









PRAGyan:串联各种网页,用 知识图谱 + LLM 支持多文档上下文的因果推理,解决海量且碎片化
- 论文大纲
- 1. WHY —— 这个研究要解决什么现实问题?
- 2. WHAT —— 核心发现或论点是什么?
- 3. HOW —— 研究如何开展?
- 4. HOW GOOD —— 研究的理论贡献和实践意义
- 解法拆解
- 提问
- 1. 为什么论文中要在构建知识图谱时保留时间戳信息?仅仅依赖 Node2Vec 的结构特性不足以捕获时序吗?
- 2. 为什么要为检索增强(RAG)设置相似度阈值(如 0.35),而不是直接保留所有潜在候选节点?
- 3. 论文称使用 GPT-3.5 Turbo 模型进行因果推理时能够体现可解释性,但 LLM 仍可能出现“幻觉”式回答。作者如何保证引用的推文确实是真实语料?
- 4. 论文提出的“可持续更新”知识图谱是否需要频繁重新运行 Node2Vec?如果实时性要求很高,这部分性能瓶颈如何解决?
- 5. 使用 LLaMa3 模型进行实体关系抽取时,论文是否深入比较了与其他关系抽取模型(如 spaCy 或 Stanford CoreNLP)的性能差异?
- 6. 论文实验中如何保证对于含有多语言的推文也能进行统一因果分析?Node2Vec 与 Sentence-BERT 是否对多语种做了专门适配?
- 7. 对于某些高度浓缩或引申意义极强的推文(如政治讽刺、反讽、隐喻),论文中提及的三元组抽取流程是否足以捕获潜藏的因果关系?
- 8. 是否存在“负因果”或“抑制效应”类关系?即某些事件非但不会导致效果,反而减轻或抑制其他事件,论文如何处理?
- 9. PRAGyan 方法把 Node2Vec 嵌入与 Sentence-BERT 嵌入结合使用。若两者相似度计算结果相矛盾(一个高、一个低),论文如何做最后决策?
- 10. 如果一条推文既可能导致 A 事件,也可能导致 B 事件,作者是否考虑过在 KG 中出现“一对多”甚至“多对多”的复杂关系?
- 11. 论文在定量评价中采用 BLEU 和 Cosine 相似度作为核心指标,但这两种指标都无法完美衡量因果推理。为什么没有用 ROUGE、METEOR 或更专业的因果评价指标?
- 12. 如何处理推文中的“幽默化”措辞或“讽刺反问”?论文的方法会不会因为文本的表面词汇而抽取到错误因果?
- 13. 用户在提出查询时,如果输入的关键词极其模糊(如“影响”,“状态”),RAG 能否提供高质量上下文?
- 14. 当推文大规模增长后,Neo4j 数据库中的查询速度和 Node2Vec 的更新开销如何平衡?
- 15. 为什么没有采用更先进的大模型(如 GPT-4 或 Llama 2)来做最终生成,而是选 GPT-3.5 Turbo?
- 16. 为什么在知识图谱中要用三元组(entity-relation-entity)而不是五元组或更多元的结构?对时序因果关系会不会太简化?
- 17. 论文中描述了一次定量实验中,PRAGyan 相比基线提升约 10% 的 BLEU 和相似度,这个 10% 是如何统计出来的?有无统计显著性检验?
- 18. 在整合 KG 与文本检索时,是否可能因为语义嵌入导致“距离近就默认有关联”,但实际上缺乏实质因果证据?
- 19. GPT-3.5 Turbo 在回答因果推理时,能否根据查询动态选择合适的检索路径,还是只做一次性的静态检索?
- 20. 作者提到若要面向其他领域(例如金融风险分析、医疗诊断),需要重新构建对应领域的知识图谱。那如何保障在新领域中依旧能保持 10% 或更多的提升?
论文:PRAGyan - Connecting the Dots in Tweets
串联各种推文,用知识图谱+LLM揭示内在因果动态,发现事件的根本原因。
那岂不是也能迁移到 健康搜索 上,分析根本的因果规律(循证研究)。
无论是社交媒体舆情还是健康搜索,核心都在于 “发现潜在的驱动因素与因果逻辑”。
论文大纲
├── 1 研究背景与问题【概述】
│ ├── 1.1 社交媒体平台的影响【背景介绍】
│ │ ├── 推文数量庞大、信息碎片化【问题】
│ │ └── 对事件和言论因果关联的理解需求【应用需求】
│ └── 1.2 大型语言模型(LLM)与知识图谱(KG)【核心概念】
│ ├── LLM(GPT、BERT等)在文本理解上的优势【技术潜力】
│ └── KG在关联关系和时序信息上的可视化与解释性【结构化优势】
├── 2 动机示例【示范性场景】
│ ├── 2.1 COVID-19推文分析【背景故事】
│ │ ├── 用户对简单生活方式的感悟激增【现象描述】
│ │ └── 手动分析推文的困难与时间成本高【痛点】
│ └── 2.2 引出自动化因果分析的需求【问题导向】
├── 3 关键概念与技术【方法介绍】
│ ├── 3.1 知识图谱(KG)【基础】
│ │ ├── 节点与边表示实体和关系【数据结构】
│ │ ├── 适配时序信息,支持更新【动态特性】
│ │ └── Neo4j 用于存储并高效查询【实现工具】
│ ├── 3.2 大型语言模型(LLM)【基础】
