







论文:Retrieval-augmented systems can be dangerous medical communicators
代码:https://github.com/rayarxti/rag-medical-communicator/
-
核心主题
AI医疗问答陷阱:检索增强系统虽然引用了来源,但仍可能误导患者。 -
研究背景与重要发现:
- 即使AI给出的每个字都正确,也可能误导患者。
- 检索增强生成(RAG)系统无法自动避免医疗回答中的误导问题。
- 目前系统回答普遍存在语境缺失、遗漏关键信息,以及强化患者偏见等现象。
- 论文的创新贡献:
- 首次提出以沟通语用学为基础框架,加强对上下文的深度理解。
- 强调提高AI医疗问答系统的安全性,降低患者误解风险。
论文大纲
├── 1 引言【检索增强式系统在医疗信息中的应用背景】
│ ├── 患者长期以来依赖在线医疗信息【背景现状】
│ ├── 生成式AI在搜索引擎中的普及【技术趋势】
│ └── 检索增强生成(RAG)潜在的误导性【问题提出】
│
├── 2 大规模数据分析【方法与结果】
│ ├── 2.1 研究方法【对Google AI Overview与Perplexity AI的实验】
│ │ ├── 查询类型设计【争议性诊断/手术安全/并发症等】
│ │ ├── 采样与标注方式【LLM判定响应误导特征】
│ │ └── 临床医生反馈【真实场景医疗搜索需求】
│ └── 2.2 结果【检索增强式回答中的主要问题】
│ ├── 不同查询间的显著差异【安全 vs. 危险、争议性疾病等】
│ ├── 基于字面查询的倾向【忽视罕见率/益处等上下文】
│ └── 可能加剧焦虑与确认偏差【仅列不良后果】
│
├── 3 定性分析【RAG系统作为医疗交流工具的不足】
│ ├── 3.1 狭隘的字面解释【忽略患者深层意图】
│ │ └── 例:“症状搜索”与“默认疾病存在”导致误导
│ ├── 3.2 忽视并误示文献原意【不考虑来源文本的整体意图】
│ │ ├── 事实被断章取义【仅摘取部分片段】
│ │ └── 来源本身的动机被忽略【有偏见或陈旧的文献】
│ └── 3.3 缺乏后续影响的推理【不考虑患者行为及决策】
│ └── 在医学高风险情境中易产生严重后果【语言输出具行动导向】
│
├── 4 未来方向【构建更有效的医学交流模型】
│ ├── 4.1 理解患者查询的真正意图【从纯字面到真实需求】
│ ├── 4.2 结合文献意图与上下文【避免断章取义】
│ ├── 4.3 考虑输出语言的下游影响【帮助患者正确决策】
│ └── 4.4 融入形式语用学与认知科学【提升模型的“语用推理”能力】
│
├── 5 替代观点【只提供原始文献链接与其他思考】
│ ├── 5.1 直接提供可信原文【减少AI生成式总结的偏差】
│ ├── 5.2 考虑用户多样化需求【专业用户 vs. 普通患者】
│ └── 5.3 平衡信息可及性与误导风险【用户自治 vs. 模型干预】
│
└── 6 结论【权衡与展望】
├── 6.1 在线健康信息的利与弊【便利与误导并存】
├── 6.2 提升RAG模型在医学场景的安全沟通能力【临床意义】
└── 6.3 未来需跨学科合作与规范【让检索增强式模型更好服务医疗】
核心方法:
├── 核心方法【整体流程】
│
│ ├── 1. 输入【研究对象与数据来源】
│ │ ├── 医疗领域查询集【来自真实或模拟患者疑问】
│ │ │ ├── 争议性诊断【如“慢性莱姆病”、假想综合征等】【用于测试RAG对隐含前提的处理】
│ │ │ ├── 手术安全性【如“为什么某手术危险”或“为什么某手术安全”】【用于探索查询偏见】
│ │ │ └── 手术并发症【如“某手术的并发症有哪些”】【用于考察模型对风险的呈现方式】
│ │ ├── 检索增强式搜索引擎【Google AI Overview & Perplexity AI】
│ │ │ └── 自动生成回答并附带来源文献链接【提供可溯源文本】
│ │ └── 临床医生反馈【医学背景支持】
│ └──【保证查询设计贴近实际医疗场景】
│
│ ├── 2. 处理过程【从采集到分析的技术方法】
│ │ ├── 2.1 数据采集【抓取搜索引擎回答】
│ │ │ ├── 批量自动查询【利用上述模板生成关键词】
│ │ │ └── 系统化记录回答【包括引用链接与回答内容】
│ │ │ └──【为后续标注和统计分析做准备】
│ │ ├── 2.2 标注与评价【判断回答的误导性】
│ │ │ ├── GPT-4或同类LLM辅助标注【用于检测回答中的谬误或疏漏】
│ │ │ ├── 事先定义的误导标签【如“未说明争议”“只列风险无概率”】
│ │ │ └── 临床医生审阅【验证标注一致性】
│ │ │ └──【确保医疗专业性】
│ │ ├── 2.3 定量分析【统计与度量】
│ │ │ ├── 计算Jaccard相似度【比较同一主题下不同查询回答的交集】
│ │ │ ├── 统计出现频次【如是否标明罕见率、是否提到争议等】
│ │ │ └── 验证回答稳定性【不同时间点重复采集比对】
│ │ └── 2.4 定性分析【从语用与认知角度剖析】
│ ├── 语用学视角【关注模型如何对用户“隐含需求”作答】
│ ├── 文本上下文解读【是否断章取义、是否忽略关键段落】
│ └── 临床风险评估【回答可能导致的患者决策偏差】
│
│ └── 3. 输出【研究结果与洞察】
│ ├── 3.1 定量结论【基于统计指标】
│ │ ├── 回答误导占比【如“XX%未说明术式收益”】
│ │ └── 不同搜索场景差异【争议诊断与手术安全类回答的差异】
│ ├── 3.2 定性结论【问题归纳】
│ │ ├── 避免提及关键信息【模型忽略“某病尚无定论”等】
