






RGAR:打通病历事实与文献概念,实时纠正与更新,在复杂症状交织病例中的渐进式推理
- 论文大纲
- 理解
- 解法
- 分析是否有隐性方法(不是书本上的方法 而是解法中的关键步骤)
- 分析是否有隐性特征(特征不在问题、条件中,而是解法的中间步骤)
- 方法可能存在哪些潜在的局限性?
- 提问
- 1. 如果外部医学知识库本身存在遗漏或过期信息,RGAR 框架该如何保证答案的准确性?
- 2. RGAR 反复迭代检索时,如何防止形成“知识回音室”(即越迭代越偏向某个错误方向的文献或假设)?
- 3. 与直接使用 GPT-3.5、GPT-4 等超大规模模型相比,RGAR 框架的优势究竟是什么?
- 4. 如果题目有大量算术推理需求(如慢性病用药剂量计算),RGAR 的多轮检索会不会反而干扰推理?
- 5. EHRNoteQA 数据集中,如何确保在提取事实性信息时不会侵犯患者隐私?RGAR 框架是否兼容隐私保护?
- 6. 多次迭代检索势必带来额外的计算负担,在实际医院系统里要如何平衡效率和准确度?
- 7. RGAR 把“事实知识”与“概念知识”区分得如此明确,但在某些交叉领域(如罕见病)里,事实与概念界限模糊,如何处理?
- 8. 论文中实验对比了 i-MedRAG、MedRAG 等方法,但为什么不对比基于检索的 Prompt Engineering(如 RePlug)?
- 9. 当 EHR 非常简短或根本没有多余信息(如只有体温、心率这种简报),RGAR 的 FKE 还能发挥作用吗?
- 10. 在获取概念知识的阶段,RGAR 使用了多查询生成,但如果生成的查询彼此矛盾或质量参差不齐,该如何处理?
- 11. 论文只讨论了多选题形式,若是问答型(Open-ended)或会话型任务,RGAR 还能直接适用吗?
- 12. 如果题目本身就提供了部分可选答案(例如 ABCD 选项),RGAR 在检索时要不要把这些选项也纳入检索关键词?
- 13. RGAR 在实验中默认检索多少篇文档?若外部知识库非常庞大,一轮检索就取 1,000 篇可行吗?
- 14. 采用 RGAR 的算法实现时,需要在训练阶段进行微调吗?还是完全零样本?
- 15. 如何评价 RGAR 中每一轮检索带来的增量?是否做过逐轮消融实验?
- 16. “事实提取(FKE)”在某些情况下是否可能误判?比如 EHR 中某些数值是旧数据或写错了,但 FKE 依然把它当真?
- 17. 当检索到的外部文献互相矛盾,比如一篇说要用特定抗生素,另一篇说不宜使用,会否造成输出混乱?
- 18. 作者是否对 RGAR 的“解释性”做过专门测评?还是只认为“有外部文献 = 解释性”?
- 19. 一些 RAG 方法会对检索到的文档做可视化可解释,比如高亮重要句子,RGAR 里有类似实现吗?
- 20. 作者提到要在真实医疗场景推广 RGAR,有没有对医生的工作流进行整合设计?还是仅停留在模型算法层面?
论文:RGAR: Recurrence Generation-augmented Retrieval for Factual-aware Medical Question Answering
论文大纲
├── 1 引言【描述背景和问题】
│ ├── 医疗领域需要精确问答【背景介绍】
│ ├── 大模型(LLMs)在医学问答中的潜在价值【技术应用】
│ └── 现有RAG方法的局限【问题描述】
│ ├── 对事实性知识(Factual Knowledge)的检索和利用不足【具体挑战】
│ ├── EHR(Electronic Health Records)中冗余信息多、有效提取难【具体挑战】
│ └── 检索到的概念性知识(Conceptual Knowledge)与患者实际病历缺乏交互【具体挑战】
├── 2 相关工作【文献综述】
│ ├── Retrieval-Augmented Generation(RAG)的发展脉络【研究进展】
│ │ ├── 早期检索:BM25、DPR等离散或稠密检索【传统方法】
│ │ └── 针对医疗领域的改进:MedRAG、MedCPT等【领域专用】
