







一、题目
题目链接:力扣
请从字符串中找出一个最长的不包含重复字符的子字符串,计算该最长子字符串的长度。
示例 1:
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
提示:
s.length <= 40000
二、题解
1、思路
🐎 动态规划
最长字串,直接想到动态规划。
"pwwkew"
动态规划四大步骤:
穷举分析
p→最长不重复子串长度为1;p;
pw→最长不重复子串长度为2;pw;
pww→最长不重复子串长度为2;pw;
pwwk→最长不重复子串长度为2;pw、wk;
pwwke→最长不重复子串长度为3;wke;
pwwkew→最长不重复子串长度为3;wke、kew。
分析找规律,拆分子问题
考虑问题:如何将当前字符串最长不重复子字符串长度,与上一个(甚至更往前一个)字符串最长子字符串长度联系起来。
最后面记录了我按照上面这个考虑问题的思路得到的一种“错误的”想法。
假设 dp[i] 为以 str[i] 结尾的(关键)子字符串的不重复字串长度(是最长)。设i从0开始。
通过分析我们发现,如下规律:
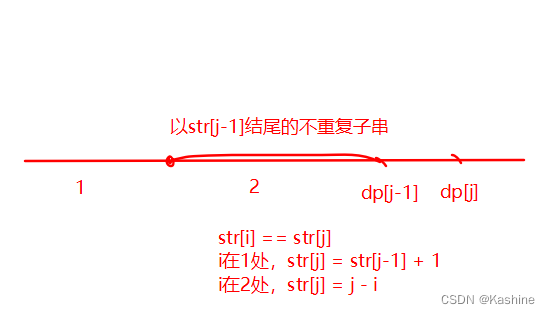
最简单的边界情况
dp[0]=1,以str[0]结尾的不重复子字符串长度。
状态转移方程
设字符 s[j] 左边距离最近的相同字符为 s[i] ,即 s[i]=s[j] 。
- 当 i < 0 ,即 s[j] 左边无相同字符,则 dp[j]=dp[j−1]+1 ;
- 当 dp[j−1]<j−i ,说明字符 s[i] 在子字符串 dp[j−1] 区间之外 ,则 dp[j]=dp[j−1]+1 ;
- 当 dp[j−1]≥j−i ,说明字符 s[i] 在子字符串 dp[j−1] 区间之中 ,则 dp[j] 的左边界由 s[i] 决定,即 dp[j] = j - i;
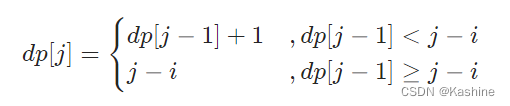
max(dp) ,即 “最长不重复子字符串” 的长度。
下面举个例子,比如“abcdbaa”,索引从0开始。 我们容易得到,当 j = 4时,以s[4]结尾字符串sub[4] = “cdb”的 长度dp[4] =3。 接下来我们看 j +1的情况。根据定义,sub[4]字符串中的字符肯定不重复,所以当 j = 5时,这时距离字符s[5]的左侧的重复字符a的索引 i = 0, 也就是说s[ 0 ]在子字符串sub[ 4 ]之外了,以s[5]结尾的字符串自然在sub[4]的基础上加上字符s[5]就构成了新的最长的不重复的子串sub[5],长度dp[5] = dp[4] + 1; 接下来我们继续看 j =6的情况,这时s[6]的左侧重复字符a的索引 i = 5,该重复字符在sub[ 5 ]中。新的最长不重复的字串sub[6]左边界以 i 结尾,长度dp[6] = j - i = 1。
🐎 滑动窗口
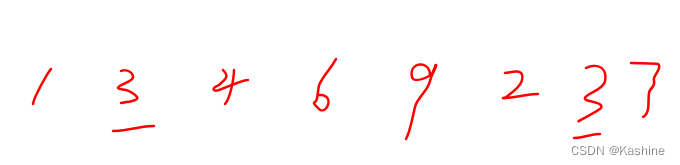
以示例一中的字符串 abcabcbb 为例:
以 (a)bcabcbb 开始的最长字符串为 (abc)abcbb;
以 a(b)cabcbb 开始的最长字符串为 a(bca)bcbb;
以 ab(c)abcbb 开始的最长字符串为 ab(cab)cbb;
以 abc(a)bcbb 开始的最长字符串为 abc(abc)bb;
以 abca(b)cbb 开始的最长字符串为 abca(bc)bb;
以 abcab(c)bb 开始的最长字符串为 abcab(cb)b;
以 abcabc(b)b 开始的最长字符串为 abcabc(b)b;
以 abcabcb(b) 开始的最长字符串为 abcabcb(b)。
假设我们选择字符串中的第 k 个字符作为起始位置,并且得到了不包含重复字符的最长子串的结束位置为 rk 。那么当我们选择第 k+1 个字符作为起始位置时,首先从 k+1 到 rk 的字符显然是不重复的,并且由于少了原本的第 k 个字符,我们可以尝试继续增大 rk,直到右侧出现了重复字符为止。
一句话讲就是右指针遇到重复字符时,左指针跳到子串里第一个重复字符下一个位置,并且把哈希表中子串中重复字符及其之前的字符去掉,重新右指针再往右扩展。
本质:寻找所有以当前字符结尾的子字符串长度,取最大值!
