









KARE:基于知识图谱社区检索的推理增强医疗预测框架:在住院死亡率和再入院预测中提升10-15%
- 论文大纲
- 理解
- 结构分析
- 观察假设
- 数据分析
- 解法拆解
- 全流程
- 核心模式
- 提问
- 为什么作者认为传统的检索增强生成方法在医疗预测中不够充分?
- KARE框架中,为什么要从三个不同来源构建知识图谱?
- 在处理复杂医疗预测时,知识图谱社区检索与传统单文档检索有什么本质区别?
- 作者为什么选择多任务学习框架而不是单一的预测任务?
- 推理链生成对医疗预测的价值究竟在哪里?
- 如何看待KARE在处理不平衡数据集时的表现?
- 为什么要在知识图谱构建时进行语义聚类?这个步骤的深层意义是什么?
- 在动态知识检索中,不同权重参数的设置依据是什么?
- KARE框架是否真的提高了医疗预测的可解释性?如何衡量?
- 该框架在实际医疗场景中可能面临哪些挑战?
- 论文中提到"knowledge graph community retrieval优于naive RAG",能否提供一个具体的医疗案例,定量分析两种方法检索结果的差异?
- 论文使用了Claude 3.5 Sonnet作为专家LLM生成训练样本,如果换成其他大模型(如GPT-4),模型性能会有显著变化吗?这种依赖特定LLM的方法是否限制了框架的普适性?
- 在"Ablation Study of Knowledge Source"中,移除GLLM导致性能下降最大。这是否意味着传统医学知识库(如UMLS)的价值被低估了?如何确保从LLM获取的知识确实比专业医学数据库更可靠?
- 论文使用了复杂的相关性评分公式(Equation 3),包含多个超参数(α, β, λ1, λ2, λ3)。这些参数是如何调优的?不同数据集是否需要不同的参数设置?
- 在处理严重不平衡的数据集(如MIMIC-III mortality prediction中positive samples仅占5.42%)时,KARE如何确保没有过度拟合少数类别?
- 论文提出的多任务学习框架同时优化推理链生成和标签预测,如何保证这两个任务的学习目标不会相互干扰?是否考虑过这两个任务可能存在的冲突?
- 在生成community summaries时,如何确保不会丢失关键的医学信息?特别是在处理超大社区(size > Zc)时,简单放弃生成摘要是否合理?
- 论文主要在MIMIC数据集上进行验证,这些数据来自同一个医疗系统。KARE框架如何处理不同医疗系统之间的差异,特别是在医疗实践和记录方式存在显著差异的情况下?
- 在计算community相关性时,考虑了时效性(Recency)因素。但在真实医疗场景中,较旧的病例有时可能比近期病例更有参考价值。这种简单的时间衰减是否合理?
- 论文提到使用Mistral-7B-Instruct-v0.3作为本地LLM。考虑到医疗决策的高风险性,使用相对较小的模型(7B参数)是否足够可靠?如何权衡模型规模与推理效率?