│ ├── Bloom’s Taxonomy在医学AI中的启发【理论基础】
│ │ ├── Factual与Conceptual知识在问题解答中的地位【知识分类】
│ │ └── Procedural与Metacognitive知识的重要性【高阶能力】
│ └── Generation-Augmented Retrieval(GAR)的查询优化策略【方法衍生】
├── 3 RGAR方法【核心方法】
│ ├── 3.1 任务定义【方法细节】
│ │ ├── 问题Q、病历F、答案候选A【输入要素】
│ │ └── 目标:从外部文本库检索并结合LLM生成最终答案【任务目标】
│ ├── 3.2 Conceptual Knowledge Retrieval (CKR)【检索阶段】
│ │ ├── 多查询生成与相似度计算【检索优化】
│ │ └── 平均相似度评分以获取候选文档【检索结果】
│ ├── 3.3 Factual Knowledge Extraction (FKE)【EHR提取阶段】
│ │ ├── 利用CKR知识指导EHR的精简过滤【EHR事实抽取】
│ │ └── 处理数值化指标和多跳信息【细节强化】
│ └── 3.4 循环管线(Recurrence Pipeline)【整体流程】
│ ├── 将抽取的事实与检索到的概念反复迭代【探索-利用循环】
│ ├── 新生成的事实信息继续完善检索query【动态更新】
│ └── 最终输出答案并保证可溯源【结果产出】
├── 4 实验设计与结果【实验验证】
│ ├── 4.1 数据集【实验数据】
│ │ ├── MedQA-USMLE、MedMCQA【专业考试题型】
│ │ ├── EHRNoteQA【包含真实EHR的复杂数据】
│ │ └── 不同数据规模和长度对检索的影响【现实挑战】
│ ├── 4.2 实验设置【实验流程】
│ │ ├── 检索器:MedCPT及Textbooks语料【检索环境】
│ │ ├── 基础LLM:Llama或Qwen系列【模型规模】
│ │ └── 评估指标:准确率为主,结合答案匹配【评测方式】
│ ├── 4.3 主要结果分析【实验结果】
│ │ ├── 对比Custom、CoT、RAG等方法的准确率【总体表现】
│ │ └── 对EHR数据越长时的性能优势【细分分析】
│ └── 4.4 消融实验与细粒度讨论【深入探讨】
│ ├── 去除CKR或FKE对性能的影响【组件贡献】
│ ├── 多轮(Rounds)循环对检索稳定性的提升【迭代收敛】
│ └── 大小不同的LLM效果对比【模型规模】
├── 5 结论【研究总结】
│ ├── RGAR框架的创新与提升【研究价值】
│ │ ├── 将Factual与Conceptual知识检索相结合【核心思路】
│ │ └── 通过循环管线强化事实抽取的准确性【方法亮点】
│ ├── 局限性与未来展望【未来方向】
│ │ ├── 自适应停止机制与更精细的多轮检索【可能改进】
│ │ └── 隐私与数据安全问题的对策【现实需求】
│ └── 对医学QA与临床决策的启示【学术与应用意义】
核心方法:
├── 3 RGAR方法【核心方法】
│ ├── 输入【问题Q、病历EHR、候选答案集A、知识库K】
│ │ ├── Q:用户提出的医疗问题【原始需求】
│ │ ├── EHR:包含患者病史、体检和检验指标等原始医疗数据【事实性数据】
│ │ ├── A:多选题形式或需要辨别的答案选项【候选输出】
│ │ └── K:医疗文本或医学文献库,用于支持外部知识检索【外部知识源】
│ ├── 3.1 任务定义【方法细节】
│ │ ├── 目标:从EHR中提取关键事实,并结合外部知识K,为Q找到正确答案【核心目标】
│ │ ├── 模型:采用LLM作为阅读器与生成器,理解并整合从EHR和K中检索到的信息【技术主体】
│ │ └── 多轮交互:允许LLM多次检索和抽取,不断修正和完善检索到的知识【迭代思路】
│ ├── 3.2 概念性知识检索 (CKR)【步骤1:检索外部知识】
│ │ ├── 多查询生成【技术方法】
