









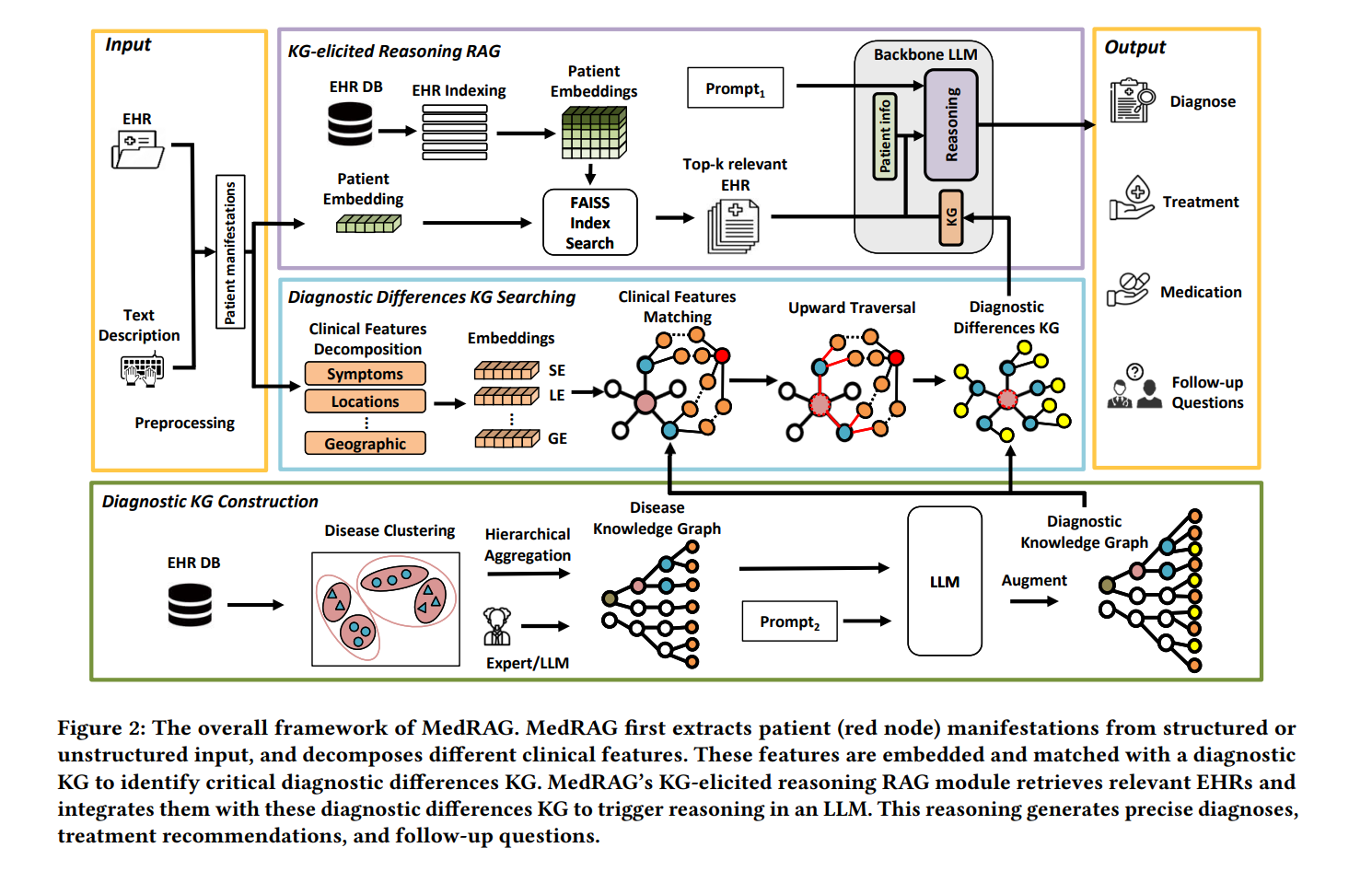
MedRAG :解决传统 RAG 对相似症状鉴别不够精确、信息缺失时缺少主动追问
- 提问
- 层次聚类具体的过程,是如何应用之前通过大模型提取到的子类别主题的呢?
- 为什么论文没有直接基于现成的医疗本体(如 UMLS),而是自己构建了一个四层层级化的诊断知识图谱(KG)?它与传统 ICD-11 的分层结构有什么差异?
- 论文中提到在做 Retrieval-Augmented Generation(RAG)时,简单的“检索-阅读”策略常常导致对相似疾病的模糊回答或者错误诊断。具体是什么原因引起了这种情况?又如何在 MedRAG 中避免?
- 文中定义了三种不同粒度层级(L1、L2、L3)来评估诊断性能。为什么要设计这三个指标?它们分别如何体现模型在“区分相似疾病”这件事上的难易度?
- MedRAG 提出了一种“Proactive Diagnostic Questioning Mechanism”(主动诊断追问机制),该机制具体是如何触发的?如果患者回答的信息依旧含糊,模型会不会陷入死循环?
- 论文使用的公共数据集 DDXPlus 非常庞大,包含上百万合成病人记录,但最后只用了一个“最大平衡子数据集”。为什么要进行裁剪?这样做会不会导致模型对稀有疾病的学习不足?
- 如果在检索环节(Retriever)或知识图谱节点匹配环节(KG Searching)中,嵌入向量出现误差、导致检索不到关键信息,会不会严重影响最终诊断?有没有提出任何应对策略?
- 论文声称该系统特别适合对接到隐私敏感的 EHR 数据库,为何 Retrieval-Augmented 方式能够更好地保护患者隐私?这和将大模型直接微调在全量敏感医疗数据上相比有什么不同?
- 对于私有的慢性疼痛诊断数据集(CPDD),论文特别构造了一个针对慢性疼痛的四层知识图谱。与公共数据集 DDXPlus 的图谱相比,CPDD 的图谱构造有什么特色或挑战?
- 若检索到的病历文本和知识图谱节点出现互相冲突的“细微差异描述”(比如某文本说坐下时加重疼痛,但 KG 里却把相关疾病的特征标注为“坐下会缓解”),MedRAG 如何处理这种冲突信息,不会导致答案自相矛盾吗?
- 文中用公式给出了“Discriminability Score σ(e_LAd)”来挑选哪些症状最适合作为主动追问的关键特征。这个分数是怎么计算的?为什么用节点的度中心性 (degree centrality) 作为判别标准?
