







XAI4LLM:结合ML和LLM的医疗诊断框架,通过不同的交互方式(NC/NL-ST)实现信息的有效传递
论文大纲
├── 1 研究背景与动机【研究框架】
│ ├── LLMs在医疗决策中的应用前景【背景介绍】
│ │ ├── 通用型LLMs的能力【技术特点】
│ │ └── 医疗诊断的特殊需求【应用场景】
│ └── 研究挑战【问题陈述】
│ ├── 领域知识整合【核心挑战】
│ ├── 数值数据处理【技术挑战】
│ ├── 通信风格优化【交互挑战】
│ └── 风险评估【安全挑战】
│
├── 2 技术方案【解决方案】
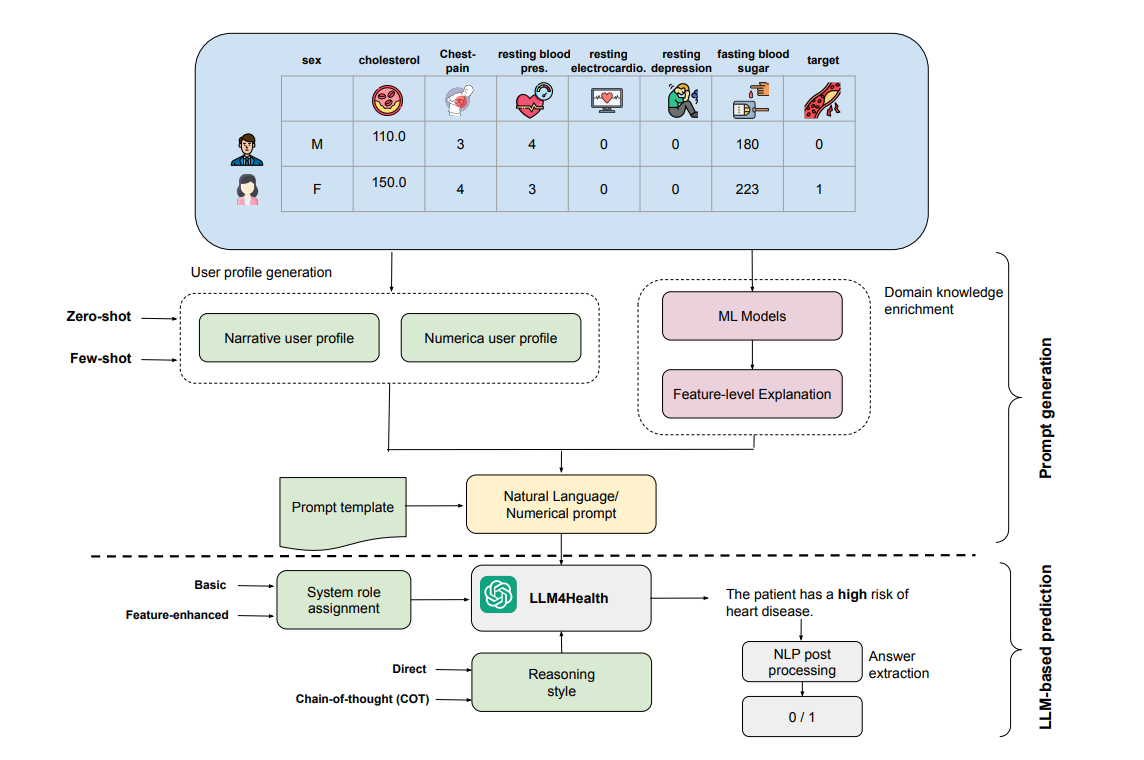
│ ├── 提示词构建层【方法设计】
│ │ ├── 用户画像生成【数据处理】
│ │ ├── 领域知识强化【知识注入】
│ │ └── 多层提示模板【结构化设计】
│ └── LLM交互与预测层【系统实现】
│ ├── 数值型对话【交互模式】
│ └── 自然语言单轮【交互模式】
│
├── 3 系统评估【实验验证】
│ ├── 零样本学习性能【基础评估】
│ ├── 小样本学习效果【进阶评估】
│ └── 性别偏见分析【公平性评估】
│
└── 4 研究发现【结论总结】
├── 通信风格影响【方法发现】
├── 推理方式作用【技术发现】
└── 偏见缓解策略【应用发现】
理解
- 提出背景和问题:
- 背景:当前医疗诊断领域需要将大模型(LLMs)与传统机器学习模型结合, 以提高诊断准确性。
- 具体问题:如何通过结构化提示和领域知识增强, 使LLMs在零样本/少样本情境下实现更准确的医疗诊断。
- 概念性质:
- 这是一个融合了LLMs、机器学习和医疗诊断的系统框架XAI4LLM。
- 其核心性质是通过分层结构化提示和两种交互模式 (数值对话式NC和自然语言单轮式NL-St) 来优化LLMs的诊断能力。
- 正反例对比:
- 正例:当使用RF领域知识和NC交互模式时, 模型在F1分数上达到0.741, F3分数达到0.921, 显示出良好的诊断性能。
- 反例:当使用NL-St模式且不加入领域知识时, 模型表现相对较差, F1分数仅为0.660。
让我用思维推理框架来分析XAI4LLM论文中的关键问题。
1. 排除推理:为什么选择LLM而不是传统ML方法?
