







本文参考自 https://zhuanlan.zhihu.com/p/114669778
最近在学transformer,tensor2tensor库中用了beam search(束搜索),了解了下束搜索的原理,但是实现中还是有很多细节问题需要梳理
一、beam search原理

贪心搜索在每一个时间步都取分数最高的token作为当前时间布的输出,复杂度低,但不一定能保证全局最优。穷举搜索遍历词汇表中的每一个token,开销太大。束搜索作为贪心算法的改进,介于两者中间,基本原理是每次选取k(num_beams)个候选词,如图1,k=2,
- 1)第一个时间步选【A】、【C】
- 2)然后计算k*vocab_size次,即分别计算【AA】、【AB】、【AC】、【AD】、【AE】和【CA】、【CB】、【CC】、【CD】、【CE】,仍然选取Top k个候选词,【AB】和【CE】(也有可能都是A这一束的)
- 3)再次分别计算【ABA】、【ABB】…【CEE】,选取Top
k个候选词,即【ABD】、【CED】。 - 4)当达到最大序列长度或遇到eos_token_id就结束。
需要注意的是,每个时间步只保留k个候选词,t-1时间步得到的输出序列(如【A】、【C】)同编码输出一起作为输入进行decode。当k=1是,束搜索退化为贪心搜索。
束搜索中输出序列的score计算公式如下:
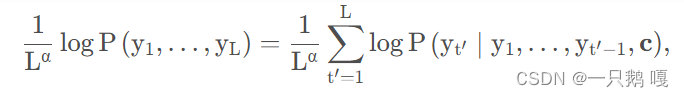
t’步骤的概率是条件概率,c为解码器的输出。其中L是最终候选序列的长度,作为惩罚项。因为每一次的概率都取log了,所以t’步骤中概率是前边概率相加。
二、beam search代码解析
基于原文( https://zhuanlan.zhihu.com/p/114669778)做一下整理与记录。
在束搜索中,需要一个存储更新候选序列的变量input_ids,(batch_size*num_beams,cur_len),随着时间步的增加,cur_len序列长度也增加;需要一个容器存储已经完成生成序列的样本,generated_hyps中每一个样本有一个容器,存储num_beams个最优序列,当超出数量的序列加入时要判断序列的score是否大于原始序列的score。
定义beam search函数,context为编码器的输出向量,batch_size为每批样本的个数,max_length为序列的最大长度,当生成的序列长度不够时,填充pad_token_id,num_beams为束搜索的k,bos_token_id为序列开头标志的token id,pad_token_id为填充的token id,eos_token_id为序列结束标志的token id。
def beam_search_generate(context,
batch_size=3,
max_length=20,
min_length=2,
num_beams=2,
bos_token_id=101,
pad_token_id=0,
eos_token_id=102,
):
pass
1. 准备初始输入
定义初始输入和得分等:
# 建立beam容器,每个样本一个,下面有类的定义。当该样本的解码token遇到eos_token_id,说明已经生成了完整句子,则往generated_hyps[batch_idx]中加入当前的token。
generated_hyps = [
BeamHypotheses(num_beams, max_length, length_penalty, early_stopping=early_stopping)
for _ in range(batch_size)
]
# 每个beam容器的得分,共batch_size*num_beams个,最后平铺成一行
beam_scores = torch.zeros((batch_size, num_beams), dtype=torch.float, device=encoder_input_ids.device)
beam_scores = beam_scores.view(-1)
# 每个样本是否完成生成,共batch_size个
done = [False for _ in range(batch_size)]
# 为了并行计算,一次生成batch_size*num_beams个序列
# 第一步自动填入bos_token
input_ids = torch.full(
(batch_size*num_beams, 1),
bos_token_id,
dtype=torch.long,
device=next(self.parameters()).device,
)
# 当前序列的长度设为1,对应bos_token_id,之后每个时间步都会+1
cur_len = 1
- generated_hyps=[BeamHypotheses(),BeamHypotheses(),BeamHypotheses()],每一个样本对应一个BeamHypotheses容器,beams属性存放的是已经完成的生成序列,每个容器中有num_beams个序列。
- beam_scores = [0,0,0,0,0,0],对应3个样本的6个beam的得分
- done = [False ,False,False ],对应3个样本是否解码完成,初始为False,当解码完成后更新为True
- input_ids = [[bos_token_id],[bos_token_id],[bos_token_id],[bos_token_id],[bos_token_id],[bos_token_id]],初始为bos_token_id,随着时间步的增加,第二个维度逐渐加入新生成的token,存储的是已经生成的序列
- cur_len 为已生成序列的长度,对应input_ids 中最后一个维度,也是时间步
下面为BeamHypotheses类的定义,每个样本对应一个BeamHypotheses(),每个容器中会维护num_beams个当前最优的序列。当往容器中添加一个序列而导致序列数大于num_beams的时候,它会自动踢掉分数最低的那个序列。
class BeamHypotheses(object):
def __init__(self, num_beams, max_length, length_penalty):
"""
Initialize n-best list of hypotheses.
"""
self.max_length = max_length - 1 # ignoring bos_token
self.num_beams = num_beams
self.beams = []
self.worst_score = 1e9
def __len__(self):
"""
Number of hypotheses in the list.
"""
return len(self.beams)
def add(self, hyp, sum_logprobs):
"""
Add a new hypothesis to the list.