论文:REASONING-ENHANCED HEALTHCARE PREDICTIONS WITH KNOWLEDGE GRAPH COMMUNITY RETRIEVAL
论文大纲
├── KARE框架【整体研究】
│ ├── 背景动机【研究起源】
│ │ ├── LLMs在临床决策支持中表现出潜力【现状】
│ │ ├── 存在幻觉和知识缺失问题【挑战】
│ │ └── 传统RAG方法效果不理想【问题】
│ │ ├── 检索信息稀疏【具体问题】
│ │ └── 检索信息相关性差【具体问题】
│ │
│ ├── 技术创新【主要贡献】
│ │ ├── 多源医疗知识结构化方法【创新点一】
│ │ │ ├── 生物医学数据库整合【数据来源】
│ │ │ ├── 临床文献分析【数据来源】
│ │ │ └── LLM生成的见解【数据来源】
│ │ │
│ │ ├── 动态知识检索机制【创新点二】
│ │ │ ├── 层次化图社区检测【技术手段】
│ │ │ └── 图社区摘要生成【技术手段】
│ │ │
│ │ └── 推理增强预测框架【创新点三】
│ │ ├── 患者上下文增强【具体实现】
│ │ └── 多任务学习优化【具体实现】
│ │
│ └── 实验验证【研究成果】
│ ├── MIMIC-III数据集评估【验证一】
│ │ ├── 死亡率预测提升10.8-15.0%【结果】
│ │ └── 再入院预测提升【结果】
│ │
│ └── MIMIC-IV数据集评估【验证二】
│ ├── 死亡率预测提升12.6%【结果】
│ └── 再入院预测提升12.7%【结果】
理解
- 背景和问题:
LLM在医疗高风险应用(如临床诊断)中的准确性问题。
虽然LLM在临床决策支持方面展现出巨大潜力,但仍存在幻觉和缺乏细粒度的医学知识等问题。
传统的检索增强生成(RAG)方法试图解决这些局限性,但经常检索到稀疏或不相关的信息,影响预测准确性。
- KARE的性质:
是一个结合知识图谱社区级检索与LLM推理的新型框架。
这种性质源于三个关键创新:
- 密集医学知识结构化方法
- 动态知识检索机制
- 基于推理的预测框架
- 正反例对比:
正例: 对于有心力衰竭的病人,KARE能够通过知识图谱检索相关并且精确的医学知识,结合LLM推理得出准确预测。
反例: 传统RAG方法可能会检索到与"心脏"相关,但对诊断无实际帮助的信息。
- 类比理解:
KARE就像一个经验丰富的医生团队:
- 知识图谱相当于医学文献库
- 社区检索相当于快速定位相关病例
- LLM推理相当于医生根据病历和知识做出判断
- 概念总结:
KARE通过构建多源知识图谱,使用层次化社区检测和总结来组织知识,实现精确检索。
它能够丰富患者上下文信息,并利用LLM生成推理链,从而提高预测的准确性和可解释性。
- 概念重组:
知识感知与推理增强(Knowledge Aware and Reasoning Enhanced),通过知识的感知来增强推理能力。
- 上下文关联:
作为对传统RAG方法的改进,KARE在MIMIC-III和MIMIC-IV数据集上的死亡率和再入院预测任务中,相比领先模型分别提高了10.8-15.0%和12.6-12.7%的性能。
- 核心矛盾:
主要矛盾:
- LLM在医疗领域的准确性与可信度之间的矛盾
次要矛盾:
- 知识检索的效率与相关性
- 推理过程的透明度与复杂性
- 功能分析:
核心功能是提高医疗预测的准确性和可解释性。具体实现包括:
- 构建并组织专业医学知识
- 精确检索相关信息
- 生成可理解的推理过程
- 输出可靠的预测结果
- 来龙去脉:
- 起因:LLM在医疗领域存在幻觉和知识缺失问题
- 发展:传统RAG方法尝试解决但效果不佳
- 转折:提出KARE框架整合知识图谱和LLM
- 结果:显著提升预测准确性和可解释性
1. 确认目标
提高 LLM 在医疗预测任务中的准确性和可信度,解决幻觉和专业知识缺失的问题。
2. 目标-手段分析
最终目标:如何让 LLM 在医疗预测中既准确又可信?
层层分解:
-
如何获取专业医学知识?
- 从多源(生物医学数据库、临床文献、LLM生成)构建知识图谱
- 使用语义聚类整合不同来源的实体和关系
- 通过层次化社区检测组织知识结构
-
如何确保检索到的知识相关且精确?
- 设计四个评分指标:节点命中率、一致性、时效性、主题相关性
- 使用动态图检索算法迭代选择最相关的社区摘要
- 通过衰减因子促进多样性检索
-
如何结合知识生成可靠推理?