可能的选择:
- 纯ML方法
- 纯LLM方法
- ML+LLM混合方法
逐一分析:
-
纯ML方法:
- 优势:准确率高(F1=0.914)
- 缺点:需要大量训练数据,缺乏灵活性
- 排除原因:无法适应新场景和少数据情况
-
纯LLM方法:
- 优势:灵活性强,少样本学习能力好
- 缺点:缺乏专业领域知识
- 排除原因:性能不如ML模型
-
ML+LLM混合方法(XAI4LLM):
- 结合两者优势
- 通过XAI注入领域知识
- 保留了少样本学习能力
结论:ML+LLM混合方法是最优选择。
2. 比较推理:NC vs NL-ST交互模式

核心问题:哪种交互模式更适合医疗诊断?
特征比较:
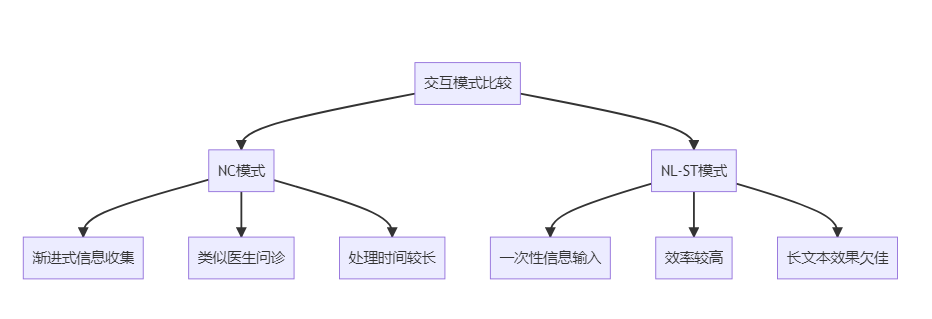
启示:
- NC模式更适合复杂诊断
- NL-ST模式适合快速筛查
- 应根据具体场景选择
3. 因果推理:领域知识如何影响模型性能
已知条件:
- LLM具有通用知识
- ML模型具有专业知识
- XAI可以提取特征重要性
因果链分析:
-
领域知识注入:
ML模型知识 --XAI提取--> 特征重要性 --提示词整合--> LLM理解 -
性能提升机制:
专业知识增强 --> 判断依据明确 --> 准确率提升
结论:领域知识通过结构化提示词提升了模型性能。
作者解决思路
目标: 如何设计算法框架让 LLMs 和 ML 模型协作完成医疗决策?
核心算法问题拆解:
-
如何构建高效的提示词工程框架?
- 如何设计多层模板结构?
- 如何自动化生成任务相关的提示词?
- 如何在提示词中嵌入ML模型的知识?
-
如何实现ML到LLM的知识迁移?
- 如何从ML模型中提取特征重要性?
- 如何将特征重要性量化为分位数?
- 如何将量化的重要性转化为自然语言描述?
-
如何优化两种交互模式的算法实现?
- 如何实现增量式的数值对话(NC)?
- 如何构建单轮叙述(NL-ST)的模板?
- 如何处理两种模式的上下文维护?
-
如何设计后处理算法提升可靠性?