│ │ ├── 强化确认偏差【只呈现与查询匹配的观点】
│ │ └── 对罕见率缺乏量化描述【患者焦虑可能被放大】
│ ├── 3.3 失效案例与示例【典型错误展示】
│ │ └── 结合原文引用对比【揭示断章取义现象】
│ └── 3.4 未来改进建议【从技术和应用层面】
│ ├── 加强模型的“意图理解”【针对隐含问题进行补充解释】
│ ├── 显式标注文献偏向与时效性【防止过时/偏颇资料误导】
│ ├── 引入形式语用或认知推理【减少机械式回答】
│ └── 多学科协作与监管【医学、语言学、AI共同完善】
│
└── 关系描述
├── 【用于测试RAG对隐含前提的处理】说明“争议性诊断”查询的设计目的
├── 【保证查询设计贴近实际医疗场景】表示“临床医生反馈”在输入阶段的作用
├── 【为后续标注和统计分析做准备】说明数据采集中“系统化记录回答”的意义
├── 【用于检测回答中的谬误或疏漏】指明LLM辅助标注的功能
├── 【确保医疗专业性】代表临床医生审阅的专业把关
├── 【比较同一主题下不同查询回答的交集】阐释Jaccard相似度分析的目标
├── 【回答可能导致的患者决策偏差】表明定性分析的临床风险评估重点
├── 【揭示断章取义现象】说明失效案例与原文对比的价值
└── 【从技术和应用层面】表示改进建议涵盖范围
1. Why —— 研究要解决的现实问题
-
患者在线获取医疗信息的需求旺盛
- 患者不再仅依赖线下医生,越来越倾向在搜索引擎或聊天机器人上查询与健康相关的问题。
- 生成式AI(如大型语言模型)与搜索引擎结合后,为“医疗查询”场景带来便捷和高效。
-
检索增强式生成(RAG)模型在医疗场景下可能产生误导
- 尽管检索增强式生成可以引用外部文献,以期减少“幻觉”并提升可信度,但在实际应用中却出现了以字面“准确”而实则“误导”的回答。
- 医疗信息的高风险和复杂性,使得任何潜在误导都有可能导致错误决策、病情延误或医患冲突。
-
当前的RAG系统缺乏“人类沟通”与“语用推理”的考量
- 模型往往只满足字面需求,却忽视了上下文、患者真实意图,以及文献本身的完整含义。
- 如果不加以改进,RAG 有可能成为“危险的医疗传播者”,而非“高效的医疗信息助手”。
2. What —— 核心发现或论点
-
检索增强式搜索引擎的回答,会因「狭隘的字面解释」与「文献断章取义」而产生误导
- 在论文的实证研究中,针对“争议性诊断”“手术安全性”等查询,RAG经常仅呈现部分不良后果、忽视概率或证据不充分的负面信息,导致患者焦虑或确认偏差。
-
即使答案具备“来源链接”,也无法保证患者能正确理解原文
- 引文机制仅在表面上提供“可追溯性”,但若模型刻意或无意地选择、剪裁文献内容,病人仍可能得到片面的结论。
-
模型缺乏对「患者上下文」与「文献上下文」的整体理解
- 因为忽略了患者的潜在情绪、真正需求(例如:患者已经极度恐惧此手术),以及对文献真实性、适用性的判断,从而无法进行必要的补充说明或纠正。
3. How —— 研究方法、前人研究局限性、创新之处、数据支持和反驳应对
3.1 前人研究的局限性
-
仅关注“生成的准确性”或“是否带引用”,未关注对患者心理与解读的影响
- 之前的研究更多评价生成式模型的准确率或幻觉程度,而很少对「回答的实际误导程度」以及「患者阅读后的行动后果」进行纵深分析。
-
未充分量化或质化“检索内容的选择机制”
- 一些研究指出RAG的潜力,但对于“引用文献是否全面、是否与主题最契合”缺乏系统实证。
-
缺乏在真实场景(尤其是医学高风险场景)的大规模测试
- 过去评估多集中于一般知识问答或开放域任务,缺少对「争议性诊断、手术安全性、术后并发症」等重要医疗查询的细致研究。
3.2 创新方法 / 视角
-
以患者真实查询为出发点
- 论文收集了大量模拟真实患者可能问到的医疗问题(如“为什么手术危险”“症状查询”“争议性疾病”),并在两个实际RAG搜索引擎(Google AI Overview, Perplexity)中进行批量测试。
-
量化+质化结合
- 量化:统计回答中是否出现关键提醒信息(如稀有概率、手术收益/风险平衡、争议诊断的科研现状);比较不同查询结果之间的内容相似度。
- 质化:从语用学和医疗沟通的角度剖析回答的潜在误导性,分析为何即使引用权威网站也可能断章取义。
-
运用“人类沟通原则”与“语用推理”来解释并评估模型行为
- 不仅仅关注模型是否回答正确,而是考察“回答是否符合人类交谈中合理的合作原则”,例如完整呈现利弊、反映真实时效和多方证据。
3.3 关键数据支持
-
定量结果
- 不同类型查询下,约有 4%~10% 的回答会遗漏概率数据;仅少量回答明确“手术亦有高成功率”“争议诊断尚无定论”等重要信息。
- Jaccard 相似度测量表明:对于相同主题的正面(“安全”)与负面(“危险”)两种问法,模型可能提供截然不同、几乎无交集的引用内容。
-
定性案例
- 在展示的案例中,用户搜索“某手术是否危险”,多数回答只罗列风险而不提成功率或益处;而用户搜索“某手术是否安全”,则往往只给成功率及益处、不谈风险。
- 针对“争议性疾病”的“症状”查询,模型往往默认其真实存在,而忽视当前医学界并无共识的事实。
3.4 可能的反驳及应对
-
反驳:RAG 提供了来源链接,患者可以自行查看原文
- 应对:现实中患者常缺乏时间、专业知识与批判性思维去阅读并理解原文;断章取义的内容仍易强化偏见。
-
反驳:用户确实想了解负面或特定信息,模型只是在回答问题
- 应对:论文指出,临床实践中若只满足狭隘询问,反而可能加剧患者恐惧或延误就医,忽视人类正常沟通中的补充提醒和客观平衡。
-
反驳:医学领域中难免需要专业判断,AI 不是医生
- 应对:作者并不否认模型不是医生,但既然引入了检索增强式引擎,就应在设计上保障回答更符合安全沟通原则;不应以“AI 不是医生”来放松准确性和完整性的要求。
