






1、什么是人脸识别?
人脸识别可以分为两个方面,一个是人脸验证,另一个是人脸识别。
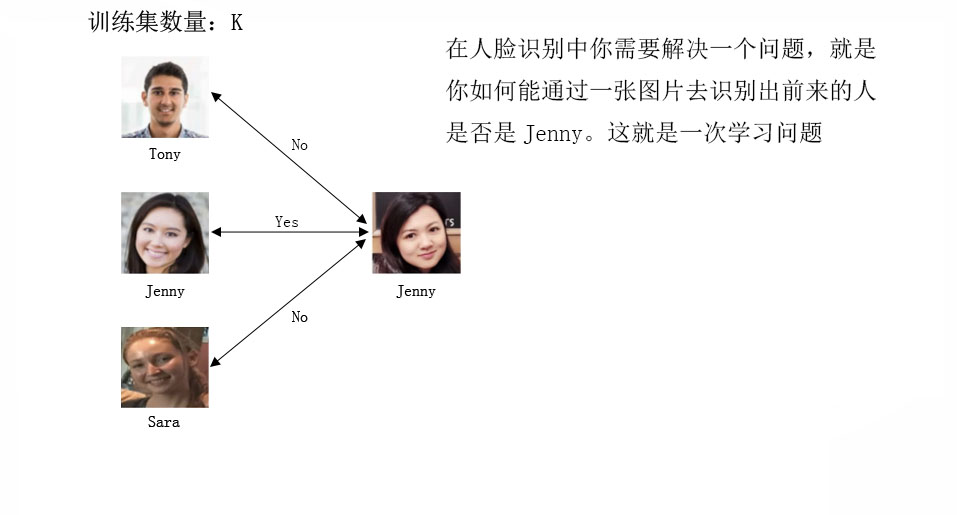
人脸验证指的是:假设我们有一个人的画像(Tony),我们需要根据这个画像验证来人是不是Tony本人。
人脸识别指的是:如果我们有一个人脸数据集(大小为K),我们需要识别来人是不是我们的人脸数据集里面的人。
人脸识别的准确率必须依托于人脸验证的准确率。
2、如何解决一次学习问题?
人脸识别问题所面临的一个挑战,就是需要解决一次学习问题。这意味着,在绝大多数人脸识别应用中,你需要通过单单一张图片或者单单一个人脸样例就能去识别这个人。但是,纵观深度学习问题,当深度学习只有一个人脸样例时,它的表现并不好。
要想解决一次学习问题,我们必须先构造“similarity”函数。
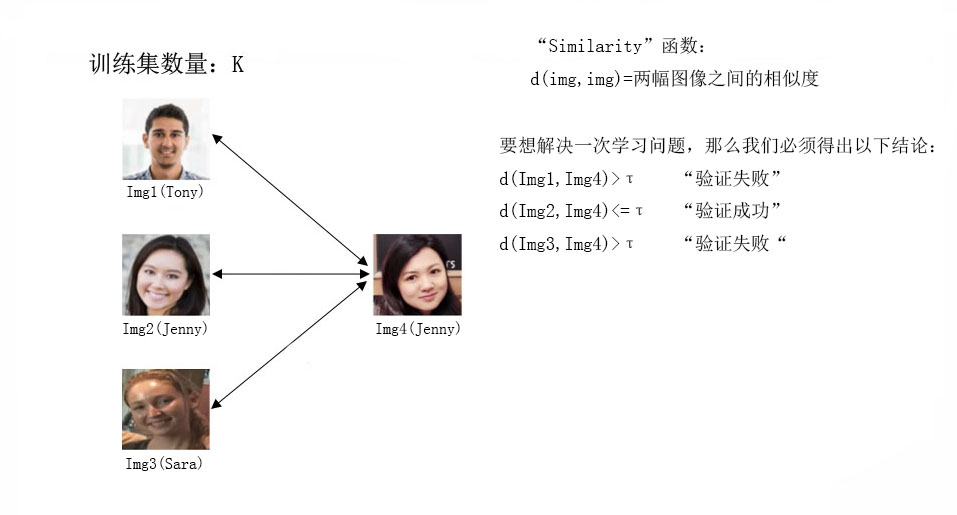
接下来,构建“similarity”函数首先得通过Siamese网络。
3、Siamese网络
你要计算“similarity”函数,你实际要做的就是训练一个网络,它计算得到的编码可以用于函数d,它可以告诉你两张图片是否是同一个人。这个网络就是“Siamese”网络。
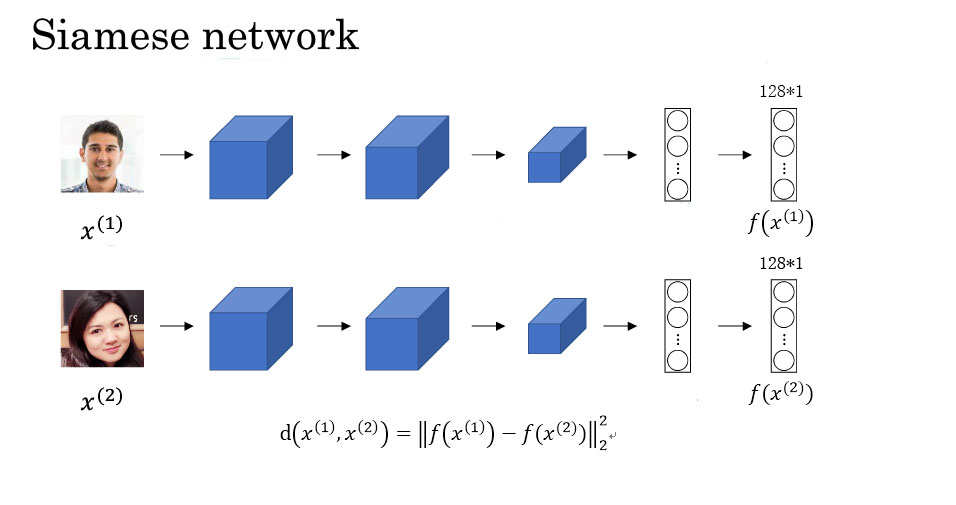
所以每一张人脸图像都会对应着一个128维的向量编码。
如果你要比较两个图片的话,你要做的就是把第二个图片喂给有同样参数的神经网络,然后得到一个不一样的128维的向量。
假设两张人脸图像的128维的向量编码分别为f(x(1))和f(x(2))。那么你要做的就是计算这两个向量的二范数的平方,如果计算结果小于τ,表示这两张人脸图像是一个人,否则,这两张人脸图像表示不同的人。
接下来,讨论这个Siamese网络的损失函数。
4、Triplet损失函数(三元组损失函数)
要想通过学习神经网络的参数来得到优质的人脸图片编码,方法之一就是定义三元组损失函数然后应用梯度下降。
三元组意味着你需要同时看三张图片。
如下图所示为三元组损失函数的基本思想(Positive意味着同一个人,Negative意味着不同的人)