"""
score = sum_logprobs / len(hyp) ** self.length_penalty # hyp是序列,只能保证有num_beams个序列,当有其他序列时踢掉一个得分最低的
if len(self) < self.num_beams or score > self.worst_score:
# 可更新的情况:数量未饱和或超过最差得分
self.beams.append((score, hyp)) # hyp是序列,每个序列对应一个score,最多只能有num_beams个序列
if len(self) > self.num_beams:
# 数量饱和需要删掉一个最差的
sorted_scores = sorted([(s, idx) for idx, (s, _) in enumerate(self.beams)])
del self.beams[sorted_scores[0][1]]
self.worst_score = sorted_scores[1][0]
else:
self.worst_score = min(score, self.worst_score)
def is_done(self, best_sum_logprobs, cur_len=None):
"""
相关样本是否已经完成生成。
best_sum_logprobs是新的候选序列中的最高得分。
"""
if len(self) < self.num_beams:
return False
else:
if cur_len is None:
cur_len = self.max_length
cur_score = best_sum_logprobs / cur_len ** self.length_penalty
# 是否最高分比当前保存的最低分还差
ret = self.worst_score >= cur_score
return ret
2. 序列扩展
序列扩展就是从【AB】、【CE】到【ABD】、【CED】的过程,随着每一个时间步的增加,序列长度+1。如下图,步骤1中为input_ids,cur_len=2,步骤2中input_ids和解码器的输出context一起作为输入进行解码,预测出vocab_size个token的概率值,步骤3中将结果重排,(batch_sizenum_beams),vocab_size --> batch_size,(num_beamsvocab_size),每一个样本/每一行取Top k个token,有可能对应第一个beam或第二个beam,所以需要记录beam_id,以便从input_ids中取出前序列分支

对于每一个batch,首先对时间步cur_len循环,未达到max_length就已完成序列生成的样本,填充pad_token_id,否则再对每一个样本循环计算是否该样本已经解码结束(对应出现eos_token_id和新加入token得分不再增加的情况),如仍需要生成,判断是否将新的token加入,如未达到num_beams或得分增加则将token放入。inputs_id记录更新生成的序列,generated_hyps容器记录已经完成的样本的生成序列。
- 只有出现了EOS token才会将生成的序列装进该样本对应的容器中
- 当前input_ids保存着当前得分最高的num_beams个序列
# 当序列长度cur_len未达到最大长度时,一直循环,每次循环后序列长度cur_len+1,当真实的输出长度小于最大长度时,即样本已经生成结束,token=eos_token_id,则填充pad_token_id
while cur_len < max_length:
# 将编码器得到的上下文向量和当前结果输入解码器,即图中1
# input_ids是已经完成解码的序列,每次cur_len循环结束会将得到的两个beam和之前的input_ids合并
output = decoder.decode_next_step(context, input_ids)
# 输出矩阵维度为:(batch*num_beams)*cur_len*vocab_size
# 取出最后一个时间步的各token概率,即当前条件概率
# 其余的时间步,对应真实序列的得分???
# (batch*num_beams)*vocab_size
scores = next_token_logits = output[:, -1, :]
###########################
# 这里可以做一大堆操作减少重复 #
###########################
# 计算序列条件概率的,因为取了log,所以直接相加即可。得到图中2矩阵
# 合并前边序列计算得分,即对每个batch分别计算【ABA】、【ABB】...【CEE】,选取Top k个候选词,即【ABD】、【CED】
# (batch_size * num_beams, vocab_size)
next_scores = scores + beam_scores[:, None].expand_as(scores)
# 为了提速,将结果重排成图中3的形状
next_scores = next_scores.view(
batch_size, num_beams * vocab_size
) # (batch_size, num_beams * vocab_size)
# 取出分数最高的token(图中黑点)和其对应得分
# sorted=True,保证返回序列是有序的
# 取Top 2 * num_beams,避免得到的都是eos_token_id???
next_scores, next_tokens = torch.topk(next_scores, 2 * num_beams, dim=1, largest=True, sorted=True)
# 下一个时间步整个batch的beam列表
# 列表中的每一个元素都是三元组
# 每一批的三元组(分数, token_id, beam_id)
next_batch_beam = []
# 对每一个样本进行扩展
# 需要判断每个样本是否已经生成完整句子,对于已经生成的填充max_length-cur_len个pad_token_id,否则判断是否出现eos_token_id,
for batch_idx in range(batch_size):
# 检查样本是否已经生成结束
if done[batch_idx]:
# 对于已经结束的句子,待添加的是pad token
next_batch_beam.extend([(0, pad_token_id, 0)] * num_beams) # pad the batch
continue
# 当前样本下一个时间步的beam列表
# 当前样本的三元组
next_sent_beam = []
# 对于还未结束的样本需要找到分数最高的num_beams个扩展
# 注意,next_scores和next_tokens是对应的
# 而且已经按照next_scores排好顺序
for beam_token_rank, (beam_token_id, beam_token_score) in enumerate(
zip(next_tokens[batch_idx], next_scores[batch_idx])
):
# get beam and word IDs
# 这两行可参考图中3进行理解
beam_id = beam_token_id // vocab_size
token_id = beam_token_id % vocab_size
effective_beam_id = batch_idx * num_beams + beam_id
# 如果出现了EOS token说明已经生成了完整句子
if (eos_token_id is not None) and (token_id.item() == eos_token_id):
# if beam_token does not belong to top num_beams tokens, it should not be added
is_beam_token_worse_than_top_num_beams = beam_token_rank >= num_beams
# 当出现EOS token,且不是Top num_beam的token,则跳出该样本的序列扩展,如果是Top num_beam的token,则该样本已经生成了完整的句子,将该样本对应的generated_hyps中添加目前生成的序列(不包括当前词eos_token_id)
if is_beam_token_worse_than_top_num_beams:
continue
# 往容器中添加这个序列,对于出现EOS token的序列,最多添加2次
generated_hyps[batch_idx].add(
input_ids[effective_beam_id].clone(), beam_token_score.item(),
)
else:
# add next predicted word if it is not eos_token
# 如果没出现EOS token,则将三元组加入到next_sent_beam中,最多添加num_beams个
next_sent_beam.append((beam_token_score, token_id, effective_beam_id))
# 扩展num_beams个就够了
if len(next_sent_beam) == num_beams:
break
# 检查这个样本是否已经生成完了,有两种情况
# 1. 已经记录过该样本结束
# 2. 新的结果没有使结果改善
# 对于出现eos_tiken_id的情况,对应的样本都已完成
done[batch_idx] = done[batch_idx] or generated_hyps[batch_idx].is_done(
next_scores[batch_idx].max().item(), cur_len=cur_len
)
# 把当前样本的结果添加到batch结果的后面
next_batch_beam.extend(next_sent_beam)
# 如果全部样本都已经生成结束便可以直接退出了
if all(done):
break
# 把三元组列表再还原成三个独立列表
beam_scores = beam_scores.new([x[0] for x in next_batch_beam])
beam_tokens = input_ids.new([x[1] for x in next_batch_beam])
beam_idx = input_ids.new([x[2] for x in next_batch_beam])
# 准备下一时刻的解码器输入
# 取出实际被扩展的beam
input_ids = input_ids[beam_idx, :]
# 在这些beam后面接上新生成的token
input_ids = torch.cat([input_ids, beam_tokens.unsqueeze(1)], dim=-1)
# 更新当前长度
cur_len = cur_len + 1
# end of length while
3. 准备输出
“上面那个while循环跳出意味着已经生成了长度为max_length的文本,比较理想的情况是所有的句子都已经生成出了eos_token_id,即句子生成结束了。但并不是所有情况都这样,对于那些”意犹未尽“的样本,我们需要先手动结束。” 对于没有出现eos_token_id的样本,需要手动处理将生成的序列放入容器中
# 将未结束的生成结果结束,并置入容器中
for batch_idx in range(batch_size):
# 已经结束的样本不需处理
if done[batch_idx]:
continue
# 把最后的结果加入到generated_hyps容器,cur_len=max_length-1时生成的是第max_length个词,已经加入到input_ids中,还需要加到generated_hyps中
for beam_id in range(num_beams):
effective_beam_id = batch_idx * num_beams + beam_id
final_score = beam_scores[effective_beam_id].item()
final_tokens = input_ids[effective_beam_id]
generated_hyps[batch_idx].add(final_tokens, final_score)
“经过上面的处理,所有生成好的句子都已经保存在generated_hyps容器中,每个容器内保存着num_beams个序列,最后就是输出期望个数的句子。”
# select the best hypotheses,最终输出
# 每个样本返回几个句子
output_num_return_sequences_per_batch = 1
# 记录每个返回句子的长度,用于后面pad
sent_lengths = input_ids.new(output_batch_size)
best = []
# 对每个样本取出最好的output_num_return_sequences_per_batch个句子
for i, hypotheses in enumerate(generated_hyps):
sorted_hyps = sorted(hypotheses.beams, key=lambda x: x[0]) # 按照score进行排序
for j in range(output_num_return_sequences_per_batch):
effective_batch_idx = output_num_return_sequences_per_batch * i + j
best_hyp = sorted_hyps.pop()[1] # 取出得分最高的序列
sent_lengths[effective_batch_idx] = len(best_hyp)
best.append(best_hyp)
# 如果长短不一则pad句子,使得最后返回结果的长度一样
if sent_lengths.min().item() != sent_lengths.max().item():
sent_max_len = min(sent_lengths.max().item() + 1, max_length)
# 先把输出矩阵填满PAD token
decoded = input_ids.new(output_batch_size, sent_max_len).fill_(pad_token_id)
# 填入真正的内容
for i, hypo in enumerate(best):
decoded[i, : sent_lengths[i]] = hypo
# 填上eos token
if sent_lengths[i] < max_length:
decoded[i, sent_lengths[i]] = eos_token_id
else:
# 所有生成序列都还没结束,直接堆叠即可
decoded = torch.stack(best).type(torch.long).to(next(self.parameters()).device)
# 返回的结果包含BOS token
return decoded
问题:会遇到词语重复的问题,待补充
三、tensor2tensor的beam search
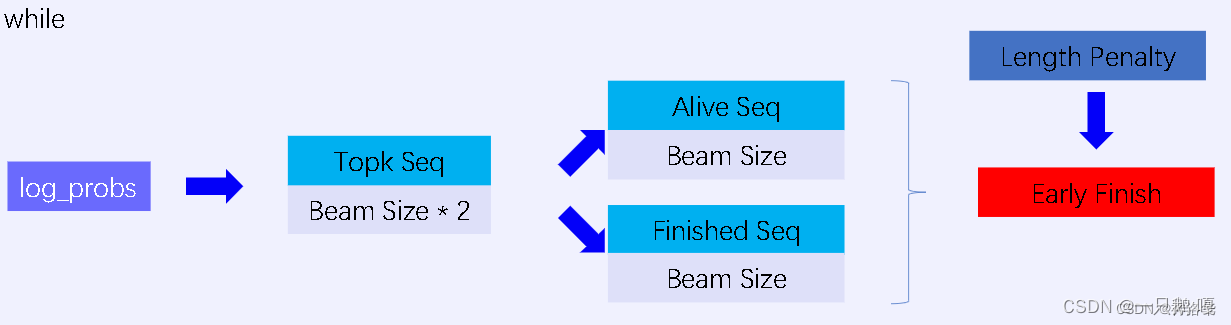
上述beam search中,每当出现eos_token_id则该分支完成解码放到容器中,所以每一个时间步生成的分支可能少于num_beams个。transformer论文源码tensor2tensor库中用到的beam_search维护两个候选序列的tensor:alive_seq和finished_seq,其中alive_seq中保留当前的时间步生成的Top k个序列,且没有终止符EOS,可以继续生成序列,finished_seq中始终更新为Top k个已经完成的序列(出现终止符EOS)。alive_seq可以保证每个时间步生成num_beams个序列(以下对应beam_size),搜索的空间会更大一些。
首先说明一些参数,symbols_to_logits_fn将上一个时间步得到的序列作为target进行decoder,再映射到vocab_size维;batch_size=3;beam_size=4,decode_length=7为生成的序列最大长度/时间步;sos_id=0为开始标志符;eos_id=1为结束标志符;initial_ids=(0,0,0)存放生成的序列,初始值为sos_id;beam search核心函数为beam_search,代码如下:
1. 初始化各项序列和概率值
初始化各项tensor:序列的输出概率alive_log_probs,shape为(batch_size,beam_size)。初始化alive_seq为sos_id,shape为(batch_size, beam_size, ?),finished_seq初始化全为0,shape为(batch_size, beam_size, ?),其中随着时间步的增加,最后一个维度+1,finished_scores初始化为-INF,shape为(batch_size, beam_size),finished_flags初始化为False,对应每一个样本的每一个分支是否完成。
def beam_search(symbols_to_logits_fn,
initial_ids,
beam_size,
decode_length,
vocab_size,
alpha,
states=None,
eos_id=EOS_ID,
stop_early=True,
use_tpu=False,
use_top_k_with_unique=True):
"""Beam search with length penalties.
Requires a function that can take the currently decoded symbols and return
the logits for the next symbol. The implementation is inspired by
https://arxiv.org/abs/1609.08144.
When running, the beam search steps can be visualized by using tfdbg to watch
the operations generating the output ids for each beam step. These operations
have the pattern:
(alive|finished)_topk_(seq,scores)
Operations marked `alive` represent the new beam sequences that will be
processed in the next step. Operations marked `finished` represent the
completed beam sequences, which may be padded with 0s if no beams finished.
Operations marked `seq` store the full beam sequence for the time step.
Operations marked `scores` store the sequence's final log scores.
The beam search steps will be processed sequentially in order, so when
capturing observed from these operations, tensors, clients can make
assumptions about which step is being recorded.
WARNING: Assumes 2nd dimension of tensors in `states` and not invariant, this
means that the shape of the 2nd dimension of these tensors will not be
available (i.e. set to None) inside symbols_to_logits_fn.
Args:
symbols_to_logits_fn: Interface to the model, to provide logits.
Shoud take [batch_size, decoded_ids] and return [batch_size, vocab_size]
initial_ids: Ids to start off the decoding, this will be the first thing
handed to symbols_to_logits_fn (after expanding to beam size)
[batch_size]
beam_size: Size of the beam.
decode_length: Number of steps to decode for.
vocab_size: Size of the vocab, must equal the size of the logits returned by
symbols_to_logits_fn
alpha: alpha for length penalty.
states: dict (possibly nested) of decoding states.
eos_id: ID for end of sentence.
stop_early: a boolean - stop once best sequence is provably determined.
use_tpu: A bool, whether to do beam search on TPU.
use_top_k_with_unique: bool, whether to use a fast (but decreased precision)
top_k during TPU beam search.
Returns:
Tuple of
(decoded beams [batch_size, beam_size, decode_length]
decoding probabilities [batch_size, beam_size])
"""
batch_size = common_layers.shape_list(initial_ids)[0]
# Assume initial_ids are prob 1.0
initial_log_probs = tf.constant([[0.] + [-INF] * (beam_size - 1)]) # (1,4) 初始化候选序列的概率
# Expand to beam_size (batch_size, beam_size)
alive_log_probs = tf.tile(initial_log_probs, [batch_size, 1]) # (3,4) 对应维度平铺复制,相当于复制了三行一样的
# Expand each batch and state to beam_size
alive_seq = _expand_to_beam_size(initial_ids, beam_size) # 当前时间步的候选序列 (3,4) 全为开始符id 0
alive_seq = tf.expand_dims(alive_seq, axis=2) # (batch_size, beam_size, 1) (3,4,1)
if use_tpu:
alive_seq = tf.tile(alive_seq, [1, 1, decode_length + 1])
if states:
states = nest.map_structure(
lambda state: _expand_to_beam_size(state, beam_size), states) # 缓存中的每一层的attention、kv、encoder output等,都在第二个维度复制4份,对应四份beam,(3,1,0,5)-->(3,4,1,0,5)
else:
states = {}
# Finished will keep track of all the sequences that have finished so far
# Finished log probs will be negative infinity in the beginning
# finished_flags will keep track of booleans
finished_seq = tf.zeros(common_layers.shape_list(alive_seq), tf.int32) # (3,4,1) 初始化全为0
