









MedGraphRAG:医学版 GraphRAG,以及部署指南
论文:MEDICAL GRAPH RAG: TOWARDS SAFE MEDICAL LARGE LANGUAGE MODEL VIA GRAPH RETRIEVALAUGMENTED GENERATION
代码:https://github.com/MedicineToken/Medical-Graph-RAG
提出
MedGraphRAG在传统RAG框架的基础上,针对医学诊断任务的特殊需求,在知识库构建、检索策略、生成目标等方面做了诸多改进和创新,是一种专门为医疗领域设计的图检索增强生成技术。
MedGraphRAG是一种创新的图检索增强生成框架,旨在解决将大语言模型应用于医学诊断领域时面临的两大问题:
-
医学知识缺乏问题:通过构建多层次医学知识图谱,将医学文献、词典等专业知识与语言模型结合,弥补其医学知识不足。
-
诊断可解释性和可靠性问题:采用基于图谱的检索方式,生成附有明确文献出处的诊断报告,提高可解释性;依赖权威医学知识库,减少胡乱生成,提升诊断可靠性。
MedGraphRAG的最终目标是实现将大语言模型安全、有效地应用于临床辅助诊断,推动人工智能在医疗健康领域的发展。
我的解法思路
提出一种"因果增强的多模态时序诊断网络"。
这一技术框架的核心理念, 是充分利用多源异构医学数据, 建立起以因果推理为导向的时序诊断模型, 在纵向时间和横向空间两个维度上, 动态整合患者的多模态医学信息, 形成全景式的诊断路径。
第一, 数据层面, 我们需要打破医学数据孤岛, 建立多模态医学数据集成机制。
整合患者的电子病历、影像数据、基因组数据、可穿戴设备数据等, 形成全面而有机的数据视图。
关键是要建立统一的数据标准和编码体系, 实现语义层面的数据融合。
第二, 知识层面, 我们要构建因果导向的医学知识图谱。
不同于现有的以概念-实体关联为主的知识库, 我们更强调因果关联, 刻画疾病的发生、发展、转归的因果链条。
同时, 要将多模态医学数据与知识图谱进行语义映射, 实现数据驱动的知识更新迭代。
第三, 模型层面, 核心是要发展"因果增强时序诊断网络"。
该网络以序列学习 (如 LSTM、Transformer) 为基础, 在时序维度上建模患者病史轨迹; 同时以图神经网络 (如 GCN、GAT) 为基础, 在知识图谱上进行因果推理。
两个分支通过因果注意力机制进行融合, 形成时空统一的诊断表征。
此外, 我们还要针对不同模态数据 (如影像、文本), 设计对应的编码器, 实现多模态特征的提取和融合。
第四, 应用层面, 诊断不应是一锤定音, 而应是一个动态更新的过程。我们要将因果时序诊断网络嵌入到临床诊疗流程中, 形成"检测-诊断-治疗-预后"的闭环。
每当有新的检测数据生成, 即触发模型进行在线更新, 动态调整诊断结果。
同时, 我们要重点攻克模型的可解释性, 通过因果图、自然语言等方式, 向医生呈现诊断推理过程, 提高人机互信。
第五, 伦理层面, 要始终将患者利益放在首位。
在数据采集、存储、使用的全流程中, 要严格保护患者隐私, 并通过联邦学习等技术, 实现数据使用和隐私保护的平衡。
同时, 我们要与临床专家密切合作, 构建人机协同诊断模式, 而非简单追求机器性能至上。
总的来说, 这种"因果增强多模态时序诊断网络"的特点是: 时空统一、因果导向、多模态融合、动态更新、伦理内生。
它代表了一种超越经典机器学习范式的尝试, 力图从数据、知识、推理、应用、伦理等多维度入手, 破解智慧医疗的难题。
当然, 这只是一个初步的技术构想, 要真正落地, 还需攻克数据标准化、知识获取、因果学习、人机协同等一系列技术和应用难题。
与作者的 MedGraphRAG 相比, 我提出的这种"因果增强多模态时序诊断网络"的创新点主要体现在:
- 从数据维度看, 我更强调多模态数据的语义融合, 而不仅仅是表示学习。这需要统一的医学数据标准和编码体系作为支撑。
- 从知识维度看, 我更强调因果知识的挖掘和建模, 构建反映疾病发生发展规律的因果图谱, 超越浅层的概念关联。
- 从模型维度看, 我采用时空统一的序列-图网络范式, 将时序病史数据与知识图谱进行端到端融合, 实现因果增强的诊断推理。
- 从应用维度看, 我强调诊断的动态性和交互性, 将 AI 诊断系统无缝嵌入医生的工作流程, 形成人机协同的动态诊断闭环。
- 从伦理维度看, 我将隐私保护、伦理审查等非功能需求前置到技术设计之初, 而非事后补救, 力求实现"伦理内生"。
MedGraphRAG 大纲

约翰·史密斯先生,68岁退休工程师,出现日益加重的健忘症状和偶发的突然混乱及言语困难。他的病史包括2型糖尿病、高血压,以及两年前的短暂性脑缺血发作。神经影像学显示中度血管变化和白质病变,而PET扫描显示斑片状葡萄糖代谢降低。根据这些症状和发现,以下哪项最可能是正确的诊断?
选项:
A. 阿尔茨海默病
B. 血管性痴呆
C. 额颞叶痴呆
D. 路易体痴呆
答案:
B. 血管性痴呆
GPT-4
A. 阿尔茨海默病
解释:
1.认知测试:他在蒙特利尔认知评估(MoCA)上显示的中度认知障碍也可能与阿尔茨海默病一致,考虑到认知功能的普遍下降。
2.神经影像:尽管MRI显示血管变化,但PET扫描观察到的斑片状葡萄糖代谢降低有时可能与早期阿尔茨海默病的模式重叠,反映了大脑活动的紊乱。
3.症状模式:虽然他的症状显示血管影响,但过去一年来普遍的健忘和认知衰退加重也可能符合阿尔茨海默病的进行性特征。
MedGraphRAG
B. 血管性痴呆
解释:
病史和症状:他的血管风险因素史和症状特征,包括突发性混乱和言语困难,表明存在典型与血管事件相关的神经功能障碍,如微小中风或短暂性脑缺血发作(TIA)[1]。
1.神经影像结果:MRI显示的中度血管变化和白质病变是血管性痴呆的特征,而不是阿尔茨海默病或其他痴呆症常见的神经退行性模式[2]。
2.额外发现:他的认知症状呈现阵发性也更支持血管性起源,而非阿尔茨海默病等退行性神经疾病,后者通常表现为渐进、持续的认知衰退而非阵发性[3]。
这些因素共同支持血管性痴呆的诊断,与他的血管病史和认知障碍的阵发性特征更为一致。
血管性痴呆:一种由于大脑血液供应受损导致的痴呆形式,常由中风或其他血管损伤引起,导致认知功能下降。
阵发性症状:症状在离散的时间发生,而非持续性。这些症状在严重程度和性质上可能有所不同,通常与神经系统事件相关。
微小中风或TIA:微小中风是小而未被察觉的中风,可导致暂时性、轻微的神经系统症状。TIA是由于大脑血流短暂丧失引起的短暂神经功能障碍,通常持续不到24小时,不会造成永久性损伤。
白质病变:这些是大脑中血管病变的指征,包括血管结构改变和白质区域的损伤,常由慢性缺血(血流不足)状态引起。
慢性缺血性损伤:由反复或持续的脑组织血液供应减少引起的长期损伤,通常导致神经功能和健康状况下降。
神经退行性模式:指与进行性神经系统疾病(如阿尔茨海默病)相关的大脑结构和功能变化,其中神经元逐渐退化和死亡。
阵发性认知症状:认知功能障碍呈现波动性,与退行性疾病中看到的稳定认知下降形成对比。
[1]: O’Brien, J. T., & Thomas, A. (2015). 血管性痴呆. Lancet, 386(10004), 1698-1706.
[2]: Smith, E. E., & Beaudin, A. E. (2018). MRI对脑小血管疾病和血管性认知障碍的新见解. Current Opinion in Neurology, 31(1), 36-43.