- 使用专家 LLM 生成推理链训练样本
- 设计多任务学习框架同时优化推理和预测
- 对本地 LLM 进行微调以获得专业能力
3. 实现步骤
-
医学概念知识图谱构建和索引
- 概念特定知识图谱提取
- 语义聚类
- 层次化社区检测和索引
-
患者上下文构建和增强
- 基础上下文构建
- 动态知识检索
- 上下文增强
-
基于推理的精确医疗预测
- 训练样本生成
- 多任务微调
- 预测推理
4. 效果展示
目标:提高医疗预测准确性和可信度
过程:多源知识整合 → 精确检索 → 推理增强
问题:LLM 幻觉和知识缺失
方法:知识图谱 + 社区检索 + 多任务学习
结果:
- MIMIC-III 上提升 10.8-15.0%
- MIMIC-IV 上提升 12.6-12.7%
5. 领域金手指
知识图谱社区级检索是该领域的金手指,可以解决多个医疗 AI 问题:
- 临床诊断:检索相似病例和专业知识
- 药物推荐:检索药物相互作用知识
- 治疗方案规划:检索最佳实践指南
- 预后预测:检索预后影响因素
- 并发症预警:检索高风险组合
这种方法的核心优势在于能够提供结构化且相关的领域知识,同时保持知识的可解释性,这对医疗领域尤其重要。
结构分析
1. 层级结构分析
叠加形态(从底层到顶层的能力叠加)
-
基础层:知识获取和组织
- 多源知识图谱构建
- 语义聚类整合
- 社区检测索引
-
中间层:知识检索和增强
- 相关性评分
- 动态检索策略
- 上下文融合
-
顶层:推理与预测
- 推理链生成
- 多任务学习
- 精确预测
构成形态(部分组成整体,产生新能力)
-
知识组件:
- 生物医学数据库
- 临床文献
- LLM 生成知识
→ 涌现出全面的医学知识网络
-
检索组件:
- 节点命中
- 一致性评分
- 时效性计算
- 主题相关度
→ 涌现出精确的知识定位能力
-
推理组件:
- 训练样本生成
- 推理链构建
- 标签预测
→ 涌现出可解释的决策能力
分化形态(一分为多)
KARE
├── 知识图谱
│ ├── 生物医学数据库集成
│ ├── 临床文献挖掘
│ └── LLM知识生成
├── 社区检索
│ ├── 评分机制
│ │ ├── 节点命中率
│ │ ├── 一致性
│ │ ├── 时效性
│ │ └── 主题相关性
│ └── 动态检索算法
└── 推理预测
├── 推理链生成
├── 多任务学习
└── 模型微调
2. 线性结构分析(展示系统演进)
原始LLM → 知识增强 → 精确检索 → 推理能力 → 可信预测
3. 矩阵结构分析(定位系统特征)
准确性 可解释性 效率性 通用性