│ │ ├── GPT-3.5 Turbo 等在文本生成和理解中的应用【NLP能力】
│ │ └── BERT/Sentence-BERT 用于句向量和相似度判断【语义编码】
│ ├── 3.3 节点与句嵌入技术【嵌入方法】
│ │ ├── Node2Vec 捕捉局部与全局结构【图嵌入】
│ │ └── Sentence-BERT 获得语义相似度【文本嵌入】
│ └── 3.4 检索增强生成(RAG)【检索与生成一体化】
│ ├── 从KG中检索语义相关上下文【检索模块】
│ └── 利用LLM生成因果推理与解答【生成模块】
├── 4 方法与流程【研究设计】
│ ├── 4.1 研究问题【目标】
│ │ └── “KG与LLM结合能否提高因果分析效果?”【核心假设】
│ ├── 4.2 数据集介绍【资源】
│ │ └── COVID-19推文数据(Kaggle公开)【文本来源】
│ ├── 4.3 关系抽取与知识图谱构建【KG构建】
│ │ ├── 使用LLaMa3提取实体与关系【实体-关系抽取】
│ │ └── 存储至Neo4j并嵌入【图数据库】
│ ├── 4.4 检索与QA过程【流程】
│ │ ├── Sentence-BERT对查询向量化【查询编码】
│ │ ├── 在Node2Vec空间检索相关节点与边【相似度检索】
│ │ └── 由GPT-3.5 Turbo 结合上下文进行因果推断【LLM回答】
│ └── 4.5 对照基线:单独使用GPT-3.5 Turbo【基线比较】
├── 5 结果与讨论【研究发现】
│ ├── 5.1 定性评价【质量与上下文准确度】
│ │ ├── PRAGyan在细节与可解释性上更优【细节丰富度】
│ │ └── 基线GPT模型易遗漏背景信息【缺少上下文】
│ ├── 5.2 定量评价【指标】
│ │ ├── BLEU分数与Cosine相似度综合对比【评估标准】
│ │ └── PRAGyan比基线提高约10%【实验结果】
│ ├── 5.3 结果分析【意义解读】
│ │ ├── KG提供结构化关系,增强LLM推理【优势原因】
│ │ └── 若仅依赖大模型,易出现不一致生成【局限性】
│ └── 5.4 对应用决策与可行动性启示【价值】
├── 6 相关工作【研究脉络】
│ ├── 6.1 社交媒体文本分析与实体识别【领域研究】
│ ├── 6.2 知识图谱与因果推理【方法研究】
│ ├── 6.3 LLMs在检索增强生成中的探索【技术研究】
│ └── 6.4 本研究与现有工作的差异【创新点】
├── 7 限制与挑战【研究不足】
│ ├── 7.1 数据动态性与噪声【推文数据问题】
│ ├── 7.2 模型评估维度有限【评价挑战】
│ └── 7.3 系统通用性与可扩展性【适用范围】
└── 8 结论与未来工作【总结与展望】
├── 8.1 整体贡献【总结】
│ ├── 提出KG+LLM整合框架进行因果分析【成果】
│ └── 实验证明比单一LLM效果更优【证据】
├── 8.2 实际应用场景【价值】
│ └── 社会媒体舆情分析、谣言溯源等【潜在方向】
└── 8.3 未来研究方向【扩展】
├── 优化KG实时更新与可解释性【技术路线】
└── 应用至更多领域(医疗、金融等)【跨领域扩展】
核心方法:
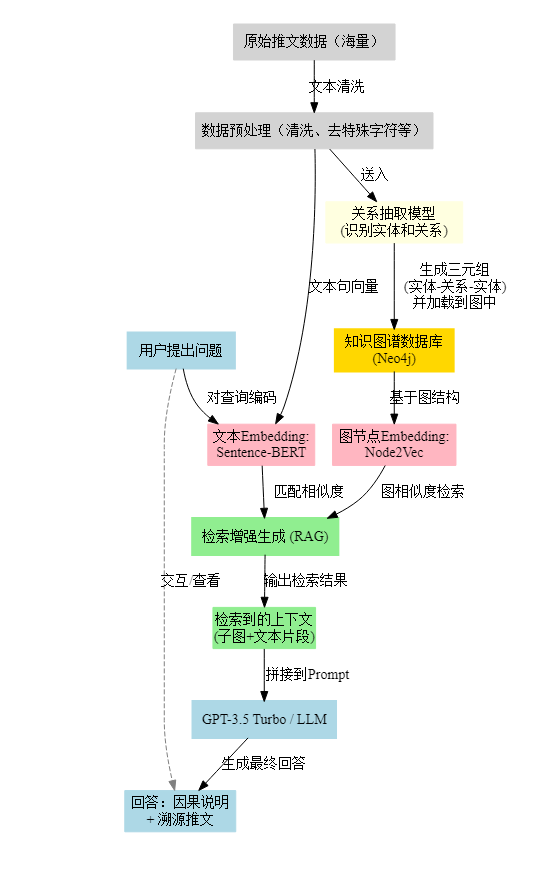
├── 1. 输入【源数据与需求】
│ ├── 1.1. 原始推文数据【文本来源】
│ │ └── 包含含噪音的社交媒体文本【带来预处理需求】
│ └── 1.2. 用户查询【用户或系统提出的问题】
│ └── 需要因果分析的主题或关键字【引导检索与推理】
├── 2. 处理过程【多阶段数据管线】
│ ├── 2.1. 数据预处理【文本清洗】
│ │ ├── 去除特殊字符、链接、表情符号【降低噪音】
│ │ ├── 处理缩写与大小写,统一格式【规范化】
│ │ └── 保留时间戳便于时序分析【时序信息】
│ │ └── 与后续因果推理中事件顺序相关【步骤衔接】
│
│ ├── 2.2. 关系抽取【实体-关系识别】
│ │ ├── 使用LLaMa3模型进行细粒度实体识别【深度NLP】
│ │ └── 生成三元组(实体1-关系-实体2)【核心输出】
│ └── 为知识图谱的构建提供结构化信息【衔接下步骤】
│
│ ├── 2.3. 知识图谱存储【结构化数据管理】
│ │ ├── 采用Neo4j数据库保存三元组【图数据库】
│ │ ├── 节点与边同时携带时序和文本信息【动态属性】
│ │ └── 可以灵活查询并持续更新【为后续检索做准备】
│
│ ├── 2.4. 向量嵌入与编码【文本与图的向量化】
│ │ ├── Node2Vec:对知识图谱的节点和结构进行嵌入【图表征】
│ │ │ └── 捕捉局部/全局语义与拓扑信息【提升检索精度】
│ │ └── Sentence-BERT:将查询和文本转换为句向量【文本表征】
│ └── 以余弦相似度来度量文本与节点的匹配度【检索核心】
│
│ ├── 2.5. 检索增强生成(RAG)【上下文获取与回答生成】