代码:https://github.com/SNOWTEAM2023/MedRAG
论文大纲
├── 1 引言【背景与需求】
│ ├── 1.1 医疗领域的诊断风险【背景】
│ │ ├── 错误诊断导致严重后果【问题陈述】
│ │ └── 需降低医生认知偏差【需求】
│ └── 1.2 Healthcare Copilot 的提出【提出系统】
│ ├── 提供诊断建议与治疗方案【功能目标】
│ └── 减轻医生负担并增强患者参与度【价值】
├── 2 相关工作【已有研究现状】
│ ├── 2.1 大语言模型(LLM)与 RAG 在医疗中的应用【技术背景】
│ │ ├── LLM 在问答/病历分析等场景的尝试【LLM 应用场景】
│ │ └── RAG 整合外部文档/知识以提供上下文【RAG 核心机制】
│ └── 2.2 知识图谱对 RAG 的增强【方法改进】
│ ├── 结构化知识图谱可提升模型推理能力【强化推理】
│ └── 现有医疗知识图谱粒度不够细【问题与挑战】
├── 3 预备知识【定义与符号】
│ ├── 3.1 诊断知识图谱定义【名词定义】
│ ├── 3.2 诊断差异 KG 搜索【工作流程】
│ └── 3.3 RAG 回顾【基础模型与流程】
├── 4 方法【MedRAG 框架】
│ ├── 4.1 Diagnostic Knowledge Graph Construction【构建诊断知识图谱】
│ │ ├── 4.1.1 Disease Knowledge Graph Construction【疾病层级关系】
│ │ │ ├── 聚类统一疾病名称【聚合】
│ │ │ └── 采用层次聚合抽象疾病类别【层级组织】
│ │ └── 4.1.2 Knowledge Graph Manifestation Augmentation【补充关键差异】
│ │ ├── 从 EHR 提取临床症状细节【细粒度要素】
│ │ └── 利用 LLM 补足易混淆病症差异点【增强要素】
│ ├── 4.2 Diagnostic Differences KG Searching【检索诊断关键差异】
│ │ ├── 4.2.1 Decomposition of Manifestations【拆分症状】
│ │ ├── 4.2.2 Clinical Features Matching【匹配关键特征】
│ │ ├── 4.2.3 Upward Traversal【向上遍历获取子类别】
│ │ └── 4.2.4 Proactive Diagnostic Questioning Mechanism【主动追问机制】
│ │ ├── 依据缺失信息提出精确问题【定位症状缺口】
│ │ └── 动态完善患者信息以提高诊断准确度【自适应更新】
│ └── 4.3 KG-elicited Reasoning RAG【结合 RAG 和图谱进行推理生成】
│ ├── 通过检索相似 EHR 获取上下文【检索模块】
│ ├── 整合诊断差异 KG 触发推理【推理模块】
│ └── 生成诊断、治疗方案及后续问题【生成式输出】
├── 5 实验【数据与对照】
│ ├── 5.1 数据集【实验对象】
│ │ ├── DDXPlus 公共数据【大规模合成 EHR】
│ │ └── CPDD 私有慢性疼痛数据【真实临床数据】
│ └── 5.2 对比基线模型【基线参考】
│ ├── Naive RAG + COT、FL-RAG、FS-RAG 等【对比方法】
│ ├── DRAGIN、SR-RAG 等【动态检索模型】
│ └── 与 MedRAG 进行结果对比【评估指标】
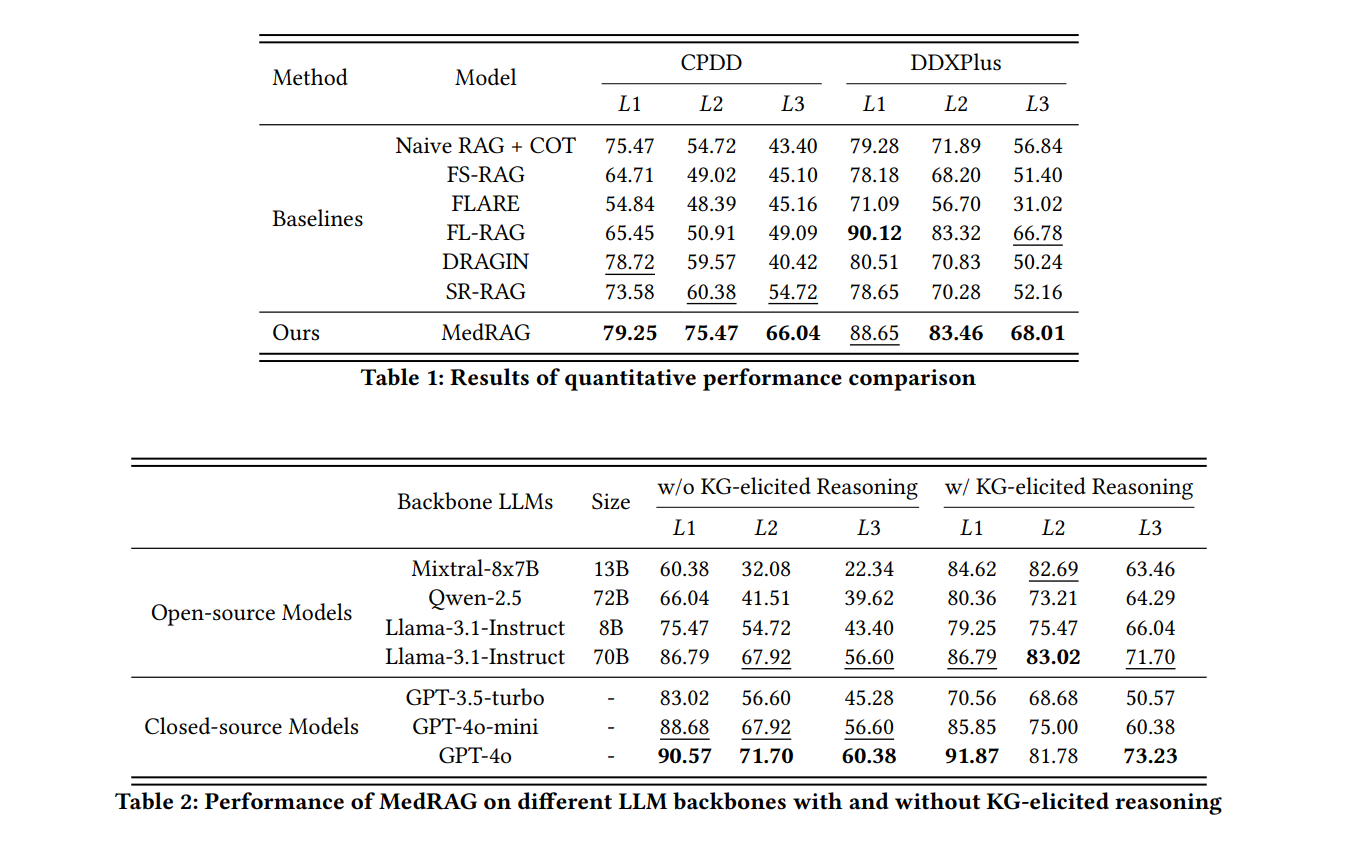
├── 6 实验结果【性能与分析】
│ ├── 6.1 定量结果【准确率与特异度】
│ │ ├── 在 L1 / L2 / L3 粒度下的诊断准确率【多级测评】
│ │ └── MedRAG 在细粒度诊断中表现突出【主要发现】
│ ├── 6.2 通用性与适配性【多模型测试】
│ │ └── 不同 LLM 作后端时,MedRAG 均能提升性能【适配性】
│ ├── 6.3 主动追问机制效果【补全关键信息】
│ └── 6.4 消融研究【各模块重要性】
│ ├── 检索器与 KG-elicited Reasoning 协同增益【协同提升】
│ └── 诊断差异节点与增广特征节点的贡献【关键节点】
└── 7 结论【回归本质】
├── 7.1 主要贡献【总结】
│ ├── 基于知识图谱引导 RAG 推理,提升诊断精度【核心价值】
│ └── 主动追问机制用于缺失信息补足【创新点】
├── 7.2 局限与未来工作【发展方向】
│ ├── 扩展多模态数据【进一步提升】
│ └── 实际医院场景的部署与语音识别集成【临床实践】
└── 7.3 第一性原理下的思考【收敛与反思】
└── 通过知识图谱与 RAG 交互实现可靠医疗决策【终极目标】
├── 1 输入【模型接收的患者信息】
│ ├── 1.1 患者结构化或非结构化病历【数据类型】
│ │ ├── EHR(Structured):包括患者症状、体征、测量指标等【关键数据】
│ │ └── 自然语言文本(Unstructured):医生与患者对话、病情描述等【自由文本】
│ └── 1.2 引入患者已知信息【背景变量】
│ └── 患者年龄、既往病史、功能状态等【辅助信息】
├── 2 处理过程【MedRAG 的主要工作流程】
│ ├── 2.1 Diagnostic Knowledge Graph Construction【构建诊断知识图谱】
│ │ ├── 2.1.1 Disease Knowledge Graph Construction【疾病图谱结构化】
│ │ │ ├── 通过聚类方法统一相似疾病名称【XXX: 聚类算法】
│ │ │ └── 利用层次聚合将疾病划分为多级类别【XXX: 分层聚类+LLM 主题抽取】
│ │ └── 2.1.2 Knowledge Graph Manifestation Augmentation【补充细粒度差异信息】
│ │ ├── 从 EHR 提取具体症状/体征等特征节点【XXX: 信息抽取/分词与规则】
│ │ └── 利用大模型生成易混疾病的差异性描述【XXX: LLM 进行补充说明】
│ │
│ ├── 2.2 Diagnostic Differences KG Searching【诊断差异知识图谱检索】
│ │ ├── 2.2.1 Decomposition of Manifestations【症状拆分】