假如你有一个10000个图片的训练集,里面是1000个不同的人的照片,你要做的就是取这10000个图片,然后生成这样的三元组,然后训练你的学习模型,对这种代价函数使用梯度下降。
那么为什么数据集是1000个人的10000张照片呢?这是因为为了定义三元组的数据集,你需要成对的A和P,即同一个人的成对的图片,为了训练你的系统,你确实需要一个数据集,里面有同一个人的多张照片。
接下来,让我们说说Triplet损失函数的数学表达式。

现在我们来看,你如何选择这些三元组来形成训练集,一个问题是如果你从训练集中随机地选择AP和N,因为是随机地选择,那么这个条件很容易达到(A和N比A和P差别很大的概率很大)
所以你要做的就是尽可能的选择难训练的三元组A、P和N。如果你想知道细节的话,那么这篇论文可能对你有帮助(Schroff et al,2015,FaceNet:A unified embedding for face recognition and clustering)
5、面部验证与二分类
Triplet损失是一个训练人脸识别卷积网络参数的好办法,但是还有其他学习参数的方法,这个方法就是将人脸识别当成一个二分类问题。
假设我们把得到的128维的人脸编码放入逻辑回归中,最后的逻辑回归可以增加参数w和b,就想普通的逻辑回归一样,你将在这128个单元上训练合适的权重用来预测两张图片是否是同一个人,这是一个很合理的方法,来学习预测0或者1。
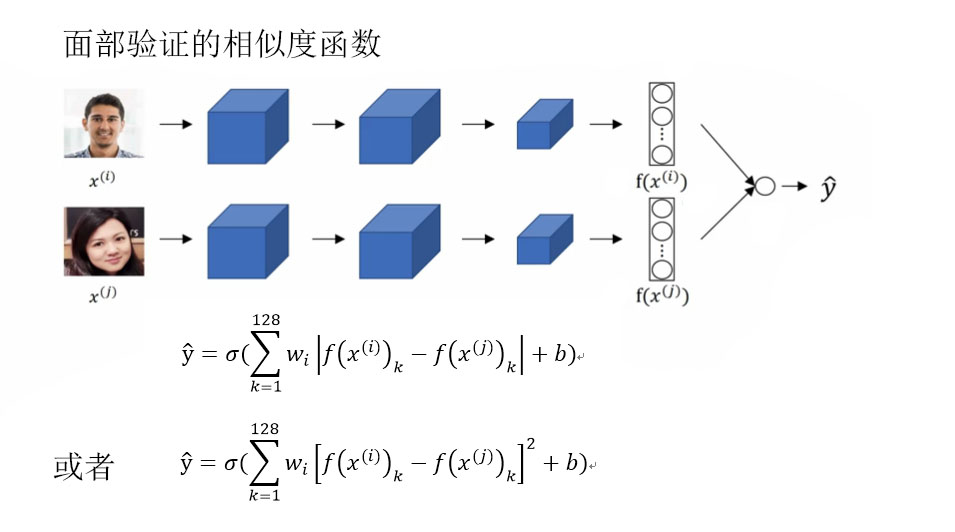
监督学习下的人脸验证代价函数:
















 745
745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