│ │ ├── 根据用户查询向量,在KG嵌入中检索最相似节点或边【检索环节】
│ │ └── 获取与查询高度关联的子图或文本片段【上下文过滤】
│ └── 为LLM(GPT-3.5 Turbo)提供准确的知识背景【衔接下步骤】
│
│ └── 2.6. 因果推理与答案生成【LLM回答】
│ ├── GPT-3.5 Turbo基于检索到的上下文执行推理【生成式模型】
│ ├── 输出可能的因果关系、事件驱动力等【回答主体】
│ └── 可进一步调用原文节点提供可追溯证据【解释性与可控性】
│
└── 3. 输出【因果分析结果】
├── 3.1. 因果推理报告【自动生成文本】
│ ├── 识别事件间的因果链条【核心成果】
│ └── 给出支撑该推断的推文来源【参考证据】
└── 3.2. 连贯的可视化知识图谱【图形展示】
└── 用户可在图谱中追溯具体节点、时间线与相互关系【增强解释】
1. WHY —— 这个研究要解决什么现实问题?
- 社交媒体海量文本的因果分析难题
社交媒体平台(如 Twitter/X)上每天产生大量的零碎、非结构化文本,研究者或组织常常需要从这些海量数据中提炼“事件背后的成因”或“观点形成的原因”。- 现实挑战:
- 碎片化:推文往往零散且缺乏系统组织,很难进行有效检索和关联分析。
- 缺乏深层因果推理:仅靠传统LLM难以深入挖掘因果,只有表层总结。
- 难以动态更新:疫情等场景下信息更新频繁,需要随时追踪和分析最新推文,但缺乏合适的动态处理体系。
- 现实挑战:
因此,本研究旨在解决“如何在海量且动态的推文数据中,挖掘并解释某种现象或事件的真正原因”,进而为决策者或研究者提供更精确、更具可追溯性的洞察。
2. WHAT —— 核心发现或论点是什么?
-
核心发现:
- 知识图谱与大模型融合(PRAGyan) 可以在社交媒体的因果分析中显著提升可解释性与准确性。
- 通过“检索增强生成 (RAG) + 知识图谱结构”方式,能够在回答“某事件/观点为什么发生?”时,回溯到具体推文、时间节点,呈现可验证的证据链,而不是一味生成笼统回答。
- 经过对比实验(与仅使用 GPT-3.5 Turbo 的基线方法相比),该方法在 BLEU、Cosine Similarity 等评价指标上均有提升,且回答质量在可读性和证据支撑方面更优。
-
主要论点:
- 只有同时发挥 LLM 的语言理解/生成能力 与 知识图谱的结构化和可追溯性,才能在庞大的社交媒体语料中获得扎实的因果推理结果。
3. HOW —— 研究如何开展?
3.1 前人研究的局限性
-
仅用 LLM 的方法
- 常见方法:直接将文本输入 GPT-3.5 或其他语言模型,得到摘要或原因推断。
- 局限:面对海量杂乱数据时,模型难以准确定位相关证据,且对“背后成因”的解读缺乏透明度、可追溯性。
-
仅用知识图谱的方案
- 常见方法:把推文中的实体和关系构建到知识图谱中,通过图数据库做检索或简单推理。
- 局限:难以对自然语言做深度理解和灵活表达,回答的生成过程比较生硬。
-
缺乏动态更新与因果深度关联
- 许多知识图谱或 NLP 方法只适合静态数据集,面对社交媒体的实时性场景,难以持续有效地保持因果链路的准确性。
3.2 你的创新方法/视角:PRAGyan
- 整体思路:
- 关系抽取(例如使用 LLaMa3 模型进行实体关系识别):从大量推文中抽取三元组(实体1-关系-实体2),并标注时间戳信息。
- 构建知识图谱(Neo4j):将三元组和时间信息保存至图数据库中,保留可视化、检索、可追踪的结构。
- Embedding & RAG:
- 用 Node2Vec 或 Sentence-BERT 得到节点/推文向量,对查询语句做向量化后在图谱中检索最相关节点/边。
- 将检索到的上下文提供给 GPT-3.5 Turbo,进行“检索增强生成 (RAG)”,从而得到包含具体证据引用的因果回答。
- 技术亮点:
- 结合了 “知识图谱(结构化和可追溯) + LLM(语言理解与生成) + RAG(检索增强)” 三种要素。
- 在面对海量推文时,可以更好地平衡语义理解与可解释性。
3.3 关键数据支持
- 数据集来源:Kaggle 新冠疫情推文数据集,包含数万条推特。
- 实验设计:
- 对推文文本进行清洗、去重、时间戳统一。
- 使用 LLaMa3 Fine-tuned 进行关系抽取,导入 Neo4j;嵌入学习 (Node2Vec, Sentence-BERT)。
- 设计若干测试查询(如“为什么出现超市抢购?”“为什么人们突然更珍惜平凡生活?”),分别用基线方法(仅 GPT-3.5)和PRAGyan对比。
- 结果指标:BLEU、Cosine Similarity、以及人工对可追溯性和因果解释度的综合评价。
3.4 可能的反驳及应对
- 反驳:知识图谱构建耗时大,更新不便。
- 应对:对 Neo4j 做定期(或实时)批量更新;关系抽取可批处理,保证一定周期内的可用性。
- 反驳:LLM 会有“幻觉”或生成不实信息。
- 应对:RAG 的流程先检索到真实推文证据,再让 GPT 生成回答,显著降低编造内容的风险,并可追溯到原始推文。
- 反驳:仅对 Twitter 数据有效,其他平台适用性?
