







 nnDetection是一种医学目标检测框架,通过自动化配置网络结构、学习率和数据增强策略,适应各种医学图像任务。它通过固定参数、规则基参数和经验参数的结合,提供自适应性能,尤其在肺结节检测和糖尿病视网膜病变分析中展现了优势。相比nnU-Net,nnDetection更侧重于对象检测而非图像分割,且在多个数据集上表现出色。
nnDetection是一种医学目标检测框架,通过自动化配置网络结构、学习率和数据增强策略,适应各种医学图像任务。它通过固定参数、规则基参数和经验参数的结合,提供自适应性能,尤其在肺结节检测和糖尿病视网膜病变分析中展现了优势。相比nnU-Net,nnDetection更侧重于对象检测而非图像分割,且在多个数据集上表现出色。
提出背景
论文:https://arxiv.org/pdf/2106.00817.pdf
代码:https://github.com/MIC-DKFZ/nnDetection
传统的对象检测方法配置过程繁琐且迭代,需要专家知识、大量计算资源、充足的验证数据,并且每遇到新任务就需重复配置过程。
nnDetection通过自动化这一过程,
能够在没有任何人工干预的情况下自适应任意医学检测问题,同时达到与最先进水平相当或更优的结果。
nnDetection通过自动配置其网络结构、学习率调整、数据增强策略等参数,能够适应不同的医学图像检测任务。
例如,在处理肺结节检测的任务时(如在LUNA16数据集上),nnDetection首先分析该任务的特定需求,比如图像的大小、结节的大小和形状等特征。
然后,它会自动调整其卷积网络(如深度、过滤器大小、步长等)来最大化地捕获肺结节的特征。
在此过程中,nnDetection可能会决定使用较深的网络结构来捕捉复杂的肺结节特征,同时应用特定的数据增强技术(如随机旋转、缩放等)来增加模型的泛化能力。
此外,它还会自动调整训练过程中的学习率,以确保快速而稳定的收敛。
通过这种方式,nnDetection能够针对肺结节检测任务自动优化其配置,从而在LUNA16数据集上达到或超过当前最先进技术的检测性能。
这种自适应能力使nnDetection不仅适用于肺结节检测,还可以被应用于其他类型的医学图像检测任务,如检测脑部MRI中的异常结构、识别X光图像中的骨折等,每次都能够无需人工干预地调整其设置以适应新的任务。
要素拆解
固定参数 (Fixed Parameters)
- 子问题: 如何确保模型架构在不同数据集上具有鲁棒的泛化能力。
- 子解法: 选择Retina U-Net作为架构模板,因其能有效利用像素级标注来增强学习,同时通过规则基参数调整具体的网络结构,如卷积核大小、池化步长和池化操作数量。
- 背景: 固定参数的设定基于对10个开发数据集的优化,旨在找到不需针对不同数据集调整的设计选择。
规则基参数 (Rule-based Parameters)
- 子问题: 如何自动调整网络拓扑、批处理大小和锚点配置以适应数据集的特定特征。
- 子解法: 通过数据指纹提取数据集特性,如对象大小,使用迭代优化过程确定网络拓扑参数,并固定批处理大小为4以提高训练稳定性。锚点配置通过迭代最大化锚点与真实框的交并比(IoU)来确定。
- 背景: 规则基参数的设定依据数据集的具体特征,如对象大小和图像分辨率,通过明确的启发式规则来自动化设计决策过程。
经验参数 (Empirical Parameters)
- 子问题: 如何处理对象检测模型中的后处理,特别是如何聚类重叠的边界框预测。
- 子解法: 使用非最大抑制(NMS)和加权框聚类来处理因密集锚点产生的预测重叠和测试时的多模型或不同增强结果的聚类。
- 背景: 经验参数主要用于测试阶段,通过在验证集上的经验优化来确定,以解决预测重叠的问题并提高模型的预测准确性。
这个逻辑链条可以被视为一个分层的决策流程:
-
固定参数阶段:
- 示例: 假设我们有一个用于医学图像中肿瘤检测的模型。
固定参数包括使用Retina U-Net架构,这是基于该模型在先前的10个开发数据集上的表现优化而确定的。
我们选择了这个架构,因为它能有效地利用像素级标注来增强学习,并且已经证明在多个数据集上具有良好的性能。
-
规则基参数阶段:
- 示例: 接下来,为了使模型能够自动调整以适应新的数据集,我们根据每个数据集的“数据指纹”来决定网络的具体配置。
例如,如果新数据集中的对象通常较大,我们可能会选择更大的卷积核和更少的池化层。
我们还会设置批处理大小为4,这是一个规则基的选择,目的是为了提高训练的稳定性。
同时,锚点配置会自动通过迭代过程来优化,以确保预测框能够与实际的物体边界框更好地对应。
-
经验参数阶段:
- 示例: 最后,在模型的后处理阶段,我们使用经验参数来解决预测中的重叠问题。
例如,当模型生成了多个重叠的边界框预测时,我们会使用非最大抑制(NMS)来选择最佳的预测框,并使用加权框聚类来合并来自模型不同版本或不同增强技术的预测。
这些参数是基于在验证集上的测试结果来优化的,旨在提高模型的预测精度。
这个逻辑链条的流程是层级化的,意味着每个阶段的输出都是下一个阶段的输入。
固定参数提供了一个稳固的基础,规则基参数允许模型适应新的数据集特征,而经验参数则优化了模型的最终预测表现。
通过这种方法,nnDetection系统地处理了医学图像对象检测任务中的全流程配置问题,从而无需人工干预即可自动适应新的数据集。
这一流程不仅减少了额外的计算成本,而且通过规则和经验优化提高了模型的泛化能力和准确性。
尽管nnDetection主要设计用于目标检测任务,即识别图像中特定物体的位置和类别,但其自动化和自适应的特性使其在处理具有复杂特征的医学图像分析任务时具有潜力,包括糖尿病视网膜分类和分期。
糖尿病视网膜病变的分类和分期涉及对视网膜图像进行详细分析,以识别病变特征(如微血管瘤、出血、硬性渗出等)并根据病变的严重程度将病例分级。
nnDetection可以通过以下方式适应这一任务:
-
自定义数据预处理:调整数据预处理流程以适应视网膜图像的特点,如调整图像亮度和对比度,使病变特征更明显。
-
特征提取与学习:虽然nnDetection主要设计用于检测任务,但通过定制网络架构和训练策略,可以使其学习视网膜图像中的病变特征,为分类和分期提供必要的信息。
-
多任务学习:在nnDetection的框架下,可以实现多任务学习,同时进行病变检测和分类分期。这需要在模型设计时加入额外的分类分支,用于预测病变的严重程度。
-
自适应参数调整:根据糖尿病视网膜病变的特性自动调整模型参数,如调整锚点框大小以匹配病变区域的尺寸,或优化损失函数以平衡不同类别的病变检测。
-
模型评估与优化:通过交叉验证和性能指标(如精确度、召回率、F1分数等)来评估模型在糖尿病视网膜病变分类和分期任务上的效果,并基于这些评估结果进一步优化模型。
虽然nnDetection主要关注目标检测,但通过适当的定制和扩展,它可以被应用于糖尿病视网膜病变的分类和分期任务。这可能需要额外的工作来调整网络架构和训练策略,以适应该特定的医学图像分析任务。
nnDetection框架的高层次设计选择和机制的概览
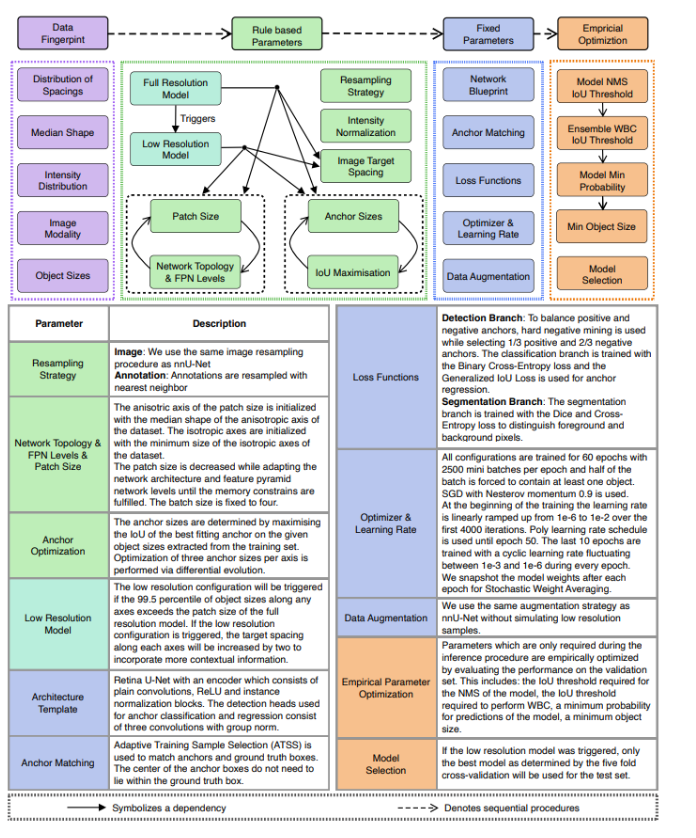
-
数据指纹(Data Fingerprint): 涵盖相关数据集属性的信息被提取出来(紫色部分),如间距分布、中位数形状、强度分布、图像模态和对象大小。
-
基于规则的参数(Rule-based Parameters): 根据数据指纹信息,执行一系列启发式规则来确定流程的规则基础参数(绿色部分)。
这些规则与一组固定参数(蓝色部分)并行工作,这些参数在不同数据集之间不需要调整。
-
