







关心问题:2B-VL端侧小模型部署在医院、作为机器人大脑的性能,怎么提升?
想用 2B 参数做出医疗机器人智能大脑?
小模型不够强?大模型装不下?
公式级优化指南:一键掌控该用多大教师、多少数据,几步到位提升你的端侧AI
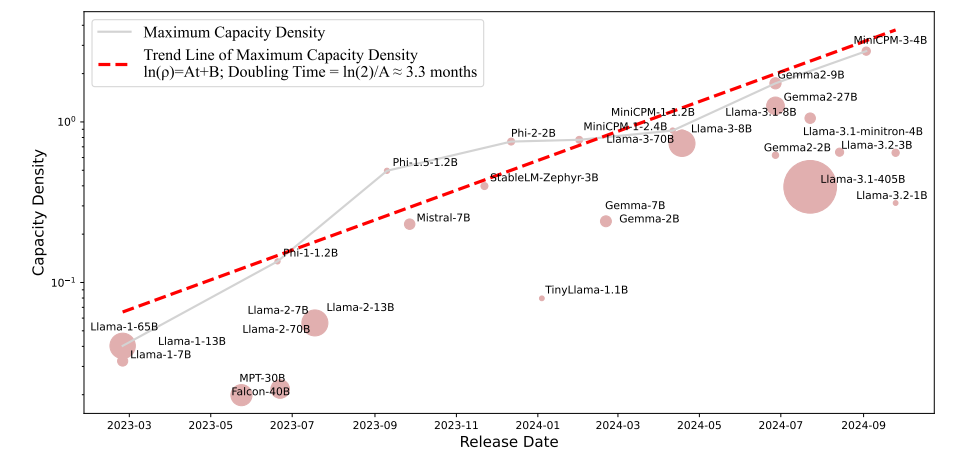
端侧小模型增长定律是怎么样的?
结论:每 3.3 个月(即 100 天)翻一倍。
什么才是蒸馏效果提升的关键?
论文:Distillation Scaling Laws(研究机构:苹果+牛津大学)
“蒸馏规模定律” 对我们做什么决策有帮助?
TA 能告诉我们在不同的计算预算和目标模型大小下,如何选择最优的教师规模、教师训练量和学生蒸馏量,从而以更低成本得到足够好的小模型。
问1:蒸馏规模定律的主要目的是什么?
-
在给定的算力或数据预算下,预测小模型(学生模型)的最佳训练配置,并估算它能达到的性能。
问2:这里提到“最佳训练配置”,具体指哪些方面?
-
包括学生模型的大小(参数量)、蒸馏所需的训练样本数量,以及教师模型的规模与教师的训练数据量。
-
Scaling Laws = 参数量 N、训练数据量 D、交叉熵 L 的幂律关系
问3:为什么学生模型要依赖一个教师模型?
-
因为在知识蒸馏中,教师模型会用自己的预测分布(logits)来“教”学生模型,让学生通过模仿教师输出来学习更深层次的特征或模式。
问4:教师模型的交叉熵 Lr 指什么?
-
TA 是教师在监督训练后,对真实数据集测得的损失,衡量教师对训练分布的拟合程度,数值越低说明教师越“强”。
问5:学生模型的交叉熵 Ls 又指什么?
-
在学生蒸馏完成后,用真实数据评估学生的预测分布,相对于正确标签的损失值,越低代表学生越能“学到”教师的能力。
数据 + 详细配置
├── 输入【确定研究对象与实验配置】│ ├── 教师模型参数 Nr 与训练数据 Dr【教师输入】│ │ ├── 来源:预先训练好的 Chinchilla-optimal 模型或其他规模模型【模型来源】│ │ └── 目标:提供教师预测分布与 logits,用于给学生模型做知识蒸馏【知识信号】│ ├── 学生模型参数 Ns【学生输入】│ │ ├── 范围:从小规模 (143M) 到大规模 (12.6B)【覆盖面】│ │ └── 作用:接收教师 logits,进行蒸馏训练【待蒸馏模型】│ └── 数据集与超参数【训练环境】│ ├── 数据集:英文 C4 的子集【语料来源】│ ├── 训练 tokens Ds【蒸馏数据数量】│ └── 超参数:基于 uP(simple) 及 MHA、RMSNorm 等设计【模型与训练细节】
-
学生模型:从 143M 到 12.6B 参数量的学生
-
教师模型:同样涵盖多种规模(从百万至数十亿参数)
-
训练数据:从数亿至数百亿 tokens。
-
在不同教师学生配比、不同 isoFLOP 训练策略、以及固定或变化的数据量等多维度上均进行对照实验,得到一致的结论。
蒸馏 + 详细步骤
├── 处理过程【构建蒸馏规模化规律的核心步骤】
│ ├── 4.1 实验设置【如何搭建实验】
│ │ ├── 使用 Maximal Update Parameterization(uP)【缩放策略】
│ │ │ └── [保证] 不同规模模型在学习率等超参数方面可直接迁移【稳定与可比性】
│ │ ├── 模型结构:基于 Gunter 等,结合 Pre-Normalization 与 RoPE【结构选型】
