用 MMT 密钥来加密和验证 MMT 根),攻击者无法篡改网络中的这些值。因此,MMT closure delegation不受重放和重新排序攻击的影响。
Summary
我们设计了一种 MMT 方案,可以在多个节点之间安全地传输内存,而无需重新加密。 MMT closure是在不可信网络中可以迁移的最小单元。当远程节点收到 MMT closure时,它可以自行解密和验证秘密数据。为了保证数据传输的安全假设,我们设计了MMT closure delegation的安全协议,以保护内存免受间谍、篡改和重放攻击。总之,我们减少了传输安全内存的开销,无需重新加密和额外的内存复制,并实现与安全通道相同的安全假设。
MMT Monitor
除了完整性森林和MMT方案的硬件扩展之外,我们还设计了一个可信的小型可信模块来管理MMT引擎并对enclave进行远程证明。
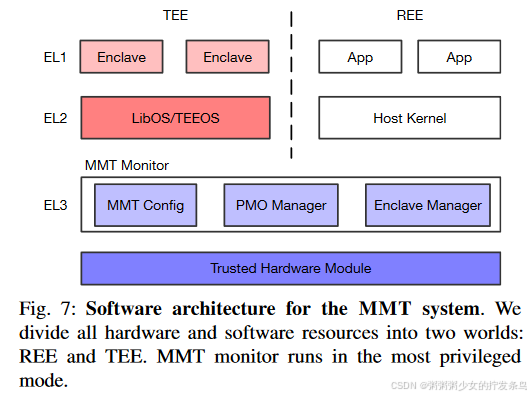
图7显示了MMT系统的软件架构。我们引入了一个可信的软件模块:MMT 监视器,用于在最高特权模式下管理 enclave 和 MMT 相关操作(例如 Arm 中的 EL3)。 MMT 监视器使用组织物理内存的功能并隐藏硬件详细信息。它还负责远程证明并建立本地和远程 enclave 之间的连接。
MMT 监视器有两个关键组件:Enclave 管理器和物理内存对象 (PMO) 管理器。
第一个组件组织 enclave 的生命周期,向远程客户端进行证明并建立连接。飞地管理器维护飞地与其元数据(例如,capability和证明报告等)之间的映射。为了建立本地和远程enclave之间的连接,本地监视器可以发起连接请求,远程监视器获取目标enclave,验证证明报告并最终建立连接。之后,Enclave 管理器可以在本地和远程 Enclave 之间建立三种通道:非安全通道、安全通道和 MMT closure delegation。
第二个组件负责配置 MMT 状态并检查物理内存对象 (PMO) 的所有权。物理内存对象包含两部分:安全内存和相应的MMT。由于MMT配置与整个系统的安全性密切相关,因此我们精心设计了一种能力机制来组织MMT和安全内存。只有 PMO 的所有者才能配置其 MMT 根,并且每个 PMO 只能有一个所有者。值得注意的是,如果安全内存被分配给另一个飞地或转移到远程飞地,则可以撤销所有权。
Summary:
我们设计了一个可信模块:MMT 监视器,用于管理 enclave 的生命周期、建立连接并配置 MMT 硬件。 MMT 监视器中有两个主要组件:Enclave 管理器和 PMO 管理器。此外,MMT监视器是唯一可以配置可信硬件模块(例如MMT控制器)的特权模块。
IMPLEMENTATION
Hardware Changes for MMT
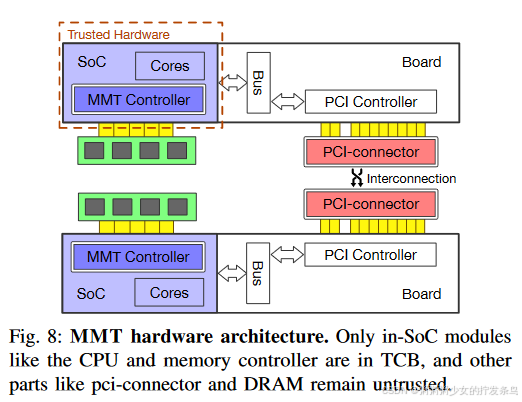
图8显示了MMT系统的硬件架构。
1) PCI-connector:
现代 smartNIC [15] 向主机公开 RDMA 接口。同样,我们实现一个特定的互连设备:pci-connector。为了进一步控制网络中的数据传输延迟,我们设置延迟周期来模拟不同的连接延迟。如果本地节点想要将其内存传输到远程节点,它将触发 DMA 请求,将内存从源节点复制到 pci-connector 的缓冲区,然后,远程 pci-connector 将发起 DMA 请求来复制内存内存从设备缓冲区到远程节点中的目的地。总之,要将内存从本地传输到远程,我们需要发起两个 DMA 请求并设置 DMA 延迟周期来模拟连接延迟。
有两种类型的数据传输:仅数据或 MMT closure delegation。
仅数据传输类似于 RDMA 操作。在我们的实现中,我们保留 tx 缓冲区和 rx 缓冲区作为默认设备缓冲区。对于MMTMMT closure delegation,需要将安全内存和MMT树节点传输到远程节点。
