






一、交叉编译
1.交叉编译案例:hello.c
#include <stdio.h>
int main(int argc, char** argv)
{
if (argc >= 2)
printf("Hello, %s!\n", argv[1]);
else
printf("Hello, world!\n");
return 0;
}将以上代码在Ubuntu中执行以下命令:
gcc -o hello hello.c
./hello
Hello,word!
./hellow Albert
Hellow,Albert!上述代码在gcc编译后可以在Ubuntu-x86上运行,但是无法在ARM板上运行,因为gcc编译出的机器指令x86架构的。如果想要给ARM板编译程序,需要使用交叉编译工具,例如:
arm-buildroot-linux-gnueabihf-gcc -o hello hello.c使用交叉编译工具可以在x86架构的机器上编译出ARM架构可以使用的程序。
2. hello.c中几个问题
(1)查看交叉编译器中头文件的目录,执行:
find -name “stdio.h”(2)自己指定头文件目录:
编译时,加上“-I <头文件目录>”(3)确定交叉编译器中库文件的默认路径:
进入交叉编译器的目录里,执行:
find -name lib
可以得到 xxxx/lib、xxxx/usr/lib,一般来说这 2 个目录就是要找的路径(4)自己指定库文件目录,指定要用的库文件:
编译时,加上“-L <库文件目录>”这样的选项,用来指定库目录
编译时,加上“-labc”这样的选项,用来指定库文件 libabc.so二、GCC编译器
1.GCC编译器简介
在windows下使用集成开发环境时可能并不会注意编译工具,只需要几个按键就将源文件编译成可执行文件。在Linux下也有集成开发环境,但是更多时候我们直接使用编译工具。在windows上的编译工具链为gcc、ld、objcopy、objdump等,经这些工具编译出的程序只能在x86架构机器上运行。要在x86架构上编译出ARM架构可以运行的程序,需要使用交叉编译工具xxx-gcc、xxx-ld等。(不同版本编译器前缀不一致,例如arm-linux-gcc)
2.GCC编译过程
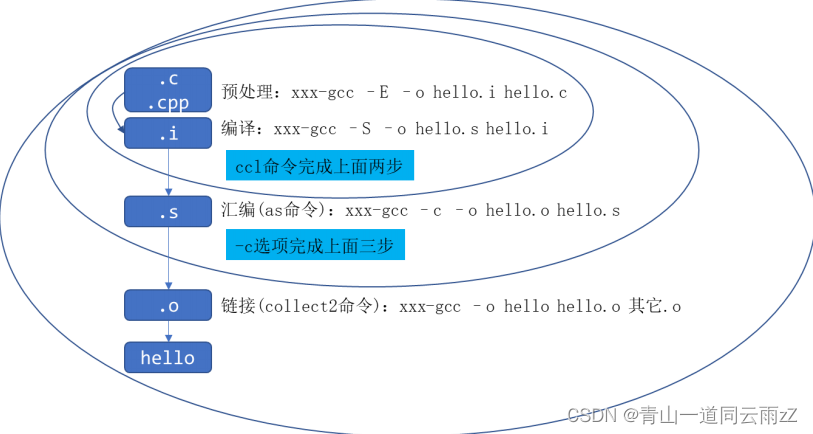
一个 C / C++文件要经过预处理(preprocessing)、编译(compilation)、汇编(assembly)和链接(linking)等 4 步才能变成可执行文件,如图1所示。不同的gcc选项可以控制这些过程,如图2所示:

示例:
gcc hello.c // 输出一个名为 a.out 的可执行程序,然后可以执行./a.out
gcc -o hello hello.c // 输出名为 hello 的可执行程序,然后可以执行./hello
gcc -o hello hello.c -static // 静态链接
gcc -c -o hello.o hello.c // 先编译(不链接)
gcc -o hello hello.o // 再链接GCC编译过程详解解
(1)预处理:C / C++源文件中,以“#”开头的命令被称为预处理命令,如包含命令“#include”、宏定义命令“#define”、条件编译命令“#if”、“#ifdef”等。预处理就是将要包含(include)的文件插入原文件中、将宏定义展开、根据条件编译命令选择要使用的代码,最后将这些东西输出到一个“.i”文件中等待进一步处理。
(2)编译: 编译就是把 C / C++代码(比如上述的“.i”文件)“翻译”成汇编代码,所用到的工具为 cc1(它的名字就是 cc1,x86 有自己的 cc1 命令,ARM 板也有自己的cc1 命令)。
(3)汇编:汇编就是将第二步输出的汇编代码翻译成符合一定格式的机器代码,在Linux 系统上一般表现为 ELF 目标文件(OBJ 文件),用到的工具为 as。x86 有自己的 as 命令,ARM 版也有自己的 as 命令,也可能是 xxxx - as(比如 arm-linux - as)。“反汇编”是指将机器代码转换为汇编代码,这在调试程序时常常用到。
(4)链接: 链接就是将上步生成的 OBJ 文件和系统库的 OBJ 文件、库文件链接起来,最
终生成了可以在特定平台运行的可执行文件,用到的工具为 ld 或 collect2。
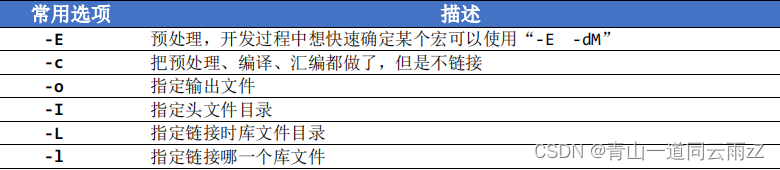
3.常用编译选项
(1)如图3所示,为GCC常用的编译选项
(2)编译多个文件的两种方法
① 一起编译、链接
gcc -o test main.c sub.cgcc -c -o main.o main.c
gcc -c -o sub.o sub.c
gcc -o test main.o sub.o(3)制作、使用动态库
① 制作、编译
gcc -c -o main.o main.c