│ │ └── 训练细节:序列长度 4096、英语 C4 数据集、去重拆分【环境与数据】
│ ├── 4.2 蒸馏规模化规律实验【如何获取数据以拟合规律】
│ │ ├── 固定 M 的教师/学生 IsoFLOP 训练【实验一】
│ │ │ ├── [目的] 观测在相同总算力下,改变教师或学生规模的效果【多维度样本】
│ │ │ └── [输出] 学生的交叉熵随教师规模与 distillation tokens 的变化趋势【性能曲线】
│ │ ├── 固定 M 学生/教师 IsoFLOP 训练【实验二】
│ │ │ ├── [目的] 探索在教师计算受限时,不同教师大小对学生的影响【分离因子】
│ │ │ └── [输出] 学生跨越不同教师交叉熵 Lr 的表现【Lr 与 Ls 关系】
│ │ └── 固定 M 教师/固定 M 学生【实验三】
│ │ ├── [目的] 全面覆盖大小组合,展示“过犹不及”现象【对照实验】
│ │ └── [输出] 当教师模型性能超出学生可承载阈值时,学生性能反而下降【关键现象】
│ ├── 4.3 提出蒸馏规模化规律函数形式【理论建模】
│ │ ├── [假设] 学生交叉熵 Ls 依赖于学生自身(Ns, Ds)与教师交叉熵 Lr【核心依赖】
│ │ ├── [形式] 采用 Broken Power Law:在教师过强与适当区间间有转折点【两种幂律区段】
│ │ └── [解释] 当教师过强或学生过弱时,会出现“过犹不及”【效用转负】
│ └── 4.4 参数拟合与验证【得到最终公式】
│ ├── [方法] 将所有实验数据与模型参数 (Ns, Ds, Nr, Dr) 带入假设函数【回归拟合】
│ ├── [结果] 在 1% 误差范围内准确预测学生交叉熵【拟合效果】
│ └── [对比] 与监督学习幂律结果一致,交叉印证蒸馏与监督的差异【双重验证】
异常发现
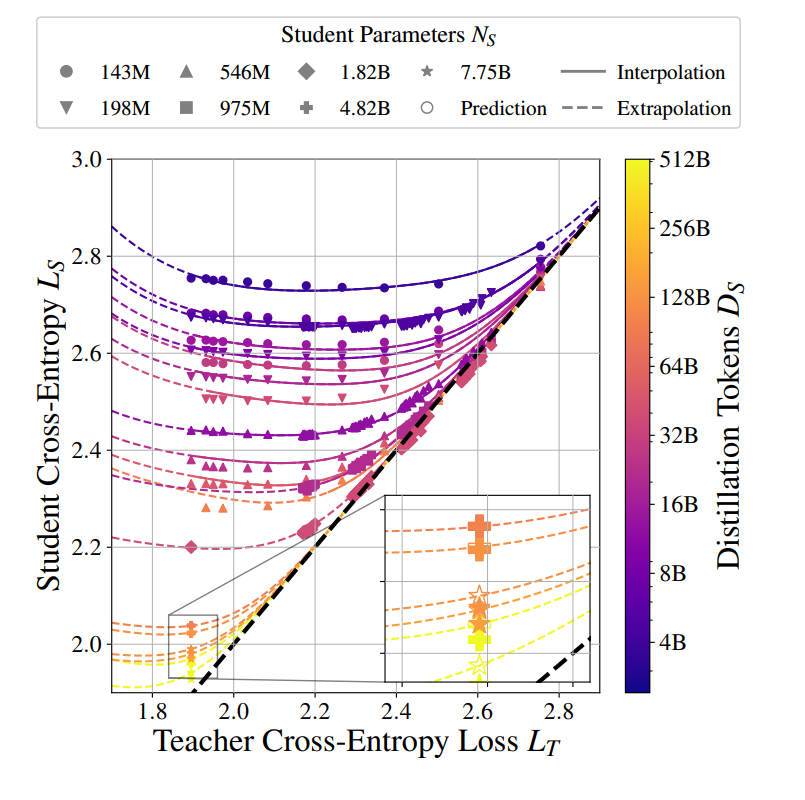
- 横轴: 教师的交叉熵损失 Lt。数值越低说明教师模型越强。
- 纵轴: 学生的交叉熵损失 Ls。同理,数值越低表示学生性能越好。
- 颜色:从紫色到黄色代表学生蒸馏所用的训练 Token 数量 Ds,从 4 B 到 512 B 不等。
- 不同形状标记: 表示学生模型的不同规模(143M、546M、1.82B、7.75B)。
- 实线:表示对“已观察过的教师”在特定学生配置下做内插(interpolation)
- 虚线:表示对教师或学生处于更强区间(或外推区间)的预测结果(extrapolation)。
实验分为三个阶段进行:
-
首先,直接对基础模型开展蒸馏训练,不以监督微调(SFT)为前置步骤;
-
其次,引入多阶段训练以及令启动数据,进一步优化模型的推理性能;
-
最后,将大规模推理模型的能力蒸馏至小型模型中,并评估这些蒸馏模型在基准测试中的表现。
实验结果显示,教师模型性能(以交叉熵损失衡量)的提升通常能带动学生模型的表现改善。
-
然而,这种提升并非无限制,当教师模型的能力超出一定水平时,学生模型的性能会反而降低,表现出一种过犹不及现象。
-
此外,在计算资源有限且学生模型规模较小时,蒸馏方法相较于监督学习具备更大优势;
-
但在计算资源充足的条件下,监督学习最终能取得优于蒸馏方法的表现。
教师损失 Lr 过低时(当教师太强、学生模型过弱时),学生反而学不到教师的高阶分布特征,导致学生性能无法随教师性能提升而同步提高。
最终结论