首先,pci-connector需要设置远程内存地址的源和目的地。
其次,在将数据内存传输到远程节点之前,它将发起传输MMT元数据的请求(详细信息请参见§V-A2)。在接收到所有MMT closure内存后,pciconnector将向本地/远程内存控制器触发finished/ack命令来更新MMT状态(在接收器中有效,在发送器中无效)。 MMT closure delegation比仅数据传输稍慢,因为它需要传输额外的元数据(MMT 树节点)。同时,MMT根验证可以与MMT委托重叠,这不在关键路径中。
2) MMT controller:
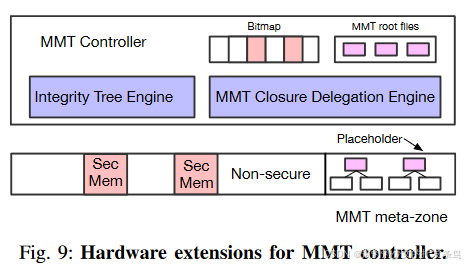
如图 9 所示,我们扩展内存控制器以支持 MMT 相关操作。 MMT 控制器包含两个新组件:完整性树引擎和MMT closure delegation引擎。完整性树引擎旨在保护物理内存免受窥探、篡改和重放攻击。 MMT控制器将整个物理内存分为三种类型:普通内存、安全内存和MMT元区。当MMT控制器收到内存请求时,它会首先检查记录物理内存类型的位图。非安全和安全内存的粒度相当于MMT的受保护大小(在我们的实现中为2M)。同时,MMT元区是一个单独的内存范围,只能由MMT监视器访问。 MMT元区存储MMT元数据,例如中间树节点和MMT根(仅占位符,任何读/写请求都会重定向到SoC中的真实根),并且每个MMT元数据与其数据存储器都有固定的映射。每个MMT根包含额外的24字节元数据:128位密钥、2位状态、58位全局唯一地址和4位保留。
与现代内存保护引擎类似,MMT控制器也采用基于counter的完整性树来保护物理内存,并将完整性树根存储在SoC中。图 1 (a) 显示了 MMT 的完整性树结构。在每个树节点中,我们采用带有哈希值的global-local counter布局。每个counter包括全局共享部分和本地单独部分。当全局counter耗尽时,我们需要更新所有子节点中的counter并执行重新哈希过程。在我们的实现中,叶节点有 64 个本地counter(64 个数量),其他树节点有 32 或 16 个本地counter。此外,每个MMT都是3级高度。
第一个组件是完整性树引擎。一旦MMT控制器收到读请求,它将遍历完整性树以从MMT元区域获取所有中间节点。树引擎收到所有树节点和数据包后,递归检查树节点中存储的哈希值,直到MMT根;对于写请求,树引擎首先向中间树节点发起多个读请求,并在写入之前检查数据完整性。验证后,它增加节点计数器并更新树节点中的哈希值。写请求被推入写队列后会立即返回,因为如果写队列不为空,则会定期触发写回操作。
第二个组件是 MMT closure delegation引擎。如上所述,物理内存分为三种类型:非安全内存、安全内存和MMT元区。对于 MMT delegation请求,MMT closure delegation引擎利用 MMT 密钥来密封 MMT 根值(即加密和验证)。之后,MMT根可以通过pci-connector安全地传输到目的地。对于远程侧,MMT closure delegation引擎将首先使用本地MMT密钥来解封传输的MMT根。如果认证失败,委托请求将被拒绝;否则,MMT引擎将接收MMT节点和数据存储器。 MMT引擎收到所有数据和MMT节点后,将触发完成命令并将MMT状态从等待设置为有效;类似地,发送方节点将收到ack命令,并使发送方的MMT失效(状态从发送变为无效)。之后,MMT 和数据存储器的所有权从发送方转移到接收方(更多详细信息请参阅§V-B2)。
Software Implementation
1) MMT Monitor and TEEOS:
我们在基于 Penglai enclave [25] 的 Arm EL3 中实现了 MMT 监视器,并采用 Chcore [31]——基于微内核的内核作为 TEE 中的可信操作系统。 ChCore 使用该功能来管理所有物理资源(例如,内存分配、时间片)和软件定义的对象(例如,通知、文件)。 MMT 监视器是管理 enclave、MMT 状态和可信硬件模块的最高特权模块。如第 IV-C 节中所述,MMT 监视器中有两个关键组件:Enclave 管理器和 PMO 管理器。
MMT 监视器使用 enclave 对象来管理本地 enclave 的生命周期并维护与远程 enclave 的连接。
对于 PMO 管理器,MMT 监视器使用额外的 MMT 相关元数据(例如,MMT 状态和密钥)扩展安全物理内存对象(sPMO),并利用组织其所有权的能力。同时,为了最小化 MMT 监视器的 TCB,我们将 sPMO 的分配卸载到 TEEOS 中。 sPMO 只能从固定内存池(如 RDMA 的缓冲区)分配。如果 enclave 获得了安全 PMO 的能力,TEEOS 会将这个物理内存范围映射到其虚拟内存空间。
2) Enclave Application:
用户级飞地应用程序有两种模式:所有权转移模式或所有权复制模式。在所有权转让模式下,MMT的所有者可以将相应的安全内存和MMT节点转让给其他人。一旦远程节点接受传输的 MMT 以及安全存储器,MMT 的所有权就从发送方转移到接收方。如果发送方想要重用转移的内存区域,则需要重新分配新的MMT。这种编程模型适用于DAG(有向无环图)场景。对于所有权复制模式,MMT 的所有者只需将安全内存和 MMT 节点的只读副本发送给接收者。如果接收方想要修改传输内存中的内容,则需要将内容复制到另一个空间。然而,由于传输的内存的所有权仍然由发送者持有,因此可以直接修改发送者这边的内容。该编程模型适用于发送/接收协议。综上所述,我们必须保证整个分布式系统中安全内存只有一份可写的副本。
EVALUATION
Methodology

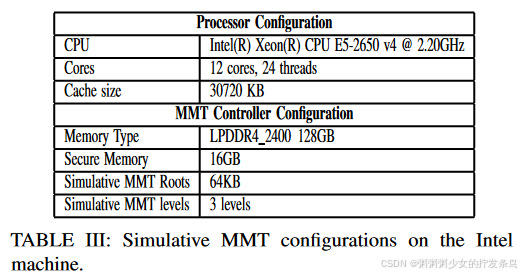
我们实现了基于 Gem5 [20] 的 MMT 硬件:一个完整的系统、周期精确的模拟器。表 II 显示了用于评估的 Gem5 配置。我们在 GEM5 中实现了完整的硬件扩展(例如,MMT 控制器、PCI-connector)。此外,为了将 MMT closure delegation的性能与使用 AES 加速器(例如当前 Intel CPU 中的 AES-NI 指令)的最先进的安全通道机制进行比较,我们在真机中实现了软件 MMT 控制器并基于RDMA连接模拟MMT closure delegation。简而言之,我们启动额外的单侧 RDMA 操作,将模拟 MMT 元数据传输到远程节点,并执行 MMT 根的软件检查。表 III 显示了真实英特尔机器的处理器和 MMT 配置。对于安全通道机制,我们重新使用OpenSSL[9]提供的密码库,并通过RDMA连接建立安全通道。
我们首先使用两种方法评估将安全内存传输到远程节点的性能:MMT closure delegation和基于软件的安全通道(例如,使用 AES-GCM 算法)。为了全面评估不同设置下的 MMT 性能和权衡,我们在不同树级别的 SPECCPU 基准测试上测试了 MMT。我们还设置了各种 PCI-connector延迟周期来模拟不同的网络连接延迟。对于实际应用,我们选择两个著名的分布式任务:MapReduce [23]和 PageRank [21]。我们实现了 MapReduce 框架,并使用不同的传输内存大小、工作负载和设置来测试端到端延迟。对于第二个应用,我们在 MMT 系统中实现了 Gather-Apply-Scatter (GAS) 模型 [29],并在应用阶段采用 PageRank 算法。
Microbenchmarks
MMT closure delegation.