│ │ │ └── 将病人描述进行分句或分块处理,抽取核心临床特征【XXX: 关键词提取】
│ │ ├── 2.2.2 Clinical Features Matching【关键特征匹配】
│ │ │ ├── 将已拆分特征与图谱节点做语义相似度计算【XXX: Embedding + 相似度模型】
│ │ │ └── 筛选最匹配的特征节点以定位相关疾病/子类别【XXX: Top-k 检索】
│ │ ├── 2.2.3 Upward Traversal【向上遍历 KG】
│ │ │ └── 找到最近的疾病子类别,获取对应差异性诊断信息【XXX: 最短路径/投票】
│ │ └── 2.2.4 Proactive Diagnostic Questioning Mechanism【主动追问机制】
│ │ ├── 当关键信息缺失时提出目标性问题【XXX: 高辨别度特征得分】
│ │ └── 根据医生或患者反馈更新患者症状描述【XXX: 动态数据补全】
│ │
│ └── 2.3 KG-elicited Reasoning RAG【结合图谱的检索与生成】
│ ├── 2.3.1 文档检索【Retrieve】
│ │ └── 从 EHR 数据库中检索相似记录并选取 top-k【XXX: 向量检索(FAISS)】
│ ├── 2.3.2 整合诊断差异 KG【Knowledge Integration】
│ │ └── 将前一步检索到的文档与差异性 KG 信息合并【XXX: Prompt 组装】
│ └── 2.3.3 基于 LLM 的推理与生成【Generate】
│ ├── 使用特制 Prompt 触发大模型进行诊断/治疗方案推理【XXX: KG + 多文档输入】
│ └── 输出更精确且具体的诊断、治疗推荐及后续问题【XXX: 生成式模型(LLM)】
└── 3 输出【MedRAG 最终生成结果】
├── 3.1 明确诊断【疾病名称或分类】
│ ├── 参考精细差异点进行区分,降低相似病种混淆【XXX: 细粒度诊断】
│ └── 可能的多重诊断建议及置信度【XXX: 结果解释】
├── 3.2 治疗和用药方案【个性化建议】
│ └── 理疗、药物、手术及康复训练等【XXX: 专家知识+LLM 输出】
└── 3.3 后续补充问诊【主动提问机制衔接】
├── 针对关键症状进一步确认【XXX: 诊断增量信息】
└── 协助医生或患者获取更精准病情描述【XXX: 问答循环】
【说明】
- 输入(第 1 层):包括结构化 EHR 与自然语言文本,用于向系统提供患者症状、检查结果等;
- 处理过程(第 2 层):依次由「知识图谱构建 → 诊断差异检索 → 带图谱的检索-生成」组成;
- 「2.1 诊断知识图谱构建」:通过疾病聚类与分层聚合得到多级疾病分类,并使用大模型完善差异性特征;
- 「2.2 诊断差异 KG 检索」:将患者症状拆分、匹配图谱节点,若信息不足则触发主动追问以完善症状描述;
- 「2.3 图谱驱动 RAG」:在检索到相关文档的同时,结合知识图谱的差异点信息,通过 LLM 生成精确诊断;
- 输出(第 3 层):系统最终为医生与患者提供明确诊断、治疗及用药建议,并可提出后续关键问题,提升诊断准确度。
通过上述树形结构与标注,可清晰呈现 MedRAG 框架中输入、核心流程(包括多模块技术及衔接关系),以及输出的完整链路。
理解
主要针对「医疗诊断领域」的复杂场景,尤其是疾病症状表现重叠、诊断难度大、医生认知负担高等情形。该类别的问题可以归为「医学诊断决策支持」。
- 具体问题:
- 不同疾病可能拥有相似的临床表现,导致容易误诊;
- 传统的检索增强生成(RAG)模型在诊断细节上缺乏区分度,输出往往不够精准或具有歧义;
- 对于患者症状缺失或描述不全的情况,模型难以及时追问以补足信息,从而妨碍最终诊断的准确度。
因此,MedRAG 的提出,针对上述具体问题(例如相似病症区分、主动追问缺失信息、减少误诊等)提供了改进方案。
「在诊断过程中能够主动区分相似症状并形成更精确的推理与回答」。
通俗地说,它有很强的“细粒度分辨能力”与“主动补充信息能力”。
- 导致这一性质的原因:
- 知识图谱(KG)的结构化特征:为不同疾病及其细微差异提供明确的层次和关联,在推理时可快速定位和区分。
- 检索增强生成(RAG)与 KG 的结合:在生成答案前,不仅检索相似病例或文档,还借助图谱做“诊断差异点分析”,从而增强模型对疾病间差别的理解。
- 主动追问机制:当缺失关键信息时,模型会根据知识图谱中高辨别度特征的缺口,向医生或患者提出补充问题,使诊断更精准。
-
正例(MedRAG 使用场景):
患者腰部疼痛,可能是「坐骨神经痛」或「腰椎管狭窄」。二者有很多相似症状(腿痛、麻木、腰痛等),但在坐姿、步行耐受度、腿部放射痛方式上有所区分。- 使用 MedRAG 时,它会从知识图谱中找出两种病的关键差异:比如「坐骨神经痛在坐姿时通常加重」,而「腰椎管狭窄在坐姿时通常缓解」。
- 如果患者未提供“坐下时疼痛是否缓解”的信息,MedRAG 会主动追问,获取答案后再给出更精准结论。最终可正确区分并给出治疗建议。
-
反例(传统或 naive RAG):
在没有引入知识图谱差异的纯 RAG 模型中,可能只看到“腰痛+下肢放射痛”,就直接给出“可能是坐骨神经痛”的结论,缺乏后续追问过程,从而漏掉“坐姿缓解疼痛”这一关键信息。如果患者实际是“腰椎管狭窄”,则会发生误诊或诊断模糊。
如何提高医疗诊断的准确度,尤其对于症状相近的疾病,或者缺失部分症状描述的场景。
MedRAG 正是针对这一痛点给出的整体框架:它既能通过知识图谱来区分相似病症,还能在生成答案前后动态检索并追问信息,弥补传统模型的不足。
解法拆解

解法 = 子解法1(知识图谱构建) + 子解法2(检索增强生成) + 子解法3(主动追问机制)
├── 子解法1:知识图谱构建
│ ├── 通过聚类算法将疾病按相似性和层次结构分类【特征1】
│ ├── 使用大模型进一步增强每个类别的诊断差异描述【特征2】
│ └── 结果:形成一个多层次、差异化的疾病知识图谱【目的】
│
├── 子解法2:检索增强生成
│ ├── 基于患者的症状进行文献或病例检索【特征1】
│ ├── 通过嵌入模型(FAISS)获取相关案例【特征2】
│ ├── 结合检索到的信息与患者症状进行推理【特征3】
│ └── 结果:生成更精确、个性化的诊断结果【目的】
│
└── 子解法3:主动追问机制
├── 识别缺失的关键信息【特征1】