- 如何设计关键词匹配算法?
- 如何实现情感分析过滤?
- 如何将长文本映射为二元决策?
-
如何设计性能评估和优化算法?
- 如何计算风险敏感的评估指标?
- 如何度量和优化性别偏差?
- 如何权衡和优化不同指标?
这种算法层面的拆解:
- 更关注具体的技术实现
- 问题之间有明确的依赖关系
- 每个问题都对应具体的算法组件
- 便于模块化实现和优化
主要算法创新点:
- 多层结构化提示词框架
- ML-LLM知识迁移机制
- 双模式交互算法
- 可靠性后处理流程
- 多维度评估体系
全流程
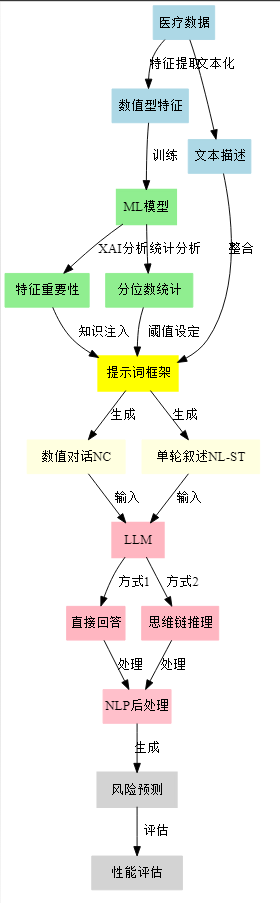
2. 全流程优化分析:
多题一解:
- 共用特征:医疗数据的结构化+非结构化特性
- 共用解法:ML-LLM混合决策框架
- 适用场景:需要同时处理数值和文本的医疗决策问题
一题多解:
-
纯ML方法:
- 特征:结构化数据为主
- 优势:高准确性
- 劣势:缺乏解释性
-
纯LLM方法:
- 特征:非结构化文本为主
- 优势:灵活性强
- 劣势:准确性不稳定
-
混合方法(本文):
- 特征:结构化+非结构化数据
- 优势:兼具准确性和灵活性
- 特点:可解释性强
-
输入输出分析:
输入:
- 患者医疗数据(数值型):
- 年龄、性别、心绞痛类型
- 血压、胆固醇等指标
- ML模型知识:
- 特征重要性
- 分位数统计
输出:
- 心脏病风险预测(0/1)
- 预测置信度
- 决策理由说明
全流程:
- 数据预处理
- ML模型特征分析
- 提示词构建
- LLM交互决策
- 后处理和结果输出
- 性能评估
创新点:
7. 提出多层结构化提示词框架
8. 设计ML到LLM的知识迁移机制
9. 实现两种互补的交互模式
10. 建立完整的评估体系
完全拆解
## 一、升维分析(空雨伞模型)
### 空:观察现象层
现状表现:
1. LLMs在医疗决策中表现:
- 零样本/少样本场景准确率低
- 决策缺乏专业依据
- 存在性别偏见和高假阴性率
数据证据:
1. 定量指标:
- 920条患者记录测试
- ML模型F1分数0.914 vs LLM基础F1分数0.687
- 性别组间性能差距最高达0.418
2. 定性问题:
- 缺乏专业医疗知识
- 决策过程不透明
- 风险控制不足
### 雨:分析原因层
直接原因:
1. 模型能力差距
- LLMs缺乏专门医疗训练
- 无法直接处理结构化医疗数据
- 推理过程不稳定
2. 知识获取瓶颈
- 难以获取专业医疗知识
- 无法有效整合ML模型知识
- 样本学习效率低
深层原因:
1. 架构限制
- 预训练模型通用性与专业性矛盾
- 文本到决策的映射不直接
- 交互模式不够优化
2. 方法论缺陷
- 缺乏系统的知识迁移机制
- 提示词工程不够完善
- 评估体系不够全面
### 伞:解决方案层
核心方案:
1. 技术创新
- 设计多层结构化提示词模板
- 建立ML-LLM知识迁移机制
- 实现双模式交互系统
2. 实施步骤
- 框架搭建:XAI4LLM系统开发
- 知识注入:ML模型特征提取和转化
- 交互优化:NC和NL-ST双模式设计
- 评估完善:多维度评估体系构建
## 二、降维拆解
### 1. 第一性原理(马斯克)
基本要素:
1. 数据理解
- 结构化医疗数据
- 非结构化文本描述
2. 知识表示
- ML模型特征重要性
- LLM语言理解能力
3. 推理决策
- 基于规则的ML推理
- 基于语言的LLM推理
### 2. 麦肯锡五法
#### 公式法
医疗决策性能 = f(专业知识 × 交互效果 × 推理能力 ÷ 风险因素)
#### 要素法
核心要素:
- 数据处理能力
- 知识整合机制
- 交互模式设计
- 推理决策机制