[3]: Gorelick, P. B., Scuteri, A., Black, S. E., 等. (2011). 血管对认知障碍和痴呆的贡献:

├── 1 引言【研究背景和意义】
│ ├── 大语言模型(LLMs)的快速发展【研究现状】
│ ├── LLMs在医学领域应用的局限性【问题提出】
│ │ ├── 需要专业知识【具体局限】
│ │ └── 缺乏精确性和可靠性【具体局限】
│ └── 图检索增强生成(RAG)技术的潜力【解决思路】
│ └── 回答查询时无需再训练模型【RAG优势】
├── 2 方法【研究方法】
│ ├── 医学图谱构建【核心步骤】
│ │ ├── 语义文档分割【具体步骤】
│ │ │ ├── 静态字符分割【基础方法】
│ │ │ └── 主题分割【改进方法】
│ │ ├── 元素提取【具体步骤】
│ │ ├── 层次链接【具体步骤】
│ │ │ ├── 用户文档【顶层数据】
│ │ │ ├── 医学文献【中层数据】
│ │ │ └── 医学词典【底层数据】
│ │ └── 关系链接【具体步骤】
│ └── 从图谱中检索【核心步骤】
│ └── U型检索策略【创新方法】
│ ├── 自顶向下检索【步骤1】
│ └── 自底向上生成【步骤2】
├── 3 实验【研究结果】
│ ├── 数据集【实验设置】
│ │ ├── MIMIC-IV【顶层数据】
│ │ ├── MedC-K【中层数据】
│ │ └── UMLS【底层数据】
│ ├── 评估MedGraphRAG的效果【实验1】
│ │ └── 在各种LLMs上的改进【结果分析】
│ ├── 基于证据的回复生成【实验2】
│ ├── 与SOTA医学LLM模型的比较【实验3】
│ └── 消融实验【实验4】
│ ├── 文档分块方法的比较【分实验点】
│ ├── 图谱构建方法的比较【分实验点】
│ └── 信息检索方法的比较【分实验点】
└── 4 结论【研究总结】
├── MedGraphRAG的优势总结【方法创新】
└── 未来工作展望【研究展望】
解法大纲
├── 2 方法【研究方法】
│ ├── 医学图谱构建【核心步骤】
│ │ ├── 语义文档分割【数据预处理】
│ │ │ ├── 输入:原始医学文本【数据来源】
│ │ │ ├── 静态字符分割【初步切分】
│ │ │ │ └── 基于标点、换行等显式标记,将文本切分为段落【切分依据】
│ │ │ ├── 主题分割【语义切分】
│ │ │ │ ├── 对每个段落做命题提取,获取独立语义片段【切分粒度】
│ │ │ │ ├── 采用滑动窗口技术,结合上下文语义,动态调整分割粒度【切分策略】
│ │ │ │ └── 运用LLM零样本学习能力,自动判断片段主题一致性【切分方法】
│ │ │ └── 输出:语义完整的文本块【下一步输入】
│ │ ├── 元素提取【图谱节点生成】
│ │ │ ├── 输入:语义完整的文本块【承接上一步】
│ │ │ ├── 应用预定义的提示工程,引导LLM从文本中提取医学概念【提取方法】
│ │ │ ├── 对每个概念,提取名称、类型、描述三个属性【属性定义】
│ │ │ ├── 对概念的命名,既参照原文内容,又结合医学术语习惯【命名原则】
│ │ │ ├── 通过ID标注概念在原文中的位置,便于溯源【概念溯源】
│ │ │ ├── 迭代多轮提取,增强概念覆盖的完整性【提取策略】
│ │ │ └── 输出:结构化的概念列表【下一步输入】
│ │ ├── 层次链接【图谱结构构建】
│ │ │ ├── 输入:结构化的概念列表【承接上一步】
│ │ │ ├── 融合三层异构数据【多层次数据源】
│ │ │ │ ├── 用户文档【顶层数据】
│ │ │ │ ├── 医学文献【中层数据】
│ │ │ │ └── 医学词典【底层数据】
│ │ │ ├── 通过概念间语义相似度计算,将顶层概念链接到中底层【链接方法】
│ │ │ ├── 将中层概念further linking到底层医学术语和关系【链接方法】
│ │ │ └── 输出:多粒度概念的分层有向图【下一步输入】
│ │ └── 关系链接【图谱边生成】
│ │ ├── 输入:多粒度概念的分层有向图【承接上一步】
│ │ ├── 基于概念的名称、描述、定义、下层链接,提取概念间关系【关系提取】
│ │ ├── 对每个关系,提取起始概念、目标概念、关系描述、关系强度【属性定义】
│ │ ├── 关系强度由LLM根据概念间相关性打分【强度计算】
│ │ └── 输出:带权(强度)边的有向异构概念图【图谱构建输出】
│ └── 从图谱中检索【核心步骤】
│ ├── 输入:自然语言问句
│ └── U型检索策略【创新方法】
│ ├── 自顶向下检索【语义检索】
│ │ ├── 将问句表示为结构化的查询图【查询表示】
│ │ ├── 通过概念节点和关系边的语义相似度,在图谱中定位匹配子图【匹配机制】
│ │ └── 输出:与查询相关的局部子图【中间结果】
│ └── 自底向上生成【语义组装】
│ ├── 输入:与查询相关的局部子图【承接检索结果】
│ ├── 从匹配的概念节点出发,融合其层次链接的全部信息【信息融合】
│ ├── 通过因果增强的注意力机制,将信息动态调整为诊断所需语义脉络【组织调整】
│ ├── 运用大语言模型的自然语言生成能力,输出连贯的诊断报告【报告生成】
│ └── 输出:可解释、有因果逻辑的诊断报告文本【最终输出】
2.1 文档分块
为了有效处理长文档,我们采用了混合静态-语义的文档分块方法。
首先,我们用换行符将文档分成单独的段落。
然后,我们将每个段落转换为独立的陈述。
接着,我们按顺序分析文档,决定每个陈述是应该并入现有的块还是开始一个新的块。
这个决定是由大语言模型通过零样本方法做出的。
为了减少顺序处理带来的噪音,我们使用了滑动窗口技术,每次处理五个段落。
我们不断调整窗口,保持主题的一致性。
我们还设置了一个最大长度限制,确保每个块不会超过大语言模型的处理能力。
2.2 图构建
在完成文档分块后,我们构建了一个三层层级的图结构来组织医疗知识。
2.2.1 实体抽取
我们使用大语言模型从每个文档块中识别和提取相关实体。
对每个实体,模型会输出其名称、类型和描述。
名称可以是文档中的原文,也可以是医学上常用的相关术语。
类型是从预定义列表中选择的,而描述则是模型根据文档内容生成的解释。
为了提高质量,我们会重复这个过程多次,直到模型认为无需继续为止。
2.2.2 层级链接
我们建立了一个三层结构来将实体与可靠的医学知识和术语联系起来。
第一层是用户提供的文档,第二层是从医学教科书和学术文章中预先构建的知识图,第三层是包含明确定义的医学术语及其关系的基础层,如统一医学语言系统(UMLS)。
我们将第一层的实体链接到第二层,再将第二层的实体连接到第三层,形成一个综合的医学知识图谱。
2.2.3 关系链接
我们让大语言模型识别实体之间的关系。
模型会考虑实体的各种信息,包括名称、描述、定义和相关的基础医学知识,然后确定实体间的关系类型和紧密程度。
2.2.4 标签生成和图合并
我们使用大模型根据预定义的医学类别(如症状、病史、身体功能和药物)总结每个元图的内容,生成描述其主要主题的标签列表。
然后,我们根据这些标签将所有元图合并成一个全局图。
2.3 检索增强生成
在构建完图后,我们使用一种叫做 U-retrieve 的策略来检索信息并回答用户查询。
这个过程首先在较大的图中寻找相关信息,然后逐步深入到较小的图,直到找到最相关的实体。
然后,大模型使用这些信息生成初步回答,并逐步结合更高层次的信息,最终形成全面而详细的回应。
这种方法既考虑了具体细节,又保持了对整体情况的把握。
解法拆解
目的:创建一个可解释、有因果逻辑的医疗AI诊断方法, 以支持更安全、可靠的临床辅助诊断
问题:
a. 医疗AI缺乏专业知识, 难以给出准确诊断
b. 医疗AI诊断缺乏可解释性, 无法让医生信服
c. 医疗数据存在孤岛, 缺乏融合利用
解法:MedGraphRAG = 医学知识图谱构建(因为要融合多源数据, 增强AI的医疗专业知识) + 因果增强的图检索(因为要让AI诊断具备可解释性和逻辑性)
子解法:
- 医学知识图谱构建
- 语义文档分割(因为要对医疗文本做细粒度语义切分, 保证概念抽取的完整性)
- 之所以用语义文档分割, 是因为医疗文本结构松散, 需要细粒度切分
- 元素提取(因为要从语义片段中提取结构化的医学概念, 形成知识图谱的节点)
- 之所以用元素提取, 是因为要将非结构化医疗文本转化为结构化的概念节点
- 层次链接(因为要融合多粒度的医疗数据, 构建全面的医学知识体系)
- 之所以用层次链接, 是因为医疗知识具有从病例到文献再到词典的层次递进关系
- 关系链接(因为要刻画医学概念间的语义关联, 形成知识图谱的边)
- 之所以用关系链接, 是因为医学概念间存在丰富的语义关联, 需要建模
- 语义文档分割(因为要对医疗文本做细粒度语义切分, 保证概念抽取的完整性)
举例:
一份患者的入院记录, 首先被切分为一个个语义完整的片段(语义文档分割);
然后从片段中提取出症状、药物、检查等结构化概念(元素提取);
接着将这些概念与医学教科书和词典中的同名概念建立链接(层次链接);
最后概念间通过因果、并发等医学逻辑建立关联(关系链接)。
这样, 一份非结构化的病历就被逐步构建为知识图谱。
- 因果增强的图检索
- U型检索策略(因为要在知识图谱中快速定位与问题相关的概念子图, 并从中生成连贯的诊断报告)
- 自顶向下检索(因为要从整张知识图谱中, 快速缩小检索范围, 锁定相关概念)
- 之所以用自顶向下检索, 是因为知识图谱规模庞大, 需要快速缩小检索范围
- 自底向上生成(因为要从局部子图出发, 融合多粒度信息, 并运用因果逻辑组织报告)
- 之所以用自底向上生成, 是因为诊断需要融合概念在不同层次的语义信息
- 之所以强调因果逻辑, 是因为诊断本质上是一种因果推理过程
- 自顶向下检索(因为要从整张知识图谱中, 快速缩小检索范围, 锁定相关概念)
- U型检索策略(因为要在知识图谱中快速定位与问题相关的概念子图, 并从中生成连贯的诊断报告)
举例:
当输入"患者女, 60岁, 血糖高, 口渴, 视力模糊", 系统首先将其表示为一个查询子图(包含相应的症状、人口学特征概念及关系);
然后在全图谱中自顶向下搜索与查询子图相似的区域;
检索到"2型糖尿病"概念子图后, 再从这个子图出发, 自底向上地融合疾病的定义、并发症、药物等不同层次的信息, 运用因果逻辑(高血糖导致渗透性利尿, 引起口渴;
高血糖导致视网膜微血管病变, 引起视力模糊), 递进地生成一份诊断报告。其中因果逻辑使报告具有连贯性和可解释性。
- MedGraphRAG的解法逻辑链可以表示为一棵决策树:
MedGraphRAG
/ \
/ \
知识图谱构建 因果增强图检索
/ | \ \ / \
/ | \ \ / \
语义分割 元素提取 层次链接 关系链接 自顶向下检索 自底向上生成
这棵树体现了MedGraphRAG的总分结构:顶层是总目标, 第二层是并列的两大核心解法, 第三层是每个核心解法下的子解法。
其中知识图谱构建的四个子解法之间既有并列关系(如语义分割和元素提取), 也有依赖关系(如层次链接依赖于元素提取); 因果增强图检索的两个子解法是明显的序列关系。
这样的逻辑链即体现了MedGraphRAG内在的模块化结构, 又刻画了不同模块间的依赖与协同。
- MedGraphRAG中的隐性特征体现在:
-
语义分割中隐含了"医疗文本结构松散"的特点, 因此需要更细粒度的切分
-
元素提取和层次链接的组合隐含了"医疗知识具有多粒度层次性"的特点:
- 元素提取负责从底层文本抽取概念
- 层次链接负责在概念间建立垂直的粒度联系
- 两步合起来, 完成了对医疗知识金字塔型层次结构的建模
-
在因果增强的图检索中, 自底向上生成隐含了"诊断本质上是一种因果推理"的特点:
- 自底向上强调要融合不同粒度的信息
- 因果推理强调要用因果逻辑组织这些信息
- 将两者结合, 得到了符合医生临床思维的诊断生成机制