├── 根据知识图谱和已知症状提出针对性问题【特征2】
└── 结果:通过补充信息提升诊断准确性【目的】
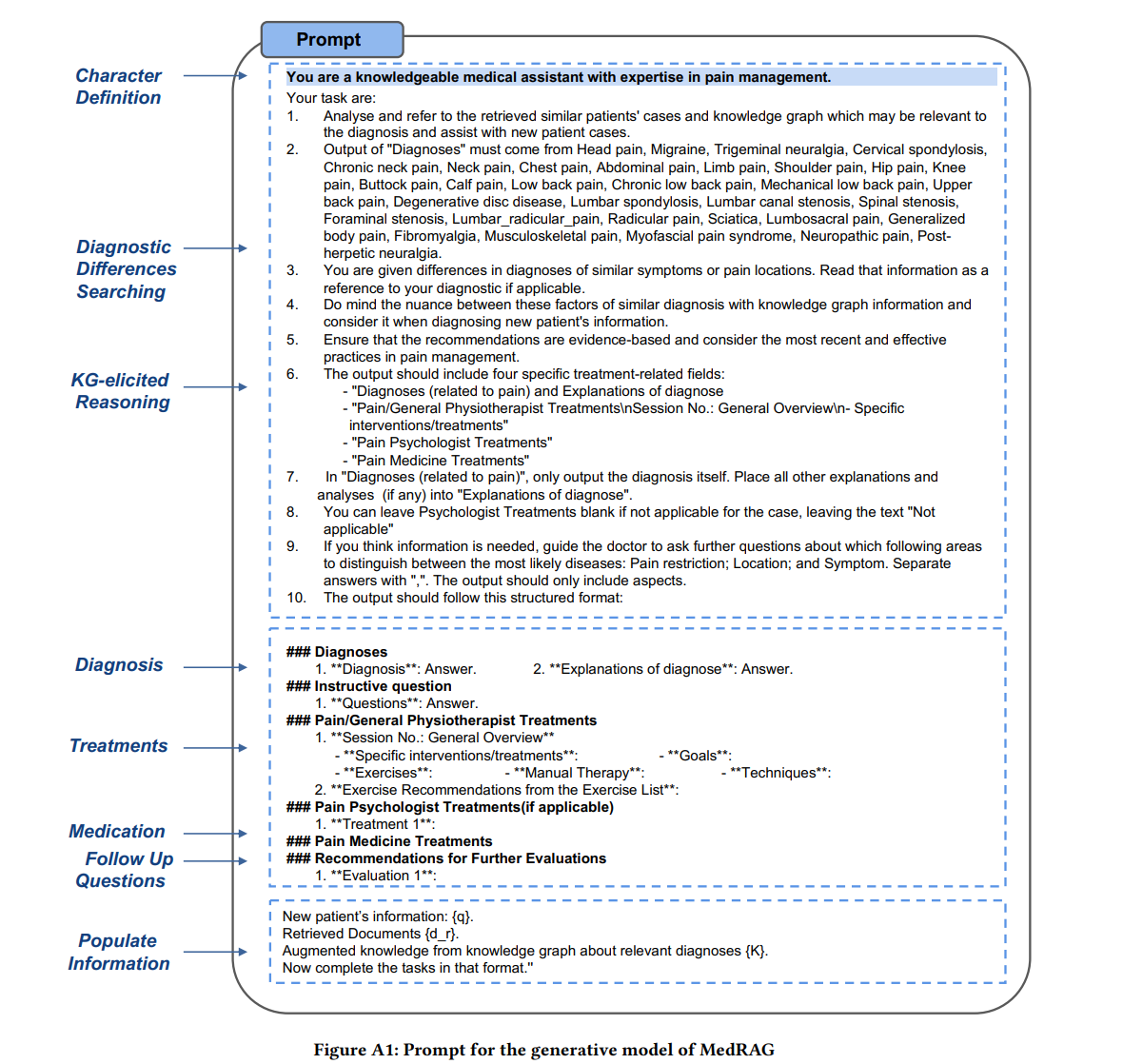
### 提示(Prompt)
**你是一名在疼痛管理领域拥有专业知识的医疗助理(medical assistant)。**
你的任务是:
1. 分析并参考检索到的与诊断相关的相似患者案例和知识图谱,这些信息可能对新的患者病例有所帮助。
2. “诊断(Diagnoses)”必须从以下疾病列表中选取:
- 头痛(Head pain)、偏头痛(Migraine)、三叉神经痛(Trigeminal neuralgia)、颈椎病(Cervical spondylosis)
- 慢性颈部疼痛(Chronic neck pain)、颈部疼痛(Neck pain)、胸痛(Chest pain)、腹痛(Abdominal pain)
- 肢体疼痛(Limb pain)、肩痛(Shoulder pain)、髋关节疼痛(Hip pain)、膝痛(Knee pain)、臀部疼痛(Buttock pain)
- 小腿疼痛(Calf pain)、腰背痛(Low back pain)、慢性腰背痛(Chronic low back pain)、机械性腰背痛(Mechanical low back pain)
- 上背痛(Upper back pain)、椎间盘变性疾病(Degenerative disc disease)、腰椎病(Lumbar spondylosis)
- 腰椎管狭窄(Lumbar canal stenosis)、脊椎狭窄(Spinal stenosis)、椎间孔狭窄(Foraminal stenosis)
- 腰椎神经根疼痛(Lumbar radicular pain)、神经根性疼痛(Radicular pain)、坐骨神经痛(Sciatica)
- 腰骶疼痛(Lumbosacral pain)、全身性疼痛(Generalized body pain)、纤维肌痛(Fibromyalgia)
- 肌骨骼疼痛(Musculoskeletal pain)、肌筋膜疼痛综合征(Myofascial pain syndrome)、神经性疼痛(Neuropathic pain)
- 带状疱疹后神经痛(Post-herpetic neuralgia)
-
3. 你会获得一些关于相似症状或疼痛部位的“诊断差异(differences)”信息。请阅读它们,如有需要,将这些差异纳入对新患者情况的诊断参考。
4. 在诊断新患者信息时,务必注意那些相似诊断之间的差异点,这些差异由知识图谱信息以及检索到的病例所提供。
5. 确保所有推荐内容基于循证医学(evidence-based)并考虑到当前最有效的疼痛管理做法。
6. 输出时应包含四个治疗相关的字段:
- **“Diagnoses (related to pain)”** 和 **“Explanations of diagnose”**
- **“Pain/General Physiotherapist Treatments\nSession No.: General Overview\n- Specific interventions/treatments”**
- **“Pain Psychologist Treatments”**
- **“Pain Medicine Treatments”**
7. 在 **“Diagnoses (related to pain)”** 中,只输出具体的诊断名称;所有额外的解释(如果有)都放在 **“Explanations of diagnose”**。
8. 如果病人不需要心理学方面的治疗,你可以将 **“Pain Psychologist Treatments”** 留空或写“Not applicable”。
9. 如果你认为信息不足,可引导医生针对最可能的疾病,向患者进一步询问以下方面以进行区分:
- 疼痛限制(Pain restriction)
- 部位(Location)
- 症状(Symptom)
可以用“*”将回答分隔,如 “*Pain restriction*,*Location*,*Symptom*”。输出中仅应包含这些方面的要点。
10. 输出内容应当遵循下述结构化格式:
### Diagnoses
1. "Diagnosis": 答案
2. "Explanations of diagnose": 答案
### Instructive question
1. "Questions": 答案
### Pain/General Physiotherapist Treatments
1. "Session No.: General Overview"
- "Specific interventions/treatments"
- "Goals"
- "Exercises"
- "Manual Therapy"
- "Techniques"
2. "Exercise Recommendations from the Exercise List"
### Pain Psychologist Treatments (if applicable)
1. "Treatment 1":
### Pain Medicine Treatments
### Recommendations for Further Evaluations
1. "Evaluation 1":
-----
New patient’s information: {q}
Retrieved Documents {d_r}
Augmented knowledge from knowledge graph about relevant diagnoses {K}
Now complete the tasks in that format!
传统医疗知识图谱,能不能也做到对相似症状鉴别不够精确?
问1:传统医疗知识图谱(Traditional Medical Knowledge Graph)是怎样的?
- 答1:它是一种在医疗领域用于描述疾病、症状、药物、诊断标准等之间关系的结构化知识库。这里的名词有:“疾病(disease)”、“症状(symptom)”、“诊断(diagnosis)”等;动词或关系常见有“is_a”(属于某疾病大类)、“part_of”(是某系统的一部分)等。
问2:为什么说传统医疗知识图谱对相似症状的鉴别能力“往往不够精确”?
