







哈希表&位图&Bloom Filter
一、哈希表
1. 哈希表理论知识
有序关联容器:set、multiset、map、multimap,底层用红黑树
无序关联容器:unordered_set和unordered_map,底层用链式哈希表。
- 面试介绍哈希表:一个关键字,经过散列函数进行映射,得到的它在表中的存储位置,符合这样的key及其映射关系后得到在表中的存储位置,这样的表就叫做散列表或者哈希表。然后可以解释哈希冲突的问题,再解释解决哈希冲突的线性探测哈希表和链式哈希表。
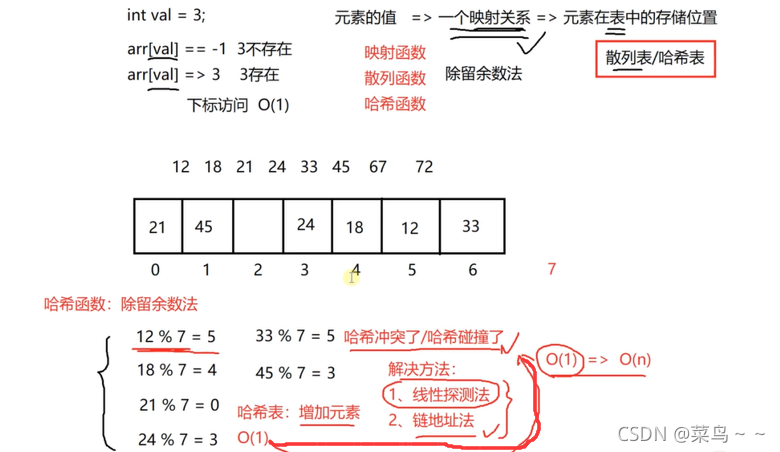
哈希表的时间复杂度趋近于O(1),由于哈希冲突的增加,可能会达到O(n)
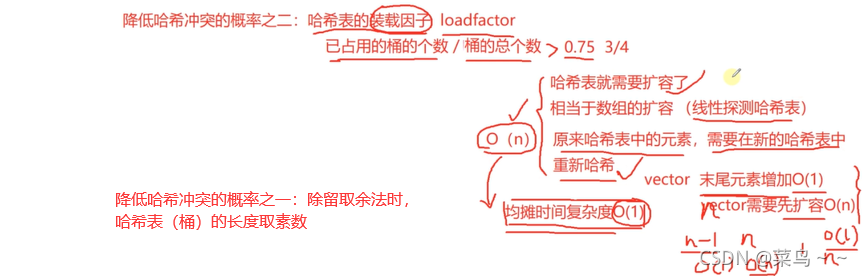
- 优势:适用于快速查找,时间复杂度趋近于O(1)
- 缺点:占用内存空间比较大,空间效率不高
- 散列函数