看下面代码理解:
- 在没有遇到相同的时候,left不动,right一直+1,right - left +1 即以当前字符结尾的不重复子串长度;
- 当遇到相同的时候,更新哈希表,并将left移动到前面重复字符的下一个位置,即计算以当前字符结尾的不重复子串长度。
发现没有,和上面动态规划一毛一样?
- 上方第一条就是动态规划第二条;
- 上方第二条就是动态规划第三条。
- 但是动态规划侧重点不一样,动态规划侧重与上一个字符结尾的不重复字符串长度的关系,双指针侧重当前不重复子串长度的直接查找。
2、代码实现
🐎 动态规划
class Solution {
public:
int lengthOfLongestSubstring(string s) {
int size = s.size();
if(size < 2)return size;
// if(s.size() == 0)return 0;// 空串
// if(s.size() == 1)return 1;// 只有一个字符
unordered_map<char, int> mp;
mp[s[0]] = 0;// 一定要将s[0]加入哈希表
int res_max = 0;// 最大子串,一定会被修改
int last_dp = 1;// dp[j-1],初始化为dp[0]=1
int i = 0;// s[i] == s[j]
for(int j = 1; j < size; j++)
{
// 寻找s[i]的位置,s[i]==s[j]
if(mp.find(s[j]) == mp.end())i = -1;
else i = mp[s[j]];
// 记录字符最后一次出现的位置,因为上方找的是最后一个
mp[s[j]] = j;
// 根据i所在的位置和dp[j-1]判断dp[j]
last_dp = last_dp < j-i ? last_dp+1 : j-i;
//cout<< s[j]<< " "<< last_dp<<endl;
res_max = max(res_max, last_dp);
}
return res_max;
}
};🐎 滑动窗口
class Solution {
public:
int lengthOfLongestSubstring(string s) {
unordered_set<char> window;
int res_max = 0;// 一定要初始化为0,不然s为空的时候无法进入循环,直接返回该值
int left = 0, right = 0;
for(int right = 0; right < s.length(); ++right)
{
// 如果没有重复的,右指针右移并记录到哈希表
if(window.find(s[right]) == window.end())
{
window.insert(s[right]);
}
else// 遇到重复的左指针移动到重复元素后一个位置,并删除哈希表中重复字符及其前面所有内容
{
while(s[left] != s[right])
{
window.erase(s[left]);
++left;
}
left += 1;
}
res_max = max(right - left + 1, res_max);
}
return res_max;
}
};3、复杂度分析
🐎 动态规划
时间复杂度:O(n);
空间复杂度:O(1)。哈希表最多存放26个内容,因为只有26个字母。如果其他字符也可以,如%#@!,最多只有128个。
🐎 滑动窗口
时间复杂度:O(n);
空间复杂度:O(1)。哈希表最多存放26个内容,因为只有26个字母。如果其他字符也可以,如%#@!,最多只有128个。
4、运行结果
🐎 动态规划
🐎 滑动窗口
附录:一个“误导”我的想法
最初的一个错误想法,也不能说错误,只能说难以实现,不如“官方”的简单,直接忽略不看哈。
穷举分析
p→最长不重复子串长度为1;p;
pw→最长不重复子串长度为2;pw;
pww→最长不重复子串长度为2;pw;
pwwk→最长不重复子串长度为2;pw、wk;
pwwke→最长不重复子串长度为3;wke;
pwwkew→最长不重复子串长度为3;wke、kew。
分析找规律,拆分子问题
pw是在p的基础上,max( w能够和p后方构成的最长子串长度2,p的最长不重复子串长度1 )=2。
pww,max( w能够和p后方构成的最长子串长度1,pw的最长不重复子串长度2 )=2。
pwwk,max( w能够和p后方构成的最长子串长度2,pww的最长不重复子串长度2 )=2。
pwwke,max( w能够和p后方构成的最长子串长度3,pwwk的最长不重复子串长度2 )=3。
pwwkew,max( w能够和p后方构成的最长子串长度3,pwwke的最长不重复子串长度3 )=3。
最简单的边界情况
假设dp[i]为以str[i]结尾的字符串(该字符串可能包含重复内容)最长不重复字串长度。设i从0开始。
dp[0] = 1 一个字符最长不重复子串长度为1。
状态转移方程
dp[i] = max( dp[i-1], str[i]和前面结合的最大不重复字串长度 )
"pwwkew"
k前方无重复k,但是有重复w,而且难以判断w位于前方可能重复的k的相对位置,因此,本方法实现困难。
















 500
500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