- 答2:因为它们通常侧重于在大类疾病层面去概念化,比如 UMLS 会用通用的“腰背痛(back pain)”或“坐骨神经痛(sciatica)”等标签来表示,一个节点下面可能包含几十种相似但其实在临床上有关键区别的细分病症。于是当症状(symptom)在节点层面过于泛化时,它无法细粒度地刻画“坐着时是加重还是缓解”“行走过程中是否麻木”等动态差异。因此,对类似的腰痛、头痛、腹痛等无法精准区分。
- 名词回顾:节点、症状、病种。
- 动词分析:侧重(focus on),概念化(conceptualize),刻画(depict)——说明了传统知识图谱更多是大范围地“整理”,但缺少对“细微差异进行拆分”这种动作。
问3:MedRAG 提到的“主动追问”是什么?它和传统图谱里的静态关系有什么区别?
- 答3:
- “主动追问(Proactive Diagnostic Questioning)”指的是:当模型发现缺少关键信息,或发现有两种疾病“症状重叠”时,系统会自动生成后续问题,引导医生/患者给出能区分这些疾病的具体症状。
- 传统图谱的关系多数是静态的,比如“疾病 A 包含症状集合 X”。它不会告诉你“如何去问病人更多细节”。而 MedRAG 的图谱在某些**关键差异节点(Diagnostic Differences)**处加入了可触发的问句或线索来提醒:“若想区分腰椎管狭窄 vs. 坐骨神经痛,需要进一步询问‘坐立时疼痛是否减轻?’”
- 名词回顾:主动追问、关键差异节点。
- 动词分析:生成(generate)后续问题、触发(trigger)问句、提醒(remind)——这是动态推理过程中的新动作。
问4:具体什么是“关键差异节点”?它能解决相似症状区分的问题吗?
- 答4:关键差异节点是指在图谱中专门用来记录“两个(或多个)容易混淆疾病之间的临床差异点”的节点或特征描述。例如,在“坐骨神经痛”和“腰椎管狭窄”中,是否“走路时加重、坐下时缓解”就是一个非常重要的差异点。
- 如果患者这方面信息缺失,就要主动追问;
- 如果问到了患者说“走几步就开始麻木,必须坐下休息”,那就倾向“腰椎管狭窄”;
- 若患者说“坐下来反而压迫神经更痛,站起来稍微缓解”,就偏向“坐骨神经痛”。
如此一来,系统能够引导医生或患者在模糊不清时提供最能区分疾病的症状要素,从而更精确地给出诊断。
- 名词回顾:关键差异节点、临床差异点。
- 动词分析:解决(solve)相似鉴别、引导(guide)追问、倾向(tend to)某诊断——它们表现了差异节点如何驱动模型去决策或询问。
问5:那传统医疗知识图谱有没有可能也做到类似“主动追问”和“精确区分”呢?
- 答5:原则上可以通过不断增补或个性化拓展,给传统图谱加入更细的“动态病程”或“症状差异”关系,但往往在实际中难度很大,比如:
- 体量庞大:UMLS、ICD-11 涵盖全球疾病,若要为每对相似疾病都建立差异节点,需要庞大的人力校对。
- 缺少动态触发机制:传统图谱缺少像 MedRAG 那样的“检索+大模型+查询后再追问”的工作流,更多是“静态存储 + 检索标签”。
- 灵活度不够:当某些医院想快速修改或加一条本地特征时,大型通用本体往往不易立刻更新,和临床快速迭代的需求会有冲突。
- 名词回顾:全局本体(global ontology)、动态病程。
- 动词分析:增补(add/append)细节、触发(trigger)机制、更新(update)本体——这里说明了传统知识图谱若要具备这些功能需要做更多繁重的扩展和改造。
通过这样多轮的“逐层提问—回答”,我们不但更好地理解了为什么“传统知识图谱难以对相似症状进行精确区分”,也进一步了解到 MedRAG 四层诊断知识图谱如何:
- 设置关键差异节点:用于在相似疾病间找出症状差异点;
- 配合主动追问:在信息缺失时,让模型“主动”去询问细节,从而提高诊断准确度;
- 与 RAG 框架结合:“检索—生成”模式下引入差异化推理,使回答更具针对性和可解释性。
在传统知识图谱的基础上,用提示词激发大模型内部相应的知识,补充当模型发现缺少关键信息,或发现有两种疾病“症状重叠”时,系统会自动生成后续问题,引导医生/患者给出能区分这些疾病的具体症状。
专注于当模型发现缺少关键信息或有两种疾病“症状重叠”时,自动生成后续问题,引导医生或患者提供能区分这些疾病的具体症状:
**提示词(Prompt)**
**你是一名知识丰富的医疗助理,负责协助医生做出诊断,并根据患者的症状提供推荐方案。**
你的任务是:
1. **分析并参考**与患者症状相关的传统医疗知识图谱,识别可能的疾病,并根据症状生成诊断建议。
2. 当你发现两种疾病的症状重叠,或症状描述中缺少关键信息时,你需要**自动生成后续问题**,帮助医生或患者提供更多能区分这些疾病的具体症状。
3. 在疾病之间有相似症状的情况下,你需要触发以下操作:
- **动态问题生成**:基于传统图谱中不同疾病的“关键差异节点”,根据你的知识,生成具体的追问以帮助区分相似疾病。
- 例如,在“腰椎管狭窄”和“坐骨神经痛”之间,生成问题:“请问,您坐下时疼痛是否减轻?”
- **引导诊断**:通过向患者或医生提问,获得更多的症状细节,帮助区分疾病的不同。
4. 输出的结构化格式如下:
- **诊断(Diagnoses)**:
1. "Diagnosis":根据症状推测的可能诊断(如:腰椎管狭窄或坐骨神经痛)。
2. "Explanations of diagnose":简要解释为何该疾病可能性较大,基于患者症状特征。
- **诊断追问(Instructive question)**:
1. "Questions":列出根据症状重叠或信息缺失后需要进一步询问的问题,帮助区分疾病。
示例:
- "坐下时,您的下背痛是否得到缓解?"
- "走路时,腿部麻木加重吗?"
- **治疗建议(Treatment Suggestions)**:
根据诊断结果和症状,提供具体的治疗建议,包含物理治疗、药物治疗等。
- **进一步评估建议(Recommendations for Further Evaluations)**:
1. "Evaluation 1":如果症状仍不明确,提供进一步的评估或检查建议,如影像学检查、神经电生理测试等。
5. **补充信息**:
- 当前患者的基本信息:{q}
- 检索到的相关文档:{d_r}
- 来自传统医疗知识图谱的相关诊断信息:{K}
6. **输出格式**:
### 诊断(Diagnoses)
1. "Diagnosis": 答案
2. "诊断解释": 答案
### 诊断追问(Instructive question)
1. "Questions": 答案
### 治疗建议(Treatment Suggestions)
1. "疼痛/一般物理治疗建议": 答案
2. "疼痛药物治疗建议": 答案
### 进一步评估建议(Recommendations for Further Evaluations)
1. "评估建议 1": 答案
**确保输出的问句能够**:
- 清晰地区分症状相似的疾病,确保患者提供尽可能多的细节。
- 引导医生根据症状的差异制定更精准的治疗方案。
通过这份中文提示词,当模型发现症状重叠或信息不足时,能够自动生成追问,帮助医生进一步确定诊断,提高医疗决策的准确性。
提问
层次聚类具体的过程,是如何应用之前通过大模型提取到的子类别主题的呢?