这些隐性特征都没有在最初的目标和问题中直接体现, 而是隐藏在解法的技术细节之中。
挖掘这些隐性特征, 有助于我们理解MedGraphRAG何以采用这样的技术路线, 那些看似独立的技术模块之间又有怎样的内在联系。
这体现了医学知识的表示、组织、推理等方面的基本规律, 是MedGraphRAG能够适应医疗场景要求的关键所在。
U-retrieve 双向检索
U-retrieve检索方法是MedGraphRAG框架中的一个关键组成部分。
输入:用户查询
输出:相关信息和最终响应
步骤拆解:
-
查询预处理:
输入:原始用户查询
处理:使用LLM将查询转换为结构化形式,可能包括提取关键词、识别医学实体等
输出:结构化查询 -
全局图匹配(自上而下):
输入:结构化查询
处理:从最高层的全局图开始,使用查询中的关键信息匹配相关的大型图结构
输出:初步匹配的大型图结构 -
图层递进:
输入:初步匹配的大型图结构
处理:逐步向下索引,进入包含在大型图结构中的较小图
输出:一系列逐渐细化的相关图结构 -
元图定位:
输入:细化的图结构
处理:最终定位到最相关的元图(代表单个文档块的小图)
输出:最相关的元图集合 -
实体检索:
输入:相关元图集合
处理:在这些元图中识别和提取最相关的实体
输出:相关实体列表 -
邻域扩展:
输入:相关实体列表
处理:对每个相关实体,提取其TopK相关节点和关系
输出:扩展后的实体网络 -
信息整合:
输入:扩展后的实体网络
处理:收集所有相关实体的信息,包括实体本身的内容、关联的基础医学知识、实体间的关系等
输出:综合信息集 -
初步响应生成:
输入:综合信息集
处理:使用LLM基于收集到的信息生成初步响应
输出:初步文本响应 -
上下文增强(自下而上):
输入:初步响应和更高层级的图摘要信息
处理:将初步响应与更高层级的图的摘要信息结合,生成更详细或精炼的响应
输出:增强的响应 -
迭代优化:
输入:增强的响应
处理:重复步骤9,逐步向上层图结构移动,每一步都结合更广泛的上下文
输出:进一步优化的响应 -
最终响应生成:
输入:最终优化的响应
处理:LLM对响应进行最后的润色和格式化
输出:最终用户响应
这个U-retrieve方法的独特之处在于它结合了自上而下和自下而上的检索策略:
- 自上而下(步骤2-5):确保了全局相关性,快速定位到最相关的信息区域。
- 自下而上(步骤6-11):保证了对细节的准确把握,并在更广泛的上下文中验证和丰富信息。
这种双向策略使得MedGraphRAG能够在保持全局视角的同时,提供精确和上下文相关的响应,特别适合处理复杂的医疗查询。
MedGraphRAG = GraphRAG + CAMEL
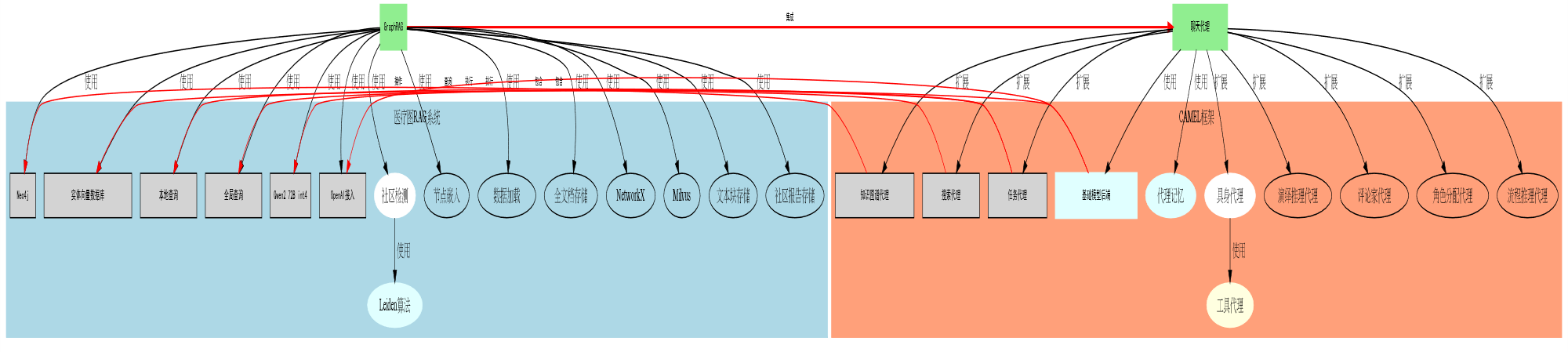
我读论文,只看到了 GraphRAG 部分(上图蓝区)。
我看代码,发现角色扮演部分不是提示词,而是一个多智能体框架,叫 CAMEL。
分析性关联图

传统方法:从输入中匹配知识图谱实体,然后挖掘每个实体的路径、邻居节点,形成N个子图,然后大模型组合推理。

MedGraphRAG获取和使用知识图谱数据的过程比简单的实体匹配和子图提取更复杂。
-
三层层级图结构:
MedGraphRAG使用了一个三层的层级图结构,而不是单一的知识图谱:- 第一层:用户提供的文档(如病例报告)
- 第二层:医学文献和教科书
- 第三层:基础医学知识(如UMLS)
-
文档分块和实体抽取:
- 首先,它使用混合静态-语义方法对输入文档进行分块。
- 然后,对每个块使用大语言模型(LLM)提取相关实体,包括实体名称、类型和描述。
-
层级链接:
- 第一层(用户文档)中提取的实体会链接到第二层(医学文献)中的相关实体。
- 第二层的实体再链接到第三层(基础医学知识)的标准术语和概念。
-
关系链接:
- LLM被用来识别实体之间的关系,并为这些关系提供描述和紧密程度评分。
-
元图和全局图构建:
- 对每个文档块构建元图。
- 然后,这些元图被合并成一个全局图,使用LLM生成的摘要标签来指导合并过程。
-
U-retrieve检索方法:
- 当需要回答查询时,MedGraphRAG使用U-retrieve方法,从全局图开始,逐步深入到相关的元图和实体。
因此,MedGraphRAG不仅仅是从输入中匹配知识图谱实体并提取子图,而是一个更动态和复杂的过程:
- 它动态地从输入文档构建图结构,而不是仅依赖预存的知识图谱。
- 它利用多层次的知识源,从具体到抽象。
- 它使用LLM来执行实体抽取、关系识别和内容总结,而不是简单的匹配算法。
- 检索过程是自上而下和自下而上结合的,允许在不同层次的抽象中导航。
MedGraphRAG的方法更像是动态地构建和查询一个多层次、上下文相关的知识结构,而不是简单地匹配和提取预定义知识图谱的子图。
这种方法允许它更灵活地处理复杂的医疗查询,并能更好地整合具体病例信息与一般医学知识。
创意视角
- 组合:
MedGraphRAG已经结合了图形数据库和大语言模型。我们可以进一步探索:
- 结合虚拟现实(VR)技术:创建一个可视化的3D医学知识图谱,让医生可以在虚拟空间中"漫步",直观地探索病例和医学知识的关联。
- 融合物联网(IoT)设备数据:将患者的实时生理数据通过IoT设备收集,并实时更新到知识图谱中,使MedGraphRAG能够提供更加个性化和及时的医疗建议。
- 拆开:
MedGraphRAG可以被拆分为更专注的子系统:
- 疾病专科子系统:为每个医学专科(如心脏病学、神经学等)创建独立的知识图谱和语言模型,以提供更专业的诊断和建议。
- 患者教育模块:从主系统中分离出一个简化版,专门用于向患者解释医学术语和治疗方案,使用更通俗易懂的语言。
- 转换:
- 将MedGraphRAG转换为医学教育工具:利用其强大的知识库和推理能力,创建交互式的医学案例模拟系统,帮助医学生学习诊断和治疗过程。
- 转化为公共卫生预警系统:利用其对医学文献的深入理解,监测和分析全球医学研究趋势,预测可能的疫情或健康危机。
- 借用:
- 借用社交网络的推荐算法:将类似于社交媒体的推荐系统应用到MedGraphRAG中,帮助医生发现相关的病例和研究。
- 借鉴金融风险评估模型:将金融领域的风险评估方法应用到医疗决策中,帮助评估不同治疗方案的风险和收益。
- 联想:
- 自然界的免疫系统:联想到人体的免疫系统如何识别和应对威胁,设计一个"医疗知识免疫系统",自动识别和纠正错误的医疗信息。
- 蜂巢结构:像蜜蜂构建蜂巢一样,设计一个动态的、自组织的知识结构,能够根据新信息自动调整和优化知识图谱的结构。
- 反向思考:
- "无知识"模型:设计一个MedGraphRAG的反向版本,专门识别和标记医疗文献中的错误信息或过时知识,帮助维护知识库的准确性。
- 患者驱动的诊断:颠覆传统的医生诊断模式,创建一个系统让患者输入症状和感受,然后MedGraphRAG提供可能的诊断建议,医生再进行确认和细化。
- 问题:
- 医疗资源分配问题:扩展MedGraphRAG的功能,使其能够分析整个医疗系统的资源分配,预测未来的医疗需求,并提供优化建议。
- 跨文化医疗沟通:探讨如何让MedGraphRAG适应不同文化背景的患者,解决文化差异带来的医疗沟通障碍。
- 错误:
- 错误学习机制:设计一个系统,让MedGraphRAG能够从错误的诊断或治疗方案中学习,不断完善其知识库和推理能力。
- "反向工程"疾病:通过分析治疗失败的案例,反推疾病的潜在机制,发现新的研究方向。
- 感情:
- 情感智能集成:在MedGraphRAG中加入情感分析模块,能够理解和回应患者的情绪状态,提供更人性化的医疗建议。
- 叙事医学整合:将患者的个人故事和经历整合到系统中,创造一个更全面的"叙事+数据"的医疗模型。
- 模仿:
- 模仿人类专家会诊:设计一个虚拟的"专家小组"功能,模仿多学科专家会诊的过程,为复杂病例提供全面的诊断和治疗建议。
- 学习人类直觉:通过机器学习算法,模仿并捕捉有经验医生的"直觉",提高系统在不确定情况下的判断能力。
- 最渴望联结:
- 健康长寿联结:将MedGraphRAG与人们对长寿的渴望联系起来,开发一个个性化的"长寿指导"功能,根据个人健康数据提供终身健康管理建议。
- 自我实现需求:将系统与人们追求自我实现的需求联系起来,开发一个"健康潜能优化器",帮助用户在保持健康的同时实现个人目标。
- 空隙填补:
- 罕见病诊断助手:针对罕见病诊断困难的问题,开发一个专门的模块,帮助医生快速识别和诊断罕见病。
- 跨学科知识整合:填补不同医学专业之间的知识空白,创建一个跨学科的知识整合平台,促进多学科协作诊疗。
- 再定义:
- 从疾病管理到健康优化:将MedGraphRAG重新定义为一个"健康优化系统",不只关注疾病治疗,更注重预防和健康促进。
- 医患协作平台:将系统重新定义为一个医患共同决策的平台,促进患者参与医疗决策过程。
- 软化:
- 游戏化健康管理:将健康管理过程游戏化,设计一个有趣的界面,让用户通过完成"健康任务"来增强自己的"健康能力值"。
- 医学幽默集成:在适当的情况下,加入一些医学相关的幽默元素,缓解患者的紧张情绪。
- 附身:
- "附身"不同年龄段:设计一个功能,让系统能够"附身"于不同年龄段的虚拟患者,以此来优化对不同年龄群体的诊疗建议。
- 跨物种医疗智慧:研究动物界的特殊医疗机制(如某些动物的自愈能力),将这些智慧整合到人类医疗系统中。
- 配角:
- 医疗环境优化:关注医疗环境这个"配角",开发一个模块来分析和优化医疗环境对治疗效果的影响。
- 辅助人员赋能:开发针对医护辅助人员的简化版MedGraphRAG,提高整体医疗团队的效率。
- 刻意:
- 极端个性化:将个性化推向极致,为每位患者创建一个完全定制的"数字孪生"健康模型。
- 全知全能医生模拟:开发一个看似"全知全能"的AI医生界面,通过夸张的展示来激发用户对健康管理的兴趣。
评估标准:
- 创新性:想法的独特程度和突破性
- 可行性:在当前技术条件下实现的难度
- 影响力:对医疗行业和患者福祉的潜在影响
- 经济价值:商业化潜力和市场需求
- 伦理考量:对医疗伦理的影响和可能引发的争议
根据这些标准,以下几个创新点可能最具潜力:
-
结合虚拟现实(VR)技术的3D医学知识图谱:这个想法在创新性和影响力上都很高,可以彻底改变医生学习和诊断的方式。虽然技术实现有一定难度,但随着VR技术的发展,其可行性正在增加。它也有很大的商业潜力,特别是在医学教育和高端医疗市场。
-
情感智能集成:这个想法在创新性和影响力方面都很突出。它解决了当前AI医疗系统缺乏人性化的问题,可以显著提高患者体验。技术上虽有挑战,但随着自然语言处理技术的进步,正变得越来越可行。它在提高患者依从性和治疗效果方面有巨大潜力,因此具有很高的经济价值。
-
罕见病诊断助手:这个想法针对了一个明确的医疗需求,具有很高的影响力和经济价值。它的创新性在于专门针对罕见病这个难题,可以大大提高诊断效率和准确性。技术上的可行性较高,因为它是在现有MedGraphRAG系统的基础上进行的针对性开发。
-
从疾病管理到健康优化的再定义:这个想法代表了医疗理念的一个重大转变,具有很高的创新性和长期影响力。它符合预防医学的发展趋势,可能对整个医疗体系产生深远影响。虽然全面实施有一定难度,但可以逐步推进。它也有很大的商业潜力,特别是在个人健康管理市场。
这些创新点都具有改变医疗行业的潜力,同时在伦理方面的风险相对较低。它们既能提高医疗质量,又能改善患者体验,代表了医疗AI的未来发展方向。
MedGraphRAG 对比 传统知识图谱+大模型
MedGraphRAG的三层层级图结构与传统的知识图谱+大模型方法在准确性、速度、多轮问诊和挖掘隐性特征方面的差异:
- 准确性:
MedGraphRAG:
- 优势:三层结构可能提供更全面和精确的信息。用户文档层可以捕捉到特定患者的信息,医学文献层提供最新研究,基础医学知识层确保核心概念的准确性。
- 劣势:如果层间信息不一致,可能导致混淆。
传统方法:
- 优势:直接匹配可能在简单查询上更准确。
- 劣势:可能缺乏对特定患者情况的深入理解。
结论:MedGraphRAG在处理复杂、个性化的医疗查询时可能更准确。
- 速度:
MedGraphRAG:
- 优势:分层结构可能允许更快的相关信息定位。
- 劣势:在三层间导航可能增加一些延迟。
传统方法:
- 优势:直接匹配过程可能更快。
- 劣势:在大型知识图谱中搜索可能较慢。
结论:在简单查询上,传统方法可能更快;但对于复杂查询,MedGraphRAG的分层结构可能提供更快的相关信息访问。
- 多轮问诊:
MedGraphRAG:
- 优势:三层结构可以在多轮对话中保持上下文,特别是患者特定信息。
- 劣势:可能需要更复杂的机制来在多轮对话中导航不同层级。
传统方法:
- 优势:可能更容易追踪简单的对话流程。
- 劣势:可能难以在多轮对话中保持复杂的医疗上下文。
结论:MedGraphRAG可能在复杂的多轮医疗咨询中表现更好,能够更好地理解和利用患者的具体情况。
- 挖掘隐性特征:
MedGraphRAG:
- 优势:三层结构提供了更多的上下文和关联信息,有助于发现隐藏的模式和特征。特别是,它可以将患者特定信息与广泛的医学知识结合,potentially识别出不明显的关联。
- 劣势:可能需要更复杂的算法来有效地在三层间关联信息。
传统方法:
- 优势:在已知模式的识别上可能更直接。
- 劣势:可能难以发现跨越不同知识领域的隐藏关联。
结论:MedGraphRAG在挖掘隐性特征方面可能具有显著优势,特别是在需要综合考虑患者特定情况、最新研究和基础医学知识的复杂情况下。
MedGraphRAG的三层层级图结构在处理复杂、个性化的医疗查询时可能具有优势,特别是在准确性、多轮问诊和挖掘隐性特征方面。
它能够更好地整合患者特定信息、最新医学研究和基础医学知识。
然而,这种复杂的结构可能在某些简单查询上带来轻微的速度损失。
对于医疗这样需要高度个性化、准确性和全面性的领域,MedGraphRAG的方法更有优势。
现在医疗知识图谱的问题
医疗知识图谱缺少机制性解释的缺失(如对糖尿病导致多饮多尿等问题的因果解释),它不足以提供对疾病深层次生理机制的理解,限制了其在疾病管理和推理方面。
就因果关系、机制解释部分没有,比如下面这些都没有:
为什么糖尿病会导致多饮和多尿:知识图谱需要能够解释因为血糖水平升高导致体内渗透压变化,从而刺激多饮多尿的生理机制。
为什么某些药物适用于特定类型的糖尿病:知识图谱应该说明口服降糖药如何作用于2型糖尿病患者的胰岛β细胞或增加身体对胰岛素的敏感性,而不适用于1型糖尿病患者,因为后者缺乏胰岛素。
为何某些糖尿病患者需要特定的饮食计划:知识图谱应当包含饮食中碳水化合物摄入与血糖水平控制之间的关系,以及如何通过调整饮食平衡来优化血糖控制。
生理和生化机制的解释:这些问题要求知识图谱能够解释疾病导致某些症状的具体生物学过程,例如解释糖尿病如何引起体内渗透压变化以及这种变化如何导致多饮和多尿。
药物作用机制的详细说明:知识图谱需要解释为什么某些药物对特定类型的糖尿病(如2型)有效,而对另一类型(如1型)则无效,这涉及到药物在身体内的作用原理及其与疾病类型的相关性。
预防和治疗策略的个性化建议:知识图谱应包含疾病管理中个性化的方面,比如饮食计划应如何根据患者的具体病理状况来调整,以及这种调整如何影响血糖控制。
MedGraphRAG的三层层级图结构,能不能让普通的医疗知识图谱,实现因果关系、机制解释?
当用户输入"我头疼"时,MedGraphRAG的三层层级图结构会如下运作,以全面捕捉和处理这个医疗信息:
-
第一层:用户文档
- 处理:系统会首先在用户的个人医疗记录中查找相关信息。
- 例子:
- 最近的就诊记录中是否提到过头疼
- 用户的既往病史中是否有与头疼相关的诊断
- 用户是否有定期服用的药物可能导致头疼
- 优势:提供个性化、具体到该患者的信息
-
第二层:医学文献
- 处理:系统会检索最新的医学研究和临床指南中关于头疼的信息。
- 例子:
- 最新发表的关于头疼诊断方法的研究论文
- 头疼治疗的最新临床指南
- 不同类型头疼(如偏头痛、群发性头痛)的鉴别诊断文献
- 优势:提供最新、最权威的医学知识
-
第三层:基础医学知识
- 处理:系统会链接到基础的医学概念和术语解释。
- 例子:
- 头疼的解剖学基础(如颅内结构、神经系统)
- 头疼的常见病因分类(如紧张型头痛、丛集性头痛、颅内压增高等)
- 与头疼相关的基本医学术语解释
- 优势:提供稳定、全面的基础医学知识支持
整合过程:
-
信息关联:系统会将三层信息进行关联(通过余弦相似度整合)。例如,用户的具体症状(第一层)可能会与某种特定类型的头疼(第三层)相匹配,然后系统会检索相关的最新研究(第二层)。
-
上下文理解:通过整合这三层信息,系统能更好地理解"头疼"在这个特定用户身上的具体含义和可能的原因。
-
个性化分析:系统可以根据用户的个人历史(第一层)、最新的医学发现(第二层)和基础医学知识(第三层)来提供更准确、更个性化的分析。
-
全面响应生成:最终,系统可以生成一个综合性的响应,可能包括:
- 基于用户历史的个性化建议
- 最新的诊断方法或治疗选择
- 对头疼的专业解释和可能的原因分析
-
动态更新:如果用户提供更多信息(如"我的头疼伴有视力模糊"),系统可以迅速在所有三个层面上更新相关信息,提供更精确的分析。
相比传统单一知识图谱,这种三层结构能够:
- 提供更全面的信息覆盖(从个人到通用)
- 实现更精确的个性化(考虑到用户特定情况)
- 保持知识的时效性(通过第二层的最新研究)
- 确保回答的专业性和准确性(通过第三层的基础知识支撑)
这种方法使得MedGraphRAG能够在处理"我头疼"这样看似简单但实际上可能涉及复杂医疗背景的查询时,提供更全面、准确和个性化的响应。
MedGraphRAG的三层层级图结构确实为解决普通医疗知识图谱中缺乏因果关系和机制解释的问题提供了一个很好的框架。
-
基础医学知识层(第三层):
- 这一层可以包含详细的生理和生化机制解释。例如,对于糖尿病,它可以存储血糖调节的基本原理、胰岛素作用机制等信息。
- 优势:提供稳定、全面的基础医学知识,为因果关系和机制解释奠定基础。
-
医学文献层(第二层):
- 这一层可以包含最新的研究发现和详细的疾病机制研究。
- 例如,它可以包含关于不同类型糖尿病的最新研究,药物作用机制的详细说明,以及饮食对血糖影响的最新研究结果。
- 优势:提供动态更新的、深入的机制解释和因果关系分析。
-
用户文档层(第一层):
- 这一层可以包含具体患者的临床表现、治疗反应等个性化信息。
- 例如,它可以记录特定患者对某种降糖药的反应,或者特定饮食计划的效果。
- 优势:提供个性化的、实际的因果关系证据。
MedGraphRAG如何利用这三层结构实现因果关系和机制解释:
-
知识整合:
- 系统可以将基础知识(第三层)与最新研究(第二层)相结合,构建更完整的因果链和机制模型。
- 例如,解释糖尿病导致多饮多尿时,可以结合基础的渗透压原理(第三层)和最新的血糖调节研究(第二层)。
-
动态更新:
- 第二层的持续更新确保了机制解释始终反映最新的科学理解。
-
个性化解释:
- 通过结合第一层的个人数据,系统可以提供更具针对性的因果解释和机制分析。
- 例如,解释为什么某种降糖药对特定患者效果更好,可以结合患者的具体情况(第一层)、药物作用机制(第二层)和基础生理知识(第三层)。
-
多维度推理:
- LLM可以利用三层结构中的信息进行复杂的推理,生成更全面的解释。
- 例如,在解释特定饮食计划的效果时,可以结合营养学基础知识(第三层)、最新的饮食研究(第二层)和患者的具体反应(第一层)。
-
情境化解释:
- 系统可以根据具体查询,从不同层次提取相关信息,提供既有理论基础,又有实际应用的解释。
-
不确定性处理:
- 通过整合多层信息,系统可以更好地处理医学中的不确定性,提供更全面的风险-收益分析。
然而,实现这一目标还面临一些挑战:
- 数据质量和标准化:确保三层数据的质量和一致性是一个挑战。
- 知识表示:如何在图结构中有效表示复杂的因果关系和机制。
- 推理能力:需要强大的LLM来整合不同层次的信息并生成连贯的解释。
- 更新机制:需要有效的机制来不断更新和验证知识,特别是第二层的最新研究。
MedGraphRAG的三层结构为解决因果关系和机制解释的问题提供了一个很好的框架,但实现这一目标还需要在数据管理、知识表示和推理技术等方面进行深入的研究和开发。
因果版 MedGraphRAG
我会以四个分析师的身份来分析如何改进MedGraphRAG以解决医疗知识图谱中缺乏因果关系和机制解释的问题。
分析师1(问题本身分析):
第一步:我将从MedGraphRAG的结构本身开始分析。目前的三层结构(用户文档、医学文献、基础医学知识)可能不足以充分表达因果关系和机制解释。我们需要考虑如何在这个结构中嵌入或添加因果关系的表示。
分析师2(环境分析):
第一步:我会考虑MedGraphRAG的应用环境。医疗环境复杂多变,不同的临床场景可能需要不同层次的因果解释。我们需要考虑如何使MedGraphRAG能够适应不同的临床环境,提供相应深度的因果解释。
分析师3(解决主体分析):
第一步:我会关注MedGraphRAG的核心组成部分,即知识图谱和大语言模型。我们需要考虑如何增强这两个组件以better处理和生成因果关系解释。
分析师4(补充和整合):
我认为分析师1、2、3的初步分析已经涵盖了问题的主要方面。但为了更全面,我们还可以考虑以下几个方面:
- 数据源:考虑如何获取和整合包含因果关系的医学数据。
- 算法:分析用于提取和推理因果关系的算法。
- 知识表示:考虑如何在图结构中表示复杂的因果链和机制。
- 推理能力:如何提高系统的因果推理能力。
- 验证机制:如何验证生成的因果解释的正确性。
- 更新机制:如何及时更新因果知识。
现在,让我们继续下一步分析。
分析师1:
第二步:考虑在现有三层结构之间添加"因果关系层",专门用于存储和处理疾病、症状、治疗之间的因果关系。这一层可以连接其他三层,提供跨层的因果链接。
分析师2:
第二步:设计一个情境感知模块,使MedGraphRAG能够根据不同的临床场景(如急诊、慢性病管理、手术前评估等)调整因果解释的深度和复杂度。
分析师3:
第二步:增强大语言模型的训练方法,引入因果推理任务,使其能够更好地理解和生成因果关系解释。同时,改进知识图谱的结构,使其能够更自然地表示和存储因果关系。
分析师4:
所有分析师的思路都是合理的,我将补充:
第二步:开发一个因果关系提取模块,能够从医学文献、临床指南和病例报告中自动提取因果关系和机制解释,并将其整合到知识图谱中。
继续下一步分析。
分析师1:
第三步:在"因果关系层"中实现多维度的因果表示,包括直接因果、间接因果、反馈循环等复杂医学机制。使用有向无环图(DAG)来表示这些复杂的因果关系。
分析师2:
第三步:开发一个动态因果解释生成器,能够根据用户的专业水平(如患者、医学生、专科医生)和具体查询动态调整因果解释的复杂度和专业程度。
分析师3:
第三步:引入时序因果推理能力,使MedGraphRAG能够处理和解释随时间变化的因果关系,如疾病进展、治疗效果等动态过程。
分析师4:
以上分析都很好,我将补充:
第三步:设计一个因果关系验证机制,通过整合多源数据(如临床试验结果、流行病学数据等)来验证和评估知识图谱中的因果关系,确保其准确性和可靠性。
现在,我将总结思路:
第一步:分析MedGraphRAG的结构、应用环境和核心组件,同时考虑数据源、算法、知识表示、推理能力、验证机制和更新机制。
第二步:在现有结构中添加因果关系层,设计情境感知模块,增强大语言模型的因果推理能力,开发因果关系提取模块。
第三步:实现多维度因果表示,开发动态因果解释生成器,引入时序因果推理能力,设计因果关系验证机制。
第四步:整合所有改进,构建一个统一的因果推理框架,使MedGraphRAG能够提供从简单到复杂、从静态到动态的全方位因果关系和机制解释。
