







MoE 介绍
大模型最开始设计思路是 — 通用。
一个通才能够处理多个不同的任务,但一群专家能够更高效、更专业地解决多个问题。
- Moe 混合多专家模型:术业有专攻,将任务分类,分给多个专家解决
与一个“通才网络”相比,一组术业有专攻的“专家网络”能够:
-
让用户获得更快的响应速度
-
提供更好的模型性能 — 每个专家模型都能针对不同的数据分布和构建模式进行搭建
-
更好地完成复杂的多种任务
如果把一个通用大模型,微调成医学大模型,虽然医学方面专业了,但其他所有方面都会下降,举一反三变成胡说八道,翻译能力骤降
-
在不显著增加计算成本的情况下大幅增加模型容量
-
开发时间更短
让一个大模型既代码牛逼,又医疗牛逼,还数学、角色扮演牛逼,你得烧多少算力、买多少数据,即使做到,项目开发周期非常长,搞不好新技术出来又颠覆了。
-
模型越大,性能越好。
今天的大模型,正迫切地需要变得更大。
随着模型越来越大,稳定性也越来越差,种种综合原因让大模型参数量长久以来限制在百亿与千亿级别,难以进一步扩大。
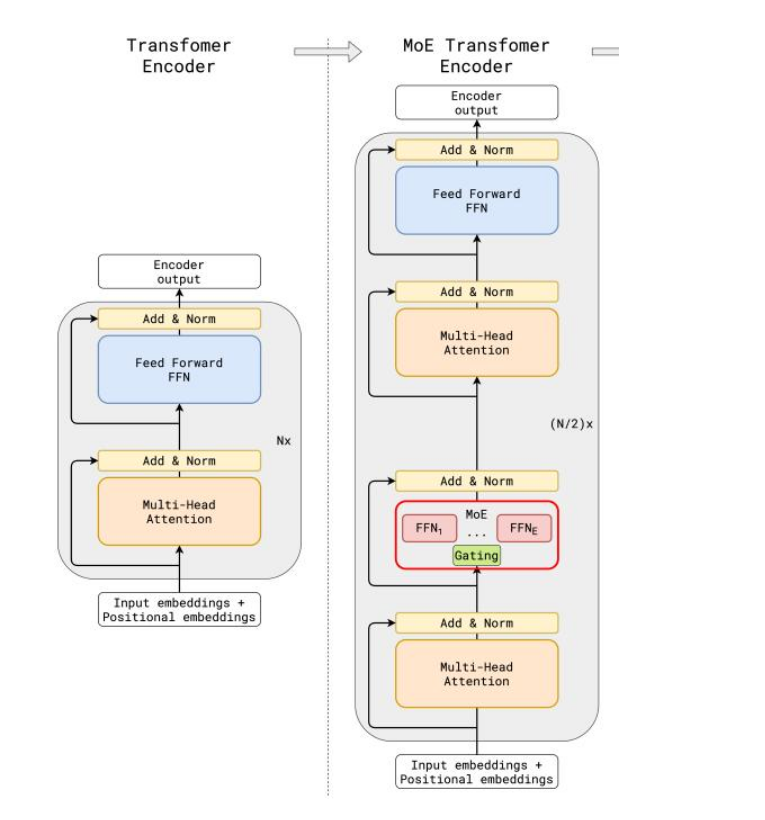
这张图对比了标准 Transformer 编码器(左侧)和 MoE(专家混合)Transformer 编码器(右侧)的架构。
-
MoE Transformer 编码器引入了MoE(专家混合)层,而标准 Transformer 编码器没有。
-
与传统大模型架构相比,MoE架构在数据流转过程中集成了一个专家网络层(红框部分)。