│ │ │ ├── 使用LLM对原始问题Q进行多种形式的扩展(如生成可能的标题、选项、上下文)【多视角提问】
│ │ │ └── 通过相似度打分,将多个查询的检索结果综合,提升检索稳定性【检索融合】
│ │ ├── 与知识库K交互【衔接】
│ │ │ ├── 采用MedCPT或其他密集检索器,将上述生成的查询向量与K中的文档向量比较【向量检索】
│ │ │ └── 选出最相关的若干文档,提供给LLM进一步分析【知识支撑】
│ │ └── 目的:获得问题背后的通用医学概念和原理,为后续EHR处理打下基础【概念补充】
│ ├── 3.3 事实性知识抽取 (FKE)【步骤2:精简EHR】
│ │ ├── 结合CKR结果【衔接】
│ │ │ ├── 用已检索到的概念性知识,来定位EHR中真正与问题Q相关的事实【知识对齐】
│ │ │ └── 特别关注数值指标、症状体征等关键细节【事实提取】
│ │ ├── LLM抽取器【技术方法】
│ │ │ ├── 对EHR做段落或句子级的切分,让模型找出与Q最相关的关键句/短语【信息过滤】
│ │ │ └── 若有多跳推理需求,则用概念知识再次辅助,形成新的事实描述【多跳整合】
│ │ └── 输出:产生一个提炼后的EHR事实列表Fe,用于下一步或最终答案【中间产物】
│ ├── 3.4 循环管线 (Recurrence Pipeline)【步骤3:迭代衔接】
│ │ ├── 基本思路:利用FKE中生成的Fe更新原始查询Q,形成Qᵇ=Q⊕Fe【更新查询】
│ │ ├── 返回CKR阶段【衔接】
│ │ │ ├── 重复使用多查询生成和检索过程,但此时输入是新的Qᵇ【动态优化】
│ │ │ └── 获取更精确的概念性知识,补充或修正先前检索【知识迭代】
│ │ ├── 终止条件:当检索到的知识稳定或达到预设轮数,即可停止【循环停止】
│ │ └── 输出答案:将最终检索到的概念性知识、抽取的事实性知识与LLM推理结合,给出答案A*【最终结果】
│ └── 处理过程的衔接【整体流程】
│ ├── 输入Q/EHR/A/K → (1) CKR检索概念 → (2) FKE提取事实 → (3) 利用Fe更新查询 → 重复(1)(2) → 输出A*【主线】
│ └── 各步骤依赖:CKR向FKE提供概念指引,FKE向CKR反馈事实切片,共同喂给LLM进行答案推理【双向互动】
└── 输出【正确答案A*】
├── 经多轮循环后,模型在充分利用外部知识与EHR事实的条件下得出最终答案【准确性提升】
└── 同时可回溯到所用文档和提取的事实,增强透明度和可信度【可解释性】
理解
Why
在医疗领域,真实世界的临床场景往往需要对大量电子健康记录(EHR)以及庞大的医学文献进行综合分析,才能给出精准且可信的诊断或治疗建议。
然而,传统的问答系统或基于大型语言模型(LLM)的生成式模型,往往难以同时兼顾临床EHR中的关键信息与外部专业知识库中的概念性信息,导致答复缺乏准确的事实支撑或专业广度,从而无法充分满足真实医疗场景的需求。
- 先从真实需求和现实痛点出发:医学问答需要兼顾「患者个体差异」和「通用医学知识」。
- 观测与分析已有研究的不足:现有 RAG 方法多注重概念检索,容易忽略 EHR 中零碎且关键的事实部分。
- 假设可行的改进方案:如果对“事实”和“概念”实行双端检索与多次迭代,或许能提高模型在医学场景的表现。
场景背景:
一位 60 岁男性患者,反复咳嗽、发热,伴随轻度呼吸困难。医院的电子健康记录(EHR)里,除了基本症状描述之外,还有胸部 X 光结果、血氧饱和度、以往慢性病史(如糖尿病、慢性阻塞性肺疾病等)、过敏史、化验指标等大量细节。
另外,外部医学文献或知识库里还存有关于不同肺部感染病因、常见并发症及用药方案的权威解读和临床试验数据。
- 传统方法的局限(反例)
-
对 EHR 的冗长信息缺乏有效提炼
传统方法可能只是把医院记录整体输入检索或模型,模型由于冗长、无序的数据难以聚焦到“关键项”,例如并没有很好地捕捉到该患者同时患有糖尿病这一高风险因素。在诊断时,该关键信息被淹没在大量不相关的医疗数据之中。 -
无法充分结合外部医学概念