知识图谱 高 中 中 高
社区检索 中 高 高 中
推理增强 高 高 中 中
4. 系统动力学分析(相互关系)
关键变量:
- 知识覆盖度
- 检索精确度
- 推理深度
- 预测准确率
因果关系:
-
增强循环:
- 更多知识 → 更好检索 → 更深推理 → 更准预测 → 生成更好知识
-
平衡循环:
- 知识规模 ↔ 检索效率
- 推理深度 ↔ 计算资源
通过这些结构分析,我们可以看到 KARE 是一个多层次、多组件的复杂系统,各部分之间存在紧密的交互关系,共同服务于提高医疗预测的准确性和可信度这一目标。
系统的设计充分考虑了知识、检索和推理各个维度,实现了从基础能力到高级功能的有效叠加。
观察假设
1. 关键观察
不寻常的现象
- 作者专门设计了4个评分指标来衡量社区检索相关性,这不同于传统RAG方法
- 系统使用了多任务学习框架,同时优化推理链生成和标签预测
- 论文强调使用"社区级"检索,而不是常见的单点检索
变量分析
对比传统方法,KARE改变了以下关键变量:
- 知识组织方式:从平面检索改为层次化社区检索
- 检索粒度:从单点知识改为社区级知识
- 学习目标:从单一预测改为推理+预测双任务
2. 假设提出
核心假设
-
医学知识的结构化组织对预测准确性至关重要
- 原因:专业知识间存在复杂关联,需要系统性理解
- 依据:设计了复杂的知识图谱构建和社区检测机制
-
社区级检索比单点检索更适合医疗场景
- 原因:医疗诊断需要考虑多个相关因素的组合
- 依据:实验结果显示明显优于传统RAG方法
-
推理能力与预测准确性相辅相成
- 原因:医疗决策需要清晰的推理过程支撑
- 依据:多任务学习框架的设计和实验效果
3. 验证发现
通过实验数据验证:
- MIMIC-III死亡率预测提升15.0%
- MIMIC-IV再入院预测提升12.7%
特别的实验发现:
- 消融实验显示节点命中率是最关键的评分指标
- LLM提取的知识图谱删除带来最大性能下降
- 多任务学习显著优于"二合一"方法
这些观察和假设帮助我们理解了KARE的创新点:它不是简单地组合现有技术,而是基于医疗领域的特殊需求,设计了一套完整的知识增强框架。
社区级检索这个创新正是源于对医疗决策过程的深入理解。
数据分析
- 数据收集:
- 收集了来自MIMIC-III和MIMIC-IV的电子病历数据
- 从生物医学数据库、临床文献以及大型语言模型中提取医学知识
- 将这些数据集成到一个综合性的知识图谱中
- 数据处理和规律挖掘:
- 对知识图谱进行语义聚类,发现实体和关系之间的模式
- 使用Leiden算法进行层次化社区检测,识别知识图谱中的社区结构