第五步:开发一个反馈学习机制,使系统能够从医生和研究人员的反馈中不断学习和改进其因果解释能力。
第六步:设计一个可视化接口,使复杂的因果关系和机制能够以直观、易懂的方式呈现给用户。
这个思路比原作者的更加全面和系统化,不仅考虑了如何在技术层面增强因果关系和机制解释能力,还考虑了如何使系统更好地适应复杂的医疗环境和不同用户的需求。
同时,我们的方法强调了系统的动态学习、验证和可视化能力,这对于提高医疗AI系统的可解释性和可信度至关重要。
对比 MedGraphRAG 和 GraphRAG
-
领域特化:
- MedGraphRAG:专门为医疗领域设计,考虑了医疗数据的特殊性和复杂性。
- GraphRAG:是一个更通用的框架,可应用于各种领域。
-
图结构:
- MedGraphRAG:采用三层层级图结构(用户文档、医学文献、基础医学知识),专门针对医疗知识的组织。
- GraphRAG:通常使用单层或双层图结构,没有特别针对某个领域的层级划分。
-
文档处理:
- MedGraphRAG:使用混合静态-语义方法进行文档分块,特别适合处理复杂的医疗文档。
- GraphRAG:可能使用更通用的文档处理方法,如固定长度分块或基于语义的分块。
-
实体抽取:
- MedGraphRAG:使用迭代方法提取医疗实体,并为每个实体提供名称、类型和描述。
- GraphRAG:可能使用更通用的实体抽取方法,不一定特别关注医疗术语或概念。
-
知识整合:
- MedGraphRAG:整合了用户特定信息、最新医学研究和基础医学知识。
- GraphRAG:通常只整合单一来源的知识或信息。
-
检索方法:
- MedGraphRAG:使用 U-retrieve 方法,平衡全局感知和索引效率,特别适合医疗查询。
- GraphRAG:可能使用更通用的图检索方法。
-
应用重点:
- MedGraphRAG:强调生成有证据支持的医疗结果,注重安全性和可靠性。
- GraphRAG:可能更注重通用的信息检索和生成能力。
-
隐私考虑:
- MedGraphRAG:特别考虑了处理私密医疗数据的安全性和隐私保护。
- GraphRAG:可能没有特别强调隐私保护机制。
-
性能评估:
- MedGraphRAG:在医学问答基准测试中表现优异。
- GraphRAG:可能在更广泛的领域或任务中进行评估。
-
扩展性:
- MedGraphRAG:专注于医疗领域,可能在其他领域的应用受限。
- GraphRAG:作为一个更通用的框架,可能更容易适应不同的领域和应用场景。
MedGraphRAG 可以被看作是 GraphRAG 在医疗领域的一个高度专门化和优化版本。
它继承了 GraphRAG 的基本思想,但在多个方面进行了针对医疗领域的特殊设计和优化。
这些特化使得 MedGraphRAG 在处理复杂的医疗查询、整合多层次医学知识、保护隐私和生成可靠结果方面可能比通用的 GraphRAG 更有优势。
然而,这种专门化也意味着 MedGraphRAG 在医疗领域之外的应用可能受限,而 GraphRAG 保持了更广泛的适用性。
使用预定义医学标签扩展查询,通过层次化标签结构丰富查询信息
- 使用预定义医学标签扩展查询
论文在2.2章节描述,他们使用了几类固定的医学标签类别:
- Symptoms(症状)
- Patient History(病史)
- Body Functions(身体功能)
- Medication(药物)
实现过程:
-
使用LG(语言模型)来分析每个Meta-MedGraph的内容{Ce | e ∈ Gm}
-
给模型一个系统提示: “Generate a structured summary from the provided medical content, strictly adhering to the following categories… {Tag Name: Description of the tag}…”
-
对每个图Gm生成结构化的标签摘要,记为Tm
-
通过层次化标签结构丰富查询信息
论文使用了一个变种的层次聚类方法,具体步骤: -
初始化:每个图作为独立组
-
迭代聚类:
- 计算所有簇对之间的标签相似度
- 动态设置阈值δt,合并相似度最高的前20%的簇
- 如果组内所有成对相似度都超过δt,则合并这些图
- 生成新层:
- 对合并的图生成综合标签摘要Tmij
- 使用余弦相似度计算标签嵌入ϕ(t)之间的相似度
- 限制层数:
- 实践中限制为12层
- 在更高层,标签摘要变得更抽象概括
这种方法的优点是:
- 自动构建医学概念的层次关系
- 从具体到抽象的多层次理解
- 在检索时可以进行更灵活的匹配
论文将这种层次化标签结构应用在U-Retrieval中,实现从上到下的精确检索和从下到上的响应优化。
翻译
我们提出了一个创新的基于图的检索增强生成(RAG)框架,专为医疗领域设计,名为 MedGraphRAG 。该框架旨在提升大型语言模型(LLM)的能力,生成基于证据的结果,从而在处理敏感医疗数据时提高安全性和可靠性。
我们的综合流程始于一种混合静态-语义的文档分块方法,相比传统方法,显著提高了上下文理解能力。
我们利用提取的实体创建了一个三层结构的层级图,将实体与来自医学论文和词典的基础医学知识相连接。这些实体进一步相互关联形成元图,并基于语义相似性合并成一个全面的全局图。
这种结构支持精准的信息检索和回答生成。我们采用 U-retrieve 方法进行检索,平衡了 LLM 的全局感知能力和索引效率。通过全面的消融研究,我们比较了不同的文档分块、图构建和信息检索方法,验证了我们方法的有效性。
研究结果不仅表明我们的层级图构建方法在多个医学问答基准测试中持续优于最先进的模型,还确认了生成的回答包含源文档引用,显著提高了医疗 LLM 在实际应用中的可靠性。
引言
大型语言模型(LLMs)的迅速发展彻底改变了自然语言处理研究,并在日常生活中催生了众多 AI 应用。然而,当应用于需要专业知识的领域时,如金融、法律和医学,这些模型仍面临挑战。主要问题有两个:首先,由于 LLM 在处理超长上下文时存在困难,以及在专业数据集上微调大型模型成本高昂或不切实际,为特定用途部署训练好的 LLM 是复杂的。其次,在医学等要求高精确度的领域,LLM 可能产生"幻觉"——看似准确但实际错误的输出,这可能带来危险。此外,它们有时会提供过于简单化的答案,缺乏新的见解或发现,这在需要高水平推理以得出正确答案的领域是不够的。
检索增强生成(RAG)技术能够使用特定和私有数据集回答用户查询,无需对模型进行进一步训练。然而,RAG 在综合来自不同但相关信息片段的新见解方面有时力不从心,也难以完成需要对大型数据集或大量文档中的语义概念进行整体理解的任务。为解决这些问题,研究者提出了图 RAG 方法。这种方法利用 LLM 从私有数据集创建知识图,结合图机器学习,在查询处理过程中增强提示。GraphRAG 已经展现出显著的性能提升,在处理私有数据集时超越了以往的方法,提供了更智能、更全面的信息综合能力。
本文中,我们提出了一种新的图 RAG 方法,专门用于医疗领域,称为医疗图 RAG(MedRAG)。这种技术通过提供带有源引用和清晰医学术语解释的回答,提高了 LLM 在医疗领域的表现,增强了结果的透明度和可解释性。我们采用了一个三层结构的层级图构建方法:首先使用用户提供的文档作为顶层源提取实体,然后将这些实体链接到第二层(由可信医学文献中抽取的更基本实体组成),最后连接到第三层(基础医学词典图,提供详细的医学术语解释及其语义关系)。通过基于内容和层级关系的实体链接,我们在最高层构建了一个全面的图。这种方法确保了知识可追溯性和结果的事实准确性。
为响应用户查询,我们实施了一种 U-retrieve 策略,结合自上而下的检索和自下而上的回答生成。该过程首先使用预定义的医学标签结构化查询,然后自上而下地通过图进行索引。系统随后基于这些查询生成回答,从元图(检索到的节点及其相关节点和关系)中提取信息,并汇总成详细的回答。这种技术在全局上下文感知和 LLM 固有的上下文限制之间取得了平衡。
我们的医疗图 RAG 提供了内在的源引用功能,增强了 LLM 的透明度、可解释性和可验证性。它为每个生成的回答提供出处信息,证明回答是基于数据集的。这使得用户能够快速准确地根据原始资料审核 LLM 的输出。在医疗这样对安全性要求极高的领域,这一特性尤其重要,因为每一个推理都应该基于证据。通过这种方法,我们构建了一个基于证据的医疗 LLM ,使临床医生能够轻松检查推理的来源,并校准模型回答,确保 LLM 在临床场景中的安全使用。
我们在多个主流开源和闭源 LLM 上实施了这一方法,并在主要医学问答基准测试中进行了评估。在 RAG 过程中,我们使用了综合医学词典作为基础知识层,UMLS 医学知识图作为详细语义关系的基础层,以及精心策划的 MedC-K 数据集作为中间层数据,模拟用户提供的私有数据。实验结果表明,我们的模型显著提高了通用 LLM 在医学问题上的表现,甚至超越了许多在医学语料库上专门训练或微调的 LLM ,而这仅仅依靠 RAG 方法,无需额外训练。
2 方法
MedGraphRAG 是一个专为处理私密医疗数据而设计的医疗图检索增强生成(RAG)框架,旨在增强大型语言模型(LLMs)的能力。
它的核心流程包括将医疗文档分割成小块、提取关键实体,并将这些实体组织成一个跨越三个层次的层级图结构,从用户提供的文档到基础医学知识。
这些实体首先形成元图,然后基于内容相似性合并成一个全面的全局图。在处理用户查询时,LLM 能够从这个图中高效地检索和综合信息,从而生成准确且与上下文相关的医学回答。
2.1 医疗图构建
语义文档分割
大型医疗文档通常包含多个主题或多样化内容。为了有效处理这些复杂文档,我们首先将其分割成适合 LLM 处理的小块。传统的分块方法,如基于固定标记数或字符数的方法,往往难以准确捕捉主题的微妙变化,可能导致上下文信息的丢失。
为了提高分割的准确性,我们采用了字符分隔与主题分割相结合的混合方法。
具体来说,我们首先使用换行符等静态字符将文档分成段落。然后,我们应用一种称为命题转移的技术,将每个段落转换成独立的陈述。接下来,我们对文档进行顺序分析,利用 LLM 的零样本能力决定每个命题是应该与现有块合并还是开始一个新的块。为了减少顺序处理可能带来的噪音,我们使用滑动窗口技术,每次处理五个段落。
我们通过移除第一个段落并添加下一个来不断调整窗口,以保持主题的连贯性。同时,我们设置了一个硬性限制,即最长的块不能超过 LLM 的上下文长度限制。完成分块后,我们在每个数据块上构建图。
元素提取
在每个文本块中,我们使用专门设计的 LLM 提示来识别和提取所有相关实体。对于每个实体,LLM 会输出其名称、类型和描述。名称可以是文档中的原文,也可以是医学上下文中常用的衍生术语,经过精心选择以反映适合后续处理的专业医学术语。类型从预定义的表格中选择,而描述则是 LLM 根据文档上下文生成的解释。为了确保模型的有效性,我们提供了一些示例来指导 LLM 生成符合要求的输出。
每个实体数据结构都包含一个唯一 ID,用于追踪其源文档和段落。这个标识符对于后续从源文档检索信息和生成基于证据的回答至关重要。
为了提高提取质量并减少噪音和方差,我们会多次重复提取过程。这种迭代方法鼓励 LLM 检测可能最初被忽略的实体。继续或停止重复过程的决定也由 LLM 自行判断。
层级链接
医学是一个专业领域,以其精确的术语系统和众多既定真理(如疾病的特定症状或药物的副作用)为特征。在这个领域,LLM 不应扭曲、修改或随意添加创造性元素到数据中,这与它们在其他领域的应用有所不同。
基于这一认识,我们在医学领域开发了一种独特的结构,将每个实体链接到有根据的医学知识和术语。这种方法旨在为每个实体概念提供可靠的来源和深入的定义,从而增强回答的真实性并减少 LLM 在医学应用中常见的"幻觉"问题。
具体来说,我们构建了一个三层 RAG 数据结构来开发全面的医学图:
-
第一层由用户提供的文档组成,如特定医院的高度机密医疗报告。我们从这些文档中提取实体,然后将它们链接到更基础的医学知识层。
