



以下是一份自然语言处理(NLP)与大模型领域的领域大图,涵盖技术框架、发展脉络、交叉融合点和应用场景的完整解析:
1. 核心技术体系
-
基础分析层级
- 词法分析:分词、词性标注、命名实体识别
- 句法分析:依存句法树、短语结构分析
- 语义分析:词义消歧、指代消解、语义角色标注
- 篇章分析:主题建模、情感分析、文本摘要
-
关键技术分类
- 文本处理:分词、停用词过滤、词干提取
- 语义建模:词嵌入(Word2Vec、GloVe)、上下文表示(ELMo、BERT)
- 生成技术:序列到序列模型(Seq2Seq)、注意力机制(Transformer)
- 任务范式:文本分类、机器翻译、问答系统、对话生成
-
方法学演进
- 规则驱动:基于语法和词典的专家系统
- 统计学习:隐马尔可夫模型(HMM)、条件随机场(CRF)
- 深度学习:RNN、LSTM、CNN
- 预训练范式:BERT(双向编码)、GPT(自回归生成)
2. 典型应用场景
- 企业服务:智能客服(ChatGPT)、合同信息抽取
- 医疗健康:病历分析、药物副作用检测
- 金融风控:新闻情感分析、风险预测
- 多语言应用:机器翻译、低资源语言处理
大模型领域大图
1. 技术演进阶段
-
发展阶段划分
- 1.0传统模型:SVM、决策树
- 2.0深度学习:CNN、RNN
- 3.0预训练模型:BERT、GPT-3
- 4.0多模态模型:CLIP、Gato
-
核心架构突破
- Transformer革命:自注意力机制实现并行化长序列处理
- 参数规模跃迁:从百万级(LSTM)到万亿级(GPT-4)
- 训练范式创新:无监督预训练 + 任务微调
-
代表性模型家族
- 编码器架构:BERT(双向语义理解)、RoBERTa
- 解码器架构:GPT系列(自回归生成)、PaLM
- 多模态架构:DALL-E(图文生成)、Flamingo(跨模态推理)
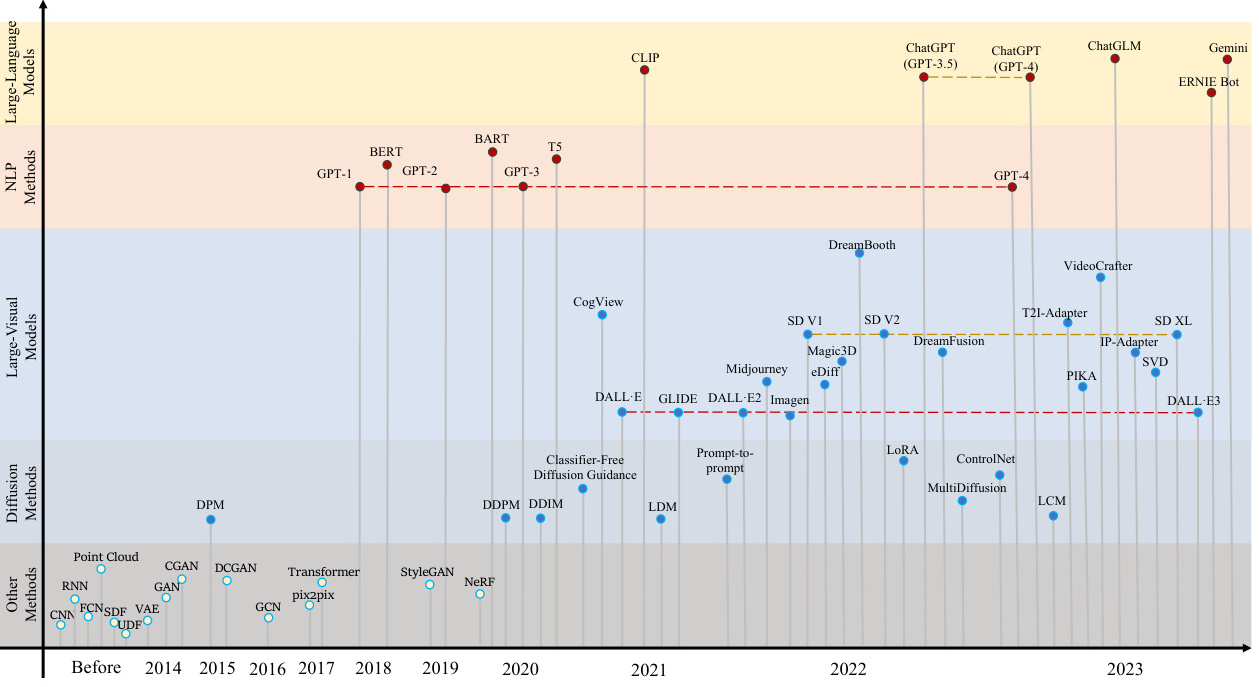
2. 关键驱动力
- 算力支持:GPU/TPU集群、分布式训练优化
- 数据积累:互联网文本、多模态语料库
- 算法创新:混合专家(MoE)、稀疏激活
交叉融合与前沿趋势
1. 技术融合点
-
架构统一性
- Transformer成为NLP与大模型的共同基础架构,支持语义理解和生成任务。
- 预训练技术(如BERT)被整合到多模态模型中,实现文本-图像联合表征。
-
能力扩展
- Few/Zero-Shot学习:GPT-3无需微调即可完成新任务。
- 逻辑推理:ChatGPT通过指令微调实现数学问题求解。
-
应用升级
- 多模态交互:医疗领域结合文本病历与医学影像分析。
- 领域自适应:行业大模型(如金融风控)通过微调提升专业任务性能。
2. 当前研究热点
- 高效计算:模型压缩(知识蒸馏)、低秩适配(LoRA)
- 可信AI:减少偏见、增强可解释性(如LIME分析)
- 具身智能:语言模型驱动机器人执行物理任务
技术工具链对比
| 框架类型 | 代表工具 | 特点 | 适用场景 |
|---|---|---|---|
| 开源框架 | Hugging Face Transformers | 预训练模型库丰富,社区支持活跃 | 学术研究、快速原型开发 |
| 商业平台 | OpenAI API | 闭源但接口易用,支持多模态 | 企业级应用、无代码部署 |
| 混合生态 | PyTorch + ONNX | 灵活性与部署效率平衡 | 工业界模型优化与落地 |
总结
自然语言处理与大模型领域正通过架构统一性(如Transformer)、能力泛化性(Few-Shot学习)和多模态扩展实现深度融合。未来趋势将围绕高效可信(降低计算成本与伦理风险)和跨域协同(文本-图像-代码联合建模)展开,推动AI从感知智能向认知智能演进。


















 2015
2015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