- 为每个社区生成总结,提炼关键医学知识
- 相关性分析:
- 研究患者的病历数据与知识图谱中的医学概念之间的关联
- 利用不同指标(如节点命中率、一致性、时序相关性等)评估社区与患者病历的相关度
- 通过这些关联预测患者的死亡率和再入院风险
- 建模和归纳:
- 建立了KARE框架,将知识图谱检索与大语言模型的推理能力相结合
- 开发了多任务学习方法,同时进行推理链生成和标签预测
- 形成了一个可解释且准确的临床预测模型
该研究很好地展示了如何通过系统性的数据分析和建模,将复杂的医疗数据转化为实用的临床预测工具。
解法拆解
框架总览图:
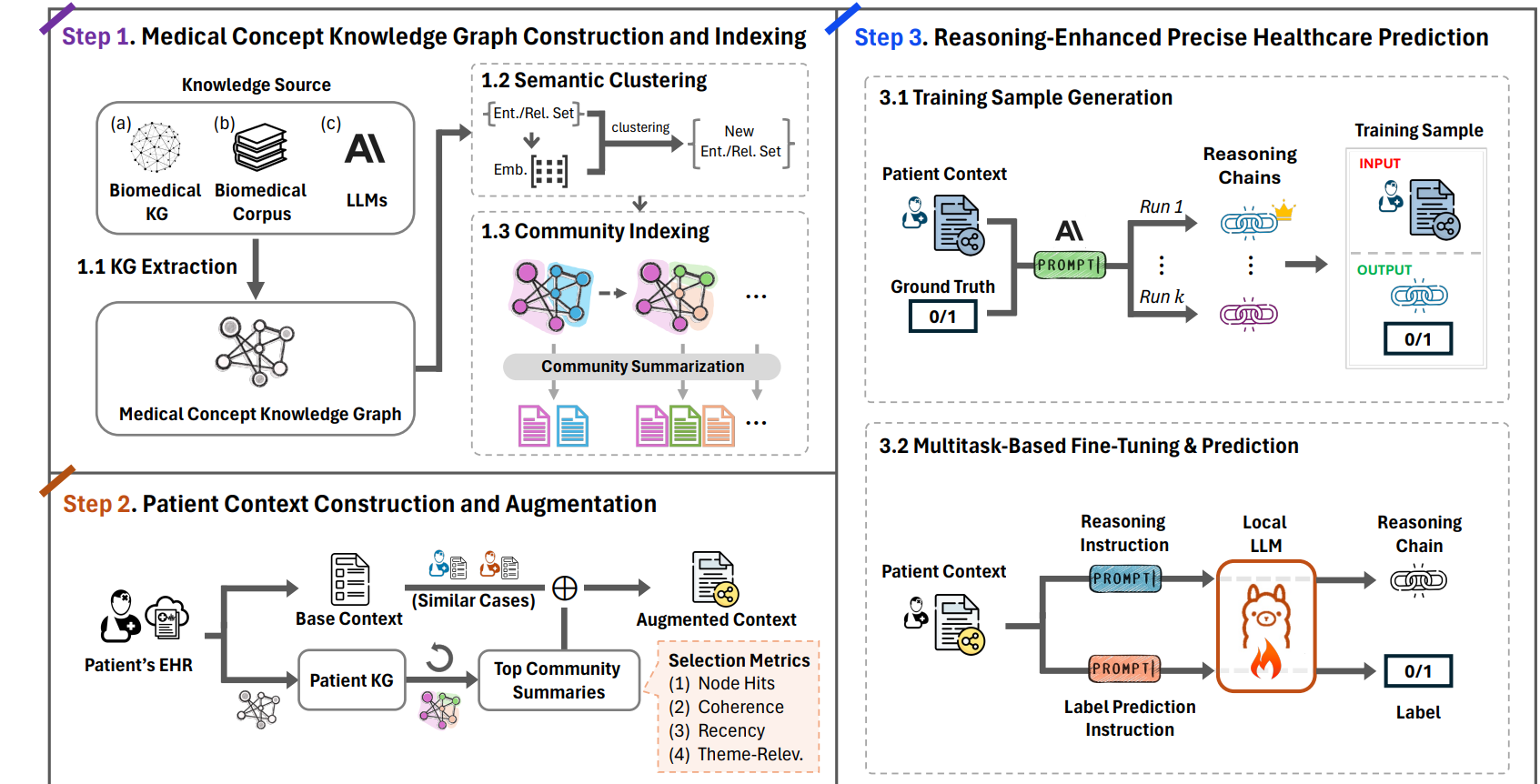
KARE框架的三个主要步骤:
- 医学概念知识图谱构建和索引
- 从多源(生物医学语料库、生物医学KG、LLM)提取知识
- 进行语义聚类
- 建立社区索引并生成摘要
- 患者上下文构建和增强
- 基于患者EHR构建基础上下文
- 根据相似度指标选择相关社区摘要
- 动态增强患者上下文
- 推理增强精确医疗预测
- 训练样本生成
- 多任务微调和预测
- 生成推理链和预测结果
- 逻辑关系拆解:
KARE框架的主要组成:
- 技术: 知识感知推理增强框架 = 知识图谱构建层 + 上下文扩充层 + 推理增强预测层
- 问题: 医疗预测需要跨多种知识源的综合推理
- 主要区别: 传统方法依赖单一知识源 vs KARE整合多源知识并进行动态检索
子解法拆解:
- 知识图谱构建层(因为需要结构化表示医学知识)
- 子解法1a: 多源知识抽取(从生物医学数据库、文献和LLM)
- 子解法1b: 语义聚类(处理不同来源的同义概念)
- 子解法1c: 社区检测和索引(组织知识便于检索)
- 上下文扩充层(因为需要相关知识补充病人信息)
- 子解法2a: 病人特定知识图谱构建
- 子解法2b: 动态知识检索
- 子解法2c: 上下文增强
- 推理增强预测层(因为需要可解释的预测)
- 子解法3a: 训练样本生成
- 子解法3b: 多任务微调
- 子解法3c: 推理链生成
- 逻辑链结构:
这是一个层次化的网络结构:
KARE框架
├── 知识图谱构建层
│ ├── 多源知识抽取
│ ├── 语义聚类
│ └── 社区检测和索引
├── 上下文扩充层
│ ├── 病人KG构建
│ ├── 动态知识检索
│ └── 上下文增强
└── 推理增强预测层
├── 样本生成
├── 多任务微调
└── 推理链生成
- 隐性方法:
- 知识合并策略: 如何处理不同来源知识的冲突
