






AI算法之一 的Attention机制到底是什么,你知道吗?
这里写目录标题
1. Attention 的本质
Attention(注意力)机制的本质:关注全部 → 关注重点
Attention机制最早在计算机视觉里应用的,随后在NLP领域开始应用,真正发扬光大实在NLP领域。
2. Attention的3大优点
- 参数少 : 与CNN、RNN相比,复杂度更小。
- 速度快: 解决了RNN不能并行计算问题。Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行计算。
- 效果好:Attention能够挑重点,就算文本比较长,也不丢失重要信息。
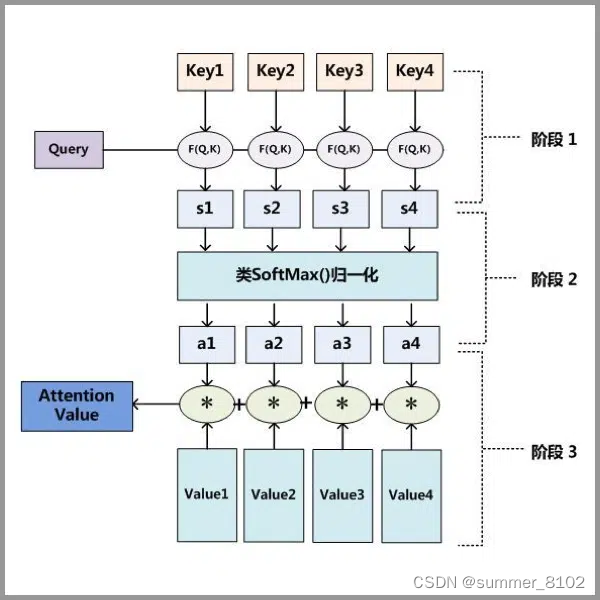
3. Attention的原理
小故事理解Attention原理:
当一位学生在准备期末考试时(query),他可能会对不同科目的知识点进行复习(value)。对于他最感兴趣的科目或者他认为考试可能重点考查的内容,他会花更多的时间和精力进行深入的学习和复习(高权重)。而对于他认为不太重要或者已经熟悉的内容,他可能只需快速浏览一下以确认自己的掌握程度(低权重)。通过这种方式,他可以在有限的时间内有效地准备并且对考试内容有一个全面的了解。
STEP1: query和key进行相似度计算,得到权值s_i
STEP2: 将权值进行归一化,得到直接可用的权重a_i
STEP3: 将权重a_i和value进行加权求和
3.Attention的类型
Attention有多种类型:Soft Attention、Hard Attention、静态Attention、动态Attention、Self Attention等等。
3.1计算区域
- Soft Attention: 是比较常见的Attention方式,对所有key求权重概率,每个key都有一个对应的权重,是一种全局的计算方式(也可以叫Global Attention)。这种方式参考了所有key的内容,考虑的比较全面,但是计算量可能比较大。
- Hard Attention: 直接精准定位到某个key,其余key不管,可以理解为这个key的概率为1,其余的为0。这种方式要求很高,要求一部到位,如果没有正确对齐,会带来很大的影响。另一方面,因为不可导,一般需要强化学习的方法进行训练。
- Local Attention: 是以上两种方式的一个这种,对一个窗口区域进行计算。先用Hard方式定位到某个地方,以这个点为中心可以得到一个窗口区域,在这个区域内用Soft方式来求Attention。
3.2 所用信息
假设我们要对一段原文计算Attention,这里原文指的是我们要做attention的文本,那么所用信息包括内部信息和外部信息,内部信息指的是原文本身的信息,而外部信息指的是除原文以外的额外信息。
- General Attention:这种方式利用到了外部信息,常用于需要构建两段文本关系的任务,query一般包含了额外信息,根据外部query对原文进行对齐。
比如在阅读理解任务中,需要构建问题和文章的关联,假设现在baseline是,对问题计算出一个问题向量q,把这个q和所有的文章词向量拼接起来,输入到LSTM中进行建模。那么在这个模型中,文章所有词向量共享同一个问题向量,现在我们想让文章每一步的词向量都有一个不同的问题向量,也就是,在每一步使用文章在该步下的词向量对问题来算 attention,这里问题属于原文,文章词向量就属于外部信息。
- Local Attention:这种方式只使用内部信息,key和value以及query只和输入原文有关,在self attention中,key=value=query。既然没有外部信息,那么在原文中的每个词可以跟该句子中的所有词进行Attention计算,相当于寻找原文内部的关系。
还是举阅读理解任务的例子,上面的baseline中提到,对问题计算出一个向量q,那么这里也可以用上attention,只用问题自身的信息去做attention,而不引入文章信息。
3.3 结构层次
-
单层Attention: 这是比较普遍的做法,用一个query对一段原文进行一次attention。
-
多层Attention: 一般用于文本具有层次关系的模型,假设我们把一个文档划分成多个句子,在第一层,我们分别对每个句子使用attention计算出一个句向量(也就是单层attention);在第二层,我们对所有句向量再做attention计算出一个文档向量(也是一个单层attention),最后再用这个文档向量去做任务。
-
多头Attention:这是Attention is All You Need中提到的multi-head attention,用到了多个query对一段原文进行了多次attention,每个query都关注到原文的不同部分,相当于重复做多次单层attention:
head_i = Attention(q_i,K,V)
最后再把这些结果拼接起来:
MutiHead(Q,K,V) = Concat(head_1,…,head_h)W
4. 模型方面
从模型上看, Attention一般用在CNN和LSTM上,也可以直接进行纯Attention计算。
- CNN+Attention
- LSTM+Attention
- 纯Attention
5. 相似度计算
在做attention的时候,我们需要计算query和某个key的相似度,常用方法:
- 点乘
- 矩阵相乘
- cos相似度
- 串联方式
- 用多层感知机















 2268
2268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









