







一、查找的概念
- 查找的概念
查找(或检索)是在给定信息集上寻找特定信息元素的过程。
待查找的数据单位(或数据元素)称为记录。记录由若干数据项(或属性)组成,如学生记录。
若某个数据项的值能标识(或识别)一个或一组记录,则称为关键字。
![]()
- 其中,“学号”、“性别”、“姓名”、“年龄”等都是记录的数据项。若某个数据项的值能标识(或识别)一个或一组记录,称其为关键字(Key)。若一个key能够唯一标识一个记录,称此key为主key。如“学号”的值给定就唯一的对应一个学生,不可能多个学生的学号相同。如“年龄”值为20时,可能有若干个同学的年龄为20,故“年龄”可作次key。下面主要讨论对主Key的查找。
- 查找的方法:
查找的方法很多,有顺序查找、折半查找、分块查找、树表查找以及Hash表查找等等。查找算法的优劣将影响到计算机的使用效率,应根据应用场合选择相应的查找算法。
二、查找算法
1、顺序查找法
- 记录可以是无序的,也可以是有序的。
- 弊端:查找的效率非常的低。
#include "seqsearch.h"
int Seqsearch(int *a,int num)
{
int i;
for(i = 9;i>=0;i--)
{
if(a[i] == num)
{
return i;
}
}
return -1;
}#include "seqsearch.h"
#include <stdio.h>
int main(int argc, const char *argv[])
{
int a[N] = {1,2,3,4,5,6,7,8,9,0};
int i,key;
char ch;
while(1)
{
printf("Please input key : ");
scanf("%d",&key);
i = Seqsearch(a,key);
if(i == -1 )
{
printf("search faile !!! ");
return -1;
}else
{
printf("search %d of %d ",a[i],i);
}
while(getchar() != '\n');//清空输入缓存
printf("continue?(y/Y)");
scanf("%c",&ch);
if(ch == 'y' || ch == 'Y')
{
continue;
}else break;
}
return 0;
}2、二分法查找法
- 使用该 查找方法 的要求: 记录必须是有序的。