4. How good —— 研究的理论贡献和实践意义
-
理论贡献
- 拓展了对 RAG 的评价维度:从仅关注“引用能否减少幻觉”扩展到“回答是否可能误导、是否符合患者真实需求”等多维度。
- 将语用学与认知科学引入 RAG 评估:在高风险领域(医疗)里,单纯词向量相似或语法正确并不够,需要结合人类沟通、上下文意图来判定回答品质。
-
实践意义
- 为医疗搜索引擎和健康问答平台提供设计改进方向:如何在界面或模型中引入更多“纠偏”机制,如显式提醒、概率数据、正反证据综合,防止患者偏听偏信。
- 推动跨学科合作:需要将临床医学、语言学、信息检索、认知科学等专业知识相结合,确保回答不再是机械罗列文献片段,而是真正满足患者安全与信息完整性。
- 对其他高风险领域有借鉴意义:如法律、金融、公共政策等,同样适用类似的“检索增强+语用推理”思路,以避免对用户产生重大误导。
设计思路
0. 作者的元思路
作者在论文《Retrieval-augmented systems can be dangerous medical communicators》中,核心想做的是评估和揭示当前“检索增强式生成”(RAG)在医疗场景中可能带来的误导性风险。
他们并不仅仅罗列案例,而是采用了近似科学研究的基本流程:主动观察 → 提出假设 → 收集数据 → 分析验证。
在此过程中,作者还融入了语言学和认知科学的思路(如语用推理、上下文理解),用来解释“为什么同样的字面准确信息,却可能导致不同程度的误导”。
1. 作者如何进行“观察”(Observation)
-
关注“不寻常”的系统表现
- 作者注意到“检索增强式系统”并非单纯地提供更多引用就万事大吉,而是在一些场景(特别是医学场景)会表现出与预期相悖的现象:回答虽然引用了文献,看似权威,但反而容易让患者产生偏见或误解。
- 这些“不寻常”之处包括:
- 对手术风险只做片面描述,比如只提及可怕并发症却不提成功率。
- 对争议性疾病默认当作“确凿存在”。
- 对同一话题,若换用不同问法,系统可能给出完全相反的回答,且都声称“有来源”。
-
在意“变量”——不同问法导致明显差异
- 作者特别留意到:当只改变问题措辞(如“某手术为什么危险” vs. “某手术为什么安全”),系统却给出截然不同的文献片段及结论。
- 这是作者的关键信号:同一个手术本应有综合利弊,但系统一会儿只给“好消息”,一会儿只给“坏消息”,而且都算“引用”了某些文献。
- 这让作者判断,“检索增强”并不等于“客观全面”,而是会因字面查询偏见而选择性地展示信息。
-
专门留意“引用”是否真的帮到了用户
- 原本人们相信:只要模型带上引用来源,就能减少虚假信息或保证可信度。
- 然而作者观察到:即使看上去“有来源”的回答,也可能因为断章取义、选择性呈现,而仍旧误导患者。
- 作者敏锐地发现了一个大家没太注意的点:“引用”并不等于“上下文正确”。
2. 作者如何提出“假设”(Hypothesis)
基于上述观察,作者提出了几个核心猜想(假设)。这些假设反映了他们对于“系统误导”的可能成因或机理的思考。
-
假设 1:RAG 在医疗领域易产生“狭隘的字面解释”,忽略患者真正的需求与意图。
- 例如:病人搜“症状”,潜意识里是想知道“自己是否真的符合这个病”,但系统只陈列“病症清单”,不提其争议或诊断标准,从而强化了患者的误解。
-
假设 2:RAG 系统常常“以部分事实替代整体事实”,因为它会选取文献中与查询最匹配的片段,忽略更完整的上下文(如统计概率、反面证据、补充说明)。
-
假设 3:系统所附的“引用”并不能确保正确理解,尤其是当引用本身存在偏见、或文献尚有争议(旧文献、不权威来源、商业广告),患者依然容易被误导。
-
假设 4:这种“片面回答”或“断章取义”的倾向不仅是偶然,而是系统性存在的,尤其当用户查询含有某种“立场(安全/危险)”或“暗含前提(争议病症真实存在)”的关键词时。
3. 作者如何验证这些假设(Data & Verification)
为了检验以上猜想,作者采用了多步数据收集与分析:
-
设计多种真实医疗查询场景
- 比如:
- “为什么某手术危险” vs. “为什么某手术安全”
- “某个争议性疾病的症状” vs. “某个争议性疾病的争议”
- 这些对比式查询可以让作者捕捉到系统对关键词的敏感度,并从数据上衡量系统的回答是否存在显著偏差。
- 比如:
-
从两个 RAG 搜索引擎获取批量回答
- Google AI Overview 和 Perplexity AI
- 同一问题在不同引擎、不同时间点多次查询,记录并对结果进行对比。
-
量化分析
- 计算回答在引用文献方面的“Jaccard 相似度”,看不同问法得到的文献片段重叠度有多大。
- 结果显示:仅做一点点措辞修改,同主题的回答却常常截然不同,可见它们受查询偏见影响非常大。
- 统计回答是否标明并发症概率、是否说明治疗的收益、是否提及争议性本身等关键信息。
- 结果显示:大部分回答只呈现了偏颇片段,缺少额外平衡信息。
-
质性研究
- 将回答与原文献进行对比,找到断章取义或选择性引用的具体例子。
- 分析回答对患者心理可能产生的误导,如“只展示糟糕并发症”会加剧焦虑,“不提真实发生率”让人高估风险。
最终,作者利用这些定量与质性结果,验证了他们先前的假设:
- RAG 确有倾向只回应字面问题而忽略真实情境;
- 不同立场问法导致完全不同结论,且引用未必带来真正的客观性。
4. 作者的思路总结
- 主动观察:作者首先关注到 RAG 在医疗问答中“貌似权威却实际误导”的不寻常现象;
- 敏感于变量:重点比较“同主题、不同提问方式”引发回答差异这一“变量”;
- 提出假设:为何引用文献的系统仍会误导?是不是忽略上下文?是不是满足于片面信息?
