







什么是clustering?
聚类算法查看多个数据点,并自动找到彼此相关或相似的数据点。
K-means clustering 示例

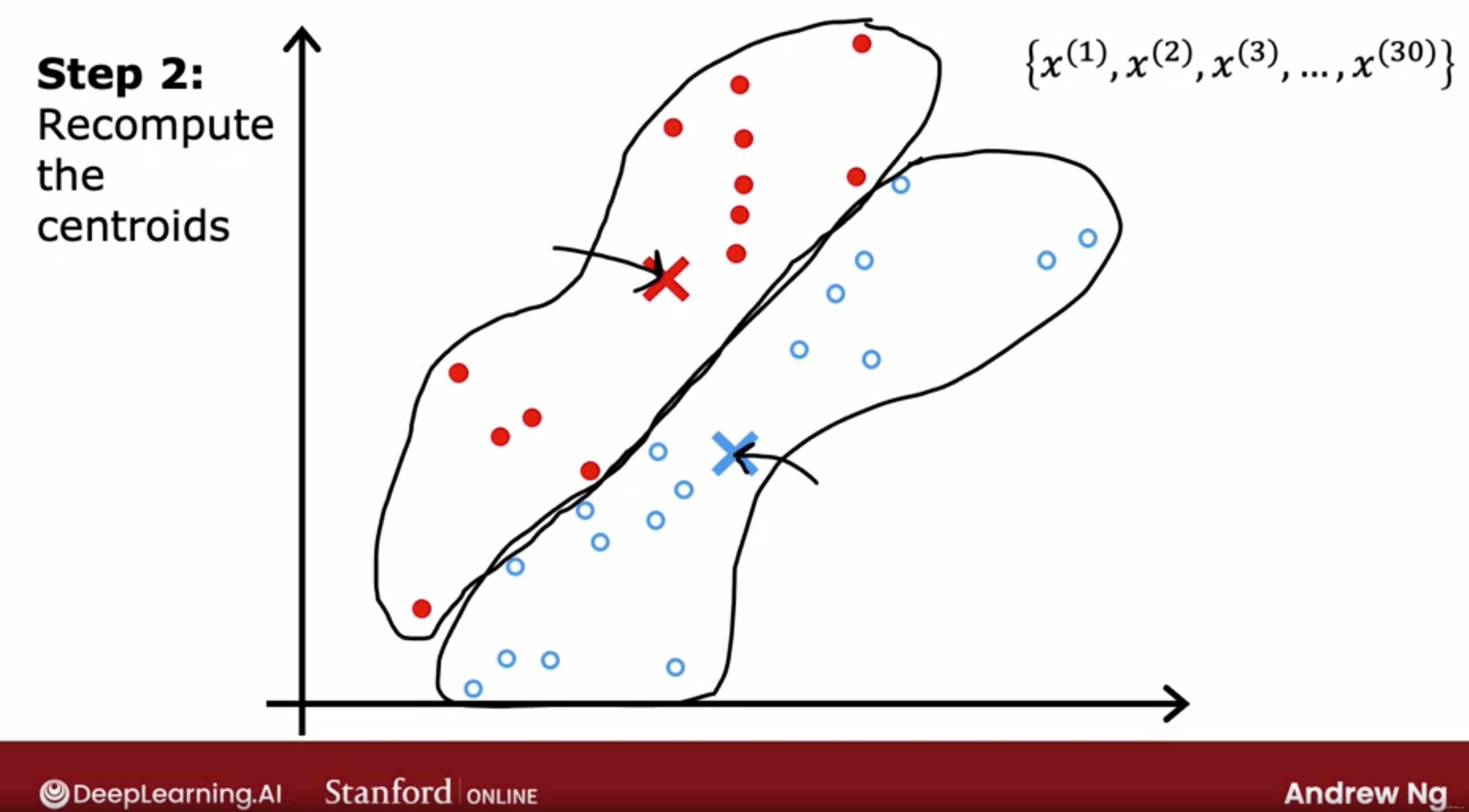