标准 Transformer 编码器
- 输入嵌入 + 位置嵌入:输入的嵌入向量和位置嵌入。
- 多头注意力机制:使用多头注意力机制来捕捉输入序列中不同位置之间的关系。
- 加法 & 归一化:将多头注意力机制的输出与输入进行残差连接,并进行归一化处理。
- 前馈神经网络(FFN):通过一个全连接的前馈神经网络对归一化后的输出进行进一步的处理。
- 加法 & 归一化:将前馈神经网络的输出与其输入进行残差连接,并进行归一化处理。
- 重复 Nx 次:上述步骤重复 N 次,得到编码器的最终输出。
MoE Transformer 编码器
- 输入嵌入 + 位置嵌入:输入的嵌入向量和位置嵌入。
- 多头注意力机制:使用多头注意力机制来捕捉输入序列中不同位置之间的关系。
- 加法 & 归一化:将多头注意力机制的输出与输入进行残差连接,并进行归一化处理。
- MoE 层:包含多个前馈神经网络(FFN₁, …, FFNₑ)。通过一个门控机制(Gating)来选择和激活其中的一部分前馈神经网络。这种机制使得模型可以选择性地激活特定的专家,从而增强模型的表示能力。
- 加法 & 归一化:将MoE层的输出与其输入进行残差连接,并进行归一化处理。
- 重复 (N/2)x 次:上述步骤重复 (N/2) 次,得到编码器的最终输出。
这种架构设计通过引入专家混合机制,使得模型在处理复杂任务时更具灵活性和适应性,同时也能够更有效地利用计算资源。
专家网络层