- 应对:只要是文本形式(如 Reddit、新闻网站评论等),只要能抽取实体关系并存入知识图谱,就可以移植此方案。
4. HOW GOOD —— 研究的理论贡献和实践意义
-
理论贡献
- 首次系统性地将“知识图谱 + RAG + LLM”融合用于社交媒体因果分析,弥合了以往“图谱缺乏灵活语言表达”和“LLM 缺乏可追溯性”的鸿沟。
- 提出了一种兼顾结构化表示与动态语义理解的新型分析范式,对未来在学术界开展深层因果推理研究起到启发作用。
-
实践意义
- 舆情监控:对于突发公共卫生事件、政治选举或品牌危机,可及时地跟踪和理解民众观点的成因,对决策有直接支持。
- 实时监测与预测:在新的数据不断出现时,动态更新知识图谱,让管理者对舆论及事件成因有持续把握。
- 推广性:不仅限于新冠疫情推文,也可应用于其他大规模、多变、需要因果洞察的场景(如金融市场舆情、供应链风险分析等)。
解法拆解
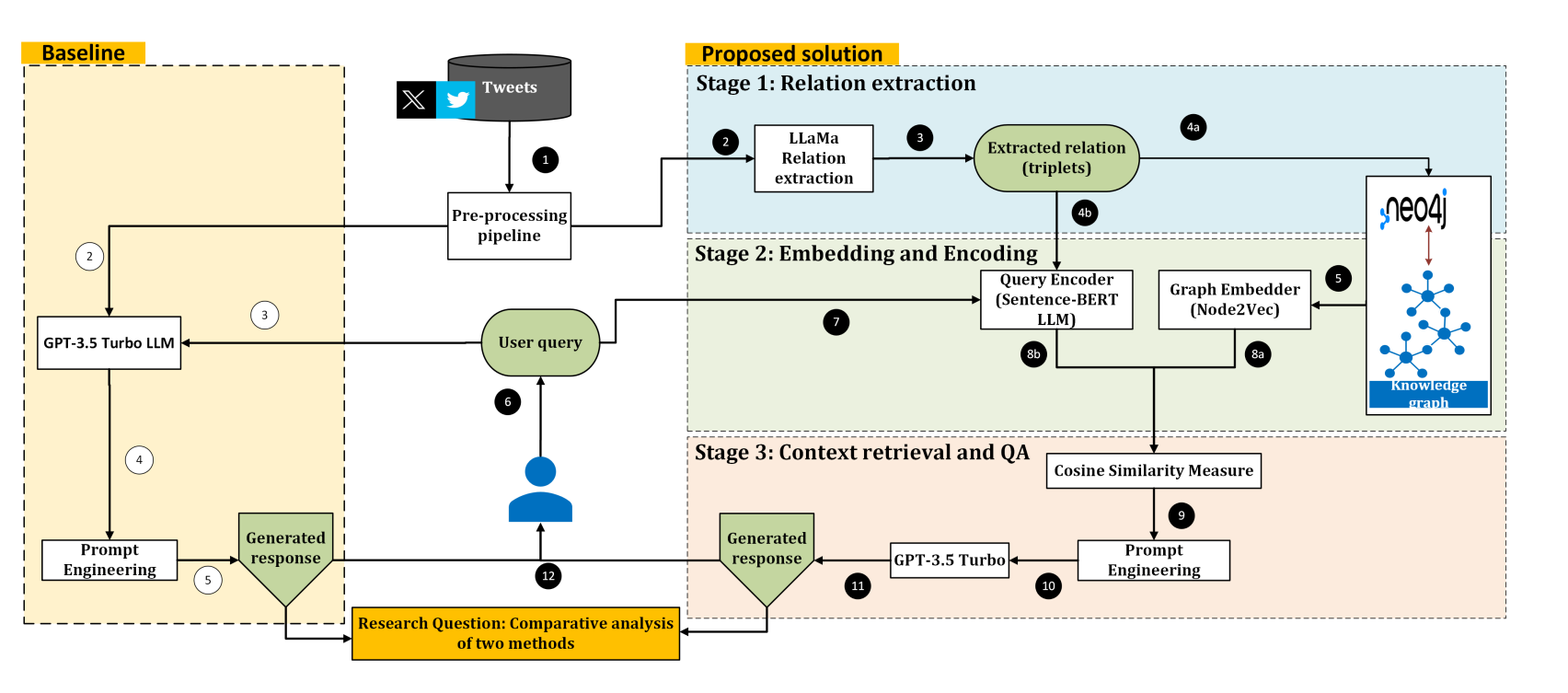
一、整体解法及主要区别
解法:PRAGyan混合模型(KG + RAG + LLM)
-
核心思路:在语言模型(LLM)生成答案之前,通过知识图谱(KG)与检索增强(RAG)提供更精准的上下文,以实现更深入、可解释的因果推理。
-
公式形式拆解(简略示意):
- 用 ( \text{RelExtract}(x) ) 表示从文本 ( x ) 中抽取实体与关系的函数(基于LLaMa3等NLP模型);
- 构造图 ( G ) 并以 Node2Vec 得到嵌入向量 ( E_G );
- 将查询 ( q ) 以 Sentence-BERT 编码得向量 ( v_q );
- 计算与图中节点/片段的相似度:( \text{sim}(v_q, E_G) );
- 选取最高相似度的子集作为检索结果 ( D^* ),再交由 LLM 进行因果推理并生成答案 ( A )。
- ( A = \text{GPT-3.5Turbo}(q ,|, D^*) )。
-
和同类算法的主要区别:
- 相比单纯使用LLM:本方法在生成前借助知识图谱与检索步骤,大幅提升了可解释度与上下文精度。
- 相比仅用知识图谱(KG):本方法融合了最新的生成式模型(GPT-3.5 Turbo),大规模语言模型在自然语言理解和生成上的优势仍得到保持。
- 相比传统信息检索+QA:通过 Node2Vec 和 Sentence-BERT 进行双重向量检索(图向量 & 文本向量),对时序信息与关联关系有更全面的把握。
二、按照“特征—子解法”的形式分解
结合论文内容,我们可以总结出4个关键特征,对应4个子解法(也可理解为4大处理模块):
解法(PRAGyan)
= 子解法1(语料噪声及时序信息 -> 数据预处理与时序保留)
+ 子解法2(实体与关系识别 -> 关系抽取/知识图谱构建)
+ 子解法3(语义关联检索 -> Node2Vec + Sentence-BERT + RAG检索)
+ 子解法4(可解释的生成式因果推理 -> LLM生成)
下面逐一展开:
子解法1:数据预处理与时序保留
之所以用“数据预处理+时序保留”的子解法,是因为**(特征)**:推文数据存在大量噪声(表情、短链、缩写等),同时时序对因果分析至关重要,不能丢失。
-
处理噪声
- 将推文中的多余字符、特殊符号、无效URL等剔除或转化。
- 保证后续文本处理模块的准确性,不被噪声干扰。
-
保留时序信息
- 保留“tweet时间戳”或“事件发生时间”,为后续推断事件先后关系奠定基础。
- 时序在因果分析中(谁先谁后)非常关键。
该子解法的作用:为后续关系抽取提供干净数据,并给知识图谱添加时间属性,以保证因果关系可追溯。