- 散列冲突处理

2. 线性探测哈希表


代码实现
#include<iostream>
using namespace std;
enum State
{
STATE_UNUSE,//从未使用过的桶
STATE_USING,//正在使用的桶
STATE_DEL,//元素被删除的桶
};
class Bucket
{
public:
Bucket(int key=0,State state=STATE_UNUSE)
:_key(key),_state(state){}
int _key;//存储数据
State _state;//存储状态
};
class HashTable
{
private:
Bucket* _table;//动态开辟的哈希表
int _tableSize;//桶的大小
int _useBucketNum;//正在使用的桶个数
double _loadFactor;//装载因子
//在C++11以后,静态常量的整型类型在类里面可以直接初始化
static const int _primeSize = 10;//素数大小
static int _primes[_primeSize];//素数表
int _primeIdx;//当前使用的素数下标
void expand()
{
++_primeIdx;
if (_primeIdx == _primeSize)
{
throw "hashtable is too large,can not expand anymore";
}
Bucket* newTable = new Bucket[_primes[_primeIdx]];
for (int i = 0; i < _tableSize; i++)
{
if (_table[i]._state == STATE_USING)
{
int idx = _table[i]._key % _primes[_primeIdx];
int k = idx;
do
{
if (newTable[k]._state == STATE_UNUSE)
{
newTable[k]._key = _table[i]._key;
newTable[k]._state = STATE_USING;
break;
}
k = (k + 1) % _primes[_primeIdx];
} while (k != idx);
}
}
delete[]_table;
_table = newTable;
_tableSize = _primes[_primeIdx];
}
public:
HashTable(int size = _primes[0], double loadFactor = 0.75)
:_useBucketNum(0), _loadFactor(loadFactor), _primeIdx(0)
{
//把用户传入的size调整到最近的比较大的素数上
if (size != _primes[0])
{
for (; _primeIdx < _primeSize; _primeIdx++)
{
if (_primes[_primeIdx] > size)
{
break;
}
}
//用户传入的size过大已经超过了最后一个数,调整为最后一个数
if(_primeIdx == _primeSize)
_primeIdx--;
}
_tableSize = _primes[_primeIdx];
_table = new Bucket[_tableSize];
}
~HashTable()
{
delete[]_table;
_table = nullptr;
}
bool insert(int key)
{
//考虑扩容
double factor = _useBucketNum * 1.0 / _tableSize;
if (factor > 0.75)
{
expand();
}
int idx = key % _tableSize;
int i = idx;
do
{
if (_table[i]._state == STATE_UNUSE)
{
_table[i]._key = key;
_table[i]._state = STATE_USING;
_useBucketNum++;
return true;
}
i = (i + 1) % _tableSize;
} while (i != idx);
}
bool erase(int key)
{
int idx = key % _tableSize;
int i = idx;
do
{
if (_table[i]._state == STATE_USING && _table[i]._key == key)
{
_table[i]._state = STATE_DEL;
_useBucketNum--;
break;
}
i = (i + 1) % _tableSize;
} while (_table[i]._state != STATE_UNUSE && i != idx);
return true;
}
bool find(int key)
{
int idx = key % _tableSize;
int i = idx;
do
{
if (_table[i]._key == key && _table[i]._state == STATE_USING)
{
return true;
}
i = (i + 1) % _tableSize;
} while (_table[i]._state != STATE_UNUSE && i != idx);
return false;