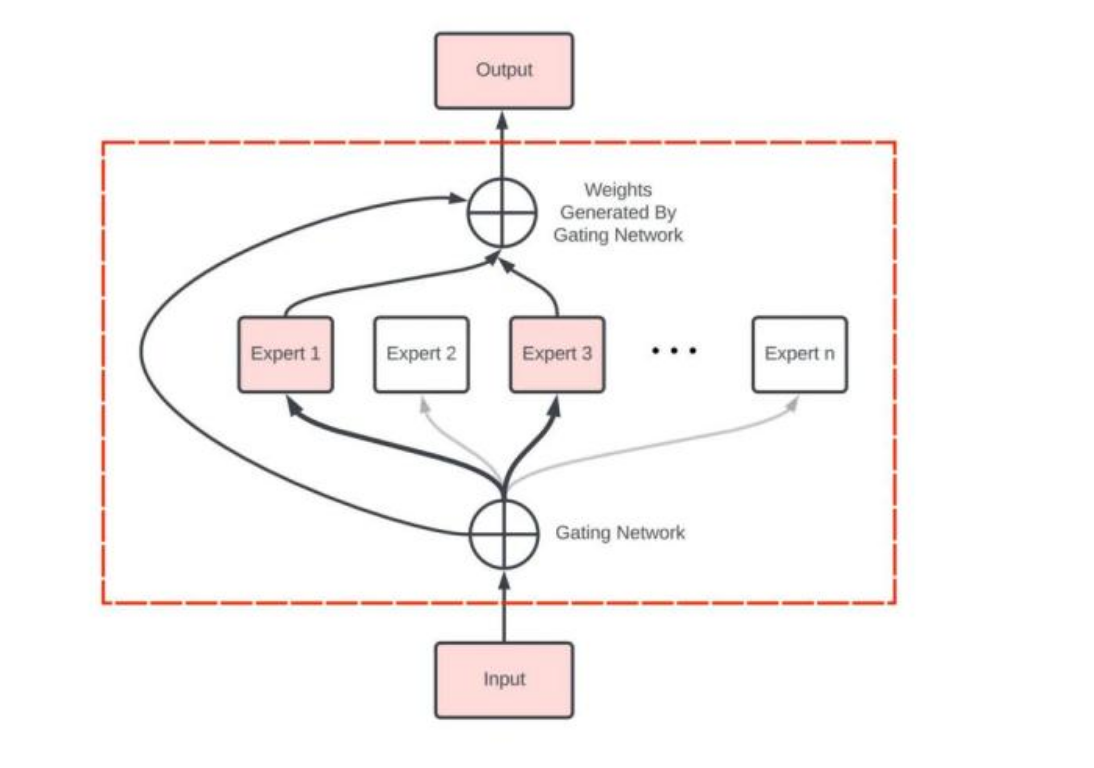
核心思想:
- 门控网络:负责智能分配任务,将不同特征的数据分配给最适合的专家。
- 专家模型:每个专家专注处理特定类型的数据特征,“让专业的人做专业的事”。
- 加权融合:将各个专家的处理结果融合,得到更精准的输出。
MoE 有两个参数:
- 专家数量 (num_local_experts):这决定架构中的专家总数,如 Mixtral-8x7B 有 8 个 7B 专家模型
- 专家数量/tonke (num_experts_per_tok):在每个层中,每个token会被分配到多少个专家模型进行处理。例如,如果num_experts_per_tok为2,那么每个token会被分配给2个专家模型。
Moe 实现俩种方式:
-
MoE(原装训练):从头设计和训练,所有部分都精心协调,更像是制造一辆全新的跑车。
-
frankenMoE(后天组合):基于现有模型进行改装和升级,重点在于如何有效组合和协调,更像是对现有汽车进行高性能改装。
大模型的有性繁殖
mergekit 合并 多个专家模型 的方式
https%3A//github.com/arcee-ai/mergekit%23merge-methods
mergekit 有 7 种合并方式。
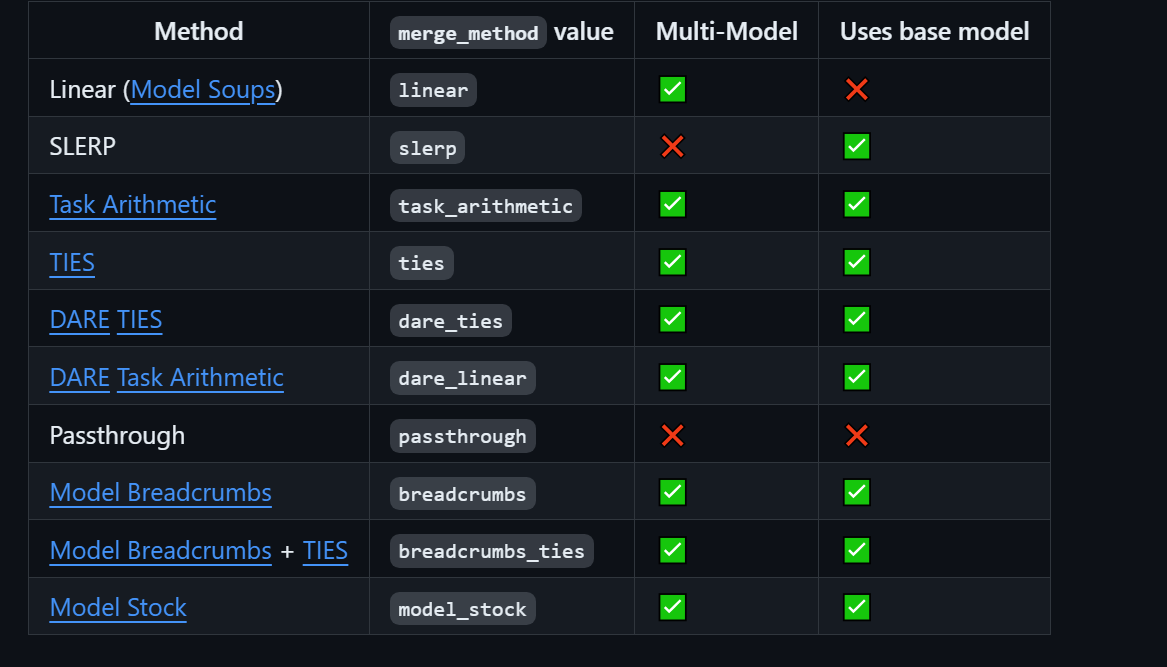
1. SLERP(球面线性插值)
问题:
为什么在某些情况下需要使用球面插值(SLERP)而不是线性插值?