# Setting the scores of the initial to negative infinity.
finished_scores = tf.ones([batch_size, beam_size]) * -INF # (3,4) 都是-INF
finished_flags = tf.zeros([batch_size, beam_size], tf.bool) # (3,4) 都是False
2. 序列扩展
时间步从0开始循环生成序列,该样本继续生成序列的条件:未达到最大序列长度decode_length并且finished_scores中最大值低于ali_score最大值,对应_is_not_finished=True,进入下一个循环,否则终止。
(_, alive_seq, alive_log_probs, finished_seq, finished_scores,
finished_flags, states) = tf.while_loop(
_is_not_finished,
inner_loop, [
tf.constant(0), alive_seq, alive_log_probs, finished_seq,
finished_scores, finished_flags, states
],
shape_invariants=[
tf.TensorShape([]),
inner_shape,
alive_log_probs.get_shape(),
inner_shape,
finished_scores.get_shape(),
finished_flags.get_shape(),
state_struc
],
parallel_iterations=1,
back_prop=False) # 循环,当alive中的最高得分低于finished中的结果,则结束循环,否则进入下一个时间步
def _is_not_finished(i, unused_alive_seq, alive_log_probs,
unused_finished_seq, finished_scores,
unused_finished_in_finished, unused_states):
"""Checking termination condition.
We terminate when we decoded up to decode_length or the lowest scoring item
in finished has a greater score that the highest prob item in alive divided
by the max length penalty
Args:
i: loop index
alive_log_probs: probabilities of the beams. [batch_size, beam_size]
finished_scores: scores for each of these sequences.
[batch_size, beam_size]
Returns:
Bool.
"""
max_length_penalty = tf.pow(((5. + tf.to_float(decode_length)) / 6.), alpha) # 2
# The best possible score of the most likely alive sequence.
lower_bound_alive_scores = alive_log_probs[:, 0] / max_length_penalty # (3,)
if not stop_early:
# by considering the min score (in the top N beams) we ensure that
# the decoder will keep decoding until there is at least one beam
# (in the top N) that can be improved (w.r.t. the alive beams).
# any unfinished beam will have score -INF - thus the min
# will always be -INF if there is at least one unfinished beam -
# which means the bound_is_met condition cannot be true in this case.
lowest_score_of_finished_in_finished = tf.reduce_min(finished_scores)
else: # True
# by taking the max score we only care about the first beam;
# as soon as this first beam cannot be beaten from the alive beams
# the beam decoder can stop.
# similarly to the above, if the top beam is not completed, its
# finished_score is -INF, thus it will not activate the
# bound_is_met condition. (i.e., decoder will keep going on).
# note we need to find the max for every sequence eparately - so, we need
# to keep the batch dimension (see axis=1)
lowest_score_of_finished_in_finished = tf.reduce_max(finished_scores,
axis=1) # finished_scores:(3,4) 都是-INF --> (3,)
bound_is_met = tf.reduce_all(
tf.greater(lowest_score_of_finished_in_finished,
lower_bound_alive_scores))
return tf.logical_and(
tf.less(i, decode_length), tf.logical_not(bound_is_met)) # 当时间步未达到decode_length时且alive_seq最优分大于finished_scores最高分时,继续循环
inner_loop函数是循环生成序列的主体函数,对于每一个时间步,分别执行三个操作:
-
- 每个时间步得到输出概率后,保留Top 2*beam_size个序列
-
- 从Top 2*beam_size中选取Top beam_size个不包含停止符eos的序列放入alive_seq中
-
- 从Top 2*beam_size中选取Top beam_size个包含停止符eos的序列放入finished_seq中
def inner_loop(i, alive_seq, alive_log_probs, finished_seq, finished_scores,
finished_flags, states):
"""Inner beam search loop.
There are three groups of tensors, alive, finished, and topk.
The alive group contains information about the current alive sequences
The topk group contains information about alive + topk current decoded words
the finished group contains information about finished sentences, that is,
the ones that have decoded to <EOS>. These are what we return.
The general beam search algorithm is as follows:
While we haven't terminated (pls look at termination condition)
1. Grow the current alive to get beam*2 topk sequences
2. Among the topk, keep the top beam_size ones that haven't reached EOS
into alive
3. Among the topk, keep the top beam_size ones have reached EOS into
finished
Repeat
To make things simple with using fixed size tensors, we will end
up inserting unfinished sequences into finished in the beginning. To stop
that we add -ve INF to the score of the unfinished sequence so that when a
true finished sequence does appear, it will have a higher score than all the
unfinished ones.
Args:
i: loop index
alive_seq: Topk sequences decoded so far [batch_size, beam_size, i+1]
alive_log_probs: probabilities of the beams. [batch_size, beam_size]
finished_seq: Current finished sequences.
[batch_size, beam_size, i+1]
finished_scores: scores for each of these sequences.
[batch_size, beam_size]
finished_flags: finished bools for each of these sequences.
[batch_size, beam_size]
states: dict (possibly nested) of decoding states.