- 验证假设:
- 批量收集从多个引擎获取回答;
- 量化回答差异与关键信息缺失度;
- 以质性分析佐证回答常常断章取义或片面呈现。
- 得出结论:现行 RAG 系统在医疗场景确有系统性风险,必须借助更深入的语用推理、信息筛选与人机交互设计,才能改进。
全流程分析
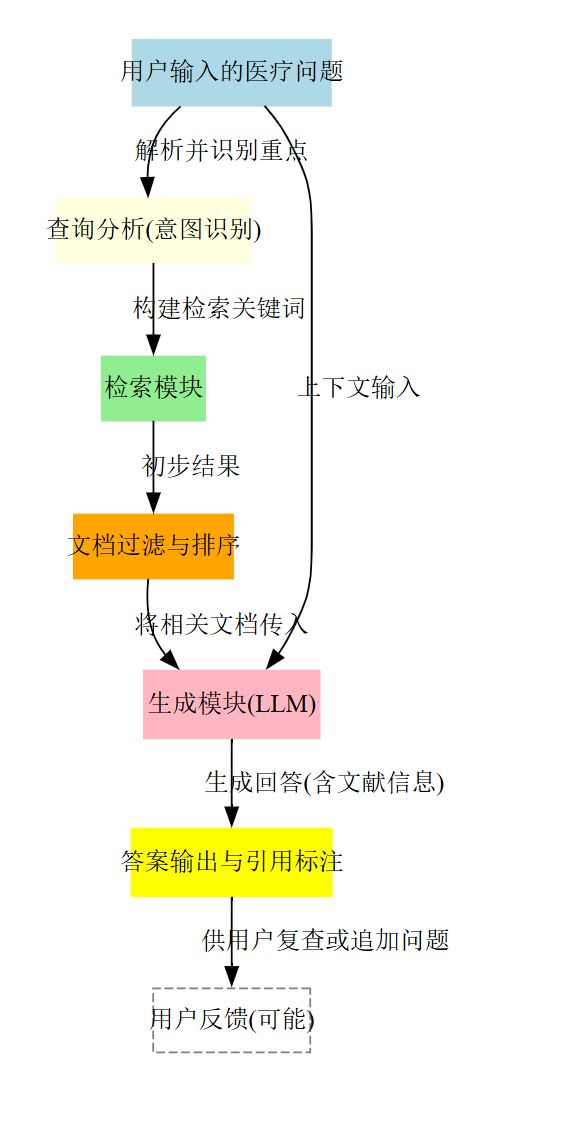
-
用户意图识别
- 输入:用户提出的医疗问题(如“为什么手术危险?”)
- 过程:
- 解析语言意图,判断用户是否存在隐含偏见(如焦虑、确认偏见)。
- 区分查询的字面含义和背后真实需求。
- 明确用户可能存在的误解或歧义。
-
文档检索(RAG特有步骤)
- 根据解析后的查询,搜索相关医学文献或来源文档。
- 初步获得潜在可用文献池。
-
文档质量评估与上下文识别(隐性关键步骤)
- 对检索到的文档进行质量评价:
- 权威性(是否权威机构发布?)
- 时效性(是否为最新研究?)
- 存在争议或冲突的文献标记。
- 对检索到的文档进行质量评价:
-
文献融合与回答生成
- 利用大型语言模型(LLM)将检索到的文档片段合并、改写、总结。
- 特别注意避免断章取义、片面引用,尤其是有统计概率或争议的数据时,应全面呈现上下文和完整统计背景。
-
答案输出与引用标注
- 明确标记文献来源(可追溯)。
- 在回答时加入必要的提示、警示信息,帮助患者合理判断风险或收益。
- 避免语言歧义,明确注
用户提问通常是有偏见的。
比如问大模型觉得自己得了某病,然后就只问那个病的检查,就会导致检查不全面。
解法拆解
1.1 解法的总体公式
令:
- (Q) 表示用户输入的查询(Query)。
- (K) 表示外部知识库或检索空间(Knowledge base)。
- (R(Q)) 表示检索模块对查询 (Q) 的检索结果集合(Relevant documents)。
- (G(\cdot)) 表示生成模块(一个大型语言模型, LLM)。
则检索增强式生成(RAG)的核心流程可写作一个简化公式:
RAG ( Q ) = G ( Q , R ( Q ) ) \text{RAG}(Q) = G\bigl(Q,\, R(Q)\bigr) RAG(Q)=G(Q,R(Q))
即:对输入查询 (Q) 进行检索,得到相关文档 (R(Q)),将这些文档与原查询一同送入生成模型 (G),生成最终回答。
- 与同类算法对比的主要区别:
- 传统纯生成式模型:(\text{Answer} = G(Q)),没有外部检索;
- 检索式问答:(\text{Answer} = \text{Select}(R(Q))),只做检索-匹配-摘录,缺乏语言模型的综合表达;
- RAG:(\text{Answer} = G(Q, R(Q))),同时具备检索能力和语言模型的综合生成能力。
1.2 解法拆解为更加具体的子解法
我们将 RAG 整体解法拆分成 4 个子解法(子步骤),每个子解法都对应某个需要重点关注的“特征”或“功能需求”。若只有一个特征对应一个子解法,就直接对应;若某特征需要两个子解法协同,就在相应子解法处说明。
(1)子解法 1:查询分析与构建(Query Understanding)
-
解法描述
对用户的初始输入 (Q) 进行预处理或理解,包括:- 分词、解析意图;
- 判断是否为医学高风险/争议性话题;
- 根据需要做同义词扩展、关键词提炼。
-
之所以用“查询分析”子解法,是因为“用户输入多样性特征”
- 医疗场景下,用户输入往往存在 措辞偏差(如“为什么手术危险” vs. “为什么手术安全”),还可能带有“隐含前提”或“错误认识”。
- 只有先理解查询特征,才能更好地匹配或检索到合适文档。
(2)子解法 2:检索模块(Retrieval)
-
解法描述
利用查询分析的结果,从外部知识库 (K) 中检索出与问题最相关的文档集合 (R(Q))。常见做法:- 向量检索(Embedding + 相似度搜索);
- 关键词检索(BM25 等传统信息检索算法);
- 综合排序(根据文献质量、日期等权重)。
-
之所以用“检索”子解法,是因为“外部知识动态性特征”
- 医学信息更新快,不能只靠模型内置参数,需要动态查询最新或最权威的临床文献或数据库。
- 检索阶段决定了后续生成的内容基础,若检索出偏颇、不权威或过时的文档,会影响回答质量。
(3)子解法 3:生成模块(Generation / Fusion)
-
解法描述
将检索到的文档 (R(Q)) 与查询 (Q) 一同作为输入,送入大型语言模型 (G),产生回答。关键环节包括:- 融合文档:对检索文档进行摘要或筛选;
- 语言生成:模型根据上下文来组织自然语言答案;
- 保留必要引用/证据:记录文档来源,准备好输出时标注。
-
之所以用“生成”子解法,是因为“回答需要综合性特征”
- 相对于简单的检索式问答,医学场景常需要将文献多段信息综合,再结合临床经验或指南,模型必须会“归纳/推理/串联”这些信息。
- 生成模块若只做机械拼接,仍可能导致断章取义,因此要格外注意“信息融合”的策略。