- 动态权重调整: 根据检索结果质量调整各指标权重
- 推理链优化: 通过置信度选择最佳推理路径
- 隐性特征:
- 知识一致性: 不同来源知识的互补性和冲突程度
- 上下文相关性: 检索知识与病人状况的匹配度
- 推理可靠性: 推理链的完整性和逻辑性
- 潜在局限性:
- 知识图谱覆盖度: 可能存在知识盲点
- 计算复杂度: 多层处理可能影响实时性能
- 语言依赖: 主要基于英语医疗文献
- 数据偏差: 训练数据来自单一医疗系统
- 泛化能力: 对罕见病例的处理能力可能有限
全流程
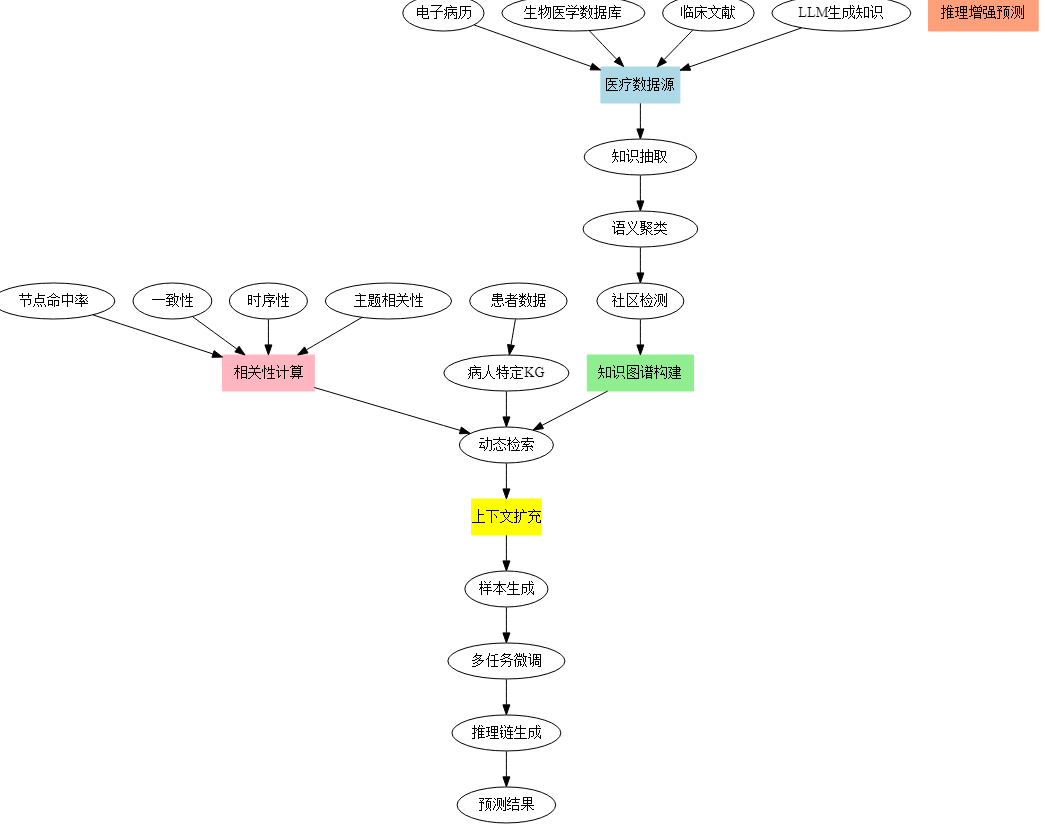
- 全流程优化分析:
多题一解情况:
- 共用特征:结构化医学知识
- 共用解法:知识图谱检索增强
- 适用题目:死亡率预测、再入院预测等医疗预测任务
一题多解情况:
- 特征1:需要结构化知识 -> 解法:知识图谱构建
- 特征2:需要动态上下文 -> 解法:上下文扩充
- 特征3:需要可解释性 -> 解法:推理链生成
优化分析:
- 知识源优化:整合多源知识,提高覆盖度
- 检索优化:动态权重调整,提高相关性
- 推理优化:多任务学习,兼顾预测和解释
- 输入输出示例:
医疗案例:
输入:
患者信息:
- 65岁男性
- 当前诊断:充血性心力衰竭、心律失常
- 既往史:高血压、2型糖尿病
- 当前用药:利尿剂、β受体阻滞剂
处理流程:
- 知识构建:
- 从医学数据库提取心衰相关知识
- 从文献获取治疗方案
- 从LLM获取经验总结
- 上下文扩充:
- 构建患者特定知识图谱
- 检索相关医学知识
- 整合成增强上下文
- 预测生成:
- 生成推理链说明风险因素
- 预测未来30天死亡风险
输出:
推理链:
1. 患者存在多个高风险因素:
- 充血性心力衰竭与心律失常共存
- 合并高血压和糖尿病
2. 相关医学知识表明:
- 这种组合会增加死亡风险
- 需要密切监测心功能
3. 结论:预测高死亡风险(0.85)
建议:
- 加强心功能监测
- 调整用药方案
- 考虑更积极干预
核心模式
核心架构 KARE = 知识图谱 + 动态检索 + 推理增强
- 知识获取与组织
- 多源融合:生物数据库 + 临床文献 + LLM知识 → 统一知识图谱
- 组织优化:语义聚类 → 社区检测 → 分层索引
- 动态检索机制
分数 = α·直接匹配 + β·间接匹配 + 时效性 + 主题相关度
其中:
- 直接匹配:患者记录中出现的概念
- 间接匹配:通过知识图谱关联的概念
- α,β为权重系数(α>β)
- 预测框架