}
};
int HashTable::_primes[_primeSize] = { 3,7,23,47,97,251,443,911,1471,42773 };
int main()
{
HashTable htable;
htable.insert(12);
htable.insert(24);
htable.insert(38);
htable.insert(15);
htable.insert(14);
cout << htable.find(12) << endl;
htable.erase(12);
cout << htable.find(12) << endl;
}
3. 链式哈希表
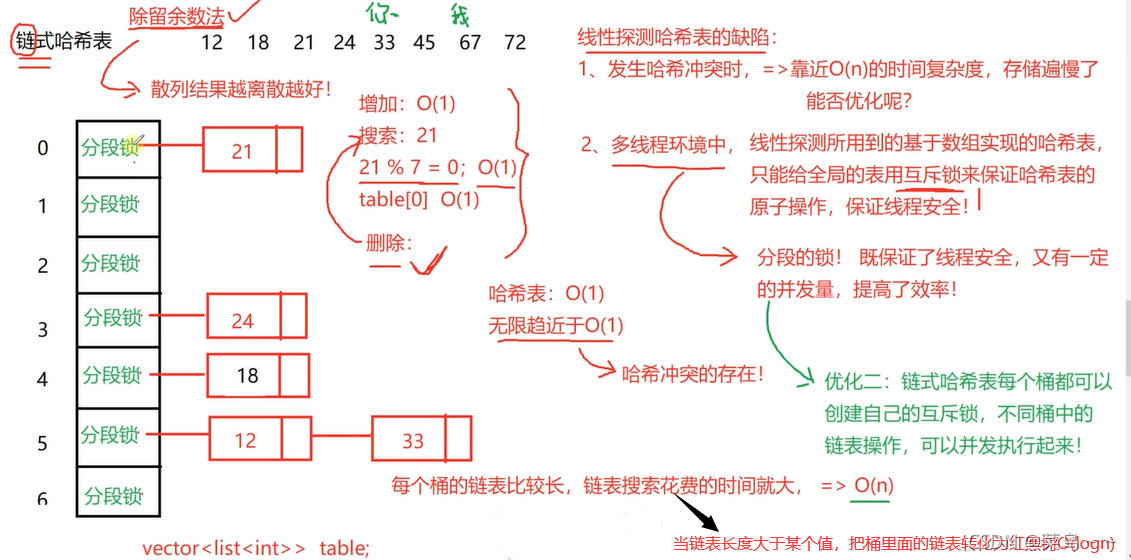
#include<iostream>
#include<vector>
#include<list>
#include<algorithm>
using namespace std;
class HashTable
{
private:
vector<list<int>> _table;
int _useBucketNum;
double _loadFactor;
static const int _primeSize = 10;
static int _primes[_primeSize];
int _primeIdx;
void expand()
{
++_primeIdx;
if (_primeIdx == _primeSize)
throw "hashtable is too large,can not expand anymore";
vector<list<int>> oldTable;
_table.swap(oldTable);
_table.resize(_primes[_primeIdx]);
for (auto list : oldTable)
{
for (auto key : list)
{
int idx = key % _primes[_primeIdx];
if (_table[idx].empty())
{
_useBucketNum++;
}
_table[idx].emplace_front(key);
}
}
}
public:
HashTable(int size = _primes[0], double loadFactor = 0.75)
:_useBucketNum(0), _loadFactor(loadFactor), _primeIdx(0)
{
if (size != _primes[0])
{
for (; _primeIdx < _primeSize; ++_primeIdx)
{
if (_primes[_primeIdx] > size)
{
break;
}
}
if (_primeIdx == _primeSize)
{
_primeIdx--;
}
}
_table.resize(_primes[_primeIdx]);
}
void insert(int key)
{
double factor = _useBucketNum * 1.0 / _table.size();
cout << factor << endl;
if (factor > 0.75)
{
expand();
}
int idx = key % _table.size();
if (_table[idx].empty())//O(1)
{
_useBucketNum++;
_table[idx].emplace_front(key);
}
else
{
auto it = ::find(_table[idx].begin(), _table[idx].end(), key);//O(n)
if (it == _table[idx].end())
{
//key不存在
_table[idx].emplace_front(key);
}
}
}
void erase(int key)
{
int idx = key % _table.size();//O(1)
//如果链表节点过长,如果散列函数比较集中,(散列函数有问题!)
// 如果散列比较离散,链表长度一般不会过长,因为有装载因子
auto it = ::find(_table[idx].begin(), _table[idx].end(), key);//O(n)
if (it != _table[idx].end())
{
_table[idx].erase(it);
if (_table[idx].empty())
{
_useBucketNum--;
}
}
}
bool find(int key)
{
int idx = key % _table.size();//O(1)
auto it = ::find(_table[idx].begin(), _table[idx].end(), key);//O(n)
return it != _table[idx].end();
}
};
int HashTable::_primes[_primeSize] = { 3,7,23,47,97,251,443,911,1471,42773 };
int main()
{
HashTable htable;
htable.insert(12);
htable.insert(24);
htable.insert(38);
htable.insert(15);
htable.insert(14);
htable.insert(40);
htable.insert(93);