(4)子解法 4:引用与输出(Citing & Output Formatting)
-
解法描述
将生成好的文本回答与引用文档来源关联起来;给出可视化的引用链接或标号,便于用户查阅。可能包括:- 插入文献标注(如[1][2][3]);
- 简要描述来源可靠度(如是否为官方机构、研究论文);
- 提示用户咨询专业人士(因医疗场景风险高)。
-
之所以用“引用与输出”子解法,是因为“可追溯性特征”
- 医疗回答需要高信任度,若无来源,会让患者难以验证;
- 但作者也指出即使有引用,也可能产生误导,所以在输出阶段要特别注重“提示信息完整”,不能只给个链接了事。
1.3 子解法与特征对应关系总表
| 特征/需求 | 子解法 | 对应原因 |
|---|---|---|
| 用户输入多样性(隐含前提/偏见) | 子解法 1:查询分析 | 必须先理清问题意图,识别错误或争议前提 |
| 知识库外部性 & 动态更新 | 子解法 2:检索模块 | 需要实时从外部检索,保证时效性和权威性 |
| 需要综合多段信息、推理与总结 | 子解法 3:生成模块 | 单纯摘录不足,模型要进行文本整合、归纳、改写 |
| 可追溯性(信息来源、可信度评估) | 子解法 4:引用与输出 | 需要显式列出来源并指导用户查看,以提升可信度或让用户自行判断 |
如果某个子解法同时满足多个特征,就会合并在一个步骤中实现;但通常而言,每个特征集中对应一个关键步骤。
举个简短例子
- 用户输入:“为什么子宫切除手术特别危险?”
- 子解法 1(查询分析):系统识别到用户关键词“子宫切除”、“危险”。可能自动扩展到“子宫切除并发症”“手术安全率”等。
- 子解法 2(检索模块):在权威数据库检索,包括官方指南、临床统计资料、学术论文。
- 子解法 3(生成模块):将检索到的资料综合,用 LLM 生成回答,提到常见并发症发生率、手术益处与适用人群等。
- 子解法 4(引用与输出):在输出答案中附加文献链接或标注[1][2],并提示用户此数据来自临床试验报告 / 卫生组织官网。
2. 这些子解法的逻辑链:决策树形式
由于每一步都有先后顺序,但其中有条件判断(例如是否为已知高风险查询,需要补充更多文献?是否检索到可信来源?),可用决策树大致表示:
RAG 解法决策树
└── (1) 查询分析
├── 如果识别到高风险/争议话题,则引入额外安全校验
└── 否则进入常规检索
└── (2) 检索模块
├── 检索到足够权威文献?
│ ├── 是 -> (3) 生成模块
│ │ └── (4) 引用与输出
│ └── 否 -> 提示检索不足或尝试其他来源
这说明子解法整体是一个线性流+条件节点的混合:
- 先做查询分析;
- 决定检索策略;
- 若检索不充分则给出提示;
- 若检索成功则进入生成与引用输出的后续步骤。
3. 分析是否有隐性方法(逐行对比解法)
在以上四个子解法中,可能存在一些并未在书本或论文中明确指出,但实际上非常关键的“隐性方法”或“中间步骤”。下面我们来挖掘:
-
检索排序中的“文献质量评估”
- 很多实现仅仅做相似度排序,但在医学场景往往需要参考“文献层级”或“发表时间”。
- 这属于隐性关键步骤:不是所有 RAG 框架都会明说,却决定了检索结果优先级是否正确。
- 可定义为**“关键方法 A:文献元信息评估”**,它依赖一个“隐性特征”:文献的质量分级或时效性,这在表面上并未直接出现在“查询”或“生成”里,却在检索排序这一中间过程发挥重大作用。
-
生成模块中的“合并冲突信息”
- 当检索到多篇文献,可能存在结论冲突(如一篇说风险率为 1%,另一篇说是 5%)。
- 如何在回答里体现这些冲突、或至少提示用户?很多系统默认简单拼接,可能导致混淆。
- 这可视为隐性关键步骤:“冲突信息的融合策略”。若缺失,会让回答看似“引用全面”却实则不可读或误导。
-
引用与输出中的“可信度提示”
- 系统常只列出文献链接,但并不说明这是新闻报道、广告宣称还是严肃学术论文。
- 若在输出时额外标注“此处文献可信度:低/中/高”,就可帮助用户判断信息价值。
- 这属于**“关键方法 B:来源可信度标注”**,在论文中可能一笔带过,事实上是非常关键的隐性方法。
4. 分析是否有隐性特征
4.1 隐性特征:多步融合造成的误差累积
- 在“生成模块”里,系统常要逐段读取检索文本、再尝试总结。这种多步摘要融合过程中,若信息冲突或统计数据缺失,就会出现**“潜在歧义”**。
- 该歧义往往不是单一特征,而是多次摘要迭代综合造成的模糊,在结果里却反映为“回答不一致”。
- 这时我们需要定义一个新的关键方法——“多次融合的一致性检查”,并将其视为“隐性特征”引起的需求。
4.2 隐性特征:用户心理 & 认知负担
- 论文中提到,用户对医疗信息非常敏感,若回答“只列负面案例”易导致恐慌,若“只列正面”则过于乐观。
- 这其实是用户层面的隐性特征(心理反应),在解法步骤中并未显式定义,但若系统不考虑该特征,就会导致不平衡回答。
- 或者说,RAG 解法若能检测到用户可能焦虑,就要在输出时予以特殊说明——这是一种“隐性的人机交互策略”。
5. 方法可能存在哪些潜在的局限性?