另一方面,模型也可能仅凭内部训练的“通用知识”来生成回答,并没有去检索外部最新或权威的临床治疗指南;结果对是否要根据患者糖尿病或慢性阻塞性肺病(COPD)特殊调整抗生素方案这一点不够敏感,给出的用药建议缺乏针对性,也难以解释为何选择该方案。 -
诊断准确性和可解释性受限
最终的诊断结果,既没有很好地利用糖尿病和 COPD 作为高危因素,也缺少对当前循证医学指南的参考,导致医生和患者都无法清晰理解“为什么选择这个方案”。如果出现治疗失效或严重副作用,追溯过程更困难。
- 结合外部概念与患者事实信息的改进(正例)
-
有效提炼 EHR 的关键事实
模型会先通过某种抽取机制,从 EHR 中提炼出最相关的要点:- 患者基础病:糖尿病、COPD
- 当前病征:呼吸困难、咳嗽、持续发热
- 检验指标:白细胞计数升高,血氧饱和度偏低
- 病人对某些抗生素过敏等
-
外部知识库检索与融合
然后,系统检索外部医学文献库,获取最新的“对于糖尿病合并 COPD 患者肺部感染的诊治要点”,或“抗生素选择应注意什么特殊事项”之类的专业共识及随机对照试验结果。 -
多次迭代,聚焦关键信息与指导意见
结合病人的具体过敏史、并发症和专业指南,模型能够迭代更新治疗方案建议:- 说明为什么需要先控制血糖水平;
- 解释选用特定抗生素的原因(例如该抗生素对糖尿病人群安全性较高,且对某些特殊病菌谱有效);
- 给出基于 COPD 病史的额外处理措施(如雾化吸入、避免诱发哮喘等)。
-
诊断的准确性和可解释性增强
得出的最终结论不仅指出了推荐的治疗药物方案,还可以追溯到哪篇权威文献、哪条临床试验数据支持这样的选择,医生和患者均能理解诊疗思路,从而对方案更有信心。
对比总结
-
传统方法
- 仅依赖 EHR 的“粗暴式”输入或模型固有知识,容易遗漏患者特殊情况;
- 诊断缺乏对外部新知识的支撑;
- 难以提供详实的解释。
-
结合 EHR 事实与外部概念的方法
- 能在多轮检索中提炼病历重点,同时引入最新或权威的医学文献;
- 针对患者特定情况定制化诊断,并给出可追溯的证据;
- 显著提高准确性和可解释性。
如同在这个肺部感染病例中,把患者具体病史和过敏史“筛出来”,再去医学知识库里查找最优治疗指南,这种“事实+概念”融合的策略,能更好地应对庞大且杂乱的医疗信息,为医生和患者提供更加可靠和易于信服的回答。
What
针对这一现实问题,本文提出了“RGAR”(Recurrence Generation-Augmented Retrieval)框架,核心在于区分并提取两类知识:来自患者EHR的事实性知识(Factual Knowledge)和来自大型医学文献或知识库的概念性知识(Conceptual Knowledge),并通过循环式交互迭代来强化二者的融合。
“搜索引擎+多次关键字精修”的模式,那RGAR相当于:先用大语言模型想出多个好关键词,搜索到一批文档;再用这些文档去对比你的本地材料(EHR),提炼其中真正需要的部分;最后合并二者结果,再更新关键词继续搜索,如此往复,直到找到满意答案。
实验结果表明,RGAR在多个多选医学问答数据集上均显著提高了模型的准确率,尤其在包含真实EHR的复杂数据集上效果更为突出。
How
- 前人研究的局限性:现有基于检索与生成相结合的RAG(Retrieval-Augmented Generation)方法,多数侧重概念性检索,较少对EHR等事实信息进行有效过滤和提取;同样,专注于EHR本身的研究往往忽视了外部概念知识对解题过程的补充。
- 创新方法/视角:RGAR首先将EHR和医学文献分别视为两大检索源,通过多查询生成(Generation-Augmented Retrieval)来检索到丰富的概念性信息;然后结合LLM对EHR进行定向抽取,精炼出对问题最相关的事实信息;再将事实与概念知识彼此交织、循环迭代,完善检索与推理过程,最终输出更加准确、可溯源的答案。
- 关键数据支持:在MedQA-USMLE、MedMCQA和EHRNoteQA等实际多选医学问答数据集上,与传统的RAG方法和其他改进方法相比,RGAR展现了更高平均准确率,特别在EHRNoteQA这种高真实度且数据冗长的场景中效果最为明显。