嗨,老铁,跟你掰扯掰扯这个“大模型分子类别+层次聚类”到底是咋整的哈。
阶段1:大模型先出马,帮忙做“话题/子类别粗分”
-
先把疾病名称都捋直
你有一堆病名,不少还是乱七八糟的:“腰椎骨质增生”“腰椎间盘突出”“lumbar spondylosis”……用脚趾头想想也知道,它们可能指的是同一件事,或者互有交叉。第一步就得人工清洗、去重、同义词合并,把所有的病名都拉到同一个起跑线上,记为 ({e_{L3}^i})。 -
让大模型来个“顺口溜”式的子类别提取
- 你扔给大模型一坨疾病的文本描述(啥症状、好发部位、可能病因之类),然后给它下指令,比如:“听着啊,你给我把这些疾病按相似度分成若干子类别,每个子类别起个能听懂的主题名,最好还能列举哪些病归属在这类里。”
- 大模型就卖力啦,它会搞出一堆“子类别”,类似“下背部退变群组”“颈椎关节病变群组”等,每个类别下挂着一些具体病名。
- 这算是大模型的语义聚合能力,你可以当它是一种“粗分”,别指望一步到位就完美,但能给你先分成若干大块儿。
-
人工微调一下
- 大模型毕竟也会时不时地放飞自我,它分的子类别里也可能夹些奇奇怪怪的归类。
- 你或者临床大夫看完后微调一下,把特别扯的地方捋顺,该拆的拆、该合的合。于是你就有了若干子类别(L2层),每个子类别下是一堆具体疾病(L3)。
小结一下:
这个阶段,咱让大模型当“高级文案+编辑”,以比较自然的语言风格把疾病先分装进子类别,这就是子类别初步。
阶段2:层次聚类再登场,把子类别往上合并成更高层级
-
先给子类别做向量表示
- 你不光要区分各个疾病,还得把这些“子类别”也定量化嘛,比如给每个子类别里所有疾病文本都转成嵌入向量,然后做个平均(或其他啥合并策略),搞成一个“话题中心向量”。这样一个子类别就对应一个向量了。
-
层次聚合(层次聚类)
- 接着你用各种层次聚类手段(什么凝聚型、Ward linkage、单链法、平均距离……)在子类别级别上算“距离”或“相似度”,距离小的就往一起并,距离大的就分开。
- 那些特别接近的子类别可能就归并到同一个父类别(L1),形成树状结构,就像家谱一样逐层合并。
-
给高层父节点命名
- 这时候也可以再次掏出大模型,让它给“父类别”起更大范围的主题名字,比如把“腰椎退变病”和“下背部关节变性”合并成“脊柱退行性变大类”之类的,再让它写个简短介绍:“这些病都是退化性、疼痛集中在下背部,啥啥症状。”
- 至此,你就能得到多层级:
- L1:如“脊柱退变大类”
- L2:大模型最初的“腰椎退变病”子类别
- L3:具体疾病名称(例如“腰椎间盘突出”)
- 如果你还想更细致点,就加 L4:针对每个病的关键表现、区分要点啥的。
这样你就获得一个带层次结构的知识图谱:顶层(L1)几个大块儿分类,然后下面(L2)就是子类别,大模型先帮你做了话题聚合,而层次聚类则把这些话题按相似度不断往上合并或拆分,最终形成一棵分类树。
大模型跟层次聚类的恩怨纠葛
- 大模型:它擅长一把梭地从文本里概括语义特征,说“哎,你看它们都挺像的,一锅烩吧”,给你一大堆子类别。
- 层次聚类:它更擅长在相似度空间中逐层合并,你可以根据阈值随时“截断”聚类层级。换言之,你能灵活控制要分几层,不用死板地就信大模型一口气分完。
最后,为了让图谱“看起来好懂”,通常会在每个节点挂点儿大模型生成的文字描述,或者附加一些临床专家的注释,告诉你这个类别是怎么回事、关键症状都有哪些、跟其他类别如何鉴别等等。
你看,这就是**“先让大模型做子类别话题提取,再用层次聚类逐层聚合”**的大致流程。说白了:
- 大模型先给你一个基于语义理解的初步分组;
- 层次聚类接棒,把各子类别在向量空间里继续合并成更高层;
- 最终落地成一个多级分类体系(诊断知识图谱),上可粗分成几大类,下可细分到具体病名。
就是这么回事儿!如果文字有点“浮夸”,那给来给 GPT 风格的。
整体流程可分为两个阶段:
阶段1:利用大模型做“话题聚合”(Topic Aggregation)并初步得到子类别
-
初步收集并清洗疾病名称
- 从电子病历(EHR)数据库中提取出所有原始疾病名称,这些名称可能存在同义词、缩写或不同程度的表述方式。
- 经过一定的文本预处理/去重/同义合并之后,得到一系列相对统一的疾病条目集合,记为 ({e_{L3}^i})。
-
使用大模型进行疾病“话题聚合”
- 在这个步骤中,大模型(例如 GPT、Llama 等)主要承担“语义理解+话题归纳”的角色。
- 为大模型设计一条提示(prompt),让它基于疾病的文本描述、典型症状、常见病因或部位等信息来“自动分组”:
“请基于下列疾病常见的症状、部位、病理特点,将这些疾病划分为若干‘子类别’(subtopic/subcategory),并给出每个子类别的主题名称或标签。”
- 大模型会输出若干“子类别话题”(例如“腰椎相关疾病”、“肩关节炎症性病变”、“坐骨神经病变”等),并且会列出每个子类别下对应的疾病清单。
- 这一过程相当于让大模型扮演“粗分”的角色,它根据疾病的“自然语言描述”与“症状特征”去进行高层次的聚合,从而得到初步的子类别集合。
-
得到子类别候选并标注
- 大模型输出的结果通常是:「子类别 1:包含哪些疾病;子类别 2:包含哪些疾病;……」。
- 研究者或者医疗专家可能还会做部分人工校验/微调,看大模型的分类是否符合真实临床逻辑。
- 这样一来,我们就拿到了子类别级别(L2 层)的分类话题标签,也为后续的“分层聚类”提供了先验信息(在什么地方可以合并或拆分等)。
小结
这个阶段的输出是:一批带有粗分类结果的疾病子类别,每个子类别代表一组在**“临床症状、疼痛部位、病理机理”等维度上比较相似**的疾病。
阶段2:进行分层聚类(Hierarchical Clustering),逐层归并得到更高层的类别
在拿到大模型产出的子类别主题之后,系统会进一步做分层聚类(也常称层次聚类)。这里可以有多种实现方式,比如凝聚型(agglomerative)层次聚类或自顶向下(divisive)层次聚类,常见的算法包括单链/完全/平均/ward 等距离或相似度的合并准则。大体思路如下:
-
为每个疾病子类别生成话题向量或话题中心
- 首先,可以将大模型输出的子类别看作一个“话题簇”(topic cluster)。
- 我们可以把子类别下所有疾病的文本描述,通过一个句向量/词向量模型(如 BERT、ClinicalBERT、或自己微调的医学领域嵌入)平均或聚合,得到该子类别的“中心向量(centroid)”。
- 这样,每个子类别都可以用一个向量来表示。
-
对这些子类别(话题簇)做分层聚类
- 接下来,就可以用层次聚类算法(常见实现比如 SciPy 的
AgglomerativeClustering,或自定义的 Ward linkage 等)来根据子类别之间的“相似度”将它们往上继续合并。 - 如果在大模型的粗分结果里,有些子类别之间在本质上非常相似(例如“腰椎退变相关”和“下背部退变相关”可能存在大范围交集),层次聚类就会把它们逐层合并到一个更大的“父类别”。
- 反之,如果某个子类别比较独特,可能在层次聚类的过程中会保持自己的一条分支(直到更高阈值时才可能被合并)。
- 接下来,就可以用层次聚类算法(常见实现比如 SciPy 的
-
设定层次聚类的截断阈值,得到最终多级类别层次
- 层次聚类会产生一颗“树状”或“树形并查”结构(dendrogram),可以在某个相似度阈值上截断,把所有节点划分为若干的高层主题(L1 级别)。
- 与此同时,子类别(L2 级别)可以保留在下方;最底层是每种具体疾病(L3 级别);再往下如果还要记录更具体的“发病机制/症状特征”(L4 级别)则可以继续往下扩展。
- 这样就形成了一种**自上而下(或自下而上)**的递归分层结构,即所谓的四层图谱:
- L1:较为宽泛的大类主题(例如 “颈椎病变”、“神经病理性疼痛综合” 等),
- L2:大模型提取的子类别主题,
- L3:具体疾病名称,
- L4:疾病特征或关键症状(后续会再用大模型补充关键鉴别要点等)。
-
在层次聚类各层节点上挂载“大模型的文本描述”
- 在完成聚类后,还会把大模型所产生的文本描述(如对某个子类别/疾病做的简要解释,或者鉴别诊断的关键点)挂载到对应节点。
- 这样便得到一个“具有层次结构 + 带有语义描述”的知识图谱。
如何结合大模型提取到的子类别主题?
