







文章信息
标题
FOVEAL A V ASCULAR ZONE SEGMENTATION OF OCTA IMAGES USING DEEP
LEARNING APPROACH WITH UNSUPERVISED VESSEL SEGMENTATION
出处
关键词
FAZ分割,血管分割,OCTA图像,风格转移,一致性损失
任务背景
任务需求
视网膜中央凹无血管区(FAZ)是视网膜疾病检测的关键指标,准确的自动FAZ分割在临床应用中具有重要影响。需要一种从浅层OCTA图像出发,分割出精确的FAZ位置的方法
背景
虽然OCTA可以提供3D数据来帮助疾病检测,但OCTA图像的正面投影图也常用于研究和实践中,以发现潜在的视网膜疾病。视网膜中央凹无血管区(FAZ)通常位于视网膜投影图像的中间,包含很少的血管。FAZ可以被认为是一些视网膜疾病检测的指标,如糖尿病视网膜病变[5]。在OCTA图像中,FAZ通常具有更清晰的边界,OCTA图像可用于FAZ评估
但是在现有的方法中,常常只输出了单个的FAZ分割图,忽略了重要的血管信息;清晰的血管分割图可以让FAZ的边界更加清晰,进一步提升FAZ的分割精度
但是血管分割的一个挑战就是缺乏标签。
贡献
本文提出了一种级联网络来同时实现无监督血管分割和精确的有监督FAZ分割。在第一步中,我们提出了一个图像变换网络,该网络采用带有一致性损失的风格转移来实现血管分割,而不需要任何人类标签。在第二步中,我们使用上一步的结果和UNet结构来实现最终的FAZ分割,这是一个端到端的整体结构