- 可能的反驳及应对:有人或许质疑多轮迭代检索是否会带来推断过度或耦合复杂度增加。为此,RGAR在实验中引入了最大轮数限制与多查询融合策略,保证了检索稳定性;同时,通过在不同规模LLM上测试,证实方法的泛化能力并不依赖于超大模型才能生效。
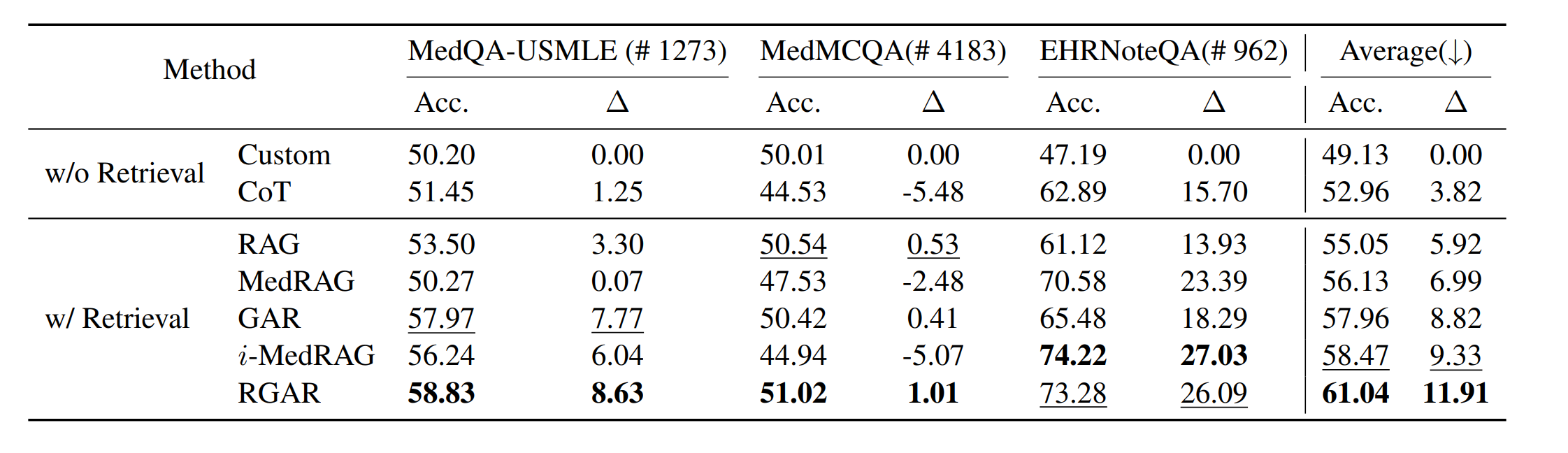
感觉 RAG 算法都怪怪的,这么复杂的工程,提升只有这么点。
How Good
本研究在理论上丰富了对检索式生成模型的理解,尤其是强调了事实与概念性知识交互的重要地位;在实践中,则为医疗问答与临床决策提供了一种可落地的技术路径,可在较小模型规模下依然保持较高准确率,并具备可溯源的优势,对医疗机构和相关技术研发都具有直接的启示与应用价值。
解法
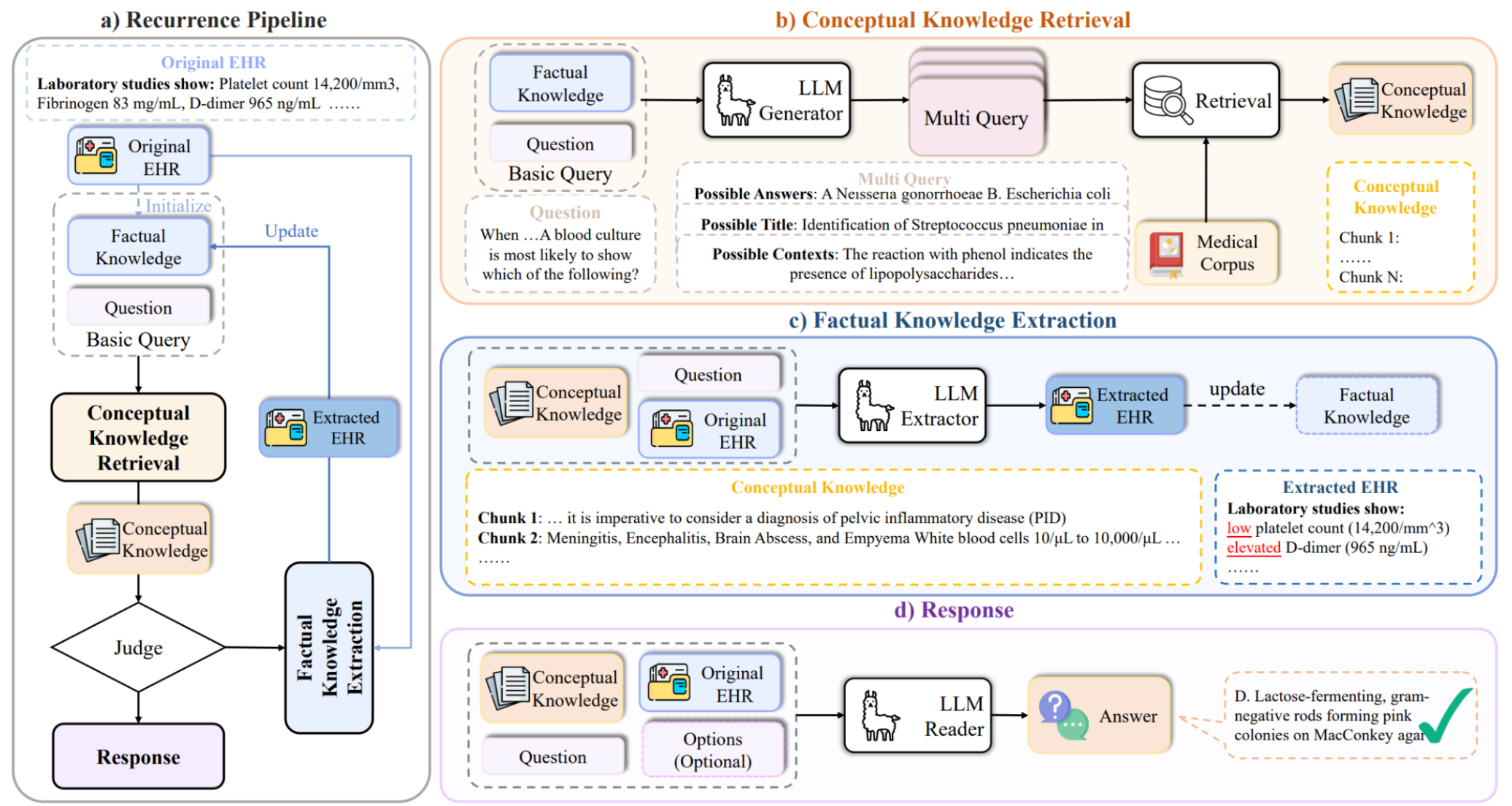
从这张图示可以看出,整套 RGAR(Recurrence Generation-Augmented Retrieval)框架按照 (a)(b)©(d) 四个部分来展示工作流程。下面逐一解析:
(a) Recurrence Pipeline
- 核心思路:展示了一个循环(Recurrence)式的流程,强调在获取问题(Question)及原始 EHR(病历)后,系统并不只是一轮检索或生成,而是反复迭代,令事实与概念不断交互、修正。
- 流程描述:
- Original EHR:最初的电子病历内容,包含关键数值(如血小板计数 14,200/mm³、纤维蛋白原 83 mg/mL、D-dimer 965 ng/mL 等)。
- Factual Knowledge + Question + Basic Query:将从 EHR 中提炼出的“事实性信息”与用户“问题”结合,形成“基础检索请求”。
- Conceptual Knowledge Retrieval:框架先去外部医学文献或知识库检索“概念性知识”。
- Judge:这里可视作对检索到的概念以及已有事实信息做一次判断或整合,若信息不足,可能再次更新 EHR 提取或检索请求;如果足够,就进入“Response”。
- Factual Knowledge Extraction:在有了概念辅助后,再次从 EHR 里抽取更精准的事实点,更新或纠正先前的事实知识。
迭代特性:图中 “Initialize” 与 “Update” 箭头表明,EHR 中的事实与检索到的概念往复交互,这正是 RGAR 的关键——不止一次检索,而是根据新的信息持续改进提问和提取。
(b) Conceptual Knowledge Retrieval
- 作用:获取“概念性知识”,如疾病原理、病原体特征、用药原则等,从外部医学文献(Medical Corpus)中补充信息。
- 过程:
- LLM Generator:利用大语言模型生成多种检索“提示”(Multi Query),包含可能的答案、标题、上下文等不同形式。
- Retrieval:对这些检索提示做相似度匹配,找到与问题最相关的一批文档(即“Conceptual Knowledge Chunk 1 … Chunk N”)。
- Multi Query 的目的是在一次检索中,通过不同角度或不同关键词来避免遗漏关键信息。
© Factual Knowledge Extraction
- 目标:从 EHR 这样长文本、冗余信息多的文档中,抽取与当前问题相关的事实部分。
- 过程:
- LLM Extractor:大语言模型以“Extractor”身份,对 EHR 中的段落或句子做筛选、摘要。
- 整合“Conceptual Knowledge” + “Question”: 有了概念提示后,可指引模型在 EHR 里找特定实验数值、病史线索等。
- Extracted EHR:产出“精简后的关键事实”。图中标注了“low platelet count (14,200/mm^3)”、“elevated D-dimer (965 ng/mL)”等要点,即提炼出更准确和更有用的信息。
(d) Response