-
检索内容本身的偏差
- 假设外部知识库包含不准确或有倾向性的信息,模型检索并引用后,仍会误导用户。
- 局限性:RAG 无法保证外部数据本身就是正确或公正的。
-
选择性引用与断章取义
- 虽然有引用,但模型如何摘取文献片段并融合?可能只选与查询最匹配、符合预设立场的句子。
- 局限性:用户问“危险”,系统就只呈现危险部分,没提及其他背景。
-
难以评估文献质量
- 在医学领域,需要考虑文献等级、循证医学证据分级、发表日期等。若缺乏严格的文献打分策略,就可能优先呈现质量低的文献。
- 局限性:这需要一套多维度的质量评估,现有 RAG 系统常常并未完善此功能。
-
模型自身的语言偏差
- LLM 对句子进行整合时,可能把“数值 1%”与“非常常见”混为一谈,给用户造成严重误导。
- 局限性:语言模型在量化表达上可能不准确,尤其面对医学概率数据时更容易出错。
-
没有考虑用户多样化水平
- 即便回答内容无误,若用户缺乏足够的医学常识或阅读能力,也可能产生误解。
- 局限性:系统缺乏个性化适配方案,难以“一句回答”同时兼顾专家和普通用户。
Q1
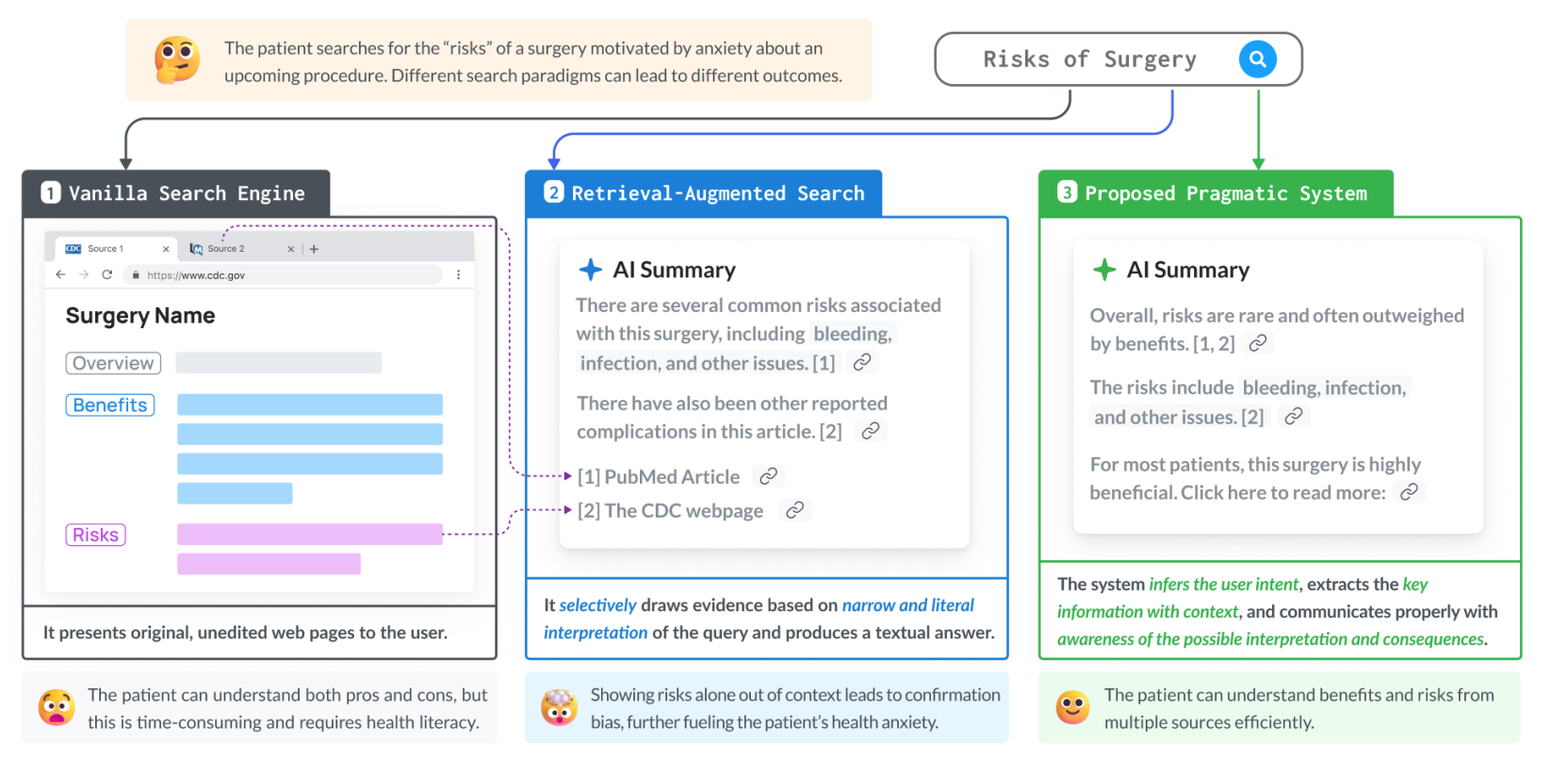
你们强调了检索增强式系统在医疗场景中容易产生误导,但如果“误导性”只体现在部分场景,而在大部分常见疾病或常规问题上并不显著呢?难道就凭一些极端案例,就要否定整个 RAG 模型的价值?