综合来看,大模型在这个流程中扮演了“先验话题提取”与“语义描述生成”的角色,具体可以理解为:
-
先验话题提取:
- 大模型先将所有疾病(底层 L3)进行一个粗分类,即把相似疾病放到同一个子类别(子话题)里。
- 这些子类别也可以看作层次聚类的“初始簇”或“引导标签”。
-
利用层次聚类对子类别做上下合并:
- 接下来层次聚类在子类别级别(已经是相似疾病的集合)上进行相似度计算和归并,以获得更高层的大类(L1)或者把少数特殊疾病剥离/细分。
- 若纯粹只用大模型直接做“一步到位”的大类划分,可能会不够细致,或者无法针对特定数量级与相似度要求去灵活调节。而层次聚类提供了一个“可视化树状结构 + 灵活阈值控制”的方式,能在临床需求下调节颗粒度。
-
节点命名与诊断要点增强:
- 当层次聚类把若干子类别合并成更大的“父类别”时,我们仍可再次调用大模型,给这些“父类别”起一个合理的名字,并生成一段简要的文字说明(病理学特征、鉴别要点等)。
- 从而把层次聚类的结果转化成一棵带有自然语言解释的知识树(最后也就衍生成一个多层次的诊断知识图谱)。
- 大模型先从所有疾病中提炼出若干子类别(话题簇),相当于利用其强大的语言理解与概念总结能力做“初步分组”。
- 层次聚类再对这些子类别进行更体系化的聚合或拆分,形成最终多级类别层次(L1、L2、L3…),从而得到我们所需的“疾病分层结构”。
- 在每个层级节点(如子类别节点、父类别节点),都可以挂载由大模型产出的“文字解释”或“关键差异症状”,从而让层次结构不只是一个“算法聚类”的结果,更是一个可阅读、可推理的“诊断知识图谱”。
这种“大模型话题提取 + 层次聚类”的组合方法,兼具了自然语言理解和数值/相似度聚合的优点,可为后续构建检索增强式生成(RAG)和知识图谱辅助诊断提供更精细、更可靠的层次化结构。
为什么论文没有直接基于现成的医疗本体(如 UMLS),而是自己构建了一个四层层级化的诊断知识图谱(KG)?它与传统 ICD-11 的分层结构有什么差异?
答:
- 论文指出,通用本体(如 UMLS、ICD-11)的概念和分类方式常常过于宽泛或抽象,且缺乏针对“疾病细微差异”所需的精细化表征。
- UMLS 的分类存在歧义和边界不清的问题,且直接使用这些庞大的外部知识库并不一定能满足“相似症状但需要高区分度”场景下的需求。
- 因此,该研究团队采用“疾病聚类 + 层级聚合 + LLM 增强”的策略,有针对性地对本地/私有的电子病历(EHR)数据进行清洗、聚合和分层,将相似病种聚合到同一子类别或类别下;再利用大模型来补充最需要的差异化症状描述节点,形成四层的 Diagnostic KG。
- 与 ICD-11 的差异主要在于:ICD-11 是基于全球疾病学与死亡率管理的官方分类,而本研究中的 KG 是从“相似表征是否有助于诊断区分”的角度出发,聚焦于如何辅助临床决策和检索过程,因此结构更“以症状鉴别”为中心、粒度更细化。
-
传统医疗知识图谱的局限
- 缺少针对“相似症状”区分的精细化节点:像 UMLS、ICD-11 等通用本体,通常从“大类疾病”或“诊断编码”角度出发,而非“针对同一症状背后的不同疾病差异”来做深度聚合。它们的层级结构更偏向医学分类学(如按照器官系统或病因),难以直接用于区分那些症状非常相似、仅在细微特征上有所不同的疾病。
- 粒度不够细,且类目过于宽泛:传统本体可能用非常笼统的概念表示疾病,导致很多不同程度或不同病理亚型都合并在同一节点之下,无法提供区别“腰椎管狭窄”和“坐骨神经痛”之类的核心差异信息。
- 缺乏动态推理的适配:通常这些知识图谱的关系更多是「is_a」「part_of」等静态描述,不一定包含“主动追问”所需的临床线索(如“此症状在坐下时是否加重?”)或“病程过程”之类的动态信息。
-
MedRAG 的四层诊断知识图谱
- 分层更聚焦“症状—疾病”差异:先通过聚类和层级归纳,将各种写法或表征不同的疾病名归一,然后再进一步细分到某些疾病的典型和特异症状、病因等特征节点。这样就能在同一大类(如“腰部相关疼痛”)下,清楚展示各亚型疾病在症状表现、触发因素、缓解/恶化条件等方面的差异。
- 引入关键差异节点(Diagnostic Differences):不仅有疾病及其通用症状,还借助大语言模型对数据库里难以区分的疾病进行“差异症状挖掘”,在图谱中增补“关键差异”节点,让模型在推断时可更精准地区分相似病种。
- 可结合“主动追问”机制:当病人提供的信息不足以区分某些疾病时,图谱会提示模型生成有针对性的追问(如“坐立时是否缓解疼痛?”),而这类动态问句在传统知识图谱里一般很少被显式表示或利用。
-
对比总结
- 目标不同:传统知识图谱更多面向学术研究、编码规范或较高层次的医学概念管理,MedRAG 的图谱旨在直接服务于临床诊断过程,尤其是“针对相似症状进行精细化甄别”。
- 灵活性与深度:MedRAG 的图谱结合实际医院 EHR 数据,通过层级聚合和 LLM 增强来构建,可在小范围内灵活调整,并补充“区分度高”的临床要点;而传统本体不易随时修改或细化。
- 动态推理能力:借助知识图谱里的差异化信息和主动追问功能,MedRAG 在病因模糊或信息缺失时更能发掘关键差别,从而显著降低错误诊断几率。
因此,相较于传统医疗知识图谱,MedRAG 自建的四层层级化诊断知识图谱更“以辨别相似症状为核心”,并且能支撑主动提问、细颗粒度区分和动态推理的过程,这是它在临床场景里提升诊断准确率的关键所在。
论文中提到在做 Retrieval-Augmented Generation(RAG)时,简单的“检索-阅读”策略常常导致对相似疾病的模糊回答或者错误诊断。具体是什么原因引起了这种情况?又如何在 MedRAG 中避免?
答:
- 原因:
- 医疗场景中某些疾病症状非常近似,比如腰椎管狭窄、坐骨神经痛、椎间盘突出,都可能呈现“腰背痛、下肢放射痛”等相似临床表现。如果仅用“文本检索 + 简单阅读生成”的策略,模型缺乏精确的差异化细节,常会出现模糊的回答,或把一种腰背痛误判为另一种。
- 大模型在生成文本时若仅依赖相似案例中的通用症状描述,可能忽视个体化的差异症状。
- 解决:
- MedRAG 在查询到相似患者病历的同时,会基于四层知识图谱提炼“诊断关键差异”(Critical Diagnostic Differences),并把这些差异点也加入到提示(prompt)中,触发大模型进行更细颗粒度的推理。
- 在需要时,MedRAG 还会生成后续的精准追问(Follow-up Questions),主动确认患者是否存在区分性强的关键症状,从而降低误判率。
文中定义了三种不同粒度层级(L1、L2、L3)来评估诊断性能。为什么要设计这三个指标?它们分别如何体现模型在“区分相似疾病”这件事上的难易度?