循环:再次分配每个点到离它最近的质心,重新计算质心。
K-means algorithm
注意: k-means的初始化质心Mu有着和数据集一样的维度。
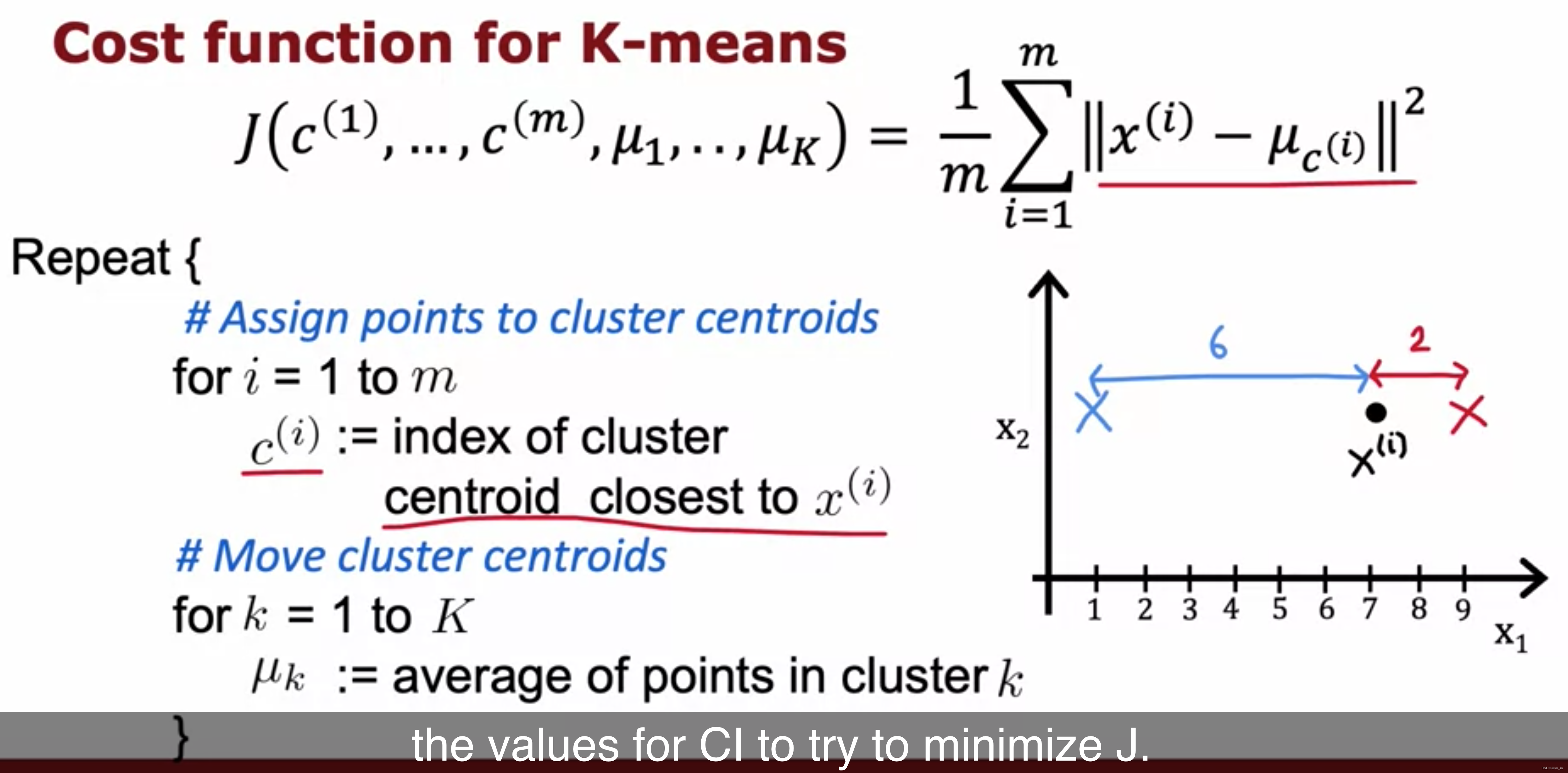
- step1, 计算最近的质心