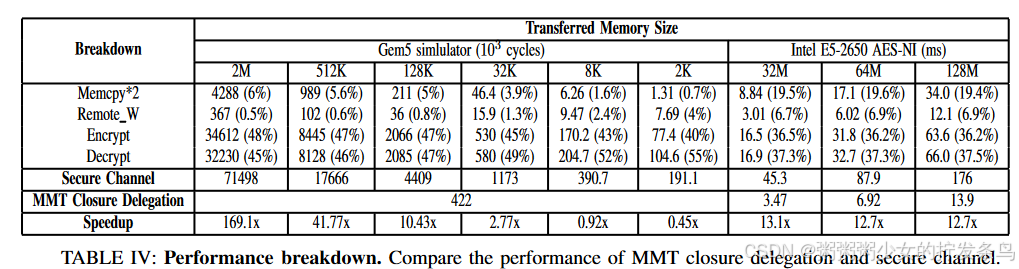
我们使用仅 CPU 和 AES-NI 指令通过安全通道方法评估 MMT closure delegation的性能。对于 MMT closure delegation,飞地需要将 MMT closure的整个粒度传输到远程,即使消息大小要小得多(在我们的实现中,MMT closure大小的默认粒度为 2M)。相比之下,安全通道使用不安全的远程写入接口,没有内存大小限制。飞地首先需要加密敏感消息并将其复制到非安全内存。然后,触发远程写入请求,将该加密消息传输到远程接收缓冲区。最后,远程飞地将加密消息从非安全接收缓冲区复制到其自己的安全内存中,然后对其进行解密。综上所述,安全通道方法中存在两次额外的内存副本、一次远程内存写入和重新加密。
表 IV:Gem5 显示了启用 MMT 的机器上 MMT closure delegation和安全通道的性能。在Gem5模拟器中,我们仅使用CPU进行密码计算。当传输的内存大小小于一个 MMT closure(2M)时,MMT closure delegation具有恒定的开销。相反,安全通道没有这个限制,但需要四个额外的操作:memcpy、remote_w、加密和解密。数据加密和解密是安全通道机制中成本最高的操作,两者都占用了2M消息近45%的时间。普通内存和安全内存之间的数据复制需要另外5%的时间,而远程内存写入只占传输开销的0.5∼4%。至于端到端性能,MMT closure delegation在传输 2M 安全内存时获得了 169 倍的加速。然而,使用安全通道方法在小消息(例如内存大小<8K)中具有更好的性能。在分布式计算场景中,每个节点都会将大规模内存传输到其他节点(参见第§II-B节),因此传输的小尺寸消息在实际工作负载中很少见。表 IV:英特尔将 MMT 性能与使用 AES 加速器的增强基线进行比较。目前的Intel CPU提供了AES-NI指令来加速AES加密。为了模拟 MMT delegation性能,我们发出两次 RDMA 写入来传输数据内存和 MMT 树节点。评估结果表明,即使使用 AES-NI 指令,MMT delegation与安全通道机制相比也获得了 13 倍的加速。
Throughput
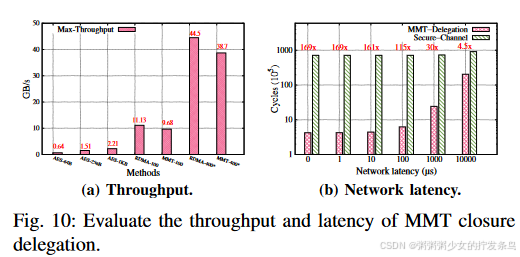
图 10 (a) 显示了 AES-128-GCM、RDMA 和 MMT 的最大吞吐量。我们使用 AES-NI 指令在不同块大小下测试 AES-GCM 算法。评估结果表明,较大的块大小可以获得更好的性能(Intel E5-2650 中为 2.2GB/s)。到评估真实机器上的 MMT 吞吐量,我们触发两个 RDMA 事务来发送数据和元数据。在我们的测试案例中,具有 100Gbps 带宽的 r-NIC 可以实现 11 GB/s 的吞吐量,MMT delegation在 RDMA 连接下可以获得 9.68GB/s 的带宽。如果我们将 r-NIC 升级到 400Gbps [7],MMT delegation的最大吞吐量将相应增加。因此,即使使用AES加速器,AES加密的吞吐量仍然比MMT delegation小一个数量级。
Network Latency.