答:
- 设计动机:不同疾病可以用不同层级来表示。例如 L1 可能是大类(如 “下背痛”),L2 是更具体的次级诊断分类(如 “腰椎管狭窄”vs“坐骨神经痛”),L3 则细化到了特定的病理程度或更细分类(如“中央型腰椎管狭窄”vs“侧隐窝狭窄”等)。
- 难易度体现:
- L1:只需要判断广义类别,模型更容易给出正确但宽泛的答案,例如“腰背痛”范围内就算对。
- L2:需要再细分明确是坐骨神经痛还是椎间盘突出等,对区分相似病种有更高要求。
- L3:要求诊断到非常具体的层次,需要模型具备完整的差异化推理能力,所以最难。
- 通过 L1、L2、L3 的诊断准确率和特异度比较,可以评估模型在不同精细化层级的诊断水平,也能客观反映模型是否真正在相似疾病之间作了准确的鉴别。
MedRAG 提出了一种“Proactive Diagnostic Questioning Mechanism”(主动诊断追问机制),该机制具体是如何触发的?如果患者回答的信息依旧含糊,模型会不会陷入死循环?
答:
- 触发条件:
- 当初步诊断中,系统判定患者的现有描述无法在相似疾病之间做出足够区分;
- 在检索和知识图谱比对时,如果发现缺失的“高区分度”临床特征(如某些特异症状或关键部位差异),会激活此机制。
- 流程:
- 系统会评估最具“可鉴别性”(Discriminability)的症状节点,自动生成后续问题,引导医生问患者更多症状细节;
- 一旦收到患者或医生补充信息后,会再次调用同样的 KG 搜索和检索模块,以更新诊断推理。
- 死循环问题:
- 由于系统只会对“少量高区分度的症状”主动发问,而不是无限地提问,并且每次得到新信息后便会重新计算诊断概率,通常不会陷入无休止循环。如果患者仍然含糊不清或拒绝回答,则系统会给出“信息不足”或“需要进一步临床检查”的提示,而不继续反复追问。
论文使用的公共数据集 DDXPlus 非常庞大,包含上百万合成病人记录,但最后只用了一个“最大平衡子数据集”。为什么要进行裁剪?这样做会不会导致模型对稀有疾病的学习不足?
答:
- 裁剪原因:
- 研究需要一个涵盖 49 种诊断但“数量分布相对平衡”的测试集与训练子集,防止“常见病过多、罕见病过少”带来训练或评估上的极度偏差。
- 计算与实验资源限制:若对所有百万量级样本都做高强度检索、嵌入和生成测试,开销过大且难以控制实验变量。
- 影响:
- 确实可能对极罕见病种的样本不足。但研究者主要目标是评估在 “复杂但常见” 场景下的相似疾病区分能力,裁剪后能保证每类病例仍有足够的数量来评估诊断表现。
- 如果需要进一步适配真实医院场景,可在部署时接入更多样本或专门针对稀有病再训练/微调。
如果在检索环节(Retriever)或知识图谱节点匹配环节(KG Searching)中,嵌入向量出现误差、导致检索不到关键信息,会不会严重影响最终诊断?有没有提出任何应对策略?
答:
- 是的,若 Embedding 有较大误差,最相关的 EHR 文档或关键 KG 节点可能未能被检索到,最终会导致生成部分的推理偏差或缺失。
- 文中提出的应对思路:
- 多粒度匹配:除了对患者的所有症状做整体匹配,也对拆解后的“小临床特征”做特征级别的相似度检索,尽量减少单一关键词召回失败对整体的影响。
- 提升鲁棒性:使用“多回合检索”或 FAISS+过滤策略,将较多候选文档进行排序后再合并;若某些关键节点的相似度低于阈值也不会直接丢弃,而是通过上行遍历(Upward Traversal)再检查父节点或子节点。
- 主动追问机制:若系统缺少某些对区分诊断特别重要的信息,会主动列出问题,由医生或患者补充,弥补检索不全带来的损失。
论文声称该系统特别适合对接到隐私敏感的 EHR 数据库,为何 Retrieval-Augmented 方式能够更好地保护患者隐私?这和将大模型直接微调在全量敏感医疗数据上相比有什么不同?
答:
- 相比于直接用大规模医疗隐私数据 fine-tune 一个大模型,RAG 方式的好处是:
- 不需要将原始敏感数据都暴露给大模型服务商或第三方,只需在本地构建向量索引或知识图谱。
- LLM 只在推断时访问“已检索”且必要的小段信息,而非完全掌握整个数据库,以减少外泄风险。
- 敏感数据可进行脱敏或聚合后再索引,传到大模型的上下文可进一步掩码或模糊处理患者标识。
- 也就是说,用 RAG 思路“检索+外部数据融合”可以只在需要时给到模型尽量少的隐私片段,相比把全部数据用于模型训练,安全策略更可控。
对于私有的慢性疼痛诊断数据集(CPDD),论文特别构造了一个针对慢性疼痛的四层知识图谱。与公共数据集 DDXPlus 的图谱相比,CPDD 的图谱构造有什么特色或挑战?
答:
- 特点:
- CPDD 数据集专门聚焦各类慢性疼痛(如腰椎、肩颈、神经痛、肌肉筋膜痛等),其疾病命名不统一且大量出现“症状名”直接当作诊断标记,如“Mechanical low back pain”或者“Chronic lumbar pain”。
- 相比 DDXPlus 的合成数据,CPDD 里很多诊断与表现写得更随意、更口语化,且包含手工备注、重症/轻症等情况。
- 挑战:
- 需要多层聚合归一,才能将多种“类似名称的痛症”聚合为同一疾病结点;
- 增加对关键症状(如肌力下降、步行耐受等)的差异化描述,以便区分不同类型的慢性疼痛。
- 论文给出的应对:通过层级聚类+LLM 的文本增强校对+专家反馈,针对“慢性痛”这个领域做了更深度加工和更精细特征节点的增补。
若检索到的病历文本和知识图谱节点出现互相冲突的“细微差异描述”(比如某文本说坐下时加重疼痛,但 KG 里却把相关疾病的特征标注为“坐下会缓解”),MedRAG 如何处理这种冲突信息,不会导致答案自相矛盾吗?
答:
- 冲突处理:
- 在“KG 引导的推理”中,模型会被提示优先考虑那些可信度更高、或“在该病中更普遍且更鉴别性”的症状特征。若个别文档出现了与多份文档或与图谱多数节点相冲突的信息,会自动在生成阶段纳入不确定性说明或给出“可能存在个体差异”。
- 系统也会通过上下行遍历(Upward/Downward Traversal)查找更上层或更下层节点以校正信息。如果冲突过大,Proactive Diagnostic Questioning 会让医生进行“二次确认”:譬如引导提问“你的疼痛是坐下时减轻还是加重?是否伴随其他活动限制?”。
- 因此,出现矛盾时,模型往往会给出几个可能结论或生成后续问题,而不是直接给出单一的绝对答案。
文中用公式给出了“Discriminability Score σ(e_LAd)”来挑选哪些症状最适合作为主动追问的关键特征。这个分数是怎么计算的?为什么用节点的度中心性 (degree centrality) 作为判别标准?
答:
-
计算方式:
σ ( e L A d ) = 1 deg ( e L A d ) \sigma(e_{LAd}) = \frac{1}{\text{deg}(e_{LAd})} σ(eLAd)=deg(eLAd)1
其中 deg(·) 表示该症状节点在图中的度数。论文将该值的倒数视作区分度。
-
理由:
- 在知识图谱中,度数越高意味着该症状出现在越多的疾病里,所以这个症状越常见、越“通用”,它的鉴别力往往越低;
- 而度数低的节点往往是更少见、更特异性的临床表现,更能在一批相似疾病中起到关键区分作用。
-
这样设计可以在追问时先确认那些“特异度高”的要点,能最有效排除错误诊断;若度中心性过高的症状不必花大量询问,因为它并不能帮助区分疾病间的细节。

















 3030
3030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