cout << htable.find(12) << endl;
htable.erase(12);
cout << htable.find(12) << endl;
}
vec1.swap(vec2):如果两个容器使用的空间配置器allocator是一样的,那么直接交换两个容器的成员变量即可,效率高!如果两个容器使用的空间配置器allocator是不一样的,那么意味着两个容器管理外部堆内存的方式不一样,需要效率低的整个数据的交换。
4. 哈希表应用
查重或者统计重复的次数,查询的效率高但是占用内存空间较大。
(1)找出第一个重复出现的数字
#include<iostream>
#include<time.h>
#include<vector>
#include<unordered_set>
#include<unordered_map>
using namespace std;
int main()
{
vector<int> vec;
srand(time(0));
for (int i = 0; i < 1000; i++)
{
vec.push_back(rand() % 1000 + 1);
}
unordered_set<int> s1;
for (auto key : vec)
{
auto it = s1.find(key);
if (it == s1.end())
{
s1.insert(key);
}
else
{
cout << "key:" << key << endl;
break;
}
}
return 0;
}
(2)找出所有重复的数字
#include<iostream>
#include<time.h>
#include<vector>
#include<unordered_set>
#include<unordered_map>
using namespace std;
int main()
{
vector<int> vec;
srand(time(0));
for (int i = 0; i < 1000; i++)
{
vec.push_back(rand() % 1000 + 1);
}
unordered_set<int> s1;
for (auto key : vec)
{
auto it = s1.find(key);
if (it == s1.end())
{
s1.insert(key);
}
else
{
cout << "key:" << key << endl;
}
}
return 0;
}
(3)统计重复出现的数字以及出现的次数
#include<iostream>
#include<time.h>
#include<vector>
#include<unordered_set>
#include<unordered_map>
using namespace std;
int main()
{
vector<int> vec;
srand(time(0));
for (int i = 0; i < 1000; i++)
{
vec.push_back(rand() % 1000 + 1);
}
unordered_map<int, int> m1;
for (auto key : vec)
{
/*
auto it = m1.find(key);
if (it == m1.end())
{
m1.emplace(key, 1);
}
else
{
it->second += 1;
}
*/
m1[key]++;
}
for (auto pair : m1)
{
if (pair.second>1)
{
cout << "key:" << pair.first << " num:" << pair.second << endl;
}
}
return 0;
}
(4)一组数据有些数字是重复的,把重复的数字过滤掉,每个数字只出现一次
#include<iostream>
#include<time.h>
#include<vector>
#include<unordered_set>
#include<unordered_map>
using namespace std;
int main()
{
vector<int> vec;
srand(time(0));
for (int i = 0; i < 1000; i++)
{
vec.push_back(rand() % 1000 + 1);
}
unordered_set<int> s1;
for (auto key : vec)
{
s1.emplace(key);
}
return 0;
}
(5)找出第一个没有重复出现的字符
#include<iostream>
#include<time.h>
#include<vector>
#include<unordered_set>
#include<unordered_map>
#include<string.h>
using namespace std;
int main()
{
string s = "dwefwerfcsadwar";
unordered_map<int, int> m1;
for (auto ch : s)
{
m1[ch]++;
}
for (auto ch : s)
{
if (m1[ch] == 1)
{
cout << ch << endl;
return 0;
}
}
cout << "所有字符都重复出现过" << endl;
return 0;
}
(6)有两个文件分别是a和b,里面放了很多ip地址(url地址、email地址),让你找出两个文件重复的ip并输出出来。