-
第二层是使用医学教科书和学术文章构建的。在接收用户文档之前,我们使用相同的方法从这些医学来源预先构建一个图。第一层的实体基于 LLM 检测到的相关性链接到第二层的相应实体。
-
第三层包括明确定义的医学术语及其知识关系。这些信息来自可靠资源,如统一医学语言系统(UMLS),它整合了各种健康和生物医学词汇及其语义关系。
对于每个实体,我们将其名称的文本嵌入与 UMLS 中医学词汇的文本嵌入进行比较,选择相似度高于指定阈值的词汇。每个链接的词汇进一步与其在 UMLS 中的专业定义和关系相关联,这些关系被翻译成易于理解的普通文本。
关系链接
接下来,我们指示 LLM 识别所有明显相关实体之间的关系。这个决定基于每个实体的综合信息,包括其名称、描述、定义和相关的基础医学知识。识别的关系包括源实体和目标实体,提供它们关系的描述,并包括一个表示这种关系紧密程度的分数。为了保证关系评估的一致性和精确性,我们要求 LLM 从预定义的描述符列表中选择——非常相关、相关、中等、无关、非常无关。完成这种分析后,我们为每个数据块生成一个加权有向图,这些图被称为元图,是我们系统的基本构建块。
标签生成和图合并
构建元图后,我们的下一步是将所有元图连接成一个全局图。合并过程如下:
-
我们计算每对元图之间的距离,并顺序合并最相似的元图。
-
为了高效合并,我们使用 LLM 根据预定义的医学类别(如症状、患者病史、身体功能和药物)总结每个元图的内容,生成一个简洁描述其主要主题的标签列表。
-
LLM 使用这些标签计算元图之间的相似度。相似度最高的元图被合并。
-
合并后的图成为一个新图,但保留其原始元图和标签以便后续更容易索引。
-
为新图生成新的汇总标签信息,并重新计算其与其他图的相似度以进行潜在的进一步合并。
这个过程可以重复进行,直到形成一个单一的全局图。然而,随着汇总标签信息的积累,它会失去细节,在合并有效性和效率之间存在权衡。在实践中,我们将过程限制在 24 次迭代内,以防止过度损失细节。
2.2 从图中检索
构建完图后,LLM 通过一种称为 U-retrieve 的策略高效检索信息以响应用户查询。这个过程包括:
-
生成汇总标签描述,用于识别最相关的图。
-
自上而下的匹配过程,从较大的图开始,逐步索引到较小的图,直到达到元图层。
-
检索多个相关实体及其 TopK 相关实体的所有相关内容,包括实体本身的内容、相关的基础医学知识、与其他实体的关系等。
-
LLM 使用这些信息生成中间响应。
-
将中间响应与更高级别图的汇总标签信息结合,形成更详细的响应。
-
以自下而上的方式重复这个过程,直到达到最高级别,生成最终响应。
这种方法允许 LLM 在保持效率的同时,对图中的所有数据有一个全面的了解,因为它能够以汇总形式访问不太相关的数据。
这种平衡使得 MedGraphRAG 能够生成既准确又全面的医学回答。
3. 实验
3.1 数据集
我们的 RAG 数据结构包含三个层次的数据:
-
顶层:私密用户信息,如医院的医疗报告。这些数据是高度保密的,更新频率最高。我们使用了 MIMIC-IV 数据集,这是一个公开的电子健康记录数据集,来自贝斯以色列女执事医学中心,包含了 2008 至 2019 年间的病人入院记录。
-
中层:最新的、经同行评审的可信医学书籍和论文。我们使用了 MedC-K 语料库,包含 480 万篇生物医学学术论文和 3 万本教科书。这些数据每年更新一次。
-
底层:定义医学术语及其语义关系的数据,主要来自权威词汇。我们使用了 UMLS(统一医学语言系统)数据集,这是一个由美国国家医学图书馆开发的综合医学词汇系统。这些数据大约每五年更新一次。
测试数据包括 PubMedQA、MedMCQA 和 USMLE 等医学问答数据集。
3.2 LLM 模型
我们使用了多个 LLM 模型进行实验,包括 LLAMA2、LLAMA3、GPT-4 和 Gemini。
3.3 结果
3.3.1 医疗图 RAG 效果
实验结果显示,我们的 MedGraphRAG 显著提升了各种 LLM 在医学基准测试上的表现。特别是对于较小的模型,如 LLaMA2-13B 和 LLaMA3-8B,改进更为显著。
对于更强大的封闭源模型如 GPT-4 和 LLaMA3-70B,MedGraphRAG 帮助它们在多个基准测试上达到了最先进的结果,甚至超过了人类专家的准确性。
3.3.2 基于证据的响应
MedGraphRAG 能够生成基于证据的回答,增强了安全性和可解释性。与单独使用 GPT-4 相比,MedGraphRAG 增强的响应不仅能准确识别疾病(如血管性痴呆),还提供了详细的解释和可验证的引用。
3.3.3 与最先进医学 LLM 模型的比较
在 MedQA 基准测试中,MedGraphRAG 应用于 GPT-4 后,其性能超过了之前最先进的提示模型 Medprompt,并优于所有经过密集微调的模型。
3.3.4 消融研究
我们进行了全面的消融研究,验证了各个模块的有效性。结果表明:
- 我们的混合静态-语义文档分块方法显著提高了性能。
- 层级图构建技术带来了最显著的改进。
- U-retrieve 方法进一步提升了检索的准确性和相关性。
总的来说,这些实验结果证明了 MedGraphRAG 在提升 LLM 医学问答能力方面的有效性,特别是在生成基于证据的可靠回答方面表现出色。
4. 结论
本文介绍了 MedGraphRAG,这是一个专为医疗领域设计的创新图基检索增强生成(RAG)框架,旨在提升大型语言模型(LLMs)的能力。
我们的方法结合了先进的文档分块技术和层级图结构,显著改善了数据组织和检索准确性。
我们的消融研究证实,该方法在医学问答基准测试中优于现有最先进的模型,并能提供可靠的、具有源引用的回答,这对医学应用至关重要。
未来,我们计划扩展这个框架以包含更多样化的数据集,并探索其在实时临床环境中的潜在应用。
总的来说,MedGraphRAG 在提高 LLM 处理医学信息的能力方面取得了显著进展,为医疗 AI 的发展开辟了新的方向。
它不仅提高了模型的准确性,还增强了结果的可解释性和可信度,这对于医疗领域的应用尤为重要。
随着技术的进一步发展和优化,MedGraphRAG 有望在临床决策支持、医学教育和研究等领域发挥更大的作用,为医疗保健的未来带来积极影响。
部署指南
一、使用miniconda搭建python环境
命令:conda create -n mgrag python=3.10.9
二、为环境安装相应库
1.首先激活mgrag环境
命令:conda activate mgrag
2.在mgrag环境下安装相应python库,安装库的列表在medgraphrag.txt文件里面
命令:pip install -r medgraphrag.txt
三、修改openai的密钥与请求地址
命令:export OPENAI_API_KEY = sk-tjv09TG6HsYGaIc634304c345a3244899cFfF45c81649aBf
命令:export OPENAI_BASE_URL="https://api.gpts.vin/v1
四、安装nano_graphrag库
修改setup.py 代码:
import setuptools
long_description = """
# Nano GraphRAG
A simple, easy-to-hack GraphRAG implementation.
More details about the project can be added here.
"""
vars2find = ["__author__", "__version__", "__url__"]
vars2readme = {}
with open("./nano_graphrag/__init__.py") as f:
for line in f.readlines():
for v in vars2find:
if line.startswith(v):
line = line.replace(" ", "").replace('"', "").replace("'", "").strip()
vars2readme[v] = line.split("=")[1]
deps = []
with open("/root/autodl-tmp/Medical-Graph-RAG/medgraphrag.txt") as f:
for line in f.readlines():
if not line.strip():
continue
deps.append(line.strip())
setuptools.setup(
name="nano-graphrag",
url=vars2readme["__url__"],
version=vars2readme["__version__"],
author=vars2readme["__author__"],
description="A simple, easy-to-hack GraphRAG implementation",
long_description=long_description,
long_description_content_type="text/markdown",
packages=["nano_graphrag"],
classifiers=[
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
],
python_requires=">=3.9",
install_requires=deps,
)
运行
cd nano-graphrag/
python setup.py sdist bdist_wheel
pip install dist/nano_graphrag-0.0.3-py3-none-any.whl
五、修改openai参数,如果步骤三openai环境变量配置不生效,搜索所有OpenAI的初始化,需要 修改api_key和base_url,比如:
miniconda3/envs/mg/lib/python3.10/site-packages/nano_graphrag/_llm.py
openai_async_client = AsyncOpenAI()改为
openai_async_client = AsyncOpenAI(api_key="sk-YNyRb2e5kDUK7b1lgACbQQcbujhM8wUB2ypT1woEvO6aqd5h",base_url="https://api.gpts.vin/v1")
六 修改/root/autodl-tmp/Medical-Graph-RAG/data_chunk.py 代码,可以减少token消耗
llm = ChatOpenAI(model='gpt-4-1106-preview', openai_api_key = os.getenv("OPENAI_API_KEY"))
为
llm = ChatOpenAI(model='gpt-4o-mini', openai_api_key = "sk-")
七、安装neo4j
安装jdk11
sudo apt install openjdk-11-jdk
sudo update-alternatives --config java
选择jdk 11版本
安装neo4j
echo "deb https://debian.neo4j.com stable 4.3" | sudo tee /etc/apt/sources.list.d/neo4j.list
apt update
apt list -a neo4j
apt install neo4j=1:4.3.24
sudo apt install cypher-shell=1:4.3.24
下载apoc插件
https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/download/4.3.0.4/apoc-4.3.0.4-core.jar