Returns:
Tuple of
(Incremented loop index
New alive sequences,
Log probs of the alive sequences,
New finished sequences,
Scores of the new finished sequences,
Flags indicating which sequence in finished as reached EOS,
dict of final decoding states)
"""
# Each inner loop, we carry out three steps:
# 1. Get the current topk items.
# 2. Extract the ones that have finished and haven't finished
# 3. Recompute the contents of finished based on scores.
topk_seq, topk_log_probs, topk_scores, topk_finished, states = grow_topk(
i, alive_seq, alive_log_probs, states) # 选出前beam_size*2个词,分别返回Top 2k个合并后的序列、Top 2k个概率值、Top 2k个得分、(3,8)是否未eos符、cache
alive_seq, alive_log_probs, _, states = grow_alive(
topk_seq, topk_scores, topk_log_probs, topk_finished, states) # 选出前beam_size个最大值,及对应得分等
finished_seq, finished_scores, finished_flags, _ = grow_finished(
finished_seq, finished_scores, finished_flags, topk_seq, topk_scores,
topk_finished) # 把之前finished中的序列和Top 2k个新的序列放在一起,取Top k,其中包括休止符
return (i + 1, alive_seq, alive_log_probs, finished_seq, finished_scores,
finished_flags, states)
grow_topk在每个时间步,首先将已生成的序列作为target进行解码得到概率值,并乘以当前序列的概率值,得到新的序列的概率值和得分(加入了序列长度的惩罚项),选出beam_size * 2个最大值和索引,将原序列和新的token合并,返回新生成的序列和得分。
def grow_topk(i, alive_seq, alive_log_probs, states):
r"""Inner beam search loop.
This function takes the current alive sequences, and grows them to topk
sequences where k = 2*beam. We use 2*beam because, we could have beam_size
number of sequences that might hit <EOS> and there will be no alive
sequences to continue. With 2*beam_size, this will not happen. This relies
on the assumption the vocab size is > beam size. If this is true, we'll
have at least beam_size non <EOS> extensions if we extract the next top
2*beam words.
Length penalty is given by = (5+len(decode)/6) ^ -\alpha. Pls refer to
https://arxiv.org/abs/1609.08144.
Args:
i: loop index
alive_seq: Topk sequences decoded so far [batch_size, beam_size, i+1]
alive_log_probs: probabilities of these sequences. [batch_size, beam_size]
states: dict (possibly nested) of decoding states.
Returns:
Tuple of
(Topk sequences extended by the next word,
The log probs of these sequences,
The scores with length penalty of these sequences,
Flags indicating which of these sequences have finished decoding,
dict of transformed decoding states)
"""
# Get the logits for all the possible next symbols
if use_tpu and states:
flat_ids = tf.reshape(
tf.slice(alive_seq, [0, 0, i], [batch_size, beam_size, 1]),
[batch_size * beam_size, -1])
else:
flat_ids = tf.reshape(alive_seq, [batch_size * beam_size, -1]) # (12,?) 维度是变量因为会随着时间步的增加维度+1
# (batch_size * beam_size, decoded_length)
if states:
flat_states = nest.map_structure(_merge_beam_dim, states) # (3,?,?,?,5) --> (?,?,?,5) 前两个维度相乘
flat_logits, flat_states = symbols_to_logits_fn(flat_ids, i, flat_states) # 将上一个时间步得到的序列作为target进行decoder,再转为vocab_size维度 (12,10)
states = nest.map_structure(
lambda t: _unmerge_beam_dim(t, batch_size, beam_size), flat_states) # (3,4,?,?,5)
elif use_tpu:
flat_logits = symbols_to_logits_fn(flat_ids, i)
else:
flat_logits = symbols_to_logits_fn(flat_ids)
logits = tf.reshape(flat_logits, [batch_size, beam_size, -1]) # (3,4,10) 当前时间步得到的概率值
# Convert logits to normalized log probs
candidate_log_probs = common_layers.log_prob_from_logits(logits) # (3,4,10) log(softmax)
# Multiply the probabilities by the current probabilities of the beam.
# (batch_size, beam_size, vocab_size) + (batch_size, beam_size, 1)
log_probs = candidate_log_probs + tf.expand_dims(alive_log_probs, axis=2) # (3,4,10) 取log之后,相乘变成相加,加上原来alive_log_probs的概率(3,4,1)
length_penalty = tf.pow(((5. + tf.to_float(i + 1)) / 6.), alpha) # alpha
curr_scores = log_probs / length_penalty
# Flatten out (beam_size, vocab_size) probs in to a list of possibilities
flat_curr_scores = tf.reshape(curr_scores, [-1, beam_size * vocab_size]) # (3,40)
if use_tpu and use_top_k_with_unique:
topk_scores, topk_ids = top_k_with_unique(
flat_curr_scores, k=beam_size * 2)
else:
topk_scores, topk_ids = tf.nn.top_k(flat_curr_scores, k=beam_size * 2) # (3,8) 选出beam_size * 2个最大值,返回值和索引
# Recovering the log probs because we will need to send them back
topk_log_probs = topk_scores * length_penalty # (3,8)
# Work out what beam the top probs are in.
topk_beam_index = topk_ids // vocab_size # (3,8) 从0、1、2、3中选取,分别代表beam
topk_ids %= vocab_size # Unflatten the ids (3,8) 从0-9中选取,表示vocab
if not use_tpu:
# The next three steps are to create coordinates for tf.gather_nd to pull
# out the correct sequences from id's that we need to grow.
# We will also use the coordinates to gather the booleans of the beam
# items that survived.
batch_pos = compute_batch_indices(batch_size, beam_size * 2) # (3,8) 第一行为0 第二行为1 第三行为2
# top beams will give us the actual coordinates to do the gather.
# stacking will create a tensor of dimension batch * beam * 2, where the
# last dimension contains the i,j gathering coordinates.
topk_coordinates = tf.stack([batch_pos, topk_beam_index], axis=2) # (3,8,2) 最后一个维度分别代表batch和beam
# Gather up the most probable 2*beams both for the ids and
# finished_in_alive bools
topk_seq = tf.gather_nd(alive_seq, topk_coordinates) # 提取对应batch和beam的原序列,(3,8,?)
