







1.str对象
str对象是定义在Index或Series上的属性
1.字母转为大写的操作:
s.str.upper() # pandas中str对象上的upper方法
…
2.[]索引器
通过[]可以取出某个位置的元素
–切片
3.string类型
2.正则表达式基础
正则表达式是一种按照某种正则模式,从左到右匹配字符串中内容的一种工具。
1.findall函数
例如,在下面的字符串中找出apple:
import re
re.findall(‘Apple’, ‘Apple! This Is an Apple!’)
具体:

例如:
code:re.findall(’.’, ‘abc’)
result:[‘a’, ‘b’, ‘c’]
2.简写字符集
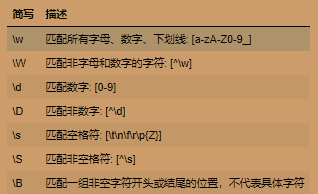
例如:
code:re.findall(’.s’, ‘Apple! This Is an Apple!’)
result:[‘is’, ‘Is’]
3.文本处理的五类操作
1.拆分
str.split能够把字符串的列进行拆分,其中第一个参数为正则表达式,可选参数包括从左到右的最大拆分次数n,是否展开为多个列expand。
s.str.split(’[市区路]’, n=2, expand=True)
2.合并
关于合并一共有两个函数,分别是str.join和str.cat。str.join表示用某个连接符把Series中的字符串列表连接起来,如果列表中出现了字符串元素则返回缺失值。
s = pd.Series([[‘a’,‘b’], [1, ‘a’], [[‘a’, ‘b’], ‘c’]])
s.str.join(’-’)
str.cat用于合并两个序列,主要参数为连接符sep、连接形式join以及缺失值替代符号na_rep,其中连接形式默认为以索引为键的左连接。
s1 = pd.Series([‘a’,‘b’])
s2 = pd.Series([‘cat’,‘dog’])
s1.str.cat(s2,sep=’-’)
3. 匹配
str.contains返回了每个字符串是否包含正则模式的布尔序列:
str.match,其返回了每个字符串起始处是否符合给定正则模式的布尔序列:
str.find与str.rfind,其分别返回从左到右和从右到左第一次匹配的位置的索引,未找到则返回-1,只能用于字符子串的匹配。
4.替换
str.replace和replace并不是一个函数,在使用字符串替换时应当使用前者。
5.提取
提取既可以认为是一种返回具体元素(而不是布尔值或元素对应的索引位置)的匹配操作,也可以认为是一种特殊的拆分操作。前面提到的str.split例子中会把分隔符去除,这并不是用户想要的效果,这时候1.就可以用str.extract进行提取:
pat = ‘(\w+市)(\w+区)(\w+路)(\d+号)’
s.str.extract(pat)
2.str.extractall不同于str.extract只匹配一次,它会把所有符合条件的模式全部匹配出来,如果存在多个结果,则以多级索引的方式存储:
s.str.extractall(pat_with_name)
3.str.findall的功能类似于str.extractall,区别在于前者把结果存入列表中,而后者处理为多级索引,每个行只对应一组匹配,而不是把所有匹配组合构成列表。
s.str.findall(pat)
4.常用字符串函数
1.字母型函数
upper, lower, title, capitalize, swapcase这五个函数主要用于字母的大小写转化。
2.数值型函数
这里着重需要介绍的是pd.to_numeric方法,它虽然不是str对象上的方法,但是能够对字符格式的数值进行快速转换和筛选。其主要参数包括errors和downcast分别代表了非数值的处理模式和转换类型。其中,对于不能转换为数值的有三种errors选项,raise, coerce, ignore分别表示直接报错、设为缺失以及保持原来的字符串。
例如,在数据清洗时,可以利用coerce的设定,快速查看非数值型的行:
s[pd.to_numeric(s, errors=‘coerce’).isna()]
3.统计型函数
count和len的作用分别是返回出现正则模式的次数和字符串的长度。
4.格式型函数
格式型函数主要分为两类,第一种是除空型,第二种时填充型。
1.第一类函数一共有三种,它们分别是strip, rstrip, lstrip,分别代表去除两侧空格、右侧空格和左侧空格。这些函数在数据清洗时是有用的,特别是列名含有非法空格的时候。
my_index = pd.Index([’ col1’, 'col2 ‘, ’ col3 ‘])
my_index.str.strip().str.len()
my_index.str.rstrip().str.len()
my_index.str.lstrip().str.len()
2.对于填充型函数而言,pad是最灵活的,它可以选定字符串长度、填充的方向和填充内容。
s = pd.Series([‘a’,‘b’,‘c’])
s.str.pad(5,‘left’,’*’)
3.在读取excel文件时,经常会出现数字前补0的需求,例如证券代码读入的时候会把"000007"作为数值7来处理,pandas中除了可以使用上面的左侧填充函数进行操作之外,还可用zfill来实现。
下面结果相同:
s.str.pad(6,‘left’,‘0’)
s.str.rjust(6,‘0’)
s.str.zfill(6)















 8169
8169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