放到目录
/var/lib/neo4j/plugins/下
修改配置文件
vi /etc/neo4j/neo4j.conf
增加下面配置
dbms.security.procedures.unrestricted=apoc.*
dbms.security.procedures.allowlist=apoc.*
dbms.security.procedures.whitelist=apoc.meta.data
启动neo4j
neo4j start
查看是否正常启动 neo4j status
出现Neo4j is running at pid 35138 说明启动正常
八、下载测试集
https://huggingface.co/datasets/Morson/mimic_ex/tree/main
上传后unzip dataset.zip 解压
九、修改run.py 测试
import os
from getpass import getpass
from camel.storages import Neo4jGraph
from camel.agents import KnowledgeGraphAgent
from camel.loaders import UnstructuredIO
from dataloader import load_high
import argparse
from data_chunk import run_chunk
from creat_graph import creat_metagraph
from summerize import process_chunks
from retrieve import seq_ret
from utils import *
from nano_graphrag import GraphRAG, QueryParam
# %% set up parser
parser = argparse.ArgumentParser()
parser.add_argument('-simple', action='store_true')
parser.add_argument('-construct_graph', action='store_true')
parser.add_argument('-inference', action='store_true')
parser.add_argument('-grained_chunk', action='store_true')
parser.add_argument('-trinity', action='store_true')
parser.add_argument('-trinity_gid1', type=str)
parser.add_argument('-trinity_gid2', type=str)
parser.add_argument('-ingraphmerge', action='store_true')
parser.add_argument('-crossgraphmerge', action='store_true')
parser.add_argument('-dataset', type=str, default='mimic_ex')
parser.add_argument('-data_path', type=str, default='./dataset_test')
parser.add_argument('-test_data_path', type=str, default='./dataset_ex/report_0.txt')
args = parser.parse_args()
if args.simple:
graph_func = GraphRAG(working_dir="./nanotest")
with open("./dataset/mimic_ex/report_0.txt") as f:
graph_func.insert(f.read())
# Perform local graphrag search (I think is better and more scalable one)
print(graph_func.query("What is the main symptom of the patient?", param=QueryParam(mode="local")))
else:
# url=os.getenv("NEO4J_URL")
# username=os.getenv("NEO4J_USERNAME")
# password=os.getenv("NEO4J_PASSWORD")
url="bolt://localhost:7687"
username="neo4j"
password="neo4j123456"
# Set Neo4j instance
n4j = Neo4jGraph(
url=url,
username=username, # Default username
password=password # Replace 'yourpassword' with your actual password
)
if args.construct_graph:
if args.dataset == 'mimic_ex':
files = [file for file in os.listdir(args.data_path) if os.path.isfile(os.path.join(args.data_path, file))]
# Read and print the contents of each file
for file_name in files:
file_path = os.path.join(args.data_path, file_name)
content = load_high(file_path)
gid = str_uuid()
n4j = creat_metagraph(args, content, gid, n4j)
if args.trinity:
link_context(n4j, args.trinity_gid1)
if args.crossgraphmerge:
merge_similar_nodes(n4j, None)
if args.inference:
question = load_high("./prompt.txt")
sum = process_chunks(question)
gid = seq_ret(n4j, sum)
response = get_response(n4j, gid, question)
print(response)
十、测试
python run.py -simple
python run.py -dataset mimic_ex -data_path ./dataset_ex -grained_chunk -ingraphmerge -construct_graph -trinity
下包:
absl-py==2.1.0
accelerate==0.33.0
agentops==0.3.7
aiofiles==23.2.1
aiohttp==3.9.3
aiosignal==1.3.1
anthropic==0.29.2
antlr4-python3-runtime==4.9.3
anyio==4.3.0
anytree==2.12.1
appdirs==1.4.4
appnope==0.1.3
asgiref==3.8.1
asttokens==2.2.1
async-timeout==4.0.3
attrs==23.1.0
autograd==1.6.2
av==12.3.0
backcall==0.2.0
backoff==2.2.1
backports-tarfile==1.2.0
bcrypt==4.1.2
beartype==0.18.5
beautifulsoup4==4.12.2
bleach==6.0.0
build==1.2.1
cachetools==5.3.3
cffi==1.17.0
chardet==5.2.0
charset-normalizer==3.3.2
chroma-hnswlib==0.7.3
chromadb==0.4.24
click==8.1.7
cloudpickle==2.2.1
cohere==4.57
colorama==0.4.6
coloredlogs==15.0.1
contourpy==1.1.0
cryptography==43.0.0
cssselect==1.2.0
curl-cffi==0.6.2
cycler==0.11.0
cython==3.0.1
dataclasses-json==0.6.4
datasets==2.19.1
defusedxml==0.7.1
deprecated==1.2.14
diffusers==0.30.0
dill==0.3.8
discord-py==2.4.0
distro==1.9.0
docker==7.1.0
docker-pycreds==0.4.0
docstring-parser==0.15
docx2txt==0.8
duckduckgo-search==6.2.6
effdet==0.4.1
einops==0.6.1
emoji==2.12.1
environs==9.5.0
et-xmlfile==1.1.0
eval-type-backport==0.2.0
executing==1.2.0
farama-notifications==0.0.4
fastapi==0.110.1
fastavro==1.9.5
fastjsonschema==2.18.0
feedfinder2==0.0.4
feedparser==6.0.11
filelock==3.12.2
filetype==1.2.0
fire==0.6.0
firecrawl-py==0.0.20
flatbuffers==24.3.25
fonttools==4.40.0
frozenlist==1.4.1
fsspec==2024.3.1
future==1.0.0
gensim==4.3.3
geojson==2.5.0
gitdb==4.0.11
gitignore-parser==0.1.11
gitpython==3.1.43
google-ai-generativelanguage==0.6.4
google-api-core==2.19.1
google-api-python-client==2.140.0
google-auth==2.29.0
google-auth-httplib2==0.2.0
google-auth-oauthlib==1.2.0
google-generativeai==0.6.0
googleapis-common-protos==1.63.0
googlemaps==4.10.0
graspologic==3.4.1
graspologic-native==1.2.1
groq==0.5.0
grpcio==1.63.0
grpcio-status==1.62.3
grpcio-tools==1.62.3
gym==0.26.2
gym-notices==0.0.8
gymnasium==0.28.1
h11==0.14.0
h2==4.1.0
hnswlib==0.7.0
hpack==4.0.0
httpcore==1.0.5
httplib2==0.22.0
httptools==0.6.1
httpx==0.27.0
huggingface-hub==0.24.5
humanfriendly==10.0
hyperframe==6.0.1
hyppo==0.4.0
