







1. AlexNet 简介
2006 年,研究人员成功利用 GPU 加速 CNN,相比 CPU 快了 4 倍。2012 年,由谷歌 Hinton 率领的团队提出新的卷积神经网络 AlexNet,在 ImageNet 2012 的图片分类任务上,以 15.3% 的错误率登顶,而且以高出第二名十几个百分点的差距吊打所有其他参与者。论文为《ImageNet Classification with Deep Convolutional Neural Networks》。AlexNet 的出现标志着神经网络的复苏和深度学习的崛起。
AlexNet 的网络结构跟 LeNet 类似,但使⽤了更多的卷积层和更⼤的参数空间来拟合⼤规模数据集 ImageNet。AlexNet 是浅层神经⽹络和深度神经⽹络的分界线,其网络结构如下
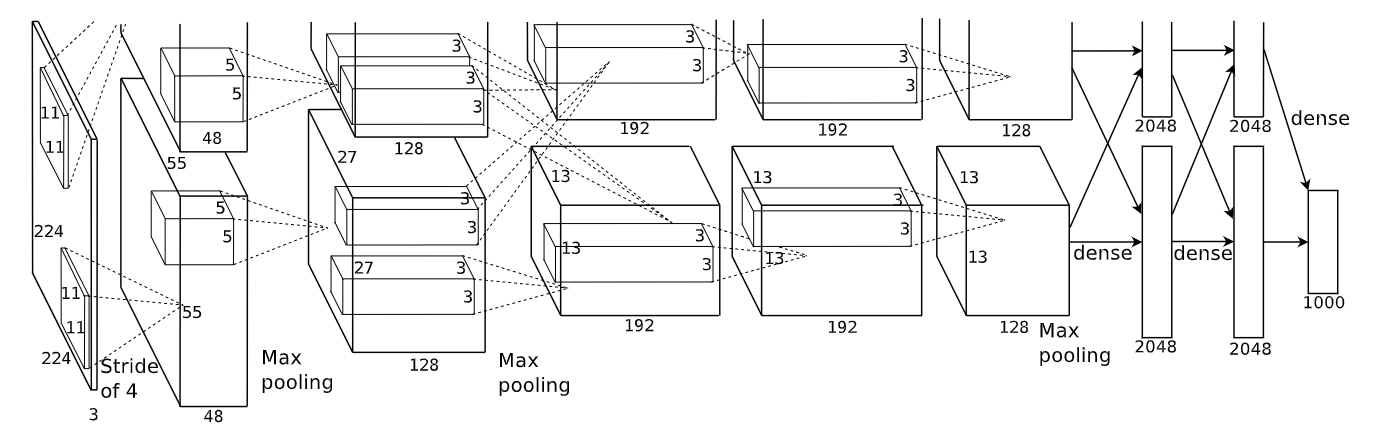
上图分为上下两个部分的网络,分别对应两个 GPU,只有到特定的网络层后才进行两块 GPU 间的交互,这种设置是为了利用两块 GPU 来提高运算的效率,其实两部分网络的结构差异不大。为便于理解,下文便选择一部分的网络 (一块 GPU 上) 进行介绍。单部分的网络结构如下
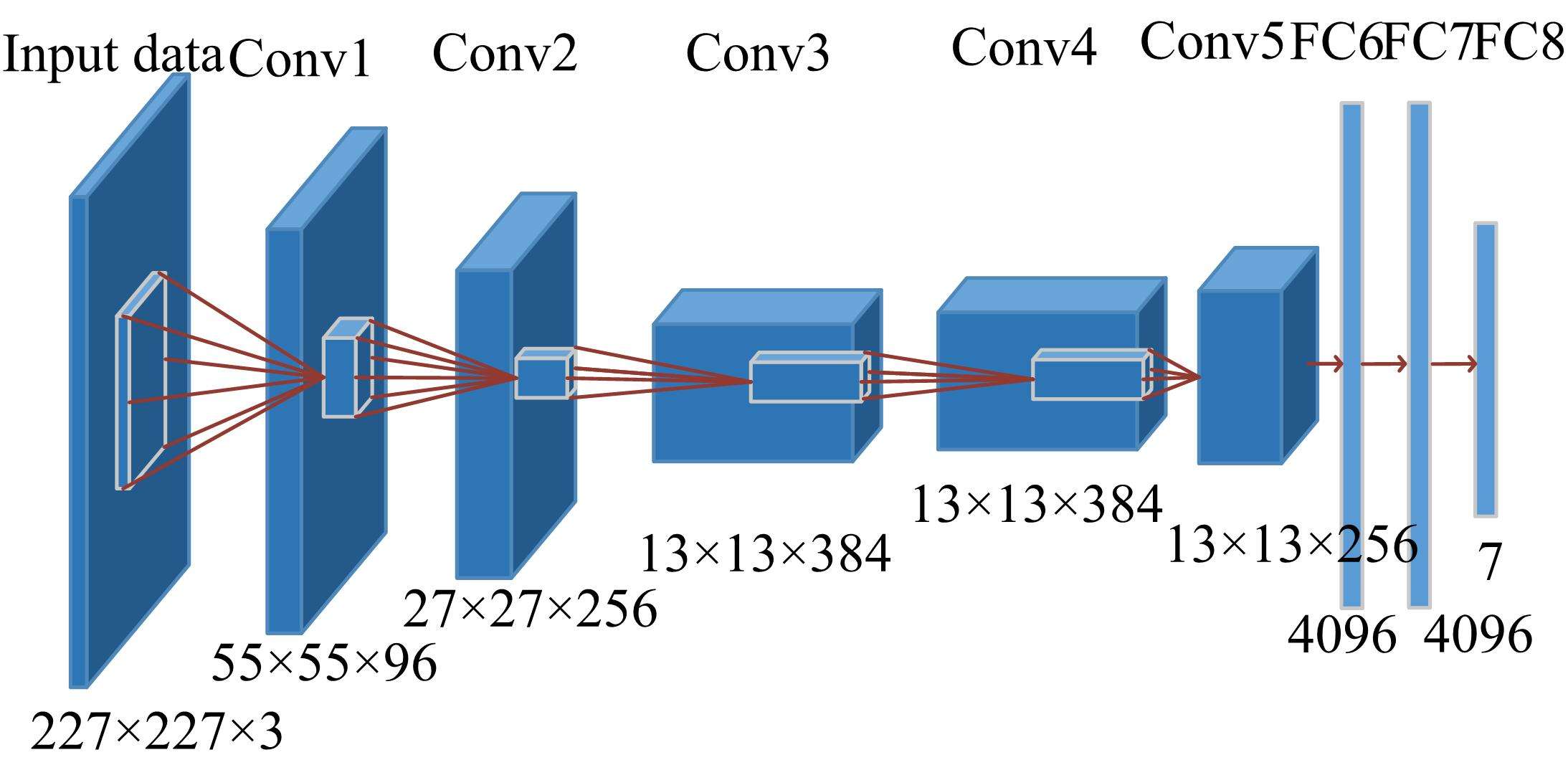
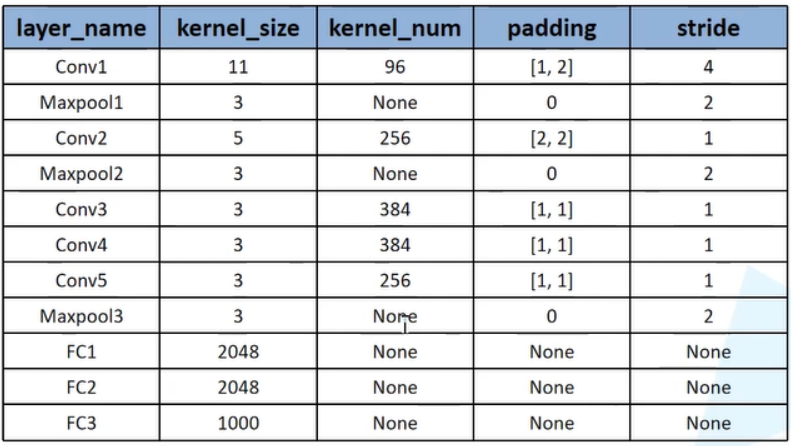
如上图所示,网络总共 8 层,包含 5 层卷积和 3 层全连接层。有关各层的详细介绍参见下图

与 LeNet 相比,AlexNet 的卷积/池化操作没有太大变化,不过网络层数有所加深。AlexNet 的主要特点有
- 成功使用 ReLU 作为激活函数,成功解决了Sigmoid 在网络较深时的梯度弥散问题。
- 使用了数据增强。
- 使用了小批量随机梯度下降法 (mini-batch SGD)。
- 在 GPU 上训练,这得益于 2006 年 CNN 在 GPU 上的实现。。
- 训练时使用 Dropout 随机忽略一部分神经元,以避免模型过拟合。
- 提出了局部响应归一化 (LRN) 层,对局部神经元的活动创建竞争机制,增强响应较大的神经元,抑制反馈较小的神经元,提高了模型的泛化能力。如今这部分工作多用 BN 替代。
- 使用重叠的最大池化。此前普遍使用平均池化,而最大池化能够避免平均池化的模糊化效果。此外,AlexNet 提出设置步长小于池化核的尺寸,让池化层的输出之间出现重叠和覆盖,提升特征的丰富性。
2. AlexNet 的 PyTorch 实现
import time
import torch
from torch import nn, optim
import torchvision
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 96, 11, 4), # in_channels, out_channels, kernel_size, stride, padding
nn.ReLU(),
nn.MaxPool2d(3, 2), # kernel_size, stride
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(3, 2),
# 连续3个卷积层,且使用更小的卷积窗口。除了最后的卷积层外,进一步增大了输出通道数。
# 前两个卷积层后不使用池化层来减小输入的高和宽
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2)
)
# 这里全连接层的输出个数比LeNet中的大数倍。使用丢弃层来缓解过拟合
self.fc = nn.Sequential(
nn.Linear(256*5*5, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
# 输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10),
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
【参考】
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