子解法2:关系抽取 / 知识图谱构建
之所以用“关系抽取+KG构建”的子解法,是因为**(特征)**:需要显式化地把推文中的实体和关系结构存储起来,提升可解释度,且方便后续检索。
-
实体与关系识别
- 使用LLaMa3等模型,做句法分析和语义识别,抽取“实体1—关系—实体2”三元组。
- 例:从“口罩短缺导致疫情恐慌”中识别出
(口罩短缺) - 导致 - (疫情恐慌)。
-
构建知识图谱
- 将三元组写入Neo4j,形成可查询的图结构。
- 在节点或边上标注时间戳、文本来源等额外信息,兼顾时序与语义。
该子解法的作用:让后续算法能够“检索”到节点关联或路径,帮助推理某一事件或话题的起因。
子解法3:语义关联检索(Node2Vec + Sentence-BERT + RAG)
之所以用“语义关联检索”的子解法,是因为**(特征)**:单纯关键词匹配或传统检索不足以捕获深层语义和网络结构,需要图嵌入和句向量结合。
-
Node2Vec
- 对知识图谱中的节点做随机游走,获取向量表示 ( E_G )。
- 能保留图的局部与全局拓扑特征,便于判断某节点与查询的网络相似度。
-
Sentence-BERT
- 将用户查询或推文文本编码成句向量 ( v_q ),可用余弦相似度来衡量语义接近度。
- 和 Node2Vec 输出结合在 RAG 框架下进行双重检索:先根据文本向量做一次过滤,再在图嵌入中找最相似或最相关的子图/路径。
-
RAG(Retrieval-Augmented Generation)
- 将检索到的上下文信息(文本片段或节点三元组)反馈给 LLM,作为提示(prompt)。
- 这样可以在回答中“引用”或“利用”准确的知识点,减少胡乱生成的风险。
该子解法的作用:保证了在大规模数据中快速定位到最“相关、重要、准确”的信息,为最终的因果推理提供高质量的上下文。
子解法4:可解释的生成式因果推理(LLM生成)
之所以用“LLM生成+可解释因果推理”的子解法,是因为**(特征)**:需要有自然语言回答的能力,同时能溯源到具体推文依据,提升可解释性。
-
因果推理回答
- 使用 GPT-3.5 Turbo 这类大语言模型,在已有检索到的上下文基础上进行推理。
- 产出更连贯、自然的文本答复,解释某现象的原因及关联证据。
-
引用原始证据
- 在回答中附带对应的节点或推文URL/ID,让读者可回溯数据源,增强可信度。
- 这部分就是“可解释AI”在NLP场景中的一次应用。
该子解法的作用:实现自然语言层面的“因果解释”,同时避免“凭空捏造”,保留可追溯的数据支撑。
三、解法的逻辑链(决策树表示)
以下是用决策树/树状结构来呈现整条流程(子解法1~4),并标注每一步与下一步的衔接关系:
┌─ 解法(PRAGyan:KG + RAG + LLM)
│
├── 子解法1:数据预处理与时序保留
│ ├── 特征:推文噪声多 & 时序重要
│ └── 输出:干净文本 + 时间戳
│
├── 子解法2:关系抽取 / KG构建
│ ├── 特征:需要结构化 & 可解释
│ └── 输出:Neo4j图数据库(实体-关系-时间)
│
├── 子解法3:语义关联检索(Node2Vec + Sentence-BERT + RAG)
│ ├── 特征:深度语义 + 图结构检索
│ └── 输出:最相关上下文/子图(D*)
│
└── 子解法4:可解释的生成式因果推理(LLM生成)
├── 特征:自然语言回答 & 可溯源
└── 输出:答案文本(含证据引用)
整个流程是一个链式逻辑:
- 先做文本清理/时序化 →
- 再抽取实体关系建图 →
- 利用图和文本向量做检索 →
- 最后让 LLM 根据检索结果完成生成。
四、分析“隐性方法”与“隐性特征”
