









 本文详细解释了Kafka的集群架构,包括核心控制器的角色、leader分区选举、自平衡机制、消费者offset管理和Rebalance,以及生产者消息发布、消息存储和高效读写策略,特别关注了分区故障恢复和一致性保障机制。
本文详细解释了Kafka的集群架构,包括核心控制器的角色、leader分区选举、自平衡机制、消费者offset管理和Rebalance,以及生产者消息发布、消息存储和高效读写策略,特别关注了分区故障恢复和一致性保障机制。
Kafka集群架构设计原理详解
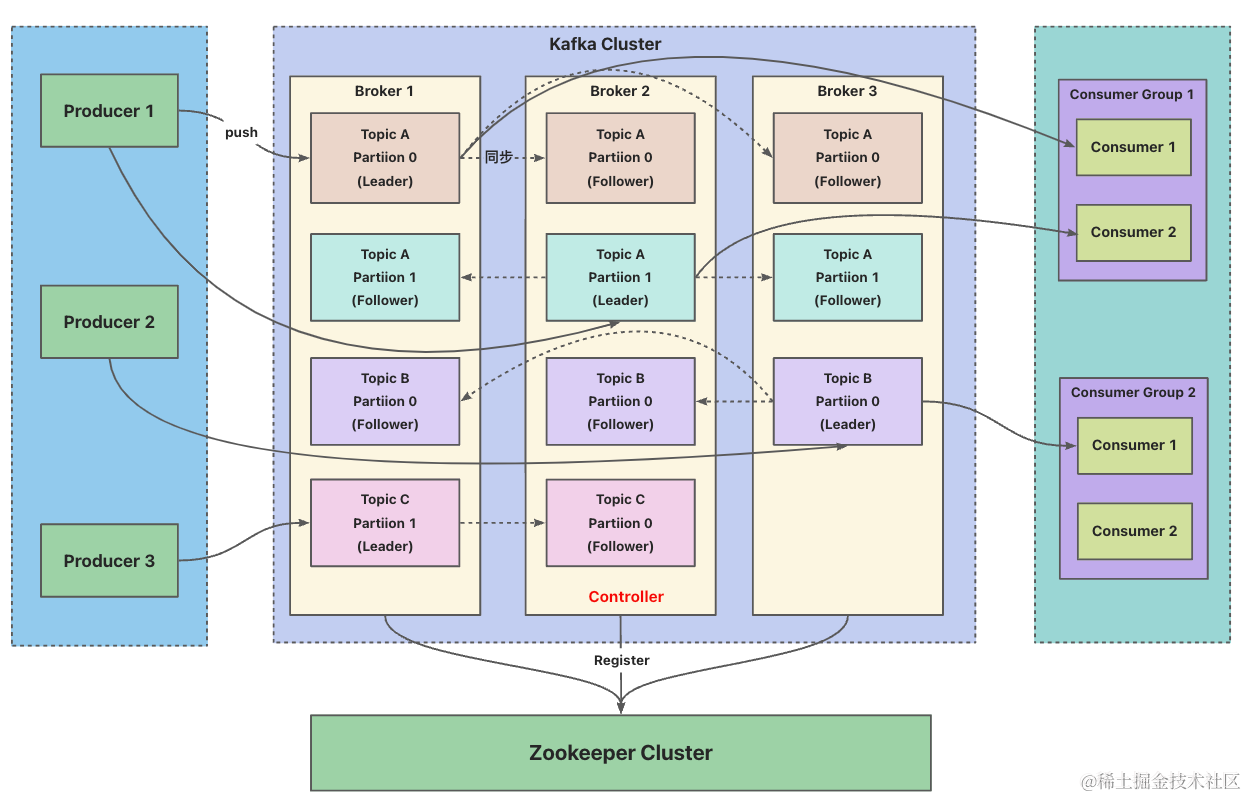
Kafka核心总控制器
-
参数说明- leader
- 负责给定Partition的所有读写请求
- replicas
- 表示某个Partition在那些Broker上存在备份,列举出节点信息
AR- 分区中的所有副本(存活和不存活的)
ISR(in-sync replicas)- 在AR中,存活的并且能与leader正常同步的分区副本
- 进入ISR列表的条件
- 副本节点不能产生分区以及能与ZK和leader副本保持稳定联系
- 副本能进行leader副本同步操作,并且数据不能滞后太多
- 进入ISR列表的条件
- 在AR中,存活的并且能与leader正常同步的分区副本
- OSR(out-sync replicas)
- 表示从ISR中踢出的节点,记录的是那些服务有问题、延迟过多的副本
- leader
-
控制器- 在Kafka集群中会有一个或多个Broker,其中有一个Broker会被选举为控制器,
负责管理整个集群中所有分区和副本的状态- 当某个分区的leader副本出现故障时,由控制器负责为该分区选举出新的leader副本
- 当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有Broker更新其元数据信息
- 当使用脚本为某个Topic增加分区数量时,由控制器负责告知其它节点
- 在Kafka集群中会有一个或多个Broker,其中有一个Broker会被选举为控制器,
Contoller Broker选举机制
- Kafka集群启动时,会自动选举一个Broker作为控制器来管理整个集群,选举的过程是集群中每个Broker都会尝试在ZK上创建/contrller临时节点并将自己的brokerid写入,ZK会保证只有一个Broker创建成功成为集群的核心控制器
- 当这个核心控制器出现故障,此时ZK上对应的临时节点会被删除,集群中其它Broker由于监听着这个节点的变化,会再次去竞争选举成为新的核心控制器
简概- 抢创ZK上/controller临时节点,监控该节点的状态变化
Leader Partition选举机制
- 控制器感知到分区leader副本所在的Broker出现故障,满足AR排名最靠前并且在ISR中得成为leader
- 满足分区副本排名靠前并且存活的会优先成为leader
Leader Partition自平衡机制
- 在一组分区副本中,leader分区负责与客户端数据交互以及向follower同步数据,通常情况下是比较繁忙的,所以默认情况下Kafka会尽量将leader分区分配到不同的Broker节点上,来保证整个集群的压力平均,但是经过leader分区选举之后,这种平衡可能会被打破,如果让过多的leader分区集中到同一个Broker就会导致该节点压力过大,所以Kafka设计了leader分区自平衡机制