- 风险控制体系
#### 流程法
1. 数据输入层
2. 知识提取层
3. 提示词构建层
4. 交互推理层
5. 决策输出层
6. 评估反馈层
#### 二分法
对立维度:
- ML vs LLM
- 结构化 vs 非结构化
- NC vs NL-ST
- 直接答案 vs 思维链
#### 矩阵法
准确性 效率 可解释性 风险控制
ML模型 高 高 低 中
LLM基础 低 中 高 低
NC模式 中 低 中 高
NL-ST模式 中 高 高 中
## 三、系统梳理
### 1. 本质问题
如何实现ML模型专业性和LLM灵活性的最优结合,构建安全可靠的医疗决策支持系统?
### 2. 解决步骤
1. 知识提取与转化
2. 提示词模板设计
3. 交互模式优化
4. 推理机制改进
5. 风险控制加强
### 3. 改进方向
1. 技术层面:
- 自适应提示词生成
- 动态交互模式
- 多模型协同决策
2. 应用层面:
- 场景扩展
- 个性化优化
- 临床实践验证
数据分析
- 数据收集:
- 使用了来自美国、瑞士和匈牙利多家医疗机构的心脏病数据集
- 数据集包含920个病人记录,其中621个样本最初有缺失数据
- 使用KNN技术填补后,创建了完整的无缺失值数据集
- 人群分布: 78%男性, 21%女性
- 心脏病患病率: 男性63%, 女性28%
- 规律发现:
- 发现LLM模型的表现显著依赖于:
- 交流方式(数值对话式 vs 自然语言单轮式)
- 推理方法(直接式 vs 思维链式)
- 提供的少样本示例数量
- 发现数值对话式随示例增加而改善
- 发现思维链式推理有助于在示例增加时保持质量
- 相关性分析:
- 发现了领域知识整合与模型表现之间的关系
- 识别出交流方式与准确度的相关性:
- 数值对话式对示例数量不太敏感
- 自然语言单轮式随提示长度增加而下降
- 发现推理方式与性别偏差的联系:思维链式叙述有助于减少偏差
- 模型建立:
- 创建了系统化的结构化提示构建框架
- 开发了多层次模板, 结合:
- 数值和自然语言用户画像
- 特定领域医学知识
- 不同交流方式
- 建立了评估框架, 同时测量准确度(F1分数)和风险敏感度(F3分数)
- 建立了公平性指标来评估性别偏差
研究者有效地通过了数据驱动推理的所有四个步骤, 开发和验证了他们的XAI4LLM医疗决策框架。
解法拆解
- 逻辑关系拆解:
目的:
- 研究大语言模型(LLMs)在医疗决策中的应用, 特别是心脏病风险预测
主要问题:
- 如何提高LLMs在医疗诊断中的准确性
- 如何整合领域专业知识
- 如何处理数值数据与自然语言之间的差异
- 如何优化与LLMs的交互方式
解决方案拆解:
- 结构化提示构建 (因为需要整合医学专业知识)
- 用户档案生成 (numerical和natural language两种形式)
- 领域知识整合 (使用ML模型的特征级解释)
- few-shot示例整合
- 多层结构化模板设计
- 交互方式优化(因为需要有效的信息传递)
- 数值对话式(NC)模式:逐步收集信息
- 自然语言单轮(NL-ST)模式:整体叙述
- 直接推理 vs 链式思维(COT)推理
- 后处理优化 (因为需要将LLM输出转化为二元决策)
- 关键词识别
- 情感分析
- 二元决策提取
- 决策树形式的逻辑链:
医疗决策优化
├── 数据输入处理
│ ├── 数值型处理
│ └── 自然语言处理
├── 模型交互设计
│ ├── 交互模式选择
│ │ ├── NC模式
│ │ └── NL-ST模式
│ └── 推理方式选择
│ ├── 直接推理
│ └── COT推理
└── 输出处理
├── 文本分析
└── 决策提取
假设场景: 评估一位64岁女性患者的心脏病风险