- 引入带有风格转移和一致性损失的无监督血管分割以提高FAZ分割精度。
- 在具有相同参数集的两个不同数据集上提出、训练和评估级联血管和FAZ分割网络,而无需任何后处理。
提出的方法
本文提出的方法整体结构如下图所示:
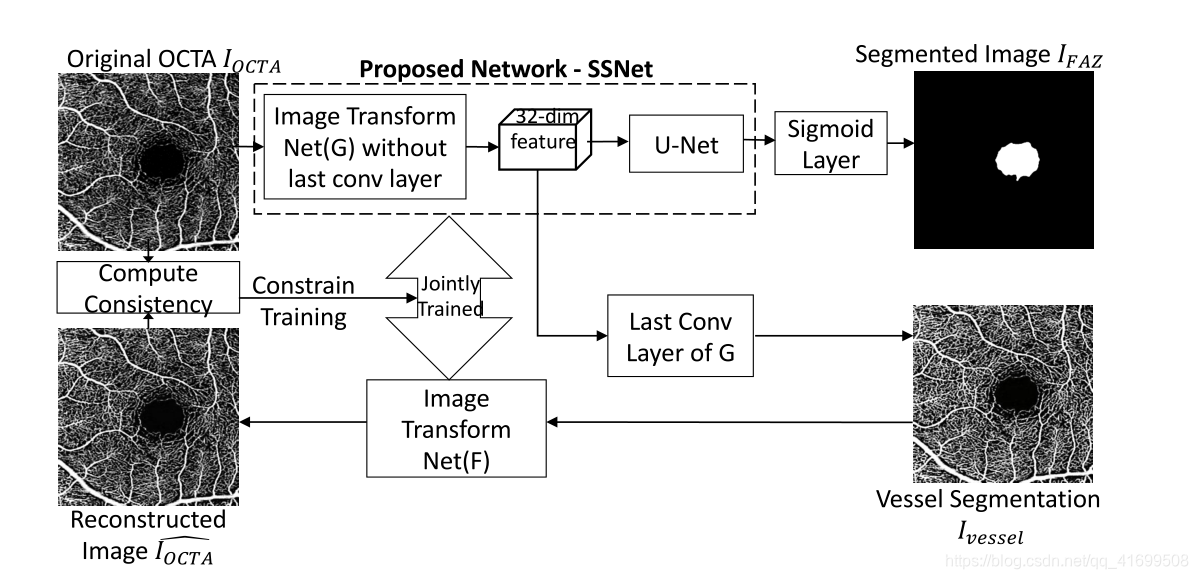
作者声称其血管分割部分是一个无监督分割任务,采用了风格转移方法
网络输入:OCTA的投影图
网络输出:1、FAZ分割图 2、血管分割图 3、OCTA重建图
用到的损失函数:
1、风格迁移网络G的损失(Content损失+Style损失)
2、风格迁移网络G的损失(Content损失+Style损失)
3、重建的OCTA图像与原图像的损失
4、Unet生成的FAZ分割图与ground true的损失
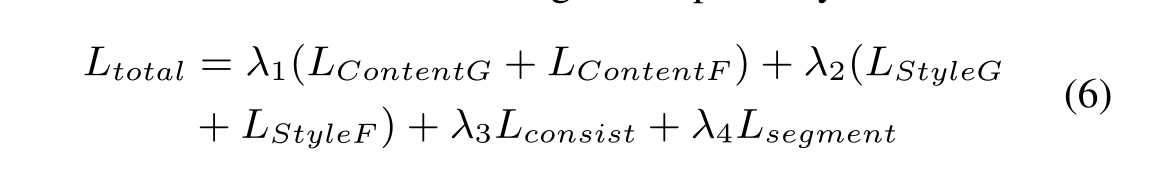
其中,he weights of content loss, style loss, consistency loss, and segmentation loss are set to be 1 × 10−2, 50, 1 × 10−2, 10, respectively.
风格迁移算法:有一个预训练好的网络,不更新权重。还有一个loss 网络,来做训练。
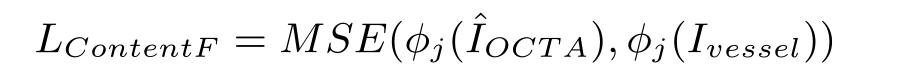