Kafka会认为AR中的第一个节点为leader节点,控制器会定期检查集群中所有Broker的分区的平衡情况,当某个Broker的分区数量高于阈值时,会触发自平衡
- leader分区自平衡是一个非常重的操作,会涉及大量数据的同步与转移,可能会造成消息丢失,所以对于业务要求较高的场景建议关闭
消费者消费消息的offset记录机制
- 每个消费者会定期将自己消费分区的offset提交给Kafka内部的Topic(_cosumer_offsets),Kafka会定期清理Topic中的消息,最后保留最新的那条数据,因为该Topic可能会接受高并发的请求,Kafka默认给其分配了50个分区,这样可以通过加机器来抗大并发
消费者Rebalance机制
- 如果消费组里的消费者数量有变化或消费的分区数有变化,Kafka会重新分配消费者消费分区的关系,比如消费组中的某个消费者挂了,此时会将已分配给它的分区转交给其它的消费者,如果它重启了,那么会将之前的分区还给它
- Rebalance只针对subscribe这种不指定分区消费的情况,如果通过assign这种消费方式指定的了分区,Kafka不会进行Rebalance
- Rebalance过程中,消费者无法从Kafka消费消息,这对Kafka的TPS会有影响,如果kafKafkaa集群内节点较多,那重平衡可能会耗时极多,所以应尽量避免在系统高峰期的重平衡发生
问题: 触发消费者Rebalance机制的情况- 消费者组里消费者变化
- 动态给Topic增加分区
- 消费组订阅了更多的Topic
Rebalance流程
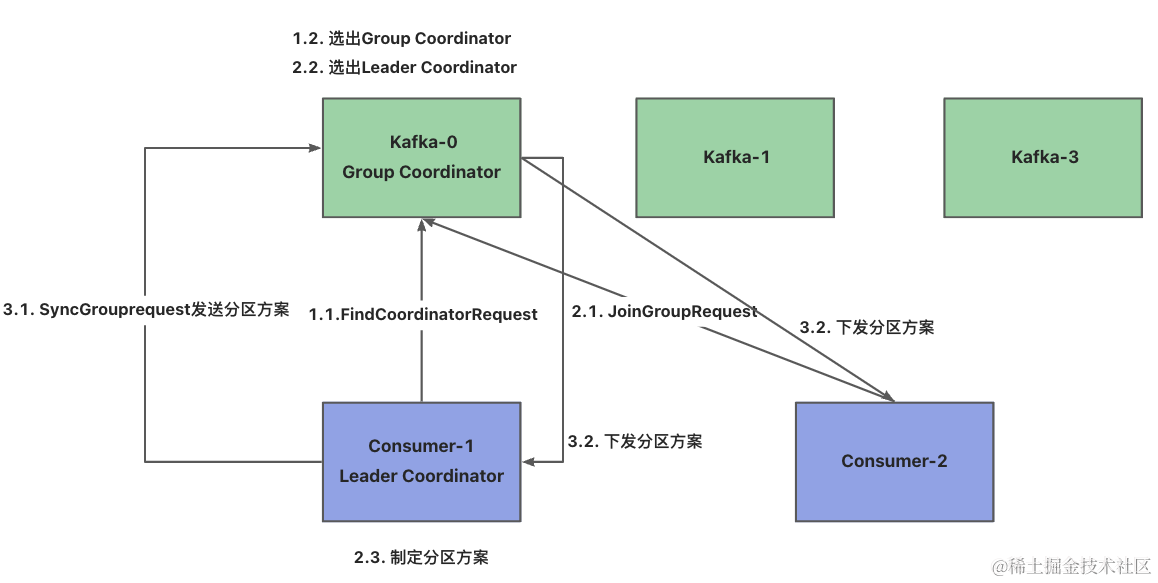
- 三阶段
- 选出组协调器
- 每个消费组都会选择一个Broker作为自己的组协调器,负责监控这个消费组里的所有消费者是否存活(心跳),然后开启消费者Rebalance,消费者组中的每个消费者启动时会向Kafka集群中的某个节点发送
查找请求来查找对应的组协调器,并建立连接 - 组协调器选择方式
- 公式:hash(consumer group id) % __consumer_offsets主题的分区数
- 每个消费组都会选择一个Broker作为自己的组协调器,负责监控这个消费组里的所有消费者是否存活(心跳),然后开启消费者Rebalance,消费者组中的每个消费者启动时会向Kafka集群中的某个节点发送
- 加入消费组
- 在成功找到消费组所对应的组协调器之后就会进入该阶段,此时消费者会向组协调器发送
加入请求并处理响应,然后组协调器会从消费者组中选择第一个加入到组的消费者作为leader(消费组协调器),把消费者组的情况发送给这个leader,并让它负责制定分区方案
- 在成功找到消费组所对应的组协调器之后就会进入该阶段,此时消费者会向组协调器发送
- 同步消费组
- 消费者leader通过组协调器发送
同步请求,然后组协调器会将分区方案发到各个消费者,然后所有消费者会根据指定分区的leader broker进行网络连接和消息消费
- 消费者leader通过组协调器发送
- 选出组协调器
Partition故障恢复机制
-
参数说明- LEO(Log End Offset)
- 每个分区的最后一个offset
- HW(High Watermark):