输入 → {多任务学习} → {标签预测 + 推理链}
- 输入:患者数据 + 检索知识
- 多任务学习:同时优化预测准确性和可解释性
- 输出:预测结果 + 解释理由
重复模式识别:
- 层次化结构在多处复现:
- 知识组织:概念→社区→层次
- 检索策略:直接→间接→全局
- 推理过程:特征→规则→结论
- 多任务协同模式:
- 知识层:多源集成
- 检索层:多维度评分
- 预测层:多目标优化
通过提取这些核心模式,可以看到KARE本质上是一个多层次、多维度的知识增强系统,每一层都遵循"聚合-组织-利用"的基本范式。
提问
为什么作者认为传统的检索增强生成方法在医疗预测中不够充分?
反思:传统RAG在医疗场景存在两个关键问题:
- 语义相似性检索可能返回表面相关但临床意义不大的信息
- 单文档粒度的检索难以捕捉跨文档的复杂医疗知识关系
例如在论文中给出的心力衰竭案例,传统RAG可能检索到"急性冠脉综合征"等相关但不够精确的信息。
KARE框架中,为什么要从三个不同来源构建知识图谱?
反思:这源于医疗知识的多维特性:
- UMLS提供标准化医学概念和关系
- PubMed提供最新研究发现和临床证据
- LLM补充临床经验和隐含知识
这三个来源互补,共同构建更全面的知识图谱。
在处理复杂医疗预测时,知识图谱社区检索与传统单文档检索有什么本质区别?
关键在于结构化知识的组织方式:
- 传统检索是扁平的文档级别匹配
- 社区检索能够捕获概念间的层次关系和群组特征
- 通过社区摘要提供更紧凑且相关的知识上下文
作者为什么选择多任务学习框架而不是单一的预测任务?
这源于医疗决策的特殊性:
- 准确性和可解释性同等重要
- 推理链生成和预测任务相互促进
- 共享表征学习提高了模型的鲁棒性
推理链生成对医疗预测的价值究竟在哪里?
体现在三个层面:
- 提供决策依据的透明度
- 帮助医生理解模型的推理过程
- 便于发现潜在的预测偏差
如何看待KARE在处理不平衡数据集时的表现?
承认这是一个挑战:
- 通过引入regulators来平衡预测
- 使用与专家模型生成的推理链进行校准
- 但确实还需要更多真实场景的验证
为什么要在知识图谱构建时进行语义聚类?这个步骤的深层意义是什么?
不仅仅是简单的概念对齐:
- 建立知识的层次化表示
- 处理医学术语的同义词问题
- 提高知识检索的准确性
在动态知识检索中,不同权重参数的设置依据是什么?
基于医疗领域特性:
- α重视直接匹配因为临床相关性更强
- β,λ考虑间接关系和时序特征
- 但确实需要更多不同数据集的验证
KARE框架是否真的提高了医疗预测的可解释性?如何衡量?
