








这里是SparkContext.createTaskScheduler(),匹配模式,创建TaskScheduler,创建SparkSchedulerBackend,然后 TaskSchedulerImpl调用initialize方法,此方法会将SparkSchedulerBackend对象传进去,填充TaskSchedulerImpl的backend对象。并且会创建pools(资源调度池),该池是为提交task到excutor而实现的。资源调度算法有fifo和fair两种。 SparkContext创建完TaskScheduler以后,会先创建DAGSchduler,然后调用taskScheduler的start方法(taskScheduler是个trait,他的实现是taskSchdulerImpl),该方法会启动backend

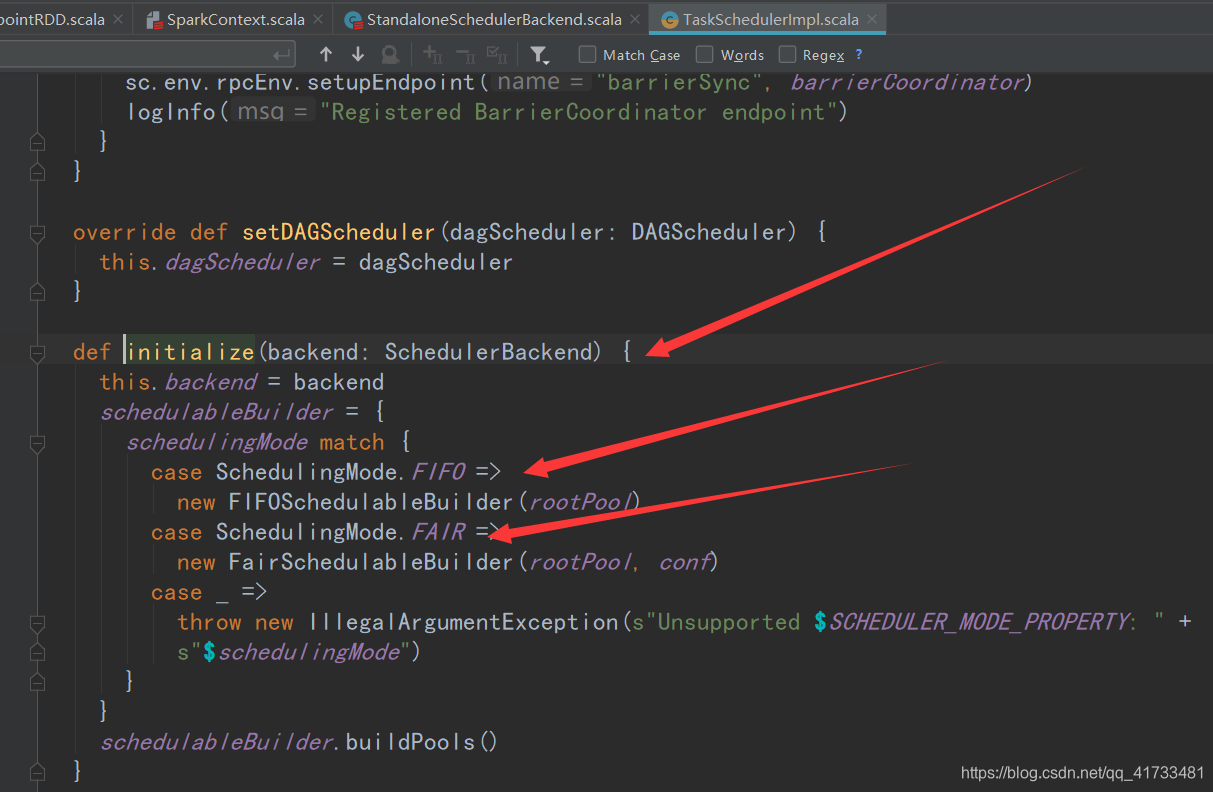
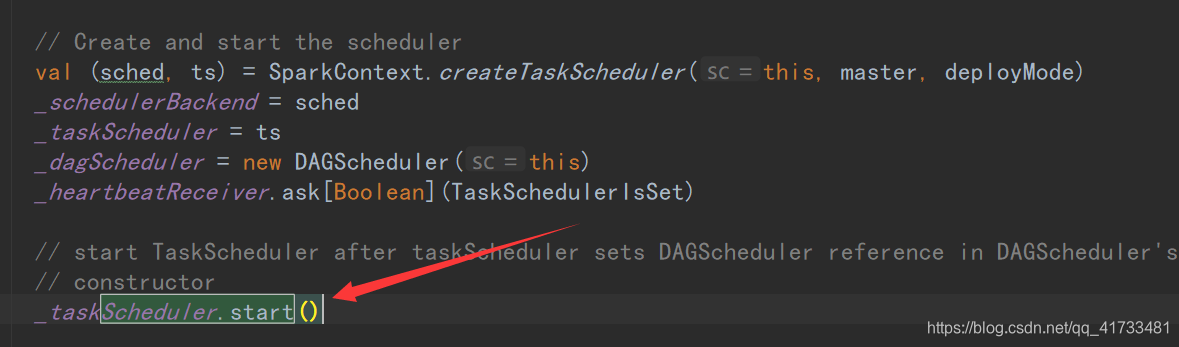