- 一组分区中最小的LEO
- LEO(Log End Offset)
-
机制- 在一组分区选举出一个leader分区之后,该leader分区就会优先写入消息,再将消息同步给其它follower分区
- 当leader分区所在的Broker发生故障时,Kafka就会触发leader分区选举机制,为了保证消息能够在多个分区中保持数据同步,每个分区都会记录自己保存的消息offset,leader分区每写入一条消息都会将LEO值+1,follower分区会从leader分区中同步消息,每同步一次,自己的LEO值+1并且同步给leader分区,leader分区通过follower返回的LEO值计算出HW值,最终会将HW值同步给所有follower
- 对于HW之前的消息是所有follower分区完成数据同步的,是安全的,可以被消费者使用
- 对于HW之后的消息是可能丢失的,是不安全的,所以不能被消费者使用
问题: 分区出现故障应对方式`- leader分区所在的Broker出现故障
- 当leader分区所在的Broker出现故障时,会从ISR中的所有follower中进行选举出新的leader,此时
新leader的LEO值会低于之前leader的LEO值,follower只能以leader为主将各自高于HW值的部分全部删除,重新从leader中同步,旧leader恢复之后也只能跟其它follower一样如此操作
- 当leader分区所在的Broker出现故障时,会从ISR中的所有follower中进行选举出新的leader,此时
- follower分区所在的Broker出现故障
- 当follower分区所在的Broker出现故障时,不会影响消息写入,只是写好了一个备份
- Kafka会将follower节点临时剔除ISR,而其他leader和follower能继续正常工作,等follower节点恢复之后,不会立即加入到ISR中,follower节点会读取本地上一次的HW值,将高于HW值的部分信息全部删除,然后从HW值位置重新消息同步,等到follower的LEO值不小于整个分区的HW值后,就会重新加入到ISR中(follower的消息同步进度追上了leader)
- leader分区所在的Broker出现故障
HW一致性保障-Epoch更新机制
问题: 对于Partition故障恢复机制使用到了LEO和HW,如何保证各个Broker中记录的HW一致- 实际上HW值在一组分区里并不是总是一致的,对于follower分区需要先从leader分区将消息拉回本地,才能上报LEO值,当所有follower分区上报完之后,leader分区才会计算出HW值,然后告知follower进行拉取最新的HW值,所以leader分区的LEO值更新与follower分区的LEO值更新存在一定延迟,这样就间接导致HW值存在一定延迟
- 如果服务一切正常,leader分区还是可以正常推进HW之的,是能保证最终一致性的
- 当leader分区出现切换,所有follower分区都只能按照各自的HW值进行数据恢复,会导致数据不一致的情况
- Kafka通过Epoch机制来保证HW的一致性
- 每次发生leader变更时,都会维护一个递增的epoch号以及当前分区写入的首个消息offset,并且持久化到文件中,其它follower会同步该文件,当出现leader变更时,follower就可以直接依赖最新的epoch去判断拉取消息的起点,避免使用自身的HW值去判断