A1
我们并未否定 RAG 在大多数情况下的潜在价值。论文列举了特定医疗场景,尤其是高风险、争议性诊断、患者隐含恐惧的情境下,RAG 所带来的误导会显著放大。虽然并不意味着所有查询都同样受影响,但这些特例若处理不当,后果往往很严重。我们的研究初衷是提醒研究者和开发者不要因为 RAG“成功应对大多数简单问题”就掉以轻心,特别要针对高风险场景做额外防护。
Q2
如果有些用户偏要在检索增强式搜索引擎里寻找“离奇的医学阴谋论”或“民间偏方”,他们本身就带着强烈的主观偏见,结果检索出来的东西自然也会很偏激。这种情况下,究竟是模型的错,还是用户查询的问题?
A2
我们并非将全部责任都归咎于模型,而是指出当用户带着主观偏见搜索时,RAG 系统往往只做字面迎合,进而强化确认偏差。理想的医疗信息系统应有一定纠偏或提示机制,例如能识别明显的阴谋论,引导用户查看权威证据或官方声明,而不是一味呈现“与其关键词最匹配的内容”。所以我们关注的是如何让系统更好地应对用户的“异常”或“偏见”查询,而非将用户自身动机忽略不计。
Q3
你们的论文中用了很多条目的统计分析,比如出现罕见率统计的回答占比多少、提及手术益处的比率多少。这些统计方法在抽样和标注过程中会有误差吧?如果这些误差导致结果并不如你们声称的那么极端,该如何解释?
A3
任何大规模分析都可能存在抽样或标注偏差,因此我们采取了多次采集、跨平台测试、并结合临床医生反馈的方式来减少随机误差。我们并不声称结果“精确到小数点”,而是通过多维度量化+质性案例相结合,证明 RAG 在高风险医疗查询中确实存在“狭隘回答”或“忽略关键信息”的系统性倾向。即便数值有所波动,结论依然成立:某些回答模式在现有系统中过于普遍,需要改进。
Q4
你们提出要让 RAG 系统更具“语用推理”能力,但这听起来相当空泛。既没有提供清晰的技术指标,也没有具体算法实现。是不是只是提个概念就想把责任甩给后续研究者?
A4
我们在论文中已强调“语用推理”的重要性,并以人类交流中的“合作原则”和“对话意图”作参考,引导后续如何改进模型。确实,论文更多是从语言学与认知科学视角提出方向,而非给出完整技术框架。我们认为这是必要的第一步:先弄清问题和方向,再在技术实现方面与其他研究者或工程团队合作展开。在学术论文中,这种方法论层面的贡献也很常见。
Q5
你们一直强调要“避免断章取义”,可是在实际产品开发中,若要保证响应速度和简明易懂,势必要对文献进行摘取和精炼,这本身就是对原文有选择性引用。怎么平衡“简洁高效”与“完整上下文”?
A5
论文讨论的“断章取义”指的是误导性省略,尤其是导致读者形成与原文整体结论相反或偏离的理解。并不意味着所有摘取都不允许。实际上,适度摘要是必要的,但必须留意原文本关键的限制条件、适用范围、统计数据等不被随意抹去。我们建议给出适当引用链接和提示,让用户可在需要时查看完整原文,以便最大程度地维持信息可追溯。
Q6
如果某些权威机构或专业期刊之间本身存在结论冲突,RAG 模型检索到不同文献,难免出现“多头陈述”。你们希望系统如何处理互相矛盾的研究结论?难道系统要强行给用户“统一口径”?
A6
我们并不主张系统统一口径。相反,若确有多种相互冲突的研究结论,应坦诚呈现这些差异,并在输出回答中做必要的背景说明:例如指出某研究针对小样本、另一研究时间更长或数据更充分。医疗决策往往没有“唯一正确”的答案,透明化地呈现不同观点,让患者与医生共同讨论才更合理。
Q7
你们在论文中提出“患者可能被夸大的手术风险或不实的并发症描述吓到”,但同样有人担心如果系统把风险淡化了,患者就会掉以轻心。你们怎样平衡“医患恐惧”与“医患放松”这对矛盾?
A7
真正的平衡并非让系统淡化或夸大,而是呈现准确的统计概率与具体情境。人性化地进行解释,如“并发症发生率为 2%~5%,但大部分患者康复良好”,比简单的“很安全”或“很危险”更可信。关键在于给出相对数字与对照,且最好提示患者“仍需与专业医生沟通”,以免依赖 AI 回答自行决策。
Q8
如何区分“患者真实想要的核心信息”与“患者字面上提的问题”?万一有些患者就是只想知道风险,不关心其它信息,你们却强行给人家推好处,这是不是越俎代庖?
A8
我们认为在医疗场景下,即便患者只问了一面,也有伦理和安全层面的考量:过度顺从可能强化误解。正如医生面对病人时,若病人只问“手术伤口痛不痛”,医生也会主动提及术后护理和潜在感染风险。这并非越俎代庖,而是确保信息传达完整,减少决策失误。
Q9
你们主张引用“专业文献”,可是很多新兴健康网站、社交媒体上也有大量病友分享,带来了丰富而真实的一手经历。如果系统只认可主流医学期刊,是否会“忽视患者经验”,造成精英主义倾向?
A9
并非排斥患者经验分享——它们在某些病症互助中确有价值。但医疗风险高、专业门槛高的场景下,主流医学研究或临床指南具有更可靠的科学验证。患者经验可被补充呈现,但应清楚区分“个人经历”与“循证结论”,防止误导。我们建议在呈现患者经历时标注其非正式性质,以免用户混淆。
Q10
要真正减少误导,你们是否建议所有 RAG 在医疗场景的回答都要经过人工审核?如果是这样,那 RAG 的快速响应优势不就大大减弱吗?