解法:
在某些情况下,线性插值可能无法准确表示数据或模拟对象之间的连续变化,特别是涉及到在球面上的插值时。
为了保持曲线的平滑性和连续性,需要使用球面插值(SLERP)。
概念:
- SLERP是一种在两个向量之间进行平滑插值的方法,保持恒定的变化率,并保留向量所在的球形空间的几何属性。
- 主要用于两个模型的合并,通过插值获得平滑过渡。
步骤:
- 将输入向量归一化为单位长度。
- 使用它们的点积计算这些向量之间的角度。
- 根据角度进行插值,生成新向量。
2. TIES
概念:
- TIES旨在将多个特定任务的模型合并为一个多任务模型。
- 通过修剪冗余参数和解决符号冲突来优化合并过程。
步骤:
- 修剪:只保留最重要的参数,将其余参数重置为零。
- 选择符号:创建统一的符号向量,表示所有模型中最主要的变化方向。
- 不相交合并:平均对齐的参数值,不包括零值。
3. DARE
概念:
- 类似于TIES,但在修剪和重新缩放权重上有所不同。
- 将微调的权重随机重置为原始值,并重新缩放权重以保持模型输出预期不变。
步骤:
- 修剪:随机重置微调的权重为原始值。
- 重新缩放:重新缩放权重,使其与基本模型权重相结合。
4. Passthrough
概念:
- 与其他方法不同,Passthrough通过连接来自不同LLM(大规模语言模型)的层生成模型。
- 适用于创建大参数模型。
步骤:
- 直接连接来自不同模型的层。
- 生成一个新的模型,结合了多个模型的参数。
总结:
- SLERP:适用于在两个模型之间进行平滑插值,保持向量几何属性。
- TIES:通过修剪冗余参数和解决符号冲突来有效合并多个模型。
- DARE:类似TIES,但在权重修剪和重新缩放上有所不同,保持输出预期不变。
- Passthrough:通过连接不同模型的层创建大参数模型,适用于生成更强大的模型。
5. Linear
Linear就是一个简单的加权平均。
mergekit 合并 多个专家模型 实操
mergekit:https://github.com/arcee-ai/mergekit
python3 -m pip install --upgrade pip # 升级 pip
git clone https://github.com/cg123/mergekit.git # 下载合并工具
cd mergekit && pip install -q -e . # 进入目录,下载所有依赖
pip install -U transformers # 更新transformers
export HF_ENDPOINT=https://hf-mirror.com # 改成抱抱网的镜像站
修改配置文件 config.yaml:
- `--model_path1`: 第一个模型的目录路径,必须提供。
- `--model_path2`: 第二个模型的目录路径,必须提供。
- `--output_model_path`: 合并模型的保存路径,必须提供。
- `--gradient_values`: 梯度值列表,表示两个模型的张量应如何合并。示例中的`[1.0, 0.5, 0.0]`表示第一个模型的梯度值权重为1.0,第二个模型的梯度值权重为0.5,没有梯度值的张量权重为0.0。
- `--max_shard_size`: 保存模型时的最大分片大小,默认为"2000MiB"。
- `--layer_only`: 如果设置,则仅处理包含"layer"键的张量。此选项与`--no_layers`是互斥的,表示只处理特定层的张量。
- `--no_layers`: 如果设置,则仅处理不包含"layer"键的张量。此选项与`--layer_only`是互斥的,表示不处理特定层的张量。
这些参数用于指定程序的输入、输出以及其他配置选项,以便执行特定的模型合并操作。
1. TIES 合并 Mistral-7b、WizardMath-7b、CodeLlama-7b
将三个模型进行混合:Mistral-7b, WizardMath-7b和CodeLlama-7b。
修改配置文件 config.yaml:
models:
- model: mistralai/Mistral-7B-v0.1 # no parameters necessary for base model
- model: WizardLM/WizardMath-7B-V1.0
parameters:
density: 0.5 # fraction of weights in differences from the base model to retain
weight: # weight gradient
- filter: mlp
value: 0.5
- value: 0
- model: codellama/CodeLlama-7b-Instruct-hf
parameters:
density: 0.5
weight: 0.5
merge_method: ties
base_model: mistralai/Mistral-7B-v0.1
parameters:
normalize: true
int8_mask: true
dtype: float16