- 最终输出阶段:
- 将“Conceptual Knowledge”(外部检索到的概念)与“Extracted EHR”(患者事实)和提问合并。
- LLM Reader:此时大语言模型扮演回答者的角色,整合所有知识给出最终回答。
- 图中例子表明答案是 “D. Lactose-fermenting, gram-negative rods forming pink colonies on MacConkey agar”,表明检索和事实综合之后,判断最可能的病原体性质。
其他要点
-
递归/循环结构:
- (a) 部分展示的“Recurrence Pipeline”是整张图最突出的设计,强调“多轮检索 + 多轮事实提炼”的思路。
-
多查询生成:
- (b) 部分详细解释了“大语言模型”如何从一次问题中派生出多种检索关键词(可能答案、可能标题、可能上下文等),形成多重视角。
-
事实 vs. 概念:
- © 部分突出了在 EHR 中拿到具体化验数值,结合 (b) 的文献知识辅助解读,共同支撑最终诊断或回答。
-
可解释性:
- (d) 部分最终生成的答案可直接对应前面的“被检索到的文档”和“EHR 中的指标”,在临床上更具说服力和可溯源性。
总结:
这张图将 RGAR 的核心流程(即先做“概念检索”,再做“事实抽取”,并且在多轮循环中不断完善检索与提问)分成四个板块,展示了从最初的长文本病历到生成清晰、有依据的医学答案的全过程。它突出的是“递归式结构”与“区分事实/概念双端检索”的思路,能在医学问答和诊断场景中显著提升准确性、可溯源性以及对复杂病历的利用效率。

RGAR
├── 子解法1:CKR(概念检索)
│ ├── 多查询生成
│ └── 文献相似度匹配
│
├── 子解法2:FKE(事实抽取)
│ ├── EHR关键片段定位
│ └── 事实性摘要或过滤
│
└── 子解法3:Recurrence Pipeline(循环迭代)
├── 更新查询
└── 重新检索 + 新一轮FKE
└── … (循环)
分析是否有隐性方法(不是书本上的方法 而是解法中的关键步骤)
潜在的隐性方法
-
多查询融合
- 表面上只是“生成多个查询”,但其实有个“融合排名”的过程:对多个查询的检索结果进行综合打分,并把高分文档再合并给模型。这一步在论文中常被简单一笔带过,但在实现时相当关键。
- 定义为关键方法:
- 方法名:多查询融合(Multi-Query Fusion)
- 隐性特征:在子解法 CKR 内部,不仅生成多条查询,还需要把它们检索到的结果统一排序/合并,才能更好地覆盖可能的解答。
-
LLM 抽取器对 EHR 的自适应切分
- 许多时候,EHR 不会天然分段,还可能包含大量数值,需要一个对长文档做“自适应切分与摘要”的过程。作者在文中使用 LLM 来提取关键句或段落,这是一种隐性中间步骤。
- 定义为关键方法:
- 方法名:自适应切分与摘要(Adaptive EHR Splitting)
- 隐性特征:这是在 FKE 里的一系列子步骤,论文可能只描述“提取事实信息”,但实际实现需让 LLM 动态决定如何分割和忽略哪些信息。
分析是否有隐性特征(特征不在问题、条件中,而是解法的中间步骤)
在 RGAR 的实际流程中,的确存在一些“隐性特征”,例如:
-
迭代时的查询噪声抑制:当某一轮检索引入较多噪声时,需要在下一轮中根据失败经验进行“噪声过滤”或放弃某些检索路径。
- 这往往是几个步骤的组合:上轮检索结果得分过低 → LLM 识别噪音文档 → 更新查询时自动去掉相关词汇。
- 论文一般不会专门定义这种“噪声抑制”方法,但它对迭代过程非常重要,可视为隐性的中间特征/关键步骤。
-
事实和概念相互映射:并非直接在文中写“我做了一个概念-事实映射模块”,而是通过让 LLM 在回答 EHR 细节时引入外部文献,形成关联。
- 这也属于隐性步骤:既不是纯检索,也不是纯生成,而是让 LLM 内部将概念知识与 EHR 内容映射到相同的语义空间。
若将这些“隐性步骤”视为可显式化的关键方法,也能更好地理解 RGAR 在实践中的运作机制。
方法可能存在哪些潜在的局限性?