idna==3.7
ijson==3.3.0
imageio==2.34.2
imap-tools==1.6.0
importlib-metadata==6.11.0
importlib-resources==6.4.0
iopath==0.1.10
ipython==8.14.0
jaraco-context==5.3.0
jax==0.4.19
jax-jumpy==1.0.0
jaxlib==0.4.19
jedi==0.18.2
jieba3k==0.35.1
jinja2==3.1.2
jiter==0.5.0
joblib==1.4.2
jsonpatch==1.33
jsonpointer==2.4
jsonschema==4.21.1
jsonschema-path==0.3.3
jsonschema-specifications==2023.7.1
jupyter-client==8.6.2
jupyter-core==5.3.1
jupyterlab-pygments==0.2.2
kiwisolver==1.4.4
kubernetes==29.0.0
langchain==0.1.14
langchain-community==0.0.31
langchain-core==0.1.40
langchain-text-splitters==0.0.1
langchainhub==0.1.21
langdetect==1.0.9
langsmith==0.1.40
layoutparser==0.3.4
lazy-loader==0.2
lazy-object-proxy==1.10.0
litellm==1.41.1
llvmlite==0.43.0
loguru==0.7.2
lxml==5.2.2
markdown==3.6
markdown-it-py==3.0.0
markupsafe==2.1.3
marshmallow==3.21.1
matplotlib==3.9.2
mdurl==0.1.2
mediapy==1.0.3
milvus-lite==2.4.8
mistral-common==1.3.3
mistralai==0.4.2
mistune==3.0.1
ml-dtypes==0.2.0
mmh3==4.1.0
monotonic==1.6
more-itertools==10.4.0
mpmath==1.3.0
msg-parser==1.2.0
multidict==6.0.5
multiprocess==0.70.16
mypy-extensions==1.0.0
nbclient==0.8.0
nbconvert==7.7.4
nbformat==5.9.2
neo4j==5.23.1
networkx==3.1
newspaper3k==0.2.8
nltk==3.8.1
numba==0.60.0
numpy==1.26.4
oauthlib==3.2.2
olefile==0.47
omegaconf==2.3.0
onnx==1.16.2
onnxruntime==1.15.1
openai==1.40.2
openapi-schema-validator==0.6.2
openapi-spec-validator==0.7.1
opencv-python==4.7.0.72
openpyxl==3.1.5
opentelemetry-api==1.24.0
opentelemetry-exporter-otlp-proto-common==1.24.0
opentelemetry-exporter-otlp-proto-grpc==1.24.0
opentelemetry-instrumentation==0.45b0
opentelemetry-instrumentation-asgi==0.45b0
opentelemetry-instrumentation-fastapi==0.45b0
opentelemetry-proto==1.24.0
opentelemetry-sdk==1.24.0
opentelemetry-semantic-conventions==0.45b0
opentelemetry-util-http==0.45b0
opt-einsum==3.3.0
orjson==3.10.0
overrides==7.7.0
packaging==23.2
pandas==2.0.2
pandocfilters==1.5.0
parso==0.8.3
pathable==0.4.3
pathlib==1.0.1
pathtools==0.1.2
patsy==0.5.6
pdf2image==1.17.0
pdfminer-six==20231228
pdfplumber==0.11.3
pexpect==4.8.0
pillow==10.4.0
platformdirs==3.10.0
portalocker==2.10.1
posthog==3.5.0
pot==0.9.4
prance==23.6.21.0
primp==0.5.5
prompt-toolkit==3.0.38
proto-plus==1.24.0
protobuf==4.23.4
pulsar-client==3.4.0
pyarrow==17.0.0
pyarrow-hotfix==0.6
pyasn1==0.6.0
pyasn1-modules==0.4.0
pyboy==1.6.9
pycocotools==2.0.8
pycparser==2.22
pydantic==2.6.1
pydantic-core==2.16.2
pydub==0.25.1
pygithub==2.3.0
pygments==2.15.1
pyjwt==2.9.0
pymilvus==2.4.5
pymupdf==1.24.9
pymupdfb==1.24.9
pynacl==1.5.0
pynndescent==0.5.13
pyowm==3.3.0
pypandoc==1.13
pyparsing==3.1.0
pypdfium2==4.30.0
pypika==0.48.9
pyproject-hooks==1.0.0
pysdl2==0.9.15
pysdl2-dll==2.28.0
pysocks==1.7.1
pytelegrambotapi==4.22.0
pytesseract==0.3.10
python-dateutil==2.8.2
python-docx==1.1.2
python-dotenv==1.0.1
python-iso639==2024.4.27
python-magic==0.4.27
python-multipart==0.0.9
python-pptx==0.6.23
pytz==2023.3
pywavelets==1.4.1
pyyaml==6.0.1
pyzmq==25.1.1
qdrant-client==1.10.1
rank-bm25==0.2.2
rapidfuzz==3.9.6
redis==5.0.8
referencing==0.30.2
regex==2023.12.25
requests==2.31.0
requests-file==2.1.0
requests-oauthlib==1.3.1
rfc3339-validator==0.1.4
rich==13.7.1
rpds-py==0.9.2
rsa==4.9
ruamel-yaml==0.18.6
ruamel-yaml-clib==0.2.8
safetensors==0.4.4
scikit-image==0.21.0
scikit-learn==1.5.1
scipy==1.12.0
seaborn==0.13.2
sentence-transformers==3.0.1
sentencepiece==0.2.0
sentry-sdk==1.45.0
setproctitle==1.3.3
setuptools==72.1.0
sgmllib3k==1.0.0
shellingham==1.5.4
shimmy==1.1.0
slack-sdk==3.31.0
smart-open==7.0.4
smmap==5.0.1
sniffio==1.3.1
soundfile==0.12.1
soupsieve==2.4.1
sqlalchemy==2.0.29
stable-baselines3==2.0.0
starlette==0.37.2
statsmodels==0.14.2
sympy==1.12
tabulate==0.9.0
tenacity==8.2.3
tensorboard==2.15.0
tensorboard-data-server==0.7.2
termcolor==2.4.0
threadpoolctl==3.1.0
tifffile==2023.4.12
tiktoken==0.7.0
timm==1.0.8
tinycss2==1.2.1
tinysegmenter==0.3
tldextract==5.1.2
tokenizers==0.19.1
tomli==2.0.1
torch==2.4.0
torchvision==0.19.0
tornado==6.3.3
tqdm==4.66.2
traitlets==5.9.0
transformers==4.44.0
typer==0.12.0
typer-cli==0.12.0
typer-slim==0.12.0
types-requests==2.32.0.20240712
typing-extensions==4.11.0
typing-inspect==0.9.0
tzdata==2023.3
ujson==5.10.0
umap-learn==0.5.6
unstructured==0.10.30
unstructured-inference==0.7.11
unstructured-pytesseract==0.3.12
uritemplate==4.1.1
urllib3==2.2.1
uvicorn==0.29.0
uvloop==0.19.0
wandb==0.15.12
watchfiles==0.21.0
wcwidth==0.2.6
webencodings==0.5.1
websocket-client==1.7.0
websockets==12.0
werkzeug==3.0.2
wikipedia==1.4.0
wolframalpha==5.1.3
wrapt==1.16.0
xlrd==2.0.1
xlsxwriter==3.2.0
xmltodict==0.13.0
xxhash==3.4.1
yarl==1.9.4
zipp==3.18.1
模型:gpt-4-1106-preview(只能选这个,或者以上版本)
我试了 gpt4o,居然会报错(4o生成失败):
WHERE (((((not ((`n`):`Summary`)) AND (not ((`m`):`Summary`))) AND (((`n`).`gid`) = ((`m`).`gid`))) AND (((`n`).`gid`) = ($`gid`))) AND ((`n`) <> (`m`))) AND ((`apoc`.`coll`.`sort`((`labels`((`n`))))) = (`apoc`.`coll`.`sort`((`labels`((`m`))))))"
我人麻了,这个算法特别费 token,又只能选这种高级模型,像开源大模型 Qwen 2.5 也会报错。
后面 11 月份代码又有更新,更新版本我还没试过。

















 2815
2815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