gcc -c -o sub.o sub.c
gcc -shared -o libsub.so sub.o sub2.o sub3.o(可以使用多个.o 生成动态库)
gcc -o test main.o -lsub -L /libsub.so/所在目录/② 运行
把libsub.so 放到 Ubuntu 的/lib 目录,然后就可以运行 test 程序。
(4)制作、使用静态库
gcc -c -o main.o main.c
gcc -c -o sub.o sub.c
ar crs libsub.a sub.o //(可以使用多个.o 生成静态库)
gcc -o test main.o libsub.a //(如果.a 不在当前目录下,需要指定它的绝对或相对路径)
/*
运行:不需要把静态库 libsub.a 放到板子上。
注意:执行 arm-buildroot-linux-gnueabihf-gcc -c -o sub.o sub.c 交叉编译需要在
最后面加上-fPIC 参数。
*/(5)其他技巧
gcc -E main.c // 查看预处理结果,比如头文件是哪个
gcc -E -dM main.c > 1.txt // 把所有的宏展开,存在 1.txt 里
gcc -Wp,-MD,abc.dep -c -o main.o main.c // 生成依赖文件 abc.dep
echo 'main(){}'| gcc -E -v - // 它会列出头文件目录、库目录(LIBRARY_PATH)三、Makefile
1.Makefile必要性与示例
(1)Makefile的必要性:
① 包含多个源文件的项目在编译时有长而复杂的命令行,可以通过makefile保存这些命令行来简化该工作;
② make可以减少重新编译所需要的时间,因为make可以识别出哪些文件是新修改的;
③ make维护了当前项目中各文件的相关关系,从而可以在编译前检查是否可以找到所有的文件。
(2)示例:
//第 1 个 Makefile,简单粗暴,效率低:
test : main.c sub.c sub.h
gcc -o test main.c sub.c//第 2 个 Makefile,效率高,相似规则太多太啰嗦,不支持检测头文件:
test : main.o sub.o
gcc -o test main.o sub.o
main.o : main.c
gcc -c -o main.o main.c
sub.o : sub.c
gcc -c -o sub.o sub.c
clean:
rm *.o test -f//第 3 个 Makefile,效率高,精炼,不支持检测头文件:
test : main.o sub.o
gcc -o test main.o sub.o
%.o : %.c
gcc -c -o $@ $<
clean:
rm *.o test -f//第 4 个 Makefile,效率高,精炼,支持检测头文件(但是需要手工添加头文
件规则):
test : main.o sub.o
gcc -o test main.o sub.o
%.o : %.c
gcc -c -o $@ $<
sub.o : sub.h
clean:
rm *.o test -f//第 5 个 Makefile,效率高,精炼,支持自动检测头文件:
objs := main.o sub.o
test : $(objs)
gcc -o test $^
//需要判断是否存在依赖文件
//.main.o.d .sub.o.d
dep_files := $(foreach f, $(objs), .$(f).d)
dep_files := $(wildcard $(dep_files))
//把依赖文件包含进来
ifneq ($(dep_files),)
include $(dep_files)
endif
%.o : %.c
gcc -Wp,-MD,.$@.d -c -o $@ $<
clean:
rm *.o test -f
distclean:
rm $(dep_files) *.o test -f2.Mikefile规则
一个简单的 Makefile 文件包含一系列的“规则”,其样式如下:
目标(target)…: 依赖(prerequiries)…
<tab>命令(command)
//注意:每个命令行前面必须是一个 Tab 字符,即命令行第一个字符是 Tab。这是
//容易出错的地方。 目标(target)通常是要生成的文件的名称,可以是可执行文件或OBJ文件,也可以是一个执行的动作名称,诸如`clean’。
依赖是用来产生目标的材料(比如源文件),一个目标经常有几个依赖。
命令是生成目标时执行的动作,一个规则可以含有几个命令,每个命令占一行。
通常,如果一个依赖发生了变化,就需要规则调用命令以更新或创建目标。但是并非所有的目标都有依赖,例如,目标“clean”的作用是清除文件,它没有依赖。