A10
在高风险或涉及敏感医学决策的查询中,适度的人类审核或“后端质量检测”确实是一个可行思路。并非要求所有回答都人审,但可以针对特定关键词或疾病类别设置“高优先级审核”。效率和安全必须做平衡,因为医疗领域的容错率很低。若能通过自动化策略先过滤大部分简单场景,对疑似高风险场景再由人工审核,可能是更实用的折中方案。
Q11
你们的大规模定量调查结果,对搜索引擎厂商可能带来负面影响——毕竟他们的产品被指存在严重误导。作为研究者,你们有没有考虑到这样的批评会影响产业合作或外界信任?
A11
批评与指出问题本身是研究者的职责所在。我们并不想“唱衰”检索增强式系统,而是帮助行业看见潜在风险。与产业合作往往意味着要先找出缺陷,再共同改进。在学术层面,提出问题和优化建议是应尽之责,远比盲目吹捧技术要更能赢得长期信任。
Q12
你们提出多学科合作(语言学、认知科学、医学等)才能解决 RAG 误导问题,但这无异于“要啥学科都来”,听起来太笼统,谁来牵头?
A12
多学科交叉确实复杂,但医疗 AI 领域天生就具备“多方协作”属性:医学专家提供临床知识与验证标准,语言学家研究语用和对话结构,AI 工程师实现算法与系统。至于“由谁牵头”,我们倾向于大中型医疗/技术机构承担主要推动角色,并与学术界形成平台或项目联盟。这是一个需要多方参与、持续推进的过程,并非一蹴而就。
Q13
你们的论文多次引用现实中对搜索引擎回答的观察,但这些观察多数基于英文环境。若换成其他语言(如中文、西班牙语),RAG 的搜索与回答逻辑可能不同,能否保证同样成立?
A13
语言差异确会影响检索的可用文献规模、模型训练语料的差异等。我们强调的是一种通用风险:RAG 更易在偏见或带立场的查询里出现片面回答,这并不只限英语。无论是哪种语言,对话中若缺乏对上下文与受众意图的深层考虑,都可能出现误导性回答。所以我们认为其他语言环境只要具备相似的检索与生成机制,也难逃同样问题。
Q14
假如一个用户询问“请告诉我如何证明某疫苗无效”,系统就被你们指责成只给负面证据。可万一真有一部分用户是出于研究目的或想做辩论准备?你们是不是矫枉过正?
A14
如果用户确实想“研究反方观点”,没有问题。但系统本身不知道用户是想“辩论”还是“真的相信疫苗无效”。若系统只展示负面资料,会让一般用户更易形成偏见。我们希望的是系统能提供多元来源,说明疫苗领域存在怎样的证据和共识,既包括可能的负面案例,也包括正面大规模研究。这样才能避免单向误导。
Q15
医疗信息是瞬息万变的,有些文献几年前还是权威共识,现在可能已经被推翻。RAG 如何及时更新或避免过时信息?
A15
这是 RAG 的重大挑战。我们在论文中也提到:系统必须搭建定期更新的知识库,并在检索排序时考虑文献的时效性。若技术层面无法保证所有信息的实时更新,至少应标注文献的发表时间,提醒用户可能存在过期风险。理想状态是能不断增量更新数据库,并引入最新临床试验和指南,减少过时信息流通。
Q16
你们给出了很多改进建议,但若系统必须实现对文献的深度“上下文阅读”,技术难度势必大幅上升,势必需要更多算力和经费。这是否让小型研究机构或初创公司难以承担,从而阻碍创新?
A16
短期内,可能确实提高了开发与运营门槛。但安全与准确是医疗信息的首要任务,尤其在高风险应用场景下。如果让不具备充足资源的团队匆忙推出 RAG 医疗产品,导致误导性严重,那对公众健康更有潜在危害。我们并不想扼杀创新,而是要强调:医疗领域容错率很低,系统必须投入足够的资源做质量控制。
Q17
假设某些搜索引擎或技术公司声称“我们有严格的合规团队和隐私保护,可以避免你们论文中那些问题”。难道你们做的研究就被证明多余了吗?
A17
合规团队或隐私保护主要应对“数据安全”或“个人信息泄漏”等问题,而我们讨论的是系统回答中信息本身的误导风险。它与隐私保护或法律合规并非同一范畴。有些公司可能确有完善的审查机制,能减少错误回答,但我们见到的实际产品仍在多个场景失手。因此论文依然有启示意义,帮助识别系统性风险并提出改进方向。
Q18
你们担心的“危险沟通”是否有些言过其实?毕竟患者在真正做重大医疗决策前,还会去医院面诊,咨询医生。线上搜索只是做个参考。
A18
许多患者会根据网上的信息自行推断“我是不是得了什么病”,或决定“要不要去医院”,这可能造成延误就诊或过度恐慌。临床上医生也常遇到被网络错误信息洗脑的患者,反而更难沟通。线上信息虽是“参考”,却在现实中常被当作“先入为主”,所以“危险沟通”的后果不可轻视。
Q19
作者本身有医疗背景吗?如果不是医疗专业,你们的观点怎么保证真正适合医学界使用?
A19
我们的研究团队包含不同背景的作者,其中有与临床或医学信息学密切相关的成员,也有语言学与计算机科学研究者。即使团队个别成员不是医生,但我们在论文中也多次说明,与真正临床专家合作和验证,才能让研究结论更具医学适用性。论文的目标是警醒技术圈与医疗圈共同关注问题,而非只凭一方视角就下定论。
Q20
假如有人认为你们的论文只是“危言耸听”,现实里大多数搜索场景都很普通,没那么严重。能否用最短的话概括你们的核心立场,告诉怀疑者为什么要重视?
A20
最短概括:“医学信息牵涉生命健康,高风险场景容不得马虎。检索增强式回答如果忽视上下文、忽视患者真实需求,就可能放大误导,甚至酿成严重后果。” 这就是我们要呼吁大家警惕的关键。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