图10(b)展示了MMT closure delegation的端到端延迟与网络延迟之间的关系。我们在 pci-connector中设置延迟周期来模拟 Gem5 中的不同网络延迟。在理想情况下(网络延迟为零),与基于 CPU 的安全通道相比,MMT closure delegation可以在 2M 传输内存的情况下获得 169 倍的加速。然而,当网络延迟增加时,MMT closure delegation的端到端延迟的改善将缩小(如果网络延迟增加到10毫秒,仅获得4.5倍的加速)。同时,对于现实世界的分布式计算,主要的通信开销来自数据传输,因为每个计算节点需要发送大规模消息,但网络延迟很小(在同一机架中使用RDMA为微秒级)。
Tree level.
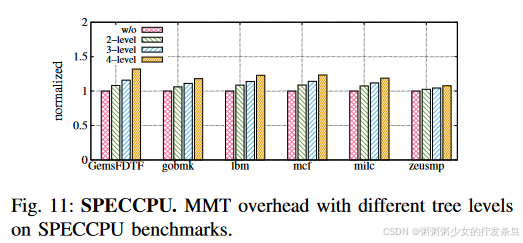
MMT树级别也是MMT系统的关键参数,我们用各种指标(例如性能、空间开销)对其进行评估。图 11 显示了不同 MMT 树级别的性能开销。我们选择SECCPU基准来评估MMT的总体性能。如果加深MMT级别,性能开销就会增加。更糟糕的是,由于SoC空间和树节点缓存有限,当增加MMT级别时,这种开销会迅速上升(一次内存访问会触发额外的树节点访问,从而占用MMT控制器中的读/写队列和树节点缓存) )。评估结果表明,如果采用2层MMT树,平均开销仅为1.07x,而假设树层增至4层,平均开销则上升至1.21x。
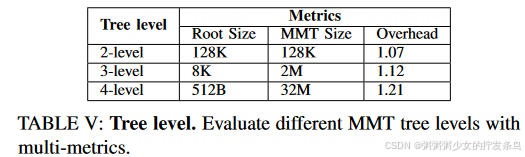
表 V 总结了不同 MMT 树级别的影响。更深的 MMT 占用更少的 SoC 存储。例如,4级MMT仅需要512B额外空间用于SoC中的MMT根。相比之下,2 级 MMT 占用 128KB 存储空间,比 4 级 MMT 大几个数量级。更重要的是,更高的MMT树级别也意味着更大的传输内存粒度。 4 级 MMT 闭包包含 32MB 连续安全内存,而 2 级 MMT 的该值为 128KB。综上所述,较高的MMT树级别可以节省SoC内存储,但会增加性能开销并扩大安全内存的粒度。在我们的评估中,我们选择 3 级 MMT 作为默认配置。
Real-world Applications
1) Trusted MapReduce:
MapReduce是分布式计算中流行的编程模型。一些最先进的技术 [47]、[59] 提出了基于 SGX 等硬件飞地的可信 MapReduce 方案。为了保护映射器和化简器输入/输出的完整性,这些工作添加了安全保证,例如读写完整性检查。 VC3[47]指出,与非安全MapReduce任务相比,安全保证将带来高达63.4%的开销。我们建立了一个内存中的MapReduce框架[18]、[43]、[57]、[62]、[67],它可以通过远程内存写入接口(非安全)或MMT closure delegation传输中间结果。

图 12 显示了具有不同传输内存大小的 WordCount 任务的端到端性能(MMT delegation与 Gem5 中的安全通道)。评估结果表明,与安全通道相比,MMT delegation可以获得高达 10 倍的加速(当传输的内存大小大于 2M 时)。为了测试最坏情况下的性能,我们以一些极小的工作负载运行 WordCount 任务。由于MMT delegation必须传输2M内存区域,因此当传输的内存大小小于8K时,使用安全通道具有更好的性能。然而,这种情况在现实世界的分布式 MapReduce 任务中几乎可以忽略不计。
