







PYG中实现小批量data类中__inc__与__cat_dim__的含义与作用
1.作用
此两个函数出现在pytorch geometric实现批量操作时,batch集行为的自定义修改方法,两种方法都是为了解决多个数据之间的拼接问题。
2.直观图解
- 官方初始定义,均对某一属性值进行判定
def __inc__(self, key, value):
if 'index' in key or 'face' in key:
return self.num_nodes
else:
return 0
def __cat_dim__(self, key, value):
if 'index' in key or 'face' in key:
return 1
else:
return 0
返回值的具体含义见图:
- __ inc __
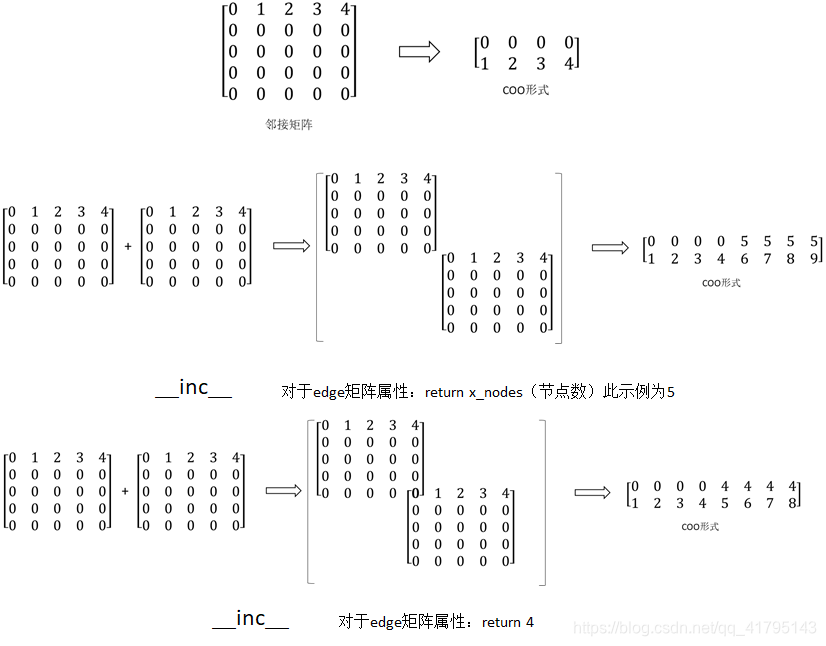
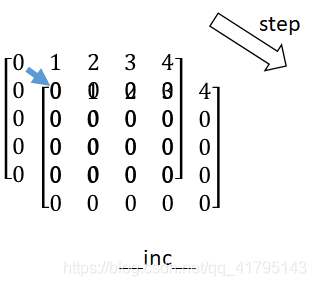
即__ inc __返回值表示相应矩阵错位步数,一般用于边的邻接矩阵:
- __ cat_dim __
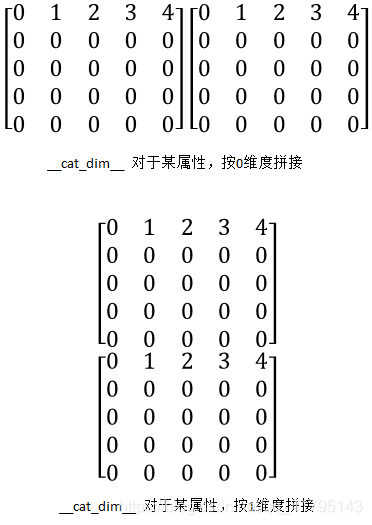
即__ cat_dim __返回值表示相应矩阵拼接的维度。按行或列拼接,一般用于节点或者结果矩阵的拼接
3.官方示例
官方默认batch拼接形式如下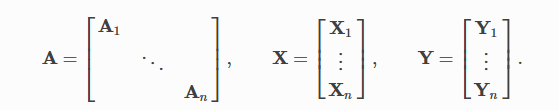
A为邻接矩阵,X为节点矩阵,Y为结果矩阵
此时对比官方示例,一目了然:
- 成对数据结构
class PairData(Data):
def __init__(self, edge_index_s, x_s, edge_index_t, x_t):
super(PairData, self).__init__()
self.edge_index_s = edge_index_s
self.x_s = x_s
self.edge_index_t = edge_index_t
self.x_t = x_t
- 批量时,要分成两个数据集来拼接,所以需要自定义边矩阵的拼接
def __inc__(self, key, value):
if key == 'edge_index_s':
return self.x_s.size(0)
if key == 'edge_index_t':
return self.x_t.size(0)
else:
return super().__inc__(key, value)
- 测试
edge_index_s = torch.tensor([
[0, 0, 0, 0],
[1, 2, 3, 4],
])
x_s = torch.randn(5, 16) # 5 nodes.
edge_index_t = torch.tensor([
[0, 0, 0],
[1, 2, 3],
])
x_t = torch.randn(4, 16) # 4 nodes.
data = PairData(edge_index_s, x_s, edge_index_t, x_t)
data_list = [data, data]
loader = DataLoader(data_list, batch_size=2)
batch = next(iter(loader))
print(batch)
>>> Batch(edge_index_s=[2, 8], x_s=[10, 16],
edge_index_t=[2, 6], x_t=[8, 16])
print(batch.edge_index_s)
>>> tensor([[0, 0, 0, 0, 5, 5, 5, 5],
[1, 2, 3, 4, 6, 7, 8, 9]])
print(batch.edge_index_t)
>>> tensor([[0, 0, 0, 4, 4, 4],
[1, 2, 3, 5, 6, 7]])
两个A矩阵,分别按照对角线扩展方式拼接了~!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