固定参数(Fixed Parameters): 包括网络蓝图、锚点匹配、损失函数、优化器与学习速率、数据增强等。
-
经验参数优化(Empirical Parameter Optimization): 训练后,在训练集上优化经验参数(橙色部分),例如模型NMS IoU阈值、集合WBC IoU阈值、模型最小概率、最小对象大小和模型选择。
图中还介绍了几个关键组件,例如:
- 全分辨率模型与低分辨率模型(Full Resolution Model & Low Resolution Model): 用于处理不同分辨率的数据输入。
- 锚点优化(Anchor Optimization): 通过IoU最大化来选择最合适的锚点大小。
- 网络拓扑和FPN层级(Network Topology & FPN Levels): 用于设置网络结构和特征金字塔网络层级。
- 检测分支(Detection Branch): 平衡正负锚点,训练分类分支时选择1/3正锚和2/3负锚。
- 分割分支(Segmentation Branch): 用Dice和Cross-Entropy损失来训练,以区分前景和背景像素。
nnDetection 与 nnU-Net
nnDetection和nnU-Net都是为医学图像分析设计的神经网络框架,但是它们在设计理念和目标任务上有所不同。
UNet 系列:做医学图像分割的任何人,都必须要会使用 nnU-Net
nnU-Net 核心思想是自动化地配置神经网络的参数,包括数据预处理、网络架构、训练策略和后处理步骤,以适应不同的数据集。
nnU-Net的目标是在不同的医学图像分割任务中提供一个标准化且高性能的解决方案,无需手动调整网络配置。
nnDetection则是专门为医学图像中的对象检测任务设计的。
对象检测不仅要识别图像中的对象,还要定位它们的位置。
nnDetection的设计允许它自适应不同数据集的特点,并优化检测性能。
它包括了数据指纹提取、基于规则的参数设定,以及经验参数的优化。
对比两者:
-
任务类型:
- nnU-Net: 专注于图像分割,即识别和轮廓化图像中的特定结构。
- nnDetection: 专注于对象检测,即定位和识别图像中的单个对象。
-
自动化程度:
- nnU-Net: 提供全自动化的网络配置,从而减少了对专业知识的需求,并简化了从一个任务到另一个任务的迁移。
- nnDetection: 虽然也提供了自动化的特性,但它专注于通过数据指纹来自动推断适合特定数据集的参数。
-
使用场景:
- nnU-Net: 适用于那些需要高质量分割结果的场景,例如器官分割或病灶分割。
- nnDetection: 更适用于需要定位、检测和分类医学图像中多个物体的场景。
两者都是为了减少深度学习在医学图像分析中的手动调参工作,并且旨在提供一种可靠、自动化的方法来处理不同的医学图像数据集。
但是,根据任务的不同(分割或检测),可能会选择不同的框架。
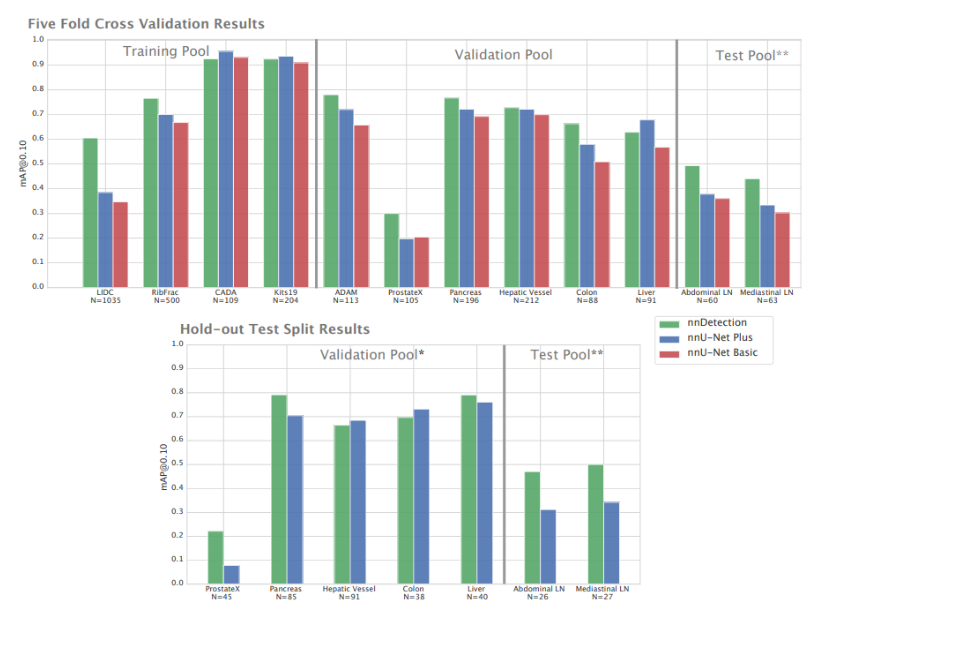
上图呈现了nnDetection与nnU-Net在12个数据集上的大规模基准测试结果:
-
上方的条形图显示了五折交叉验证的结果,分别是训练池、验证池和测试池的平均精度均值(mean Average Precision, mAP@0.1)。
每个数据集的名字如LIDC、KiTS19等都是医学图像数据集的缩写,数字代表每个数据集的样本数量。
-
下方的条形图展示了不同数据集的测试拆分结果,同样用mAP@0.1来衡量在验证池和测试池上的性能。
nnDetection在多数数据集上的表现优于nnU-Net Plus和nnU-Net Basic。

















 935
935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