(7)有两个文件分别是a和b,各自存放约1亿条ip地址,每个ip地址是4B, 限制使用100M,让找出来两个文件中重复的ip地址并输出。
采用分治思想。

二、 位图算法

数字是否出现过的状态,存储在一个位数组当中。
位图数组的长度:根据最大值来确定位图数组的长度,要找出这组数字中的最大值, 因为小的值在位图数组里肯定是靠前存放,大的值肯定是靠后存放,只要保证大的位能够表示出来,那么前面这些小的位肯定能表示出来。

问题:

用哈希表解决
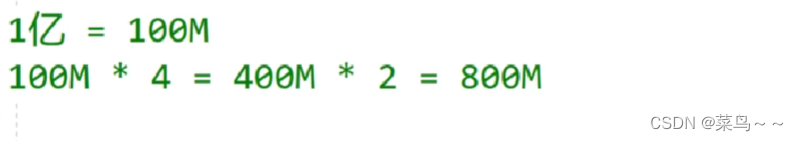
用位图算法

可以发现相比哈希表,位图算法非常省内存的,但是它有一些限制,需要知道数组中的最大值。
位图数组代码实现:
#include<iostream>
#include<vector>
using namespace std;
int main()
{
vector<int> vec = { 12,34,56,12,43,67,87,62,43 };
//定义位图数组
int max=vec[0];
for (auto key : vec)//O(n)
{
if (max < key)
{
max = key;
}
}
//定义的位图数组所有位要初始化0,表示元素没出现过
int* bitmap = new int[max / 32 + 1]();
unique_ptr<int> ptr(bitmap);
for (auto key : vec)
{
int index = key / 32;
int offset = key % 32;
//取k对应的位的值
if (0 == (bitmap[index] & (1 << offset)))
{
bitmap[index] |= (1 << offset);
}
else
{
//找第一个重复出现的数
//cout << key << "是第一个重复出现的数字" << endl;
//break;
//找所有重复出现过的数
cout << key << "重复出现过" << endl;
}
}
return 0;
}
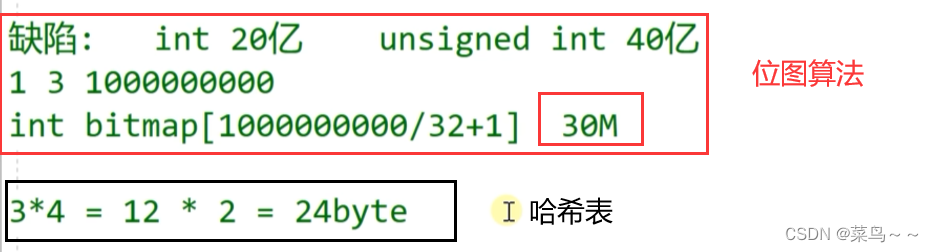
位图算法的缺陷:
- 不好处理谁是第一个不重复的,因为找第一个不重复的要统计次数,但是在位图数组里只能记录是否出现过,而不能记录出现了几次,表示不了这么多状态。可以这样做:原来用1个位保存数据的状态,现在用2个位保存数据的状态,比较麻烦。
- 比如有一组数据1,3,1000000000
位图算法推荐使用的场景:数据的个数>=序列里面数字的最大值
三、 布隆过滤器Bloom Filter
布隆过滤器在大数据查重、缓存服务器redis里面、黑名单过滤、钓鱼网站过滤、url过滤这些场景中非常常见。
布隆过滤器可以弥补哈希表占用内存空间比较大,位图确实省空间,但是存在像1,3,1000000这种问题比较浪费空间。布隆过滤器可以结合位图和哈希,是一种更高级的位图解决方案,效率高而且省内存。

Bloom Filter注意事项:



只要能接受一定的误判率用布隆过滤器也是可以的。


代码实现:
class BloomFilter
{
private:
int _bitSize;//位图长度
vector<int> _bitMap;//位图数组
public:
BloomFilter(int bitSize = 1471)
:_bitSize(bitSize)
{
_bitMap.resize(bitSize / 32 + 1);
}
//添加元素 O(1)
void setBit(const char* str)
{
//计算k组哈希函数的值
int idx1 = BKDHash(str) % _bitSize;
int idx2 = RSHash(str) % _bitSize;
int idx3 = APHash(str) % _bitSize;
//把相应的idx1,idx2,idx3这几位全置为1
int index = 0;
int offset = 0;
index = idx1 / 32;
offset = idx1 % 32;
_bitMap[index] |= (1 << offset);
index = idx2 / 32;
offset = idx2 % 32;
_bitMap[index] |= (1 << offset);
index = idx3 / 32;
offset = idx3 % 32;
_bitMap[index] |= (1 << offset);
}
//查询元素 O(1)
bool getBit(const char* str)
{
//计算k组哈希函数的值
int idx1 = BKDHash(str) % _bitSize;
int idx2 = RSHash(str) % _bitSize;
int idx3 = APHash(str) % _bitSize;
int index = 0;
int offset = 0;
index = idx1 / 32;
offset = idx1 % 32;
if (0 == (_bitMap[index] & (1 << offset)))
{
return false;
}
index = idx2 / 32;
offset = idx2 % 32;
if (0 == (_bitMap[index] & (1 << offset)))
{
return false;
}
index = idx3 / 32;
offset = idx3 % 32;
if (0 == (_bitMap[index] & (1 << offset)))
{
return false;
}
return true;
}
};
//URL黑名单
class BlackList
{
private:
BloomFilter _blockList;
public:
void add(string url)
{
_blockList.setBit(url.c_str());
}
bool query(string url)
{
return _blockList.getBit(url.c_str());
}
};
int main()
{
BlackList list;
list.add("http://www.baidu.com");
list.add("http://www.360buv.com");
list.add("http://www.tmall.com");
list.add("http://www.tencent.com");
string url = "http://www.tencent.com";
cout << list.query(url) << endl;
return 0;
}














 2963
2963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