这段文本描述了一个模型合并的配置文件,让我逐步解释一下:
-
models部分指定了要使用的模型和模型的层范围。在这里列出了三个模型,分别是"Mistral-7B-v0.1"、“WizardMath-7B-V1.0"和"CodeLlama-7b-Instruct-hf”,每个模型都指定了一个层范围。 -
merge_method部分指定了如何合并models中指定的多个模型。在这里使用的是"ties"方法。 -
base_model部分指定了基础模型,即在合并过程中将保留其结构的模型。在这里是"Mistral-7B-v0.1"。 -
parameters部分指定了模型的参数。每个参数都有一个filter和一个value。filter指定了参数的作用范围,value指定了参数的值。 -
dtype部分指定了模型的数据类型,这里是"float16"。
这个配置文件的作用是指定了要合并的模型、合并方法、基础模型以及相关参数,以便进行模型合并操作。
运行合并命令:
mergekit-yaml ultra_llm_merged.yaml output_folder \
--allow-crimes \
--copy-tokenizer \
--out-shard-size 1B \
--low-cpu-memory \
--write-model-card \
--lazy-unpickle
-
mergekit-yaml: 这是一个命令行工具的名称,用于执行模型合并操作。 -
ultra_llm_merged.yaml: 这是一个输入参数,指定了一个配置文件的路径,该配置文件描述了模型合并的相关信息。 -
output_folder: 这是另一个输入参数,指定了合并模型的输出文件夹路径,合并后的模型将保存在这个文件夹中。 -
--allow-crimes: 这是一个选项,表示允许混合不同架构的模型进行合并。 -
--copy-tokenizer: 这是一个选项,表示在输出文件夹中复制一个分词器。 -
--out-shard-size 1B: 这是一个选项,指定了每个输出分片中的参数数量。在这里设置为1B,即1字节。 -
--low-cpu-memory: 这是一个选项,表示将结果和中间值存储在GPU上,适用于GPU显存大于系统内存的情况,以减少CPU内存的使用。 -
--write-model-card: 这是一个选项,表示输出一个包含合并详细信息的README.md文件。 -
--lazy-unpickle: 这是一个选项,表示使用实验性的懒惰反序列化器以减少内存使用量。
2. SLERP 合并 Llama3-8B、mistral-ft-optimized-1218
修改配置文件 config.yaml:
slices:
- sources:
- model: OpenPipe/mistral-ft-optimized-1218
layer_range: [0, 32]
- model: shenzhi-wang/Llama3-8B-Chinese-Chat
layer_range: [0, 32]
merge_method: slerp
base_model: OpenPipe/mistral-ft-optimized-1218
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
-
slices部分指定了要使用的模型和模型的层范围。在这里列出了两个模型,分别是"OpenPipe/mistral-ft-optimized-1218"和"mlabonne/NeuralHermes-2.5-Mistral-7B",每个模型都指定了一个层范围。 -
merge_method部分指定了如何合并slices部分指定的多个模型。在这里使用的是"slerp"方法,即球面线性插值方法。 -
base_model部分指定了基础模型,即在合并过程中将保留其结构的模型。在这里是"OpenPipe/mistral-ft-optimized-1218"。 -
parameters部分指定了模型的参数。这里包含了三个参数,分别是"self_attn"、"mlp"和一个没有指定名称的参数。每个参数都有一个filter和一个value。filter指定了参数的作用范围,value指定了参数的值。 -
dtype部分指定了模型的数据类型,这里是"bfloat16",即16位浮点数。
运行命令:
mergekit-moe config.yaml merge --copy-tokenizer
3. DARE 合并 Mistral-7B、SamirGPT-v1
修改配置文件 config.yaml:
models:
- model: mistralai/Mistral-7B-v0.1
# No parameters necessary for base model
- model: samir-fama/SamirGPT-v1
parameters:
density: 0.53
weight: 0.4
- model: abacusai/Slerp-CM-mist-dpo
parameters:
density: 0.53
weight: 0.3