下图是:sparkSchedulerBackend的start方法首先进行各种参数的填充,最后会创建Appclient(),创建Applicent前创建ApplicationDescription,它会把我们设置的什么应用名称啊,多少内存啊,几个核啊,这些资源信息整合起来。然后放到Applicent里面。
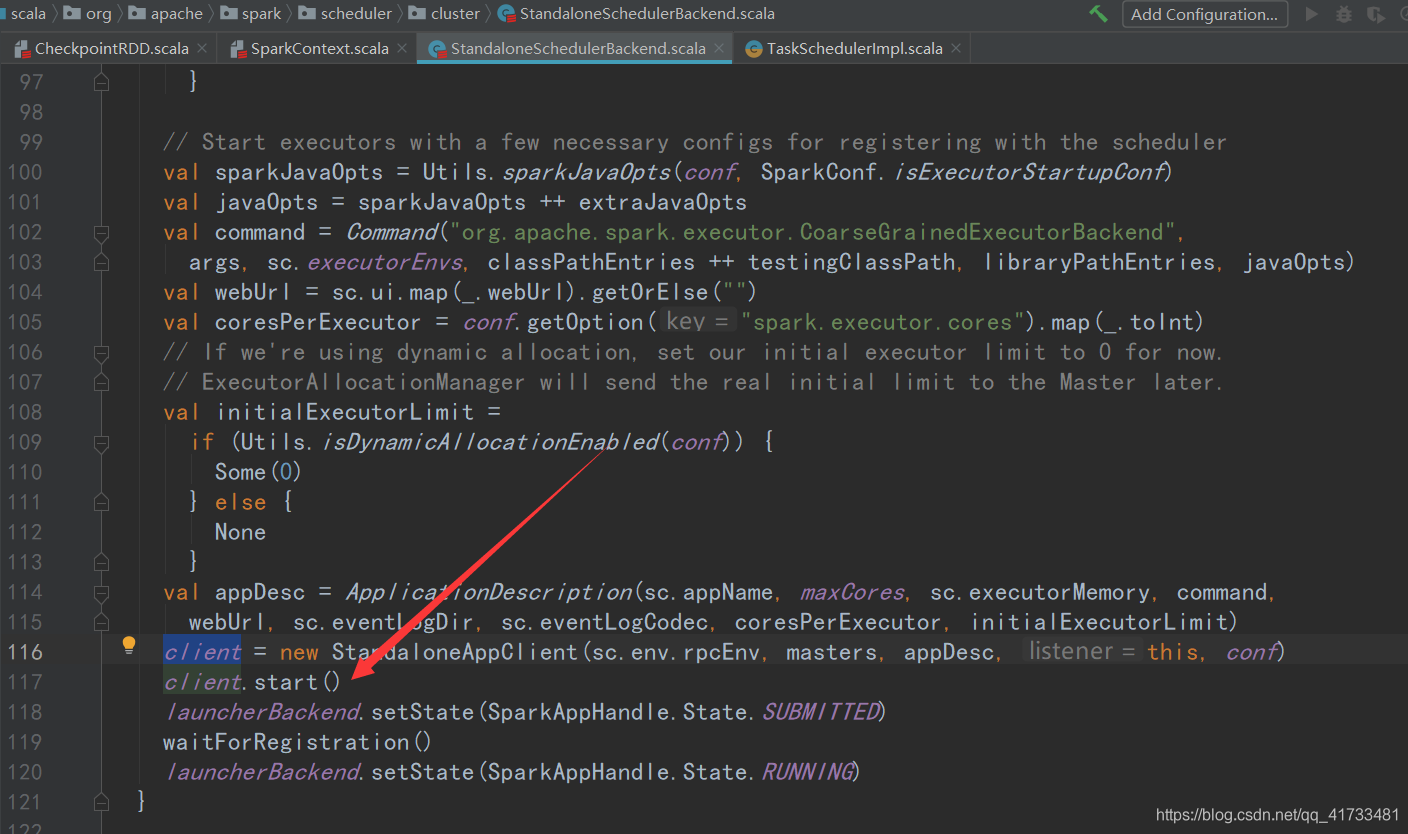
Appclient去连接master

下图是DAGschduler的功能














 306
306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