if states:
states = nest.map_structure(
lambda state: tf.gather_nd(state, topk_coordinates), states)
# Append the most probable alive
topk_seq = tf.concat([topk_seq, tf.expand_dims(topk_ids, axis=2)], axis=2) # (3,8,?) 将原序列和新的token合并,第3个维度是序列的长度
else:
# Gather up the most probable 2*beams both for the ids and
# finished_in_alive bools
topk_seq = fast_tpu_gather(alive_seq, topk_beam_index)
if states:
states = nest.map_structure(
lambda state: fast_tpu_gather(state, topk_beam_index), states)
# Update the most probable alive
topk_seq = tf.transpose(topk_seq, perm=[2, 0, 1])
topk_seq = inplace_ops.alias_inplace_update(topk_seq, i + 1, topk_ids)
topk_seq = tf.transpose(topk_seq, perm=[1, 2, 0])
topk_finished = tf.equal(topk_ids, eos_id) # (3,8) bool 判断是否为休止符
return topk_seq, topk_log_probs, topk_scores, topk_finished, states
grow_alive选取Top beam_size个不包括eos的序列(将休止符的位置变为-INF)作为alive_seq,保存的是每一个时间步的Top beam_size个不包括eos的序列。
def grow_alive(curr_seq, curr_scores, curr_log_probs, curr_finished, states):
"""Given sequences and scores, will gather the top k=beam size sequences.
Args:
curr_seq: current topk sequence that has been grown by one position.
[batch_size, beam_size, i+1]
curr_scores: scores for each of these sequences. [batch_size, beam_size]
curr_log_probs: log probs for each of these sequences.
[batch_size, beam_size]
curr_finished: Finished flags for each of these sequences.
[batch_size, beam_size]
states: dict (possibly nested) of decoding states.
Returns:
Tuple of
(Topk sequences based on scores,
log probs of these sequences,
Finished flags of these sequences)
"""
# Set the scores of the finished seq in curr_seq to large negative
# values
curr_scores += tf.to_float(curr_finished) * -INF # (3,8) 将休止符的位置变为-INF
return compute_topk_scores_and_seq(curr_seq, curr_scores, curr_log_probs,
curr_finished, beam_size, batch_size,
"grow_alive", states, use_tpu=use_tpu) # 选出前beam_size个最大值,及对应的概率等
def compute_topk_scores_and_seq(sequences,
scores,
scores_to_gather,
flags,
beam_size,
batch_size,
prefix="default",
states_to_gather=None,
use_tpu=False,
use_top_k_with_unique=True):
"""Given sequences and scores, will gather the top k=beam size sequences.
This function is used to grow alive, and finished. It takes sequences,
scores, and flags, and returns the top k from sequences, scores_to_gather,
and flags based on the values in scores.
This method permits easy introspection using tfdbg. It adds three named ops
that are prefixed by `prefix`:
- _topk_seq: the tensor for topk_seq returned by this method.
- _topk_flags: the tensor for topk_finished_flags returned by this method.
- _topk_scores: the tensor for tokp_gathered_scores returned by this method.
Args:
sequences: Tensor of sequences that we need to gather from.
[batch_size, beam_size, seq_length]
scores: Tensor of scores for each sequence in sequences.
[batch_size, beam_size]. We will use these to compute the topk.
scores_to_gather: Tensor of scores for each sequence in sequences.
[batch_size, beam_size]. We will return the gathered scores from here.
Scores to gather is different from scores because for grow_alive, we will
need to return log_probs, while for grow_finished, we will need to return
the length penalized scores.
flags: Tensor of bools for sequences that say whether a sequence has reached
EOS or not
beam_size: int
batch_size: int
prefix: string that will prefix unique names for the ops run.
states_to_gather: dict (possibly nested) of decoding states.
use_tpu: A bool, whether to compute topk scores and sequences on TPU.
use_top_k_with_unique: bool, whether to use a fast (but decreased precision)
top_k during TPU beam search.
Returns:
Tuple of
(topk_seq [batch_size, beam_size, decode_length],
topk_gathered_scores [batch_size, beam_size],
topk_finished_flags[batch_size, beam_size])
"""
if not use_tpu:
_, topk_indexes = tf.nn.top_k(scores, k=beam_size) # (3,4) scores为概率值和-INF,选出前beam_size个最大值和索引,因为是从40个里选出了Top8,最多只有4个vocab_size,所以这次选出的4个最大值一定没有休止符
# The next three steps are to create coordinates for tf.gather_nd to pull
# out the topk sequences from sequences based on scores.
# batch pos is a tensor like [[0,0,0,0,],[1,1,1,1],..]. It says which
# batch the beam item is in. This will create the i of the i,j coordinate
# needed for the gather
batch_pos = compute_batch_indices(batch_size, beam_size) # (3,4) 第一行为0 、第二行为1、第三行为2
# top coordinates will give us the actual coordinates to do the gather.
# stacking will create a tensor of dimension batch * beam * 2, where the
# last dimension contains the i,j gathering coordinates.
top_coordinates = tf.stack([batch_pos, topk_indexes], axis=2) # (3,4,2) 最后一个维度对应batch和Top k索引
# Gather up the highest scoring sequences. For each operation added, give
# it a concrete name to simplify observing these operations with tfdbg.
# Clients can capture these tensors by watching these node names.
def gather(tensor, name):
return tf.gather_nd(tensor, top_coordinates, name=(prefix + name))
topk_seq = gather(sequences, "_topk_seq") # (3,4,?) 从topk_seq(3,8,?)中选取最大的词
topk_flags = gather(flags, "_topk_flags") # (3,4) 应该都是True?