在论文里,有几项做法虽未被作者单独命名,却起到了重要作用,可以视为**“隐性方法”或“隐性特征”**:
-
隐性方法A:时序信息的融合
- 在大多数检索场景中,文献只提及文本相似度,较少把“时间顺序”显式纳入检索规则。
- 这里作者在构建图谱时给边添加了时间属性,或在 Node2Vec 里加入对时序的处理(如定期重跑、保留时间戳以影响抽样等)。
- 这是不一定在普通NLP流程中常见的特征,却在因果分析中很关键。
-
隐性方法B:上下文阈值筛选
- 论文有提到使用Cosine相似度阈值(如0.35)来筛选检索结果,保证不引入过多噪音。
- 这一步往往被当做一个“细节参数调优”处理,但它其实是隐性的关键决策:不当的阈值会导致检索过度或不足。
-
隐性方法C:对原始推文回溯
- LLM的回答结果可以附带引用具体推文ID,这个回溯机制需要在数据预处理和图构建时,把推文ID等元数据完整保存。
- 论文中虽没详细称之为“关键技术”,但它能大幅提高最终的可解释与可追溯度,属于隐性但重要的实现细节。
这些隐性方法多半是实践层面的小技巧或关键衔接步骤,常被作者简要描述或一笔带过,但实际上对成果落地影响很大。
五、分析“隐性特征”
隐性特征可能不是研究问题本身或显式条件中指定的,而是在算法/实现中自然而然浮现的要点。例如:
-
节点/关系的动态更新频率
- 社交媒体数据是流式的,节点和关系随时可能变化。作者短暂提到可以持续构建、定期嵌入,但并未深入展开自动化刷新机制。
- 这种“动态性”其实是一个极富挑战的隐性特征,如果更新不及时,就会导致因果分析过时或不准确。
-
对高噪音短文本的处理策略
- 推特数据通常简短且含有网络用语,很多词不在常见词典中。
- 作者虽然提及预处理,但其中文本分词、拼写校正策略如何实现,可能是另一大隐性特征。若分词错误,会影响后面整个抽取与检索流程。
-
因果推理的上下文长度
- GPT-3.5 Turbo 有输入Token限制,如果检索到的上下文过长,需要截断/摘要。截断又会影响因果推理的完整性。
- 这是一种隐性平衡:如何在可行的Token范围内保留最有价值信息。
六、方法的潜在局限性
-
依赖图构建的质量
- 如果抽取关系不准确,或节点间时序属性不正确,会直接影响因果推理的质量。
- 尤其对于海量推文,自动关系抽取错误率难以避免。
-
Node2Vec 等嵌入更新的实时性
- 当推文数据不断涌入,Node2Vec 需要定期重跑或增量更新。大规模图的增量嵌入并不简单,如果更新滞后,检索结果可能不反映最新动态。
-
LLM 可能仍产生幻觉式回答
- 虽然通过RAG显著减少了无根据生成,但并不能保证100%避免LLM的“幻觉”。尤其若检索内容本身存在错误或与主题相关度不高,生成答案仍可能失真。
-
领域通用性
- 该方法在社交媒体因果分析中表现出色,但移植到其他领域(例如专业医学、金融等)时,需要构建对应领域的KG、关系抽取模型,成本较高。
-
计算成本
- 抽取、构建图谱、Node2Vec、检索和LLM推理,都有一定算力和存储要求。在极大规模数据下,可能存在性能瓶颈或开销过高的问题。
总结
-
解法拆解与子解法对应特征
- 数据预处理(去噪+时序)
- KG构建(结构化+可解释)
- 语义检索(图嵌入+文本嵌入)
- LLM生成(自然语言推理+可追溯)
-
隐性方法与隐性特征
- 时序信息的融合策略、相似度阈值设置、结果回溯与证据呈现等,都属于容易被忽略却关键的技术点。
-
潜在局限性
- 主要包括关系抽取质量、动态更新困难、LLM“幻觉”、跨领域适用性有限和计算成本高等。
提问
1. 为什么论文中要在构建知识图谱时保留时间戳信息?仅仅依赖 Node2Vec 的结构特性不足以捕获时序吗?
