






ELK Stack
Elasticsearch(存储+检索+分析),简称ES
Logstash(日志收集)
Kibana(可视化)
以上软件的安装请看上几篇博客
1、向es中插入数据
使用head插件向ES中新增一条数据并进行数据浏览

2、ES数据模型
Index:索引,由多个Document组成
Type:索引类型,6.x中仅支持一个,以后将逐渐被移除
Document:文档,由多个Field组成
Field:字段,包括字段名与字段值
3、ES与关系型数据库的对比

es中的索引相当于数据库
类型相当于与表 名称都是唯一的
一行信息 相当于一个document
Column 相当于filed 字段
4、文档(document)是ES的最小数据单元
原始数据:_source: 原始的json格式数据
文档元数据
_index:索引名
_type:索引类型
_id:文档编号
_version:文档版本号用于并发控制
_score:在搜索结果中的评分

5、文档管理
put 是增加或者更新
update 修改
delete 删除
get 查询
post 创建
head 改变或者删除
put:单行插入 put 必须要加_id post可以不用 会自己生成。

post /abc/article·/
{“id”:“6”,“title”:“标题wu”,“content”:“wodedaj”}
批量插入
post /_bulk 和put /_bulk 都可以使用

post /_bulk ----批量操作 增删改 —必须写在同一行
{“create”:{"_index":索引,"_type":类型,"_id":“编号”}}
{json串}
{“update”:{"_index":索引,"_type":类型,"_id":“编号”}}
“doc”:{json串}
{“delete”:{"_index":索引,"_type":类型,"_id":“编号”}}
批量读取文档
get /def/stu/_mget
{“docs”:[{"_id":1},{"_id":2}]}
GET def/_mget
{“docs”:[{"_type":“stu”,"_id":“1”},{"_type":“stu”,"_id":“2”}]}
GET /_mget
{“docs”:[{"_index":“def”,"_type":“stu”,"_id":“1”},{"_index":“def”,"_type":“stu”,"_id":“2”}]}
delete 删除
删除创建的文档 或者索引
delete demo
get 查询
索引管理
1、创建索引 查询索引
PUT demo.123 //创建索引
GET demo.123 //查看索引
2、带参数创建索引
PUT demo
{
“settings” : {
“index” : {
“number_of_shards” : 2,
“number_of_replicas” : 2
}
}
}
3、索引映射
映射:为了能够将时间域视为时间,数字域视为数字,字符串域视为全文或精确值字符串, Elasticsearch 需要知道每个域中数据的类型。这个信息包含在映射中。映射就是指明字段类型。
PUT demo.12345
{
“settings” : {
“number_of_shards” : 1
},
“mappings” : {
“_doc” : {
“properties” : {
“field1” : { “type” : “text” }//filed代表字段
}
}
}
}
ES的分布架构
节点
一个集群由多个节点组成,每个节点指定相同的cluster.name
主节点负责创建索引、删除索引、分配分片、追踪集群中的节点状态等
一个节点是一个ES实例,默认每个节点都可为候选主节点与数据节点,即:
node.master: true
node.data: true
索引:索引是指向一个或多个分片的逻辑命名空间
分片:
索引是指向一个或多个分片的逻辑命名空间
最小级别的工作单元,一个Lucene实例(倒排索引)
主分片
静态不可变
索引首先被存储在主分片中,然后复制相应的副本分片
副本分片
动态可修改
用于故障转移,一旦主分片失效,副本分片晋升为主分片
分片检索:
es的搜索方式
URI Search
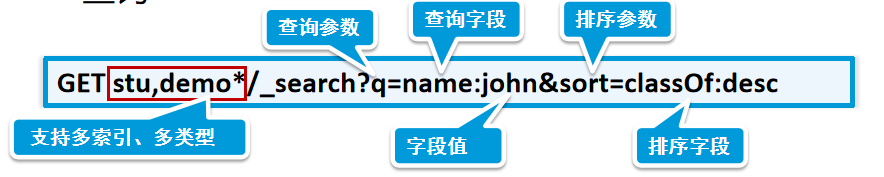
GET stu/_count —》获得document的数量
叶查询子句
用于在特定字段中查找特定值
match查询
1、match_all :返回所有文档
get /def/stu/_search
{
“query”:{
“match_all”:{
}
}
}
2、match :布尔匹配查询
get /def/stu/_search
{
“query”:{
“match”:{
“name”:“john kerry”//分词结果为john 和kerry 只要name字段中包含其中任意一个,就返回该文档
}
}
}
3、match_phrase:短语匹配查询
get /def/stu/_search
{
“query”:{
“match_phrase”:{
“name”:“john kerry”//分词结果为john 和kerry
如果name字段中依次包含所有分词,返回该文档
}
}
}
4、match_phrase_prefix:短语前缀匹配查询
GET /edf/stu/_search
{
“query”: {
“match_phrase_prefix”: {
“name”:“John Ke”//最后一个单词作为前缀匹配
}
}
}
5、multi_match:多字段匹配查询
GET /edf/stu/_search
{
“query”: {
“multi_match”: {
“query”: “John like cooking”,
“fields”: [“name”,“interest”]
}
}
}
term查询
term:词条查询
按照存储在倒排索引中的确切字词,对字段进行匹配
GET /edf/stu/_search
{
“query”: {
“term”:{
“name”:“john”
}
}
}
terms多词条查询:
GET /edf/stu/_search
{
“query”: {
“terms”:{
“name”:[“john”,“da”]
}
}
}
range查询
GET /edf/stu/_search
{
“query”: {
“range” : {
“yearOfBorn” : {
“gte” : 1995,
“lte” : 2000
}
}
}
}
复合查询子句
可以包含叶子或者其它的复杂查询语句
bool查询
GET /edf/stu/_search
{
“query”: {
“bool”: {
“must”: {
“match”: { “interest”: “cooking”} },
“must_not”: {
“range”: { “yearOfBorn”: { “gte”: 1995, “lte”: 2000 }}}
}
}
}















 1823
1823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