-
运算和时间成本
- 多轮检索意味着更多次的向量检索与 LLM 调用,计算开销和时间延迟都会上升,不一定适用于在线或实时要求非常高的场景。
-
对大模型能力的依赖
- RGAR 中“多查询生成”“自适应切分”等步骤高度依赖 LLM 的生成质量。若基础大模型不够强,生成出来的查询或抽取结果可能不准确、甚至混乱。
-
算术或逻辑推理的冲突
- 论文里也提到过,对算术占比高的问题(如复杂公式推导)时,检索过多外部文本可能会干扰模型内部算术推理。
-
隐私与安全性
- EHR 数据涉及患者隐私,若要把这些数据上传给云端 LLM,需要严格的隐私保护措施。这个在实际部署中也是一个大障碍。
-
缺乏动态停止机制
- RGAR 提倡多轮迭代,但具体迭代多少次较为合适?目前大多是预设轮数或简单阈值;可能出现要么过多迭代造成资源浪费,要么过少迭代导致信息不全的情况。
提问
1. 如果外部医学知识库本身存在遗漏或过期信息,RGAR 框架该如何保证答案的准确性?
答:
- RGAR 使用的是“检索 + 生成”的思路,但如果知识库本身不全或信息过时,框架仍会受到源头数据的限制。
- 论文中建议定期更新或维护“可信任的医学数据库”,并在回答时可溯源检索到的文档。
- 若外部知识库严重缺失,框架可能给出不完整甚至错误答案,需要专家或附加验证机制做最后把关。
2. RGAR 反复迭代检索时,如何防止形成“知识回音室”(即越迭代越偏向某个错误方向的文献或假设)?
答:
- 作者在实验中通过多查询融合、在每一轮都“合并多个查询结果”来缓解单一视角导致的偏差。
- 如果某次检索大幅偏离,可在下轮根据质量度或相似度剔除“噪音”文档。
- 理想情况还是需要引入一定的“负反馈”或随机扰动机制,避免单一路径越走越偏。
3. 与直接使用 GPT-3.5、GPT-4 等超大规模模型相比,RGAR 框架的优势究竟是什么?
答:
- 无论 GPT-3.5 还是 GPT-4,都存在潜在的“幻觉(hallucination)”问题,以及对最新或细分领域知识的不足。
- RGAR 强调可溯源的“外部检索”,让回答能对具体文档或证据负责。
- 在中小模型中尤其明显:RGAR 可让相对较小参数模型达到接近或超越更大模型的效果。
4. 如果题目有大量算术推理需求(如慢性病用药剂量计算),RGAR 的多轮检索会不会反而干扰推理?
答:
- 论文作者也提到“检索文本”在纯算术场景下未必提供帮助,甚至会干扰大语言模型原本的算术能力。
- 他们建议在算术占比特别高的题目中减少无关文献的干扰,或在框架内加入专门的算术推理模块,以实现“检索”与“算术”并行而非相互冲突。
5. EHRNoteQA 数据集中,如何确保在提取事实性信息时不会侵犯患者隐私?RGAR 框架是否兼容隐私保护?
答:
- 原始 EHR 通常要先经过匿名化处理,去除个人可识别信息。
- RGAR 本身是“方法论”,部署时可以在本地或受控环境下完成检索与生成,避免将敏感数据发送到公共云端。
- 论文给出的只是框架思路,实际应用还需在系统架构中加入角色访问控制、数据脱敏等隐私保护机制。
6. 多次迭代检索势必带来额外的计算负担,在实际医院系统里要如何平衡效率和准确度?
答:
- 在实验中,作者往往设置 1~2 轮迭代就能提升大部分准确度;超过 3 轮收益递减且开销增大。
- 临床系统可以设定“最大迭代轮数”,或者根据初步推理满意度来自适应地决定是否继续迭代。
- 若对实时性要求极高,可牺牲部分检索深度,或预先针对常见病情缓存高频文献摘要。
7. RGAR 把“事实知识”与“概念知识”区分得如此明确,但在某些交叉领域(如罕见病)里,事实与概念界限模糊,如何处理?
答:
- 论文采取的策略是先将 EHR 明确标记为“患者个人信息”一类,而外部知识库则是“通用概念”一类。
- 交叉情境下,即便概念混杂,也仍可先把病历视为事实来源,从外部查到的说明视为概念来源。
- 如果某罕见病在 EHR 中出现众多未证实信息,仍需人工或其他系统来帮助判定哪些是事实、哪些是推断。
8. 论文中实验对比了 i-MedRAG、MedRAG 等方法,但为什么不对比基于检索的 Prompt Engineering(如 RePlug)?
答:
- 可能是因为作者在撰写时主要关注医疗领域已有的 RAG 方案,而 RePlug、RETRO 等方法相对更通用或刚出现。
- 并不代表 RGAR 不可与之对比,未来可做进一步扩展实验。
- 作者也指出 RGAR 的思想与其他高级 Prompt/检索优化方案并不冲突,二者可能兼容。
9. 当 EHR 非常简短或根本没有多余信息(如只有体温、心率这种简报),RGAR 的 FKE 还能发挥作用吗?
答:
- 若 EHR 本身就很短,FKE 提取层面价值有限,可以近似跳过或简化。
- 论文讨论过 MedQA-USMLE 一类短文本题:RGAR 确实也能用,但与原本 RAG 相比优越性不如在长 EHR 中明显。
- 该框架并不是强制每一环节都必用,属于可配置化思路。
10. 在获取概念知识的阶段,RGAR 使用了多查询生成,但如果生成的查询彼此矛盾或质量参差不齐,该如何处理?