topk_gathered_scores = gather(scores_to_gather, "_topk_scores") # (3,4) 对应得分
if states_to_gather:
topk_gathered_states = nest.map_structure(
lambda state: gather(state, "_topk_states"), states_to_gather)
else:
topk_gathered_states = states_to_gather
else:
if use_top_k_with_unique:
_, topk_indexes = top_k_with_unique(scores, k=beam_size)
else:
_, topk_indexes = tf.nn.top_k(scores, k=beam_size)
# Gather up the highest scoring sequences. For each operation added, give
# it a concrete name to simplify observing these operations with tfdbg.
# Clients can capture these tensors by watching these node names.
topk_seq = fast_tpu_gather(sequences, topk_indexes, prefix + "_topk_seq")
topk_flags = fast_tpu_gather(flags, topk_indexes, prefix + "_topk_flags")
topk_gathered_scores = fast_tpu_gather(scores_to_gather, topk_indexes,
prefix + "_topk_scores")
if states_to_gather:
topk_gathered_states = nest.map_structure(
# pylint: disable=g-long-lambda
lambda state: fast_tpu_gather(state, topk_indexes,
prefix + "_topk_states"),
states_to_gather)
else:
topk_gathered_states = states_to_gather
return topk_seq, topk_gathered_scores, topk_flags, topk_gathered_states
grow_finished函数,将原来的beam_size个序列和新生成的2*beam_size个序列合并,选取Top beam_size个最优的序列,其中优先选取包含eos的序列(通过将不包含eos的位置设为-INF)。
def grow_finished(finished_seq, finished_scores, finished_flags, curr_seq,
curr_scores, curr_finished):
"""Given sequences and scores, will gather the top k=beam size sequences.
Args:
finished_seq: Current finished sequences.
[batch_size, beam_size, current_decoded_length]
finished_scores: scores for each of these sequences.
[batch_size, beam_size]
finished_flags: finished bools for each of these sequences.
[batch_size, beam_size]
curr_seq: current topk sequence that has been grown by one position.
[batch_size, beam_size, current_decoded_length]
curr_scores: scores for each of these sequences. [batch_size, beam_size]
curr_finished: Finished flags for each of these sequences.
[batch_size, beam_size]
Returns:
Tuple of
(Topk sequences based on scores,
log probs of these sequences,
Finished flags of these sequences)
"""
if not use_tpu:
# First append a column of 0'ids to finished to make the same length with
# finished scores
finished_seq = tf.concat(
[finished_seq,
tf.zeros([batch_size, beam_size, 1], tf.int32)], axis=2) # (3,4,?)
# Set the scores of the unfinished seq in curr_seq to large negative
# values
curr_scores += (1. - tf.to_float(curr_finished)) * -INF # (3,8) 休止符的地方得分正常,其余地方为-INF
# concatenating the sequences and scores along beam axis
curr_finished_seq = tf.concat([finished_seq, curr_seq], axis=1) # (3,12,?)
curr_finished_scores = tf.concat([finished_scores, curr_scores], axis=1) # (3,12)
curr_finished_flags = tf.concat([finished_flags, curr_finished], axis=1) # (3,12)
return compute_topk_scores_and_seq(
curr_finished_seq,
curr_finished_scores,
curr_finished_scores,
curr_finished_flags,
beam_size,
batch_size,
"grow_finished",
use_tpu=use_tpu,
use_top_k_with_unique=use_top_k_with_unique)
3. 准备输出
为了防止一直未出现eos,finished_flags中没有该序列,用alive_seq补充。最后每个样本取top_beams个最优序列。
inner_shape = tf.TensorShape([None, None, None])
if use_tpu:
inner_shape = tf.TensorShape([batch_size, beam_size, decode_length + 1])
if use_tpu:
state_struc = nest.map_structure(lambda state: state.get_shape(), states)
else:
state_struc = nest.map_structure(get_state_shape_invariants, states) # 将states中间设为none(3,4,1,5,8)-->(3,None,None,None,8)
alive_seq.set_shape((None, beam_size, None))
finished_seq.set_shape((None, beam_size, None))
# Accounting for corner case: It's possible that no sequence in alive for a
# particular batch item ever reached EOS. In that case, we should just copy
# the contents of alive for that batch item. tf.reduce_any(finished_flags, 1)
# if 0, means that no sequence for that batch index had reached EOS. We need
# to do the same for the scores as well.
finished_seq = tf.where(
tf.reduce_any(finished_flags, 1), finished_seq, alive_seq) # 第一个参数对应的位置为True,则保留finished_seq(?,4,?)该位置处的值,否则alive_seq(?,4,?)该位置处的值
# 和上述没有出现eos手动添加到容器中类似
finished_scores = tf.where(
tf.reduce_any(finished_flags, 1), finished_scores, alive_log_probs)
return finished_seq, finished_scores, states
if top_beams == 1:
decoded_ids = decoded_ids[:, 0, 1:] # (?,?) 保留第一个最大的,因为返回topk是逆序排列的,第三个维度的第0个值是sos,所以从第1个值开始
scores = scores[:, 0] #(3,)
else:
decoded_ids = decoded_ids[:, :top_beams, 1:]
scores = scores[:, :top_beams]
总的来说,tensor2tensor中束搜索的思想与上述类似,实现细节有些不同,看完第一部分的束搜索再看t2t中的实现就容易些了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