答:
- 因果推理往往对事件的先后顺序十分依赖。若只靠 Node2Vec 进行结构化嵌入,它主要捕捉节点在图中的邻域与拓扑,但并未显式保留事件之间的时间先后关系。
- 论文强调在边或节点属性中加入时间戳信息,既能在检索(RAG)时约束时间范围,也能让最终的因果分析更具可信度与可追溯性。否则,两个节点之间的联系虽在结构上接近,但其事件可能并不具备先后顺序,也就难以得出可靠的因果判断。
2. 为什么要为检索增强(RAG)设置相似度阈值(如 0.35),而不是直接保留所有潜在候选节点?
答:
- 如果没有相似度阈值,检索结果会包含大量与查询主题关系不大的节点,反而增加了噪音。
- 通过设定阈值,可以过滤掉与查询并无实质关联的节点,确保 GPT-3.5 Turbo 接收的上下文更精准。该数值是论文作者在实验中多次调试、对比产生的,兼顾了查全率与查准率的平衡。
3. 论文称使用 GPT-3.5 Turbo 模型进行因果推理时能够体现可解释性,但 LLM 仍可能出现“幻觉”式回答。作者如何保证引用的推文确实是真实语料?
答:
- 论文方法中,所有推文在存入 Neo4j 知识图谱时都附带了原始文本和对应时间戳。
- 当 GPT-3.5 Turbo 生成因果解释时,实际上是基于检索到的真实节点(或文本片段)进行推理;因为检索是使用余弦相似度 + Graph Embedding 的方式进行,所以带进来的上下文就是真实推文数据。
- 当然,这无法 100% 避免模型自发补充“幻觉”信息,但在回答中附上推文 ID 或引用链接,读者可回溯 Neo4j 数据库中的原始文本来交叉验证。
4. 论文提出的“可持续更新”知识图谱是否需要频繁重新运行 Node2Vec?如果实时性要求很高,这部分性能瓶颈如何解决?
答:
- 论文只在“未来工作”或“系统可扩展性”部分简要提及:为了保持图嵌入的准确性,需要定期或动态地更新 Node2Vec。
- 若是实时性极高的场景,作者也承认增量式的 Node2Vec 并非易事,需要更先进的在线图嵌入方法(如 Dynamic Node2Vec、GraphSAGE 等)。
- 当前论文只做了阶段性批处理,而不是完全实时更新,故在高频数据流下的性能瓶颈暂未全面解决。
5. 使用 LLaMa3 模型进行实体关系抽取时,论文是否深入比较了与其他关系抽取模型(如 spaCy 或 Stanford CoreNLP)的性能差异?
答:
- 论文仅在方法描述与实验部分提到采用了“solanaO/llama3-8b-sft-glora-re”这种特定微调版本来进行关系抽取,因为其在推文文本上的表现较好。
- 并没有系统性对比传统的 spaCy、CoreNLP 或其他最新关系抽取模型(如 GPT-4 模型内置的提取能力)。作者似乎把重点放在了整体框架,而非在抽取模型的对比上,这可能是后续研究的一大空间。
6. 论文实验中如何保证对于含有多语言的推文也能进行统一因果分析?Node2Vec 与 Sentence-BERT 是否对多语种做了专门适配?
答:
- 论文主要基于英文推文数据,对多语言并未做大量测试。
- Sentence-BERT 默认可以用于多语种,但效果往往依赖具体的多语言模型版本。论文并未专门提及多语言适配策略,也就意味着在多语言场景下,需要另行筛选或训练对应的 BERT 模型,否则效果可能会打折。
7. 对于某些高度浓缩或引申意义极强的推文(如政治讽刺、反讽、隐喻),论文中提及的三元组抽取流程是否足以捕获潜藏的因果关系?
答:
- 论文提到关系抽取主要依赖句法和实体层面,遇到高级修辞手法(比如反讽)可能失效。
- 作者在“局限性”与“未来工作”部分表示,这种复杂语义需要更精细的语义理解或上下文语境模型。简单的实体-关系抽取仍不足以保证准确度。所以对于深层次隐喻或带政治色彩的短语,KG 里可能出现不完整或误导的关系。
8. 是否存在“负因果”或“抑制效应”类关系?即某些事件非但不会导致效果,反而减轻或抑制其他事件,论文如何处理?
答:
- 论文主要讨论正向因果(X 导致 Y),但并没有专门区分“促进/抑制”等细分类型。
- 作者在研究中更多是捕捉“导致”或“引发”这类语义,尚未针对“负因果”做显式区分。若后续要细分正负因果,三元组构造时可能要加入更多关系标签(如“inhibits”、“reduces”等)。
9. PRAGyan 方法把 Node2Vec 嵌入与 Sentence-BERT 嵌入结合使用。若两者相似度计算结果相矛盾(一个高、一个低),论文如何做最后决策?
答:
- 论文中常用的做法是先用文本相似度(Sentence-BERT 余弦值)对大量候选进行初步过滤,再用图嵌入(Node2Vec)来评估局部拓扑相似度,取综合得分高者。
- 并没有明确提出一个加权方案或优先级策略,但可推测是先“文本相似”敲定候选,再根据图结构相似排序。若存在冲突,通常还是以语义文本匹配为主,因为最终的因果问题大多是关于文本含义。
10. 如果一条推文既可能导致 A 事件,也可能导致 B 事件,作者是否考虑过在 KG 中出现“一对多”甚至“多对多”的复杂关系?
答:
- 论文确实允许“一对多”关系,例如“口罩短缺”这个节点可以同时连接“价格上涨”和“恐慌蔓延”两个后继节点。
- Neo4j 图数据库原生支持任意数量的关系边,所以技术层面没问题。不过在抽取层面,需要 LLaMa3 或其他模型能识别多重关系,实际效果则依赖关系抽取的精度。
11. 论文在定量评价中采用 BLEU 和 Cosine 相似度作为核心指标,但这两种指标都无法完美衡量因果推理。为什么没有用 ROUGE、METEOR 或更专业的因果评价指标?