为了进一步估计 MMT 的端到端性能,我们在真实的 Intel 服务器中运行 MapReduce 作业,并利用 RDMA 传输中间结果。协调器将使用 RDMA 队列对 (QP) 连接映射器和减速器。共有三种配置: Baseline 在非安全模式下运行,在 RDMA 事务期间没有任何保护; MMT使用MMT closure delegation来传输中间结果;安全通道利用 AES-GCM 算法来保护传输数据的机密性和完整性。
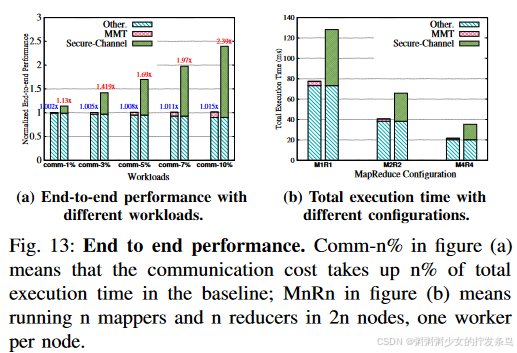
如图13(a)所示,我们评估了MapReduce在不同工作负载下的端到端性能。 Comm-n%表示基线中通信成本占总执行时间的n%,y轴是归一化性能。对于安全通道,AESGCM 加密将增加数据传输开销。例如,在 comm-5% 的工作负载中,通信仅占执行时间的 5%。然而,在安全通道模式下,这一比例将上升至 74%,导致高达 69% 的开销。 MMT delegation的性能与基线相当,因为它不需要重新加密传输的数据。在comm-10%工作负载下,端到端开销仅为1.5%,与安全通道机制相比,提高了12%∼58%。
我们通过在不同节点上运行 MapReduce 工作线程来评估 MMT delegation的可扩展性。如图13(b)所示,MnRn表示在2n个节点中运行n个mapper和n个reducer。每个映射器都需要与所有减速器建立连接。评估结果表明,MMT delegation不会破坏 MapReduce 系统的可扩展性,因为 MMT delegation利用类似消息传递的接口进行通信。与RDMA连接类似,MMT delegation在传输中间结果时不会引入任何一致性操作。
2) PageRank:
PageRank [21] 是一种广泛使用的图计算算法。最近的研究提出了一种用于大规模分布式图计算的聚集-应用分散(GAS)模型[29]。一次 GAS 迭代包含三个阶段:收集、应用和分散。为了将分布式 GAS 模型迁移到 MMT 系统,我们设计了一个称为远程传输的新阶段,它将敏感消息发送到远程 MMT 机器。如图 14(a) 所示,我们首先在每个 MMT 机器中设置聚集和分散缓冲区。对于跨机器边缘,源顶点节点会将消息复制到分散缓冲区,并触发远程内存写入(非安全)或MMT closure delegation,将消息发送到远程的聚集缓冲区。在收集阶段,我们可以确保所有传输的消息在本地计算机中准备就绪。
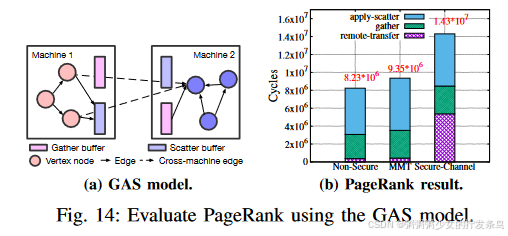
图14(b)显示了GAS模型中PageRank算法的评估结果。共有三种配置:非安全、MMT 和安全通道。非安全意味着我们在没有任何内存保护的情况下执行 PageRank(禁用 MMT 引擎); MMT/安全通道是指使用MMT closure delegation/安全通道在跨机器边缘传输远程消息。我们初始化一个具有近 100,000 个节点和 60,000 个跨机器边的图(类似于现实世界的图)。评估结果表明,使用MMT closure delegation,远程传输阶段仅占用一次迭代的5%执行时间。对于安全通道,近37.5%的运行周期花费在远程传输阶段。至于端到端性能,MMT closure delegation与安全通道相比获得了 35% 的提升。
DISCUSSION
Fault tolerance.
MMT采用与当前基于RDMA的分布式系统相同的容错策略。首先,MMT委托使用与RDMA可靠连接(RC)模式类似的技术,保证每个数据包在网络中不会丢失或重新排序。其次,开发者在分布式计算中可以采用主备编程模式。
Scalability.