(1)第一次找到mid后,判断要寻找的目标在那个半段上,然后以low为头,以 mid-1为尾,再次二分整个记录,寻找下一个mid
(2) 一直将记录折半下去,一直到i>=j,则说明范围缩小到了最小,比较该数值是不是需要查找的数值,是则返回数值,不是则返回-1;
3、分块查找法
分块查找又索引查找,它主要用于“分块有序”表的查找。所谓“分块有序”是指将线性表L(一维数组)分成m个子表(要求每个子表的长度相等),且第i+1个子表中的每一个项目均大于第i个子表中的所有项目。“分块有序”表应该包括线性表L本身和分块的索引表A。因此,分块查找的关键在于建立索引表A。
(1)建立索引表A(二维数组)
索引表包括两部分:关键字项(子表中的最大值)和指针项(子表的第一项在线性表L中位置)
索引表按关键字有序的。
例如:线性表L(有序)为:1 2 3 4 5 6 7 8 9 10 11 12
分成m=3个子表:{1 2 3 4} {5 6 7 8} {9 10 11 12}
索引表A:二维数组:第一列为每个子表的最大值 ,第二列为每个子表的起始地址
即: 4 0
8 4
12 8
(2)利用索引表A,确定待查项X所在的子表(块)。
(3)在所确定的子表中可以用“折半查找”法搜索待查项X;若找到则输出X;否则输出未找到信息。
例如:
输出顺序表(8,14,6,9,10,22,34,18,19,31,40,38,54,66,46,71,78,68,80,85,100,94,88,96,87)中采用分块查找的方法查找(每块的块长为5,共有5块)关键字46的过程。
#include <stdio.h>
#define MAXL 100 //定义表中最多记录个数
#define MAXI 20 //定义索引表的最大长度
typedef int KeyType;
typedef char InfoType[10];
typedef struct
{
KeyType key; //KeyType为关键字的数据类型
InfoType data; //其他数据
} NodeType;
typedef NodeType SeqList[MAXL]; //顺序表类型
typedef struct
{
KeyType key; //KeyType为关键字的类型
int link; //指向分块的起始下标
} IdxType;
typedef IdxType IDX[MAXI]; //索引表类型
int IdxSearch(IDX I,int m,SeqList R,int n,KeyType k) //分块查找算法
{
int low=0,high=m-1,mid,i,count1=0,count2=0;
int b=n/m; //b为每块的记录个数
printf("二分查找\n");
while (low<=high) //在索引表中进行二分查找,找到的位置存放在low中
{
mid=(low+high)/2;
printf(" 第%d次比较:在[%d,%d]中比R[%d]:%d\n",count1+1,low,high,mid,R[mid].key);
if (I[mid].key>=k)
high=mid-1;
else
low=mid+1;
count1++; //累计在索引表中的比较次数
}
if (low<m) //在索引表中查找成功后,再在线性表中进行顺序查找
{
printf("比较%d次,在第%d块中查找元素%d\n",count1,low,k);
i=I[low].link;
printf("顺序查找:\n ");
while (i<=I[low].link+b-1 && R[i].key!=k)
{
i++;count2++;
printf("%d ",R[i].key);
} //count2累计在顺序表对应块中的比较次数
printf("\n");
printf("比较%d次,在顺序表中查找元素%d\n",count2,k);
if (i<=I[low].link+b-1)
return i;
else
return -1;
}
return -1;
}
int main()
{
SeqList R;
KeyType k=46;
IDX I;
int a[]={8,14,6,9,10,22,34,18,19,31,40,38,54,66,46,71,78,68,80,85,100,94,88,96,87},i;
for (i=0;i<25;i++) //建立顺序表
R[i].key=a[i];
I[0].key=14;I[0].link=0;
I[1].key=34;I[1].link=4;
I[2].key=66;I[2].link=10;
I[3].key=85;I[3].link=15;
I[4].key=100;I[4].link=20;
if ((i=IdxSearch(I,5,R,25,k))!=-1)
printf("元素%d的位置是%d\n",k,i);
else
printf("元素%d不在表中\n",k);
printf("\n");
}4、树表查找法
- 定义
树型存储结构和树型逻辑结构是完全对应的,都是表示一个树形图,只是用存储结构中的链指针代替逻辑结构中的抽象指针罢了,因此,往往把树型存储结构(即树表)和树型逻辑结构(树)统称为树结构或树。在本节中,将分别讨论在树表上进行查找和修改操作的方法 [1] 。
- 基本思想
⑴当二叉排序树不空时,首先将给定值k与根结点的关键字进行比较,若相等则查找成功;
⑵若给定值k小于根结点的关键字,则下一次与左子树的根结点的关键字进行比较,若给定值k大于根结点的关键字,则与右子树的根接到的关键字进行比较。如此递归的进行下去直到某一次比较相等,查找成功。如果一直比较到树叶都不等,则查找失败。
5、Hash查找法
- 在存储每一个记录的同时,key值与位置记录的关系表 ------- 哈希表
- 建立记录 表时,建立记录的关键字与记录的位置之间的关联。------ 如何去建立?建立一个怎样的表?哈希表是什么样子的?
- 映射 的概念 --- H(key) ------ > key Hash函数。
(1)Hash表的含义
Ⅰ、 Hash表,又称散列表、杂凑表。在前面讨论的顺序、折半、分块查找和树表的查找中,其ASL的量级在O(n)~O(log2n)之间。不论ASL在哪个量级,都与记录长度n有关。随着n的扩大,算法的效率会越来越低。ASL与n有关是因为记录在存储器中的存放是随机的。或者说记录的key与记录的存放地址无关,因而查找只能建立在key的“比较”基础上。
Ⅱ、 理想的查找方法是:对给定的k,不经任何比较便能获取所需的记录,其查找的时间复杂度为常数级O(C).这就要求在建表的时候,确定记录的key与其存储地址之间的关系f,即使key与记录的存放地址H相对应:
![]()
或者说,记录按key存放。
Ⅲ、之后,当腰查找key=k的记录时,通过关系f就可得到相应记录的地址而或取记录,从而免去了key的比较过程。这个关系f就是所谓的Hash函数(或则称为 散列函数,杂凑函数),记为H(key)。它实际是一个地址映像函数,其自变量为记录的key,函数值为记录的存储地址(或者称为Hash地址)。
Ⅳ、另外,不同的key可能得到同一个Hash地址,即当key1≠key2时,可能有H(key1)==H(key2),此时称key1与key2为同义词。这种现象称为“冲突” 或者“碰撞”,因为一个数据单位只可存放一条记录。
Ⅵ、一般,选取Hash函数只能做到使冲突尽可能少,却不能完全避免。这就要求在出现冲突之后,寻求适当的方法来解决冲突记录的存放问题。

![]()