- 数据输入示例:
原始数据:
- 年龄: 64岁
- 性别: 女
- 胸痛类型: 非典型性心绞痛
- 血压: 135 mmHg
- 胆固醇: 220 mg/dl
- 空腹血糖: 130 mg/dl
- 解决方案实施过程:
A) 结构化提示构建:
数值对话式(NC)版本:
<User> 年龄: 64岁
<User> 性别: 女性
<User> 胸痛类型: 非典型性心绞痛
<User> 血压: 135 mmHg
<User> 胆固醇: 220 mg/dl
<User> 空腹血糖: 130 mg/dl
自然语言单轮(NL-ST)版本:
这位患者是一位64岁的女性,出现非典型性心绞痛症状。其静息血压为135 mmHg,血清胆固醇水平为220 mg/dl,空腹血糖为130 mg/dl。
B) 领域知识整合:
特征重要性分析:
- 关键因素: 胸痛类型、胆固醇、心电图ST段
- 次要因素: 血压、血糖
C) 模型输出示例:
直接推理:
基于患者的临床指标,特别是非典型性心绞痛和血压水平,评估结果为存在心脏病风险(1)。
链式思维(COT):
让我逐步分析:
1. 患者年龄(64岁)属于高风险年龄段
2. 出现非典型性心绞痛是重要警示信号
3. 血压(135mmHg)轻度升高
4. 胆固醇(220mg/dl)处于边界水平
5. 空腹血糖(130mg/dl)偏高
综合以上因素,特别是年龄和症状特征,判断存在心脏病风险(1)。
这个例子展示了:
- 如何将原始数据转换为不同形式的提示
- 如何整合医学领域知识
- 不同推理方式的差异
- 如何得到最终的风险评估结果
通过这个例子可以看出系统的工作流程:数据收集 → 提示构建 → 知识整合 → 模型推理 → 结果输出
为什么作者选择使用LLMs而不是传统机器学习方法来进行医疗诊断?
- LLMs具有广泛的泛化能力,可以从大规模数据中学习并理解复杂的医疗信息
- LLMs可以直接进行prediction→label的处理,不需要像传统ML那样需要大量专门的训练数据
- LLMs能够整合医疗领域知识,并通过自然语言交互提供更具解释性的诊断结果
- LLMs具有零样本/少样本学习能力,在数据有限的新兴医疗问题上也能发挥作用
文中提到的两种交互方式(NC和NL-ST),你认为各自的优势和局限性是什么?
NC(数值对话式)和NL-ST(自然语言单轮)两种交互方式的优劣:
优势:
- NC style: 可以渐进式收集信息,模仿医生问诊过程,对较长对话更稳定
- NL-ST style: 可以一次性提供完整病例信息,在少量样本时准确率较高
局限性:
- NC style: 需要更多交互轮次,处理时间较长
- NL-ST style: 在prompt长度增加时性能下降明显,对大量信息的整合能力有限
如何看待AI在医疗诊断中可能产生的假阴性问题?
文章特别强调了假阴性的严重性,因为在医疗诊断中漏诊比误诊的后果更严重。
作者通过使用F3分数(更注重召回率)来评估模型性能,并发现LLMs在整合领域知识后可以在一定程度上降低假阴性风险。
为什么要在提示中加入领域知识?这种方式是否真的有效?
加入领域知识的必要性和效果:
- 必要性:因为LLMs是通用模型,需要专门的医疗领域知识来提升在特定任务上的表现
- 效果:研究表明,通过feature-level explanation方式整合ML模型提供的领域知识确实能提升LLMs的诊断准确性
- 实验数据显示,加入领域知识的模型在F1和F3评分上都有显著提升,特别是在少样本学习场景下
整体而言,领域知识的引入是有效的,它帮助LLMs在医疗诊断这样的专业领域中取得了更好的表现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









