






嘿嘿!
我是大四做毕设,我是家电推荐
主要看了尚硅谷的电商推荐系统结果发现,只是直接给了数据源,而且和我数据也不对应,一开始自己爬虫结果跪,然后计划想买一个,想着简单的爬虫能多贵,要我600,我的天!只能自己干!我又不是土财主。
好了正题:需要有一些简单的python,和html基础
系统:win10 开发工具:pycharm
主要使用python类库:bs4,requests,lxml(需要安装的)
我就不介绍了,csvn教程多的要死
(只给些截图,不给代码了,建议自己敲一敲,网页有些用了…都是不重要的信息)
结果

1200个商品(商品id,名称,图片,我爬取下来的排名)当然你可以有别的反正都得到整个商品信息,想要什么,往里面写写完事了,我只分析家电,就没爬分类
准备阶段:
爬取商品信息:进入我们想要的页面https://search.jd.com/Search?keyword=%E5%AE%B6%E7%94%A8%E7%94%B5%E5%99%A8%E6%8E%92%E8%A1%8C&enc=utf-8&qrst=1&rt=1&…(建议谷歌浏览器,按f12进入开发者工具,右击有查看网页源代码,ctrl+f查找元素记住)****
完成以后,安装上面的python库
接下来就开始写代码了
代码一
引入类库
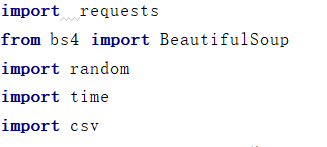
bs4就是简单的html的定位类,和xpath差不多,比他简单,不了解(添加链接描述看这个博主写的)
requests获取全部的网页加载信息
代码二
它就比较简单了,获取连接(但是连接这里有点讨厌因为我们肯定不是只爬取一页吧,可是简单的商品翻页再去找个翻页类,不可能吧!所以我们去解析这个url,第一页https://search.jd.com/Search?keyword=%E5%AE%B6%E7%94%A8%E7%94%B5%E5%99%A8%E6%8E%92%E8%A1%8C&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E5%AE%B6%E7%94%A8%E7%94%B5%E5%99%A8%E6%8E…8C&stock=1&page=1&s=1&…
第二页https://search.jd.com/Search?keyword=%E5%AE%B6%E7%94%A8%E7%94%B5%E5%99%A8%E6%8E%92%E8%A1%8C&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E5%AE%B6%E7%94%A8%E7%94%B5%E5%99%A8%E6%8E%92%…%8C&stock=1&page=3&s=61&…
第三页https://search.jd.com/Search?keyword=%E5%AE%B6%E7%94%A8%E7%94%B5%E5%99%A8%E6%8E%92%E8%A1%8C&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E5%AE%…E7%94%B5%E5%99%A8%E6%8E%92%E8%A1%8C&stock=1&page=5&s=121&…
看出来了吧page1,3,5,7。s1,61,121。很显然值就是翻页信息)
我们把这两个信息&s和&page从url(图里)里删除
headers就是简单的模拟一下浏览器的头部,别让人家一看,你都不蒙面直接偷信息,百度一下怎么获取自己浏览的请求头

之后呢?
for循环在里面改变url(url里&后的信息没有顺序要求),不断分析requests获取下来的html就好了,requests的get方法里有拼接url的参数params,之后给bs4,
然后到soup行之后,soup的find方法就是简单的定位,是哪一个<>标签,一般是class,和id定位,回到浏览器


li标签的class是一个多属性,所以我是直接定位ul标签,然后.contents,所有的子节点返回成一个list类型,bs4遍历添加链接描述看这个博主

写太多,人看不见去了这是(一)吧如果有问题评论,刷好评也感谢!
嘿嘿















 1231
1231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