Producer发布消息机制
- 写入方式
- 生产者采用
推模式将消息发布到Broker,每条消息都被追加到分区中,属于顺序写磁盘(顺序写磁盘效率比随机写内存效率要高,保障Kafka吞吐率)
- 生产者采用
- 消息路由
- 生产者发送消息到Broker时,会根据分区算法选择将其存到某个分区
路由机制- 指定了分区
- 未指定分区但指定key,通过对key的值进行hash
- 未指定分区和key,通过轮询
- 生产者发送消息到Broker时,会根据分区算法选择将其存到某个分区
- 写入流程
- 生产者先从ZK的state节点下找到分区的leader,然后将消息发送给leader,leader将消息持久化到本地log,follower从leader拉取消息成功之后发生ACK,leader收到所有ISR中节点的ACK之后,维护HW值再向生产者发送ACK
- 采用稀疏索引(类似数据库中的非聚集索引),通过二分查找进行定位,效率较高
- 生产者先从ZK的state节点下找到分区的leader,然后将消息发送给leader,leader将消息持久化到本地log,follower从leader拉取消息成功之后发生ACK,leader收到所有ISR中节点的ACK之后,维护HW值再向生产者发送ACK
日志存储
问题: Topic下的消息是如何存储的- Kafka每个分区都会对应一个文件夹,以topic + 分区号命名,消息在分区内采用分段存储,每个段的消息都存到不同的日志文件中,这样能保证旧文件可以定期被快速删除,另外为了方便将数据刷到内存,所以规定每个段的日志文件最大为1G
- 整个文件结构采用稀疏索引结构,这样可以加速日志文件的读取,并且采用顺序写磁盘的方式(只支持追加,不支持修改和删除)进行追加内容,提升了写入的效率
文件高效读写机制
文件结构- 同一个Topic下的多个分区采用单独的日志文件进行存储,可以并行读取,这样可以加速读取Topic下的数据
- 采用稀疏索引结构,可以加快日志文件的检索速度
顺序写磁盘- 对于每个日志文件,Kafka都提前规划了固定的大小,这样保证在申请文件时可以提前占据一块连续的磁盘空间
- 日志文件采用顺序写磁盘的方式,不用浪费时间去寻找空闲空间,就可以基于之前申请的文件进行追加,提升写入效率
- 顺序写
- 以追加的形式在同一个文件中进行写入,写入效率极高
- 随机写
- 寻找空闲的磁盘空间进行写入,磁盘中的空闲空间可能不是连续的,所以写入效率很低
- 顺序写
零拷贝- 配合内核态的复制机制,减少用户态和内核态之间的内容拷贝
实现方式- mmap文件映射机制
- 用户态不缓存整个IO过程,只通过文件的映射信息进行内核态的读写,类似于JDK中的DirectByteBuffer实现机制
- sendfile文件传输机制
- 向内核态发送sendfile指令操控它进行文件复制
- 在Kafka中,当消费者从Broker上拉消息时,用户态只需要向内核态发送sendfile指令,此时Broker就会从磁盘读出数据,复制到网卡的socket缓冲区中,再通过网络传输出去
- 向内核态发送sendfile指令操控它进行文件复制
- mmap文件映射机制
















 579
579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