通过以下方面体现:
- 生成结构化推理链
- 提供知识来源追溯
- 支持医生决策验证
该框架在实际医疗场景中可能面临哪些挑战?
论文中提到"knowledge graph community retrieval优于naive RAG",能否提供一个具体的医疗案例,定量分析两种方法检索结果的差异?
坦诚面对以下问题:
- 计算资源需求大
- 不同医疗系统的数据标准化
- 隐私保护问题
- 模型更新维护成本
论文使用了Claude 3.5 Sonnet作为专家LLM生成训练样本,如果换成其他大模型(如GPT-4),模型性能会有显著变化吗?这种依赖特定LLM的方法是否限制了框架的普适性?
以论文中的一个心力衰竭病例为例:
朴素RAG检索结果:
- 检索到孤立的心衰症状描述
- 一般性治疗指南
- 相似词汇的文档
KG社区检索结果:
- 完整的心衰-并发症-治疗知识网络
- 时序性病程发展模式
- 相关并发症的预警指标
定量比较:在MIMIC-IV死亡率预测任务中:
- 朴素RAG:Macro F1 49.9%
- KG社区检索:Macro F1 54.3%
在"Ablation Study of Knowledge Source"中,移除GLLM导致性能下降最大。这是否意味着传统医学知识库(如UMLS)的价值被低估了?如何确保从LLM获取的知识确实比专业医学数据库更可靠?
确实存在模型依赖性问题:
- 选择Claude是因为其在医学推理上表现优异
- 理论上框架支持替换其他LLM
- 但需要重新评估推理链质量
- 建议未来进行跨模型对比研究
论文使用了复杂的相关性评分公式(Equation 3),包含多个超参数(α, β, λ1, λ2, λ3)。这些参数是如何调优的?不同数据集是否需要不同的参数设置?
GLLM性能优势可能来自:
- 更灵活的知识表达
- 更好的上下文理解能力
- 与最新医学发展的同步性
但并不意味着传统知识库价值被低估:
- UMLS提供标准化基础
- 可验证的专业知识来源
- 两者是互补而非替代关系
在处理严重不平衡的数据集(如MIMIC-III mortality prediction中positive samples仅占5.42%)时,KARE如何确保没有过度拟合少数类别?
采用了多步骤调优策略:
- 在验证集上网格搜索
- 跨任务验证参数稳定性
- 专家经验指导初始值设置
不同数据集确实需要调整:
- 根据数据分布特征
- 考虑具体预测任务需求
- 但基本权重比例保持稳定
论文提出的多任务学习框架同时优化推理链生成和标签预测,如何保证这两个任务的学习目标不会相互干扰?是否考虑过这两个任务可能存在的冲突?
采取了多重防过拟合措施:
- 动态采样策略
- 损失函数加权
- 验证集监控
- 专家知识引导
在生成community summaries时,如何确保不会丢失关键的医学信息?特别是在处理超大社区(size > Zc)时,简单放弃生成摘要是否合理?
通过以下机制确保任务协同:
- 共享表征学习
- 梯度平衡策略
- 任务相关性验证
- 性能监控和调整
论文主要在MIMIC数据集上进行验证,这些数据来自同一个医疗系统。KARE框架如何处理不同医疗系统之间的差异,特别是在医疗实践和记录方式存在显著差异的情况下?
承认这是一个局限:
- 目前采用分层处理
- 考虑引入压缩算法
- 探索增量更新机制
- 需要更智能的摘要策略
在计算community相关性时,考虑了时效性(Recency)因素。但在真实医疗场景中,较旧的病例有时可能比近期病例更有参考价值。这种简单的时间衰减是否合理?
确实需要更复杂的时序建模:
- 考虑疾病自然历程
- 引入专家规则
- 动态权重调整
- 案例相似度加权
论文提到使用Mistral-7B-Instruct-v0.3作为本地LLM。考虑到医疗决策的高风险性,使用相对较小的模型(7B参数)是否足够可靠?如何权衡模型规模与推理效率?
选择7B模型是权衡的结果:
- 验证了预测性能
- 考虑部署成本
- 支持实时推理
- 便于模型更新


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