- step2 移动质心

optimization objective
converge: 收敛
Cost function

又被命名为Distortion function
为什么选择cost function
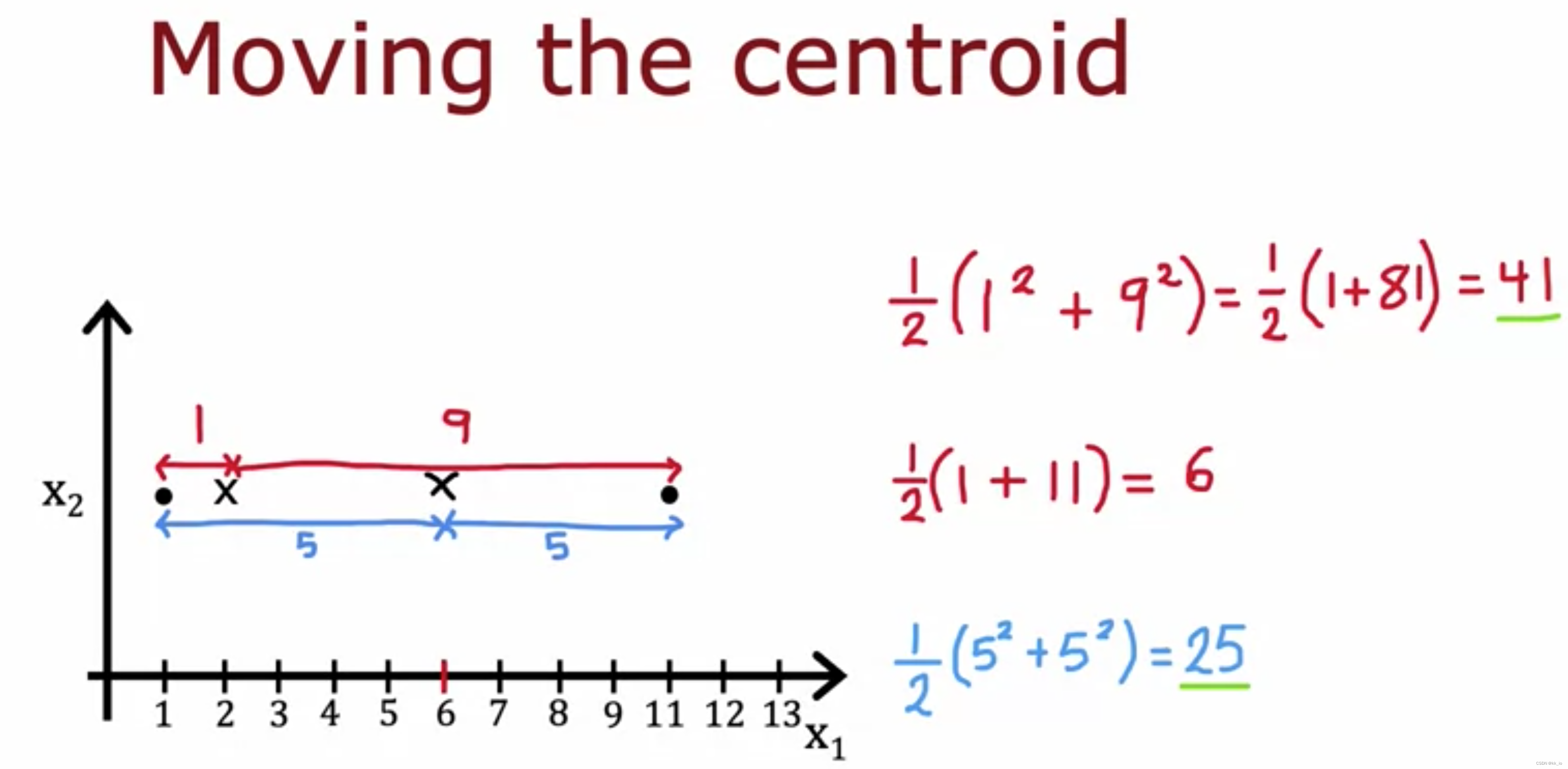
moving the centroid
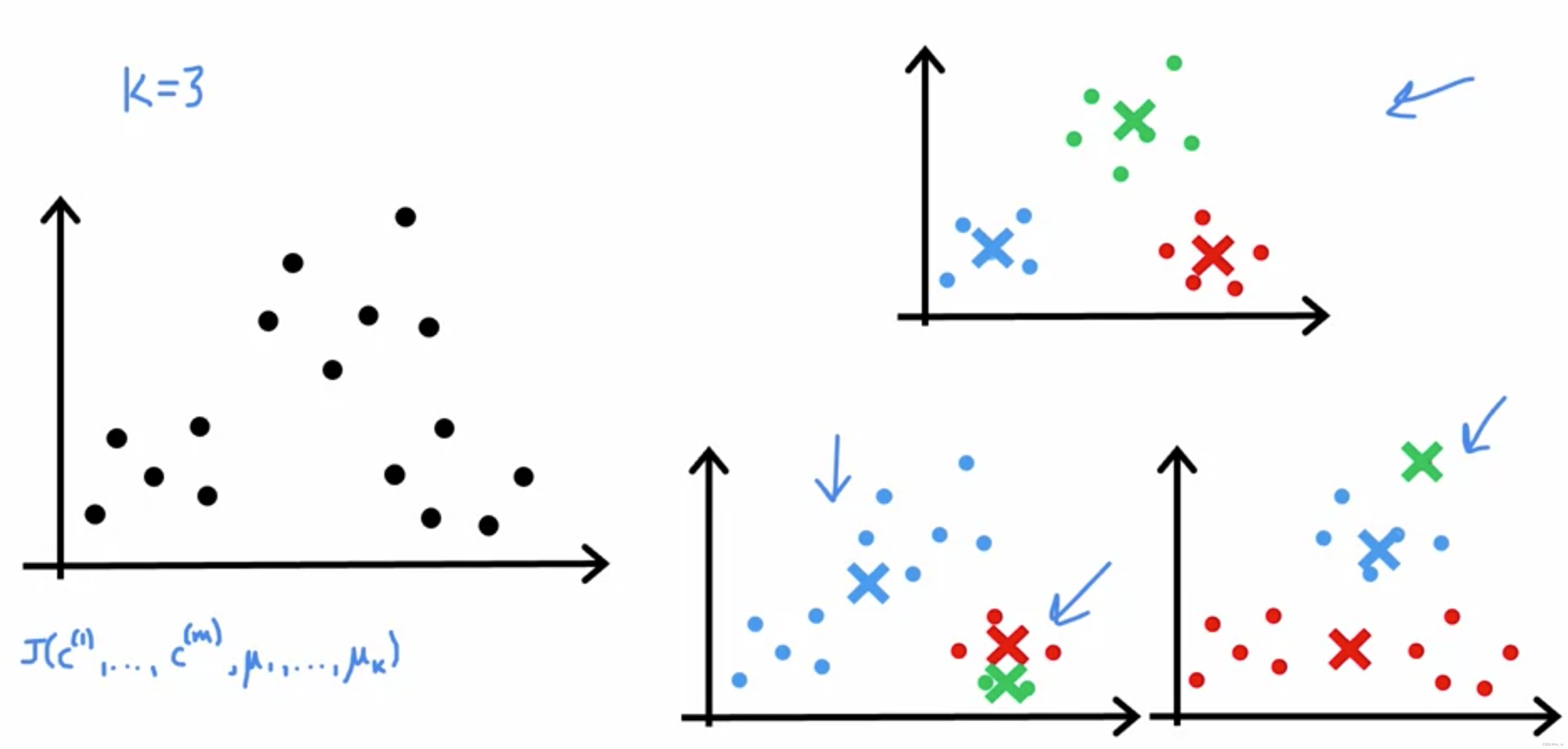
Initializing K-means
如果初始化k个质心,如何评估初始化的效果?
选择K < m, 随机选择K个训练样本作为k个质心。
如何选择质心的最佳选择,就是计算成本函数J为最小的.
随机初始化的算法

初始化对于K-means有重要的作用,这里的i就是多次初始化去找cost function最低的初始化方法。
Choosing the number of clusters
elbow 方法是选择cluster K的一种统计学方法,但总是很难选择。一般聚类数是通过downstream purpose(下游需求)确定。















 968
968











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