content loss是把血管分割图和输入的原图放入这个预训练好的网络中,去取出第j层的特征图,把这两个特征图拿来做均方误差损失。
网络G和F的风格损失如下所示:
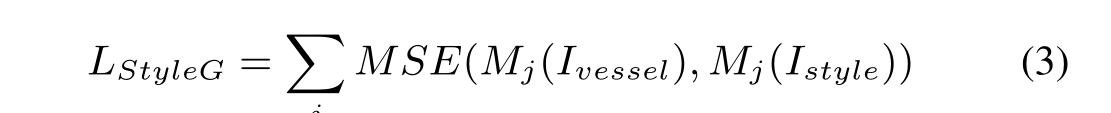
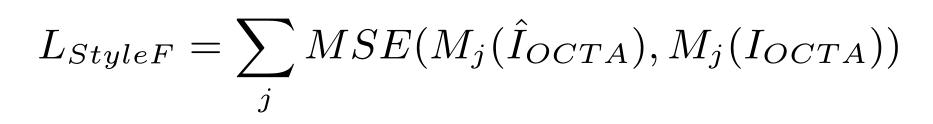
这个地方的Mj的算法引用了另一篇 文章
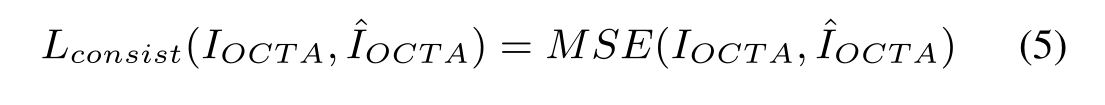
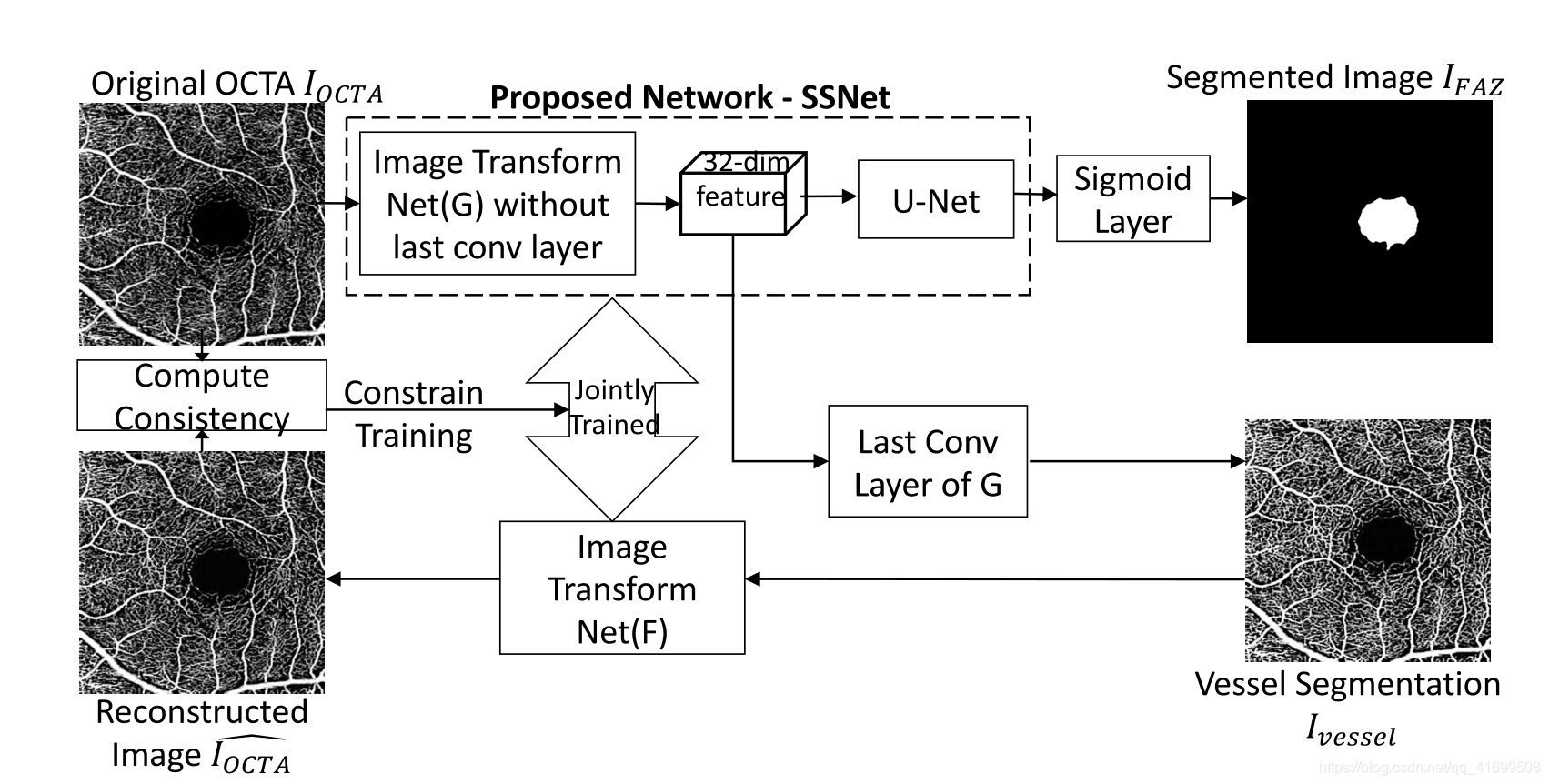
回到这张图,我们重新来梳理一遍本文的思路和逻辑。
1、首先我们有一个原始输入图片OCTA,有它的FAZ手工标签,有一个style图像(不是这个数据集的,不代表这个数据集的血管信息,只提供血管标签的风格)
2、然后我们将OCTA图像送入一个风格转移的网络中,这个网络的最后一层输出是一张图片,我们认为这张图片是血管分割图,用风格图像和content图像来与它做损失进行训练(PS:那为什么作者说这一个过程是无监督的呢?因为监督这个训练过程的是style image和content image,而content image就是输入的原图,style image则是其他数据集的label,并不是当前训练的输入图像对应的血管标签,所以认为这个过程是无监督的),与此同时,我们取出刚刚训练的网络的倒数第二层,他还是32dims的特征图,把它送入unet中训练,输出结果就是FAZ的分割图,直接让它与gt做loss。