分布式计算中有两种编程模型:分布式共享内存(DSM)和消息传递。由于内存一致性、写放大等原因,DSM 的可扩展性较差。MMT closure delegation选择了更具可扩展性的原语:消息传递。消息传递不存在可扩展性问题[30]、[40]、[41]、[62],因为它建立了点对点连接并将同步职责转移给开发人员。此外,MMT设计与其他可扩展完整性树方案兼容[25]、[33]、[46]、[55]。最先进的技术使用更紧凑的树结构、预取和安装机制来支持高达 512GB 的安全内存。
Security.
MMT为物理内存提供最高的安全保护,可以防御恶意读写,甚至重放攻击。一些相关作品也声称构成了机密计算的可信环境,但损害了部分物理攻击。 TDX [6] 承认它不能防御内存重放攻击。更糟糕的是,在不受信任的网络中,物理攻击变得更加严重,因为攻击者可以轻松控制网络基础设施并注入恶意包。因此,我们不能放松MMT威胁模型的安全假设。
RELATED WORK
Hardware-based Memory Integrity Protection.
许多先前的工作[22]、[25]、[28]、[33]、[44]-[46]、[49]、[50]、[55]、[56]也提出了内存完整性保护方案和减少完整性树的开销。罗杰斯等人。 [45]提出了一种针对分布式共享内存的有效数据保护。然而,MMT没有DSM系统的假设,每个节点可以拥有自己的、不可共享的内存。更重要的是,MMT可以直接传输安全内存,无需重新加密。 Penglai[25]设计了一种可扩展的内存保护方案,保护单个节点中的 512GB 安全内存。它将子树根动态挂载到 SoC 中,以最大限度地减少安全检查开销。 Synergy[50]将数据MAC存储在为ECC保留的位置(例如ECC内存),这可以减少完整性树的内存开销。此外,内存保护控制器中可以应用专用缓存来存储中间树节点,提高安全检查的性能。 Morphable [46]动态调整树节点中的计数器大小以减少溢出频率。 BMT[44]使用Merkle树来保护树计数器而不是内存数据,这减少了完整性检查的开销。 Vault [56]提出了一种具有不同大小的树counter的树结构。 ITESP [55]为每个应用程序构建一个单独的完整性树以实现更好的缓存局部性。 PCPT [33]利用并行压缩预取树来预测内存获取并减少完整性检查开销。 BMF [26] 旨在保证持久内存上的崩溃一致性,并减少 BMT 根更新的性能开销。虽然BMF和MMT都采用完整性森林方案,但BMF没有考虑如何在多个节点之间建立分布式Merkle Forest。综上所述,这些方案仅关注单个节点内的内存保护,而没有考虑多个节点之间的安全数据传输。
Hardware Enclave.
基于硬件的飞地已在主流架构中得到广泛采用,例如Intel SGX [22]、TDX [6]、Arm TrustZone [17]、CCA [3]、RISCV Keystone [37]等。Intel建立了可信环境为飞地提供内存机密性、完整性和新鲜度保护。但是,SGX [22] EPC 内存不可用于设备,我们无法在此内存范围上执行 DMA 操作。 TDX[6]只考虑了内存加密和完整性保护,但没有防御重放攻击。 CCA[3]仅提供加密存储器,没有完整性保护。 TrustZone[17]和Keystone[37]没有考虑对内存系统的物理攻击(无加密、完整性保护)。 Graviton [61] 提出了与 CPU enclave 协调的 GPUenclave。为了在 CPU 和 GPU 之间安全地传输敏感消息,它利用 AES-SHA3 算法来保护传输的消息。 HIX[35]将硬件内存保护引擎应用于GPU架构,并利用内存访问模式来优化完整性树结构。 Elasticlave [16] 仅使用 RISC-V 中的 PMP 机制提供内存隔离。它不考虑对内存的任何物理攻击。然而,MMT考虑了内存加密、完整性和新鲜度保护,并提供了一种在不违反安全假设的情况下将安全内存转移给他人的机制。
CONCLUSION
本文提出可迁移默克尔树(MMT)来减少机密分布式计算中的安全数据传输开销。为了实现这一目标,我们设计了一个安全协议:MMT closure delegation,将 MMT closure安全地传输给其他人,而无需重新加密。评估结果表明,与传统的安全通道机制相比,MMT能够显着降低传输开销,提升现实世界分布式应用的性能。



















 1968
1968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











