









 本文介绍了GloVe模型,它结合了全局矩阵分解和局部上下文窗口方法,旨在优化词向量表示。通过对词类比任务、词相似度任务和NER的实验,展示了GloVe在多种任务上的优越性能,并分析了模型参数如向量长度、上下文窗口大小和语料库规模对结果的影响。
本文介绍了GloVe模型,它结合了全局矩阵分解和局部上下文窗口方法,旨在优化词向量表示。通过对词类比任务、词相似度任务和NER的实验,展示了GloVe在多种任务上的优越性能,并分析了模型参数如向量长度、上下文窗口大小和语料库规模对结果的影响。
Introduction
大多数词向量方法依赖于成对的词向量之间的距离或角度,作为评估此类此表示的内在质量的主要方法。有人提出了一种新的、基于单词类比的评估方案,该方案通过检查单词向量之间的标量距离,而不是不同的维度差异,来探索单词向量空间的精细结构。举例:"the analogy king is to queen as man is to woman" should be encoded in the vector space by the vector equation king -queen = man - woman. 这种评估方案倾向于产生意义维度的模型,从而抓住分布式表示的多聚类思想(后半句不太懂)
Related Work
学习词向量的两个主要模型族是:(1)全局矩阵分解方法,如潜在语义分析(LSA) 和(2)局部上下文窗口方法,如skip-gram模型。目前,这两种模型有缺陷。虽然像LSA这样的方法可以有效地利用统计信息,但它们在单词类比任务上做得相对较差,这表明向量空间结构不是最优的。像skip-grams这样的方法可能在类比任务上做得更好,但它们没有很好地利用语料库的统计数据,因为它们训练的是单独的局部上下文窗口,而不是全局共出现计数。
矩阵分解法:利用低秩近似来分解关于语料库的统计信息的大型矩阵,代表是基于奇异值分解(SVD)的LSA算法,该方法是对term-document矩阵进行奇异值分解,得到词的向量表示以及文档的向量表示。
(潜在语义分析(LSA)解析 | 统计学习方法 | 数据分析,机器学习,学习历程全记录 - 知乎)
局部上下文窗口法:skip-gram,(根据单词本身预测单词上下文)。CBOW(根据单词上下文预测单词)
Glove模型就是在将这两种特征结合在一起,既使用了语料库的全局统计特征,也使用了局部的上下文特征。为了做到这一点,引入了共线概率矩阵X。
共线:单词i与单词j共同出现在指定大小的窗口中。
共线矩阵:统计单词i与单词j一起出现的次数的矩阵。(它是对称的)
模型推导





Relationship to Other Models
因为所有学习词向量的无监督方法最终都是基于语料库的出现统计,所以模型之间应该有共性。下面又展示,我们将展示这些模型(选的是skip-gram)如何与我们定义的拟议模型相关性。

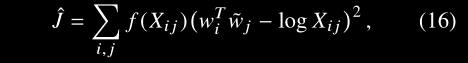
Complexity of the model
有点难
实验设置
我们对单词类比任务、各种单词相似度任务以及用于 NER任务

词类比:(主要关注点)a is to b as c is to ?包括语意与语法对比:“Athens is to Greece as Berlin is to ?(语意)“dance is to dancing as fly is to ?(语法)
词相似度:在词相似度的任务上评估了模型
NER:在CoNLL-2003 英语基准数据集。
在5个大小不同的语料库上训练模型,使用斯坦福的分词器对每个语料库进行分词与小写,选择窗口大小为10,造共现矩阵X,设置 xmax = 100,α = 3/4,并使用 AdaGrad 训练模型,从 X 中随机采样非零元素,初始学习率为 0.05。我们对小于 300 维的向量运行 50 次迭代,否则为 100 次迭代。
模型生成两组向量W和 ˜W(因为X是对称的,所以他俩也对称)为了减少过度拟合和噪声,改善结果,我们使用的是W+ ˜W作为我们词向量。
使用了10个负采样。负采样的本质:每次让一个训练样本只更新部分权重,其他权重全部固定;减少计算量;(一定程度上还可以增加随机性)
结果
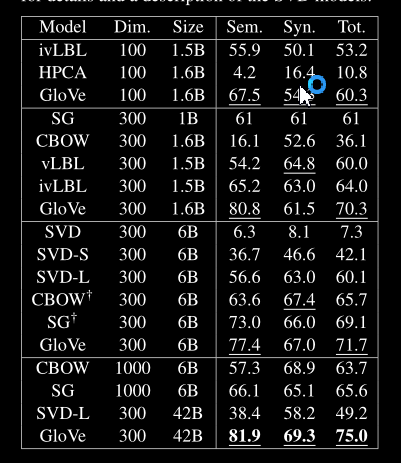
单词类比任务:GloVe 模型的性能明显优于其他基线,而且通常具有更小的向量大小和更小的语料库。
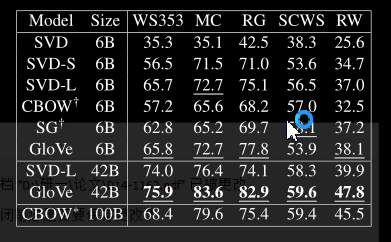
词相似任务:在五个不同单词相似度数据集的测试上,GloV e 在使用不到一半大小的语料库时表现最优。

GloV e 模型在所有评估指标上都优于所有其他方法,除了 CoNLL 测试集,HPCA 方法在该测试集上表现稍好。
模型分析
Model Analysis: Vector Length and Context Size 
在图 2 中,我们展示了改变向量长度和上下文窗口的实验结果。延伸到目标词左右的上下文窗口称为对称的,仅向左延伸的上下文窗口称为不对称的。在 (a) 中,我们观察到大于约 200 维的向量的收益递减。在 (b) 和 (c) 中,我们检查了改变对称和非对称上下文窗口的窗口大小的效果。对于小的和不对称的上下文窗口,句法任务的性能更好,这符合直觉,即句法信息主要来自直接的上下文并且可能强烈依赖于词序。另一方面,语义信息更多的是通过更大的窗口大小捕获的。
Model Analysis: Corpus Size
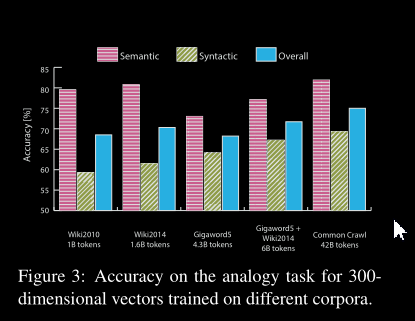
在句法子任务上,随着语料库大小的增加,性能单调增加。语义任务并非如此,在较小的 Wikipedia 语料库上训练的模型比在较大的 Gigaword 语料库上训练的模型做得更好。这可能是由于类比数据集中有大量基于城市和国家的类比,以及 Wikipedia 对大多数此类位置都有相当全面的文章这一事实。
Model Analysis: Comparison with word2vec 
我们将类比任务的整体性能绘制为训练时间的函数。我们注意到,如果负样本的数量增加到超过 10 个左右,word2vec 的性能实际上会下降。推测这是因为负样本方法不能很好地逼近目标概率分布。
结论
GloVe 用于词表示的无监督学习,在词类比、词相似性和命名实体识别任务上优于其他模型。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