- model: EmbeddedLLM/Mistral-7B-Merge-14-v0.2
parameters:
density: 0.53
weight: 0.3
merge_method: dare_ties
base_model: mistralai/Mistral-7B-v0.1
parameters:
int8_mask: true
dtype: bfloat16
-
models部分指定了要使用的模型和模型的相关参数。在这里列出了四个模型,分别是"Mistral-7B-v0.1"、“SamirGPT-v1”、“Slerp-CM-mist-dpo"和"Mistral-7B-Merge-14-v0.2”。- 对于"SamirGPT-v1"、“Slerp-CM-mist-dpo"和"Mistral-7B-Merge-14-v0.2”,指定了
density和weight参数。density指定了要保留的参数比例,weight指定了该模型的权重。
- 对于"SamirGPT-v1"、“Slerp-CM-mist-dpo"和"Mistral-7B-Merge-14-v0.2”,指定了
-
merge_method部分指定了如何合并models部分指定的多个模型。在这里使用的是"dare_ties"方法。 -
base_model部分指定了基础模型,即在合并过程中将保留其结构的模型。在这里是"Mistral-7B-v0.1"。 -
parameters部分指定了模型合并的其他参数。在这里指定了int8_mask参数为true,表示在模型合并过程中使用int8掩码。另外还指定了模型的数据类型为"bfloat16",即16位浮点数。
运行命令:
mergekit-moe config.yaml merge --copy-tokenizer
4. Passthrough 合并 Llama3-8b、Phi-3
修改配置文件 config.yaml:
slices:
- sources:
- model: cognitivecomputations/dolphin-2.9-llama3-8b
layer_range: [0, 32]
- sources:
- model: shenzhi-wang/Llama3-8B-Chinese-Chat
layer_range: [24, 32]
merge_method: passthrough
dtype: bfloat16
运行命令:
mergekit-moe config.yaml merge --copy-tokenizer
Moe 改进医学大模型
问题: 医疗健康领域的大型语言模型普遍缺乏针对医学子专业的特化,导致不能满足各子专业的独特需求。
现有的医学语言模型往往将医疗健康视为一个单一领域,忽视了其复杂的子专业。
解法: 将内科重新定义为11个不同的子专业。
- 多样性 —— 每个子专业都有其复杂和独特的语言。
- 专业性高 —— 每个子专业都要求有高水平的专业知识。
内科的子专业包括:
- 心脏病学(Cardiology):专注于心脏和循环系统的疾病。
- 内分泌学(Endocrinology):研究内分泌系统和激素相关疾病,如糖尿病。
- 胃肠病学(Gastroenterology):关注消化系统的疾病。
- 肾脏病学(Nephrology):专门处理肾脏疾病。
- 呼吸系统病学(Pulmonology):研究肺和呼吸系统的疾病。
- 风湿病学(Rheumatology):关注关节、肌肉和骨骼的疾病。
- 血液学(Hematology):研究血液、血液生成器官和血液疾病。
- 感染病学(Infectious Disease):专注于由微生物引起的疾病。
- 肿瘤学(Oncology):研究癌症及其治疗。
- 神经内科(Neurology):虽然通常被视为独立于内科的专业,但它涉及到中枢和外周神经系统的疾病。
每个子专业都需要特定的知识和技能集,因为它们涵盖的健康问题、治疗方法和研究领域各不相同。
这种细分有助于医疗专业人员更精确地诊断和治疗各种疾病,同时也支持了医学研究的深入发展。
那 Moe 分别搞,再组合成一个医学大模型,效果绝对比纯大模型好。
虽然都是医学,都属于内科,但其实差距很大。
处理不同场景
医者AI的产品可以根据不同的需求,调度不同的专家模型进行服务。
例如,如果需要通用健康管理AI,它可以调度“询症”专家模型和各种功能类的专家模型;
如果需要肺结节健康管理AI,它可以调度“复合判断”、“治法确定”专家模型和“糖尿病管理”专家模型;
如果需要针对糖尿病的营养师AI,它可以调度“糖尿病”专家模型和“食疗”专家模型等等。
MoE架构模型是一种适合健康场景的大模型,与”微调大模型”有四个本质区别:
一是前后一致性和准确性高,可达97%以上,避免了通用大模型的“幻觉”问题;
二是长期记忆强,可保留3年对话历史,不会像通用大模型那样忘记前序内容;
三是小样本训练好,通过多层模型架构实现小样本训练,1000轮小样本即可实现专人模型复制。
四是主动引导,通过1+9的MoE模型架构,实现复杂步骤的复刻,主动引导用户对话。主动引导沟通时长超过20分钟。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