(2)关于Hash表的讨论关键是两个问题, 一是 选取Hash函数的方法 二是 确定解决冲突的方法。
选取(或构造)Hash函数的方法很多,原则是尽可能将记录均匀分布,以减少冲突现象的发生。以下介绍几种常见的构造方法。
直接地址法 ,数字分析法,平方取中法,叠加法,保留除数法,随机函数法
- 直接地址法
此方法是取key的某个线性函数为Hash函数,即令: H(key)=a*key+b (其中a、b为常数,此时称H(key)为直接Hash函数或自身函数)。
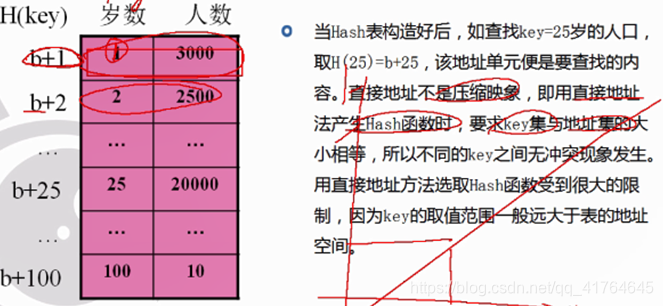
某地区1~100岁的人口统计表:

给定的存储空间为b+1 ~ b+100 号单元(b为起始地址),每个单元可以存放一条记录Ri(1≤i≤100)。取“岁数”为key,令:H(key) = key+b; 则按此函数构造的Hash表如下图所示:
- 数字分析法
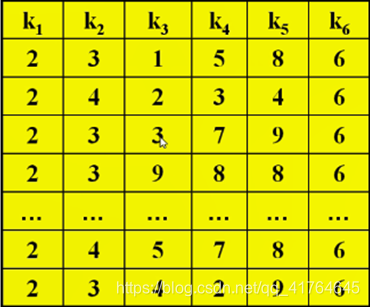
例如:设记录数等于80,记录的key为6位10进制数,即key = (k1 k2 k3 k4 k5 k6)10 ki(1≤i≤6)=0|1|2|.......|9,地址空间为00~99,则可令: H(key )= ki*kj;
- 平方取中法
当取key中某些位为Hash地址而不能使记录均匀分布时,根据数学原理,取(key)²中的某些位可能比较的理想,所以平方取中法中,令:![]()
![]()
![]()
的存储空间而定。
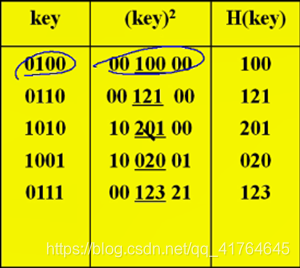
例如: 设 Hash表地址空间为000~999,对一组随机性不好的Key,按平方取中法选取的H(key)如表所列:
- 叠加法

例如:
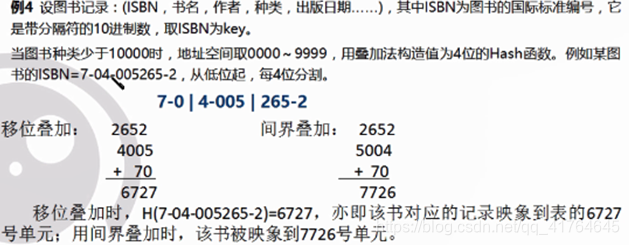
- 保留除数法

例如:

- 随机函数法

总结:以上介绍了选取Hash函数的6中方法,从中可以看出,选取Hash函数要考虑的因素为:
(1)key的长度、类型以及分布的情况。
(2)给定的Hash表表长。.
(3)记录的查找效率。
通常是几种方法结合使用,目的是使记录更好的均匀分布,减少冲突的发生。
(3) 处理冲突的方法
选取随机度好的Hash函数可使冲突减少,一般来讲不能完全避免冲突。因此,如何处理冲突是Hash表不可缺少的另一方面。
在处理冲突的过程中,可能发生一连串的冲突现象,即可能得到一个地址序列H1、H2........Hn ![]()
H1是冲突时选取的下一个地址,而H1中可能已有记录,又设法得到下一个地址H2........ 直到某个Hn不发生冲突为止。这种现象叫“聚积”,它严重影响了Hash表的查找效率。
冲突现象发生有时并不完全是由于Hash函数的随机性不好引起的,聚积的发生也会加重冲突。还有一个因素是表的 装填因子α,α=n/m,其中m为表长,n为表中记录个数。一般α在0.7~0.8之间,使表保持一定的空闲余量,以减少冲突和聚积现象。
- 开发地址发
发生冲突时,在H(key)的前后找一个空闲单元来存放冲突的记录,即在H(key)的基础上 获取下已地址。
Hi = (H(key)+di)%m
其中m为表长,%运算是保证Hi落在[0 , m-1]区间;di 为地址增量。
di 的取法有多种:

例子:使用保留除数法,选取Hash函数。


- 链地址法
发生冲突时,将各冲突记录链在一起,即同义词的记录存于同一链表。
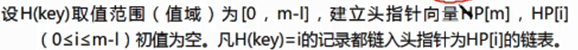


注:冲突时,将同义词存放于同一个链表时,将先入的记录挂载在后入记录的next指针域中,即后入的记录指向先入的的记录。(先入的记录的地址存放于 后入的记录中)














 488
488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