答:
- 论文使用了相似度打分加平均的方式,把多查询检索到的结果综合排名,合并最相关的段落。
- 如果部分查询生成了荒诞或矛盾关键词,可以在事后排名环节中将相关检索分数做削减或直接排除。
- 这本质上需要大模型具备一定的“自我纠错”或“评估”能力,否则就要引入后处理规则。
11. 论文只讨论了多选题形式,若是问答型(Open-ended)或会话型任务,RGAR 还能直接适用吗?
答:
- 核心流程(检索概念 + 抽取事实 + 多轮迭代)对问答型、对话型任务仍有价值。
- 多选只是方便评测准确率;对话则需要额外的多轮交互处理,但思路相通。
- 一些后续研究已尝试把 RGAR 植入对话系统,用来回答患者咨询问题。
12. 如果题目本身就提供了部分可选答案(例如 ABCD 选项),RGAR 在检索时要不要把这些选项也纳入检索关键词?
答:
- 一种做法是先“option-free retrieval”,只针对题干和 EHR 检索外部文献,以免检索偏向某个选项。
- 另一种做法是将选项文字也嵌入查询,但要避免过多暗示检索器,从而导致带有偏见的检索结果。
- 论文在实现中,大多采用 option-free 的检索策略,减少选项对检索结果的干扰。
13. RGAR 在实验中默认检索多少篇文档?若外部知识库非常庞大,一轮检索就取 1,000 篇可行吗?
答:
- 论文提到一般取 32 篇左右(top-32)做后续处理。
- 如果一次性检索上千篇,计算量会激增,且很多文档可能重复或无关。
- 通过多次迭代,每次取少量 top 文档,结合后续筛选,更能保证质量与效率平衡。
14. 采用 RGAR 的算法实现时,需要在训练阶段进行微调吗?还是完全零样本?
答:
- 论文倾向于零样本 / 少样本策略,让大模型直接执行“生成多查询+检索+回答”流程。
- 如果有条件,也能微调 LLM,使其生成的查询更贴合医学场景;但在实验对比中,作者多是“prompt 级别”的实现。
15. 如何评价 RGAR 中每一轮检索带来的增量?是否做过逐轮消融实验?
答:
- 论文确实通过在 0~3 轮迭代的准确率做对比。
- 一般在第 1 轮到第 2 轮提升最明显,第 2~3 轮略有提升或趋于稳定,第 3 轮之后往往出现计算代价过高且收益有限的情况。
- 消融实验表明,完全不用迭代时性能比使用迭代要差 5~10%(在 EHRNoteQA 上)。
16. “事实提取(FKE)”在某些情况下是否可能误判?比如 EHR 中某些数值是旧数据或写错了,但 FKE 依然把它当真?
答:
- FKE 只是自动化过滤与抽取,对 EHR 正确性不做校验。若 EHR 本身有错误或时间错配,可能会导致模型推断也出错。
- 实际应用中,最好在 EHR 数据里添加“时间戳”、“最新记录”标记或人工核验,框架本身很难处理真实世界各种数据差错。
17. 当检索到的外部文献互相矛盾,比如一篇说要用特定抗生素,另一篇说不宜使用,会否造成输出混乱?
答:
- 多篇文献彼此冲突是医学知识库中可能存在的现象。
- RGAR 目前没明确讨论如何自动仲裁矛盾文献。它仅把检索结果呈现给 LLM,让 LLM 综合决策。
- 理想情况要么由专家标注文献可信度,要么引入更多指示(如文献出处、年份、权威程度)辅助模型判断。
18. 作者是否对 RGAR 的“解释性”做过专门测评?还是只认为“有外部文献 = 解释性”?
答:
- 作者在实验中主要关注正确率提升及引用文档可追溯性,把可追溯视作“解释性”体现之一。
- 并未在论文中对“解释性”有更深入的测评,比如是否读者能真正理解推理过程。
- 这算是后续可以研究的方向。
19. 一些 RAG 方法会对检索到的文档做可视化可解释,比如高亮重要句子,RGAR 里有类似实现吗?
答:
- 论文中并未详细演示可视化,但提到可以将最终选中段落与 EHR 关键值做合并输出。
- 这是一个前端展示层的问题,理论上很容易实现,比如自动标注被大模型采纳的证据句子。
- 目前作者更多关注框架的核心机制和准确率,不是 UI 层面的可视化。
20. 作者提到要在真实医疗场景推广 RGAR,有没有对医生的工作流进行整合设计?还是仅停留在模型算法层面?
答:
- 主要还是算法层面的设计,尚未系统对接到医院电子病历系统、医生诊疗流程中。
- 作者认为 RGAR 要上线,需要更多配合,如安全审核、隐私协议、医生可操作界面等。
- 论文结尾也点出未来工作:要让 RGAR 更贴近临床使用场景时,必须与 EHR 平台以及医师决策流程实现无缝整合。
总结:
这些刁难问题主要围绕 RGAR 的各个环节(多轮检索机制、FKE、CKR、隐私安全、算术推理等)以及与真实医疗应用的结合方式。答案大多基于论文相关描述、结合一般学术或实践常识给出简要说明,帮助更全面地理解作者在开发 RGAR 时所面临的挑战与潜在改进空间。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