输出【获得蒸馏规模化规律与应用指导】├── 蒸馏规模化公式:Ls(Ns, Ds, Lr)≈f(Ns, Ds, Lr)【核心成果】└── [可指导] 在给定算力/数据量下如何选取教师与学生规模【实际部署策略】├── 关键发现:当教师已存在且学生数据量适中,蒸馏更具效率【利于小模型部署】├── 教师损失 Lr 过低时,学生反而难以逼近其分布【效用转负】└── 与监督学习对比:数据量足够大时,监督可超过蒸馏;但资源有限时,蒸馏更优【使用边界】
作者提出了 蒸馏规模定律(Distillation Scaling Law)
能够预测在不同计算预算、教师质量、学生大小和蒸馏数据量条件下,学生模型的最佳交叉熵。
1. 学生模型的交叉熵 Ls 主要受三个变量影响:
- 学生规模 Ns:参数量大小决定了学生的学习能力。
- 蒸馏 Token 数 Ds:蒸馏数据量越多,学生模型的交叉熵通常会降低,但存在边际收益递减。
- 教师模型的交叉熵 Lt:比教师弱的学生受益于蒸馏,但如果教师过强,可能会遇到“过犹不及”,即学生无法完全吸收教师的信息。
因此,在给定计算预算下,选择教师模型时要避免教师交叉熵 Lt 远低于学生可学习能力,否则蒸馏效率降低。
如何利用这些参数来指导蒸馏选择?
可根据 预算情况、已有教师模型、学生目标性能 来决定最佳蒸馏策略。主要依据是:
1. 确定学生模型大小 Ns:
- 如果计算资源有限(移动端部署),优先选择 小型 (如 143M、546M)。
- 如果计算资源较充足(服务器推理),可以选择 中等规模(如 1.82B)。
- 如果要最大化性能(强 AI 模型),选择 大规模(如 7.75B)。
2. 选定合适的教师模型 Nt 或 Lt:
- 线性比例关系 意味着:当你想要训练一个 2B 的学生模型时,教师模型往往在 (1-3) 倍学生规模 范围内更具性价比。
- 如果你的学生是小模型(< 1B),不必使用超大教师(> 7B),避免“容量差距”导致学习受限。
3. 选择学生模型最佳的蒸馏数据量 Ds:
- 2B 学生模型,若你想满足“Chinchilla”的 Token/参数比 Ms ≈ 20:
- Ds ≈ 2B×20=40B Tokens
实际情况中,如果算力或数据有限,也可以只用 10~20B Tokens 来做蒸馏,但收益会递减。
论文中的实验显示,学生蒸馏数据量不足时(例如 <8B),很难逼近教师的性能。
论文局限
苹果的蒸馏规律专门研究“教师给学生提供完整概率分布”的场景(即软蒸馏)
但现在的蒸馏SFT(硬蒸馏)方法,更倾向于“让教师生成具体序列供学生学习”,而不是让学生模仿每个词的概率分布。
-
就是把教师生成的序列当做新数据集来训练
对于这种序列级知识蒸馏(也称蒸馏 SFT),论文的结论是否仍然有效,还有待进一步验证。
为什么两种蒸馏(软 vs. 硬)被区分?
答3:因为他们的“学习信号”不一样:
- 软蒸馏(Hinton,2015):学生通过模仿教师整个概率分布(每个词的 softmax 输出,整个分布蒸馏),从而学习到“错误选项之间相对关系”。
- 硬蒸馏 / 序列级蒸馏:学生只看到教师“选出的那条序列”,不知道教师对其他词或候选序列的评分如何,丢失了许多分布层面的信息。
随着大模型的发展,越来越多的蒸馏方法转向让教师“生成序列”(硬标签)给学生学,这与 Hinton 2015 的软蒸馏思路差异较大。
这种输入形式上的差异,会使 训练动态、模型收敛方式、性能上限 都可能发生变化,导致原先适合软蒸馏的规律不一定直接适用于硬蒸馏。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