规则一般是用于解释怎样和何时重建目标。make 首先调用命令处理依赖,进而才能创建或更新目标。当然,一个规则也可以是用于解释怎样和何时执行一个动作,即打印提示信息。
一个 Makefile 文件可以包含规则以外的其他文本,但一个简单的 Makefile文件仅仅需要包含规则。虽然真正的规则比这里展示的例子复杂,但格式是完全一样的。
3.Makefile文件里的赋值方法
immediate = deferred
immediate ?= deferred
immediate := immediate
immediate += deferred or immediate
define immediate
deferred
endef在 GNU make 中对变量的赋值有两种方式:延时变量、立即变量。区别在于它们的定义方式和扩展时的方式不同,前者在这个变量使用时才扩展开,意即当真正使用时这个变量的值才确定;后者在定义时它的值就已经确定了。使用`=’,`? = ’定义或使用 define 指令定义的变量是延时变量;使用`: = ’定义的变量是立即变量。需要注意的一点是,`? = ’仅仅在变量还没有定义的情况下有效,即`? = ’被用来定义第一次出现的延时变量。对于附加操作符`+ = ’,右边变量如果在前面使用(: = )定义为立即变量则它也是立即变量,否则均为延时变量。
4.Makefile常用函数
$(function arguments)这里`function’是函数名,`arguments’是该函数的参数。参数和函数名之间是用空格或 Tab 隔开,如果有多个参数,它们之间用逗号隔开。这些空格和逗号不是参数值的一部分。
(1)字符串替换和分析函数
1 $(subst from,to,text)
在文本`text’中使用`to’替换每一处`from’。
比如:
$(subst ee,EE,feet on the street)
结果为‘fEEt on the strEEt’。
2 $(patsubst pattern,replacement,text)
寻找`text’中符合格式`pattern’的字,用`replacement’替换它们。`pattern’和`replacement’中可以使用通配符。
比如:
$(patsubst %.c,%.o,x.c.c bar.c)
结果为:`x.c.o bar.o’。
3 $(strip string)
去掉前导和结尾空格,并将中间的多个空格压缩为单个空格。
比如:
$(strip a b c )
结果为`a b c’。
4 $(findstring find,in)
在字符串`in’中搜寻`find’,如果找到,则返回值是`find’,否则返回值为空。
比如:
$(findstring a,a b c)
$(findstring a,b c)
将分别产生值`a’和`’(空字符串)。
5 $(filter pattern...,text)
返回在`text’中由空格隔开且匹配格式`pattern...’的字,去除不符合格式`pattern...’的字。
比如:
$(filter %.c %.s,foo.c bar.c baz.s ugh.h)
结果为`foo.c bar.c baz.s’。
6 $(filter-out pattern...,text)
返回在`text’中由空格隔开且不匹配格式`pattern...’的字,去除符合格式`pattern...’的字。它是函数 filter 的反函数。
比如:
$(filter %.c %.s,foo.c bar.c baz.s ugh.h)
结果为`ugh.h’。
7 $(sort list)
将‘list’中的字按字母顺序排序,并去掉重复的字。输出由单个空格隔开的字的列表。
比如:
$(sort foo bar lose)
返回值是‘bar foo lose’。(2)文件名函数
1 $(dir names...)
抽取‘names...’中每一个文件名的路径部分,文件名的路径部分包括从文件名的首字符到最后一个斜杠(含斜杠)之前的一切字符。
比如:
$(dir src/foo.c hacks)
结果为‘src/ ./’。
2 $(notdir names...)
抽取‘names...’中每一个文件名中除路径部分外一切字符(真正的文件名)。
比如:
$(notdir src/foo.c hacks)
结果为‘foo.c hacks’。
3 $(suffix names...)
抽取‘names...’中每一个文件名的后缀。
比如:
$(suffix src/foo.c src-1.0/bar.c hacks)
结果为‘.c .c’。
4 $(basename names...)
抽取‘names...’中每一个文件名中除后缀外一切字符。
比如:
$(basename src/foo.c src-1.0/bar hacks)
结果为‘src/foo src-1.0/bar hacks’。
5 $(addsuffix suffix,names...)