答:
- 作者承认 BLEU、Cosine 相似度只是较为通用的文本匹配及语义相似度指标,并非专为因果逻辑评估设计。
- 之所以选这两种,是因为它们比较成熟、实现简单,也能给出与人工答案的匹配度参考。更专业的因果推理指标(如因果图评估、结构方程模型检验等)可能过于复杂,不在此研究范围内。
12. 如何处理推文中的“幽默化”措辞或“讽刺反问”?论文的方法会不会因为文本的表面词汇而抽取到错误因果?
答:
- 这是论文列出的局限之一:对复杂语用(反问、笑话、讽刺)等缺乏深入理解。
- 关系抽取模型主要看句法和语义依存,遇到讽刺或反问时可能误判出与字面意思相反的关系。作者提出在未来可通过情感分析、讽刺检测等外部模块补强,但当前实验并未实现。
13. 用户在提出查询时,如果输入的关键词极其模糊(如“影响”,“状态”),RAG 能否提供高质量上下文?
答:
- 若查询过于宽泛,Sentence-BERT 编码出的语义向量可能与大量节点都有一定相似度,检索时就难以收敛。
- 论文建议在实际系统中引导用户输入更具体的问题,如“为什么口罩价格上涨导致恐慌?”之类,这样才更好检索到关联度高的节点。否则 RAG 在面对模糊词时依然可能给出宽泛或无关紧要的结果。
14. 当推文大规模增长后,Neo4j 数据库中的查询速度和 Node2Vec 的更新开销如何平衡?
答:
- 论文只做了 35k 条推文的数据规模测试,在这个量级下 Neo4j 查询和 Node2Vec 还算可控。
- 一旦数据量暴增到几百万甚至上亿条推文,则需要分布式图数据库或更高效的在线嵌入算法。作者在“未来工作”中指出,这会是系统扩展的一大挑战,但并没有给出详细解决方案。
15. 为什么没有采用更先进的大模型(如 GPT-4 或 Llama 2)来做最终生成,而是选 GPT-3.5 Turbo?
答:
- 论文撰写及实验时,GPT-3.5 Turbo 相对稳定且易用,API 也较成熟。
- 面向学术研究,GPT-4 当时尚未大规模开放或成本过高,作者基于 3.5 版本就能展示核心思路(RAG 与 KG 的结合)。
- 换成 GPT-4 也不会改变主要框架,只会在生成质量上或对复杂句的理解力上有所提升。
16. 为什么在知识图谱中要用三元组(entity-relation-entity)而不是五元组或更多元的结构?对时序因果关系会不会太简化?
答:
- 三元组是图数据建模的基础形式,易于存储、检索及嵌入。
- 若要表达更多属性(如时间、地点、情感极性),往往以“属性”的形式附在节点或边上,而不是改变核心三元组结构。
- 论文强调“时间”可以作为边属性留存,并不一定需要五元组来显式表示。简单三元组足够表达“谁-做了什么-对象是什么”,其它信息可放到属性里。
17. 论文中描述了一次定量实验中,PRAGyan 相比基线提升约 10% 的 BLEU 和相似度,这个 10% 是如何统计出来的?有无统计显著性检验?
答:
- 作者在论文中提到对 64 条“手动设计的因果查询”进行实验测量,统计平均 BLEU 得分和平均余弦相似度。
- 他们给出的“10%”是在平均值层面的提升,并未明确提供统计显著性(如 p-value)。这点可能是研究的简化处理,但在严格学术论文中往往会附带方差或显著性检验。
18. 在整合 KG 与文本检索时,是否可能因为语义嵌入导致“距离近就默认有关联”,但实际上缺乏实质因果证据?
答:
- 是的,这也是纯基于相似度检索的局限之一:相似度只能说二者在向量空间里“语义接近”,但不必然存在真正的因果关系。
- 论文强调通过知识图谱中的“边类型”来补充验证,如有“导致”或“引发”的关系标签才算因果,否则可能只是同一主题的上下文。
- 但毕竟自动关系抽取也有误差,并不能完全杜绝假阳性问题。
19. GPT-3.5 Turbo 在回答因果推理时,能否根据查询动态选择合适的检索路径,还是只做一次性的静态检索?
答:
- 论文里采用的 RAG 流程是“先检索后生成”,是一种一次性的静态检索。即先由 Sentence-BERT 做相似度筛选,再喂给 GPT-3.5 Turbo。
- 并没有实现更复杂的“多轮交互式检索”(如 GPT 先读一下,再决定需要什么补充信息,继续检索),所以依旧属于单轮检索—生成的范式。对极为复杂的问题可能存在不够灵活的情况。
20. 作者提到若要面向其他领域(例如金融风险分析、医疗诊断),需要重新构建对应领域的知识图谱。那如何保障在新领域中依旧能保持 10% 或更多的提升?
答:
- 不同领域对知识图谱建模的要求、概念层级、实体关系都不同,且关系抽取模型也需做行业文本的专门微调。
- 若能够保证抽取质量、图的完整度与文本语料足够,重复使用“Node2Vec+Sentence-BERT+LLM”思路依旧可行。能否维持 10% 以上的提升要看对照基线是什么,以及新领域的数据特征。作者并未承诺这个数字在各领域都普适,只是实验结果证明了在 COVID-19 推文数据集上的有效性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