3、得到了血管的无监督分割图后,我们再把这个分割图送入另一个风格迁移网络F中训练,在F中,OCTA原图现在是style label,而刚刚生成的血管分割图就是content image
4、F网络生成的OCTA’ ,再让这个OCTA’ 与OCTA做一致性损失
实验
数据集描述
OCTAGON3
包含55对3毫米× 3毫米的表层OCTA图像和形状为320 × 320的FAZ掩模。从10至69岁的18名健康受试者中获得36幅OCTA图像,从19名糖尿病患者中选择19幅图像。使用由专家1标注的groud true
sFAZDA TA
包含来自45名参与者的405张3毫米×3毫米表面OCTA图像,形状为704 × 704。每个参与者有9幅不同亮度和对比度的OCTA图像。
实验指标


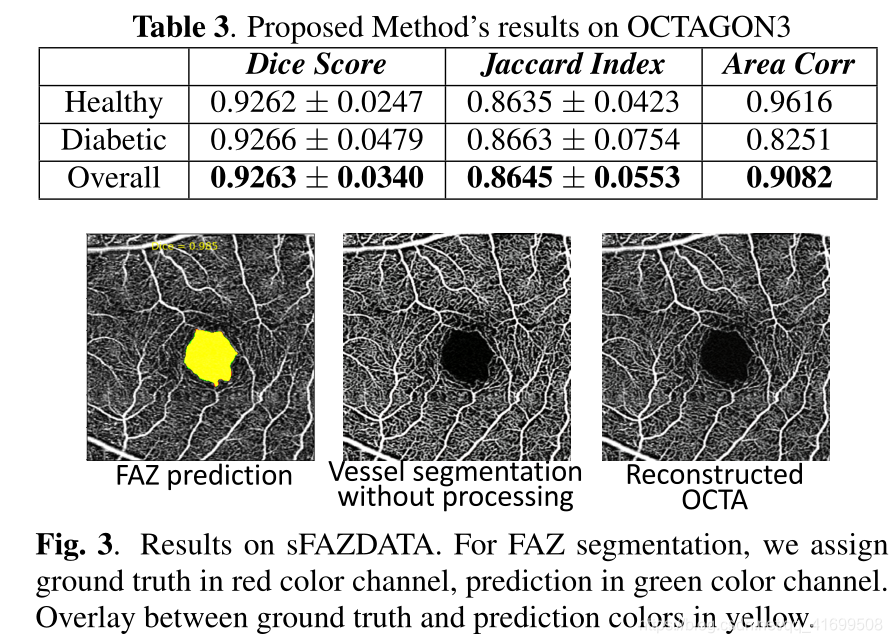
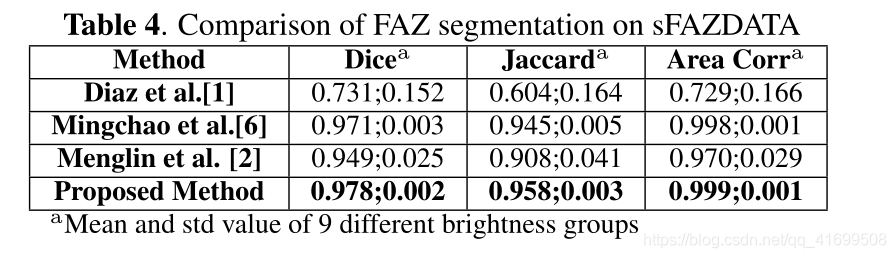
小结
首先这篇文章发表的会议还是很厉害的,文章的创新性很强。虽然用的都是成熟的网络的结合,但是把风格迁移的方法拿过来做分割还是很厉害,而且也利用到了RV(视网膜血管)与FAZ固有先验关系的特点。
不过感觉有的地方讲的不够清楚,得去翻看其参考文献才能更好的理解它














 3063
3063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