参数‘names...’是一系列的文件名,文件名之间用空格隔开;suffix 是一个后缀名。将 suffix(后缀)的值附加在每一个独立文件名的后面,完成后将文件名串联起来,它们之间用单个空格隔开。
比如:
$(addsuffix .c,foo bar)
结果为‘foo.c bar.c’。
6 $(addprefix prefix,names...)
参数‘names’是一系列的文件名,文件名之间用空格隔开;prefix 是一个前缀名。将 preffix(前缀)的值附加在每一个独立文件名的前面,完成后将文件名串联起来,它们之间用单个空格隔开。
比如:
$(addprefix src/,foo bar)
结果为‘src/foo src/bar’。
7 $(wildcard pattern)
参数‘pattern’是一个文件名格式,包含有通配符(通配符和 shell 中的用法一样)。函数 wildcard 的结果是一列和格式匹配的且真实存在的文件的名称,文件名之间用一个空格隔开。
比如若当前目录下有文件 1.c、2.c、1.h、2.h,则:
c_src := $(wildcard *.c)
结果为‘1.c 2.c’。(3)其他函数
1 $(foreach var,list,text)
前两个参数,‘var’和‘list’将首先扩展,注意最后一个参数‘text’此时不扩展;接着,‘list’扩展所得的每个字,都赋给‘var’变量;然后‘text’引用该变量进行扩展,因此‘text’每次扩展都不相同。
函数的结果是由空格隔开的‘text’ 在‘list’中多次扩展后,得到的新‘list’,就是说:‘text’多次扩展的字串联起来,字与字之间由空格隔开,如此就产生了函数 foreach 的返回值。
下面是一个简单的例子,将变量‘files’的值设置为 ‘dirs’中的所有目录下的所有文件的列表:
dirs := a b c d
files := $(foreach dir,$(dirs),$(wildcard $(dir)/*))
这里‘text’是‘$(wildcard $(dir)/*)’,它的扩展过程如下:
① 第一个赋给变量 dir 的值是`a’,扩展结果为‘$(wildcard a/*)’;
② 第二个赋给变量 dir 的值是`b’,扩展结果为‘$(wildcard b/*)’;
③ 第三个赋给变量 dir 的值是`c’,扩展结果为‘$(wildcard c/*)’;
④ 如此继续扩展。
这个例子和下面的例有共同的结果:
files := $(wildcard a/* b/* c/* d/*)
2 $(if condition,then-part[,else-part])
首先把第一个参数‘condition’的前导空格、结尾空格去掉,然后扩展。如果扩展为非空字符串,则条件‘condition’为‘真’;如果扩展为空字符串,则条件‘condition’为‘假’。
如果条件‘condition’为‘真’,那么计算第二个参数‘then-part’的值,并将该值作为整个函数 if 的值。
如果条件‘condition’为‘假’,并且第三个参数存在,则计算第三个参数‘else-part’的值,并将该值作为整个函数 if 的值;如果第三个参数不存在,函数 if 将什么也不计算,返回空值。
注意:仅能计算‘then-part’和‘else-part’二者之一,不能同时计算。这
样有可能产生副作用(例如函数 shell 的调用)。
3 $(origin variable)
变量‘variable’是一个查询变量的名称,不是对该变量的引用。所以,不能采用‘$’和圆括号的格式书写该变量,当然,如果需要使用非常量的文件名,可以在文件名中使用变量引用。
函数 origin 的结果是一个字符串,该字符串变量是这样定义的:
‘undefined' :如果变量‘variable’从没有定义;
‘default' :变量‘variable’是缺省定义;
‘environment' :变量‘variable’作为环境变量定义,选项‘-e’没有打开;
‘environment override' :变量‘variable’作为环境变量定义,选项‘-e’已打开;
‘file' :变量‘variable’在 Makefile 中定义;
‘command line' :变量‘variable’在命令行中定义;
‘override' :变量‘variable’在 Makefile 中用 override 指令定义;
‘automatic' :变量‘variable’是自动变量
4 $(shell command arguments)
函数 shell 是 make 与外部环境的通讯工具。函数 shell 的执行结果和在控制台上执行‘command arguments’的结果相似。不过如果‘command arguments’的结果含有换行符(和回车符),则在函数 shell 的返回结果中将把它们处理为单个空格,若返回结果最后是换行符(和回车符)则被去掉。
比如当前目录下有文件 1.c、2.c、1.h、2.h,则:
c_src := $(shell ls *.c)
结果为‘1.c 2.c’。














 1643
1643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









