







递归算法通过一个函数在执行过程中一次或者多次调用其本身实现,或通过一种数据结构在其表示中依赖于相同类型的结构更小的实例,
递归主要分为三类:线性递归、二路递归和多重递归。
一、线性递归
如果一个递归函数被设计成所述主体的每个调用至多执行一个新的递归调用,这被称为线性递归。
阶乘函数:
def factorial(n):
"""
calculate the factorial of n
:param n: unsigned int
:return: unsigned int
"""
if n == 0:
return 1
else:
return n*factorial(n-1)
二分查找法:
def binary_search(data, target, low, high):
"""Return True if target is found in indicated portion of a python list
The search only considers the portion from data[low] data[high] inclusive
:param data: list
:param target: single value(int, float...)
:param low: unsigned int
:param high: unsigned int
:return: bool
"""
if low > high:
return False
else:
mid = (low + high) // 2
if target == data[mid]:
return True
elif target < data[mid]:
# recur on the portion left of the middle
return binary_search(data, target, low, high - 1)
else:
# recur on the portion right of the middle
return binary_search(data, target, mid + 1, high)
二、二路递归
当一个函数执行两个递归调用时,它便是二路递归。
二路递归计算一个序列元素之和:
def binary_sum(ls, start, stop):
"""
return the sum of the numbers in implicit slice ls[start:stop]
:param ls: list
:param start: unsigned int
:param stop: unsigned int
:return: sum of ls(int or float)
"""
if start > stop: # zero elements in slice
return 0
elif start == stop - 1: # one element in slice
return ls[start]
else:
mid = (start + stop) // 2
return binary_sum(ls, start, mid) + binary_sum(ls, mid, stop)
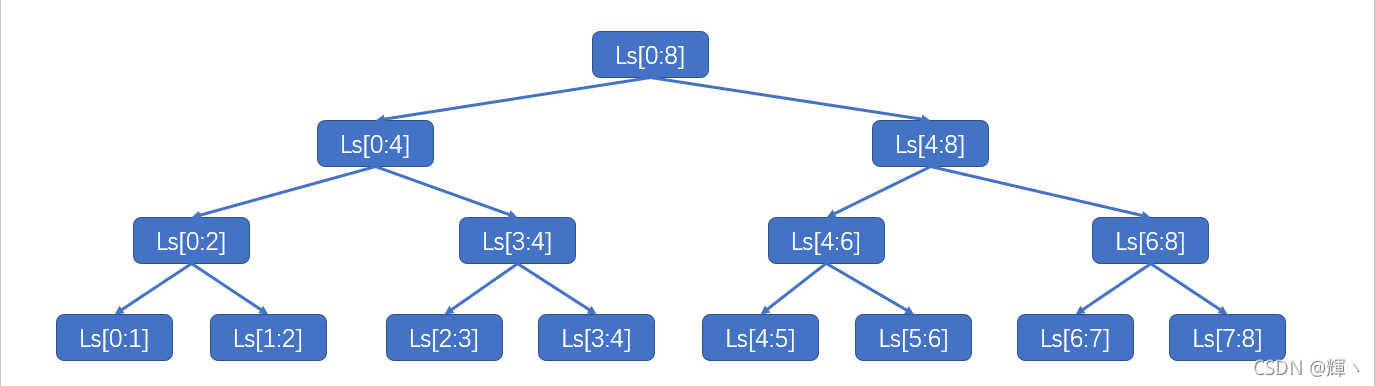
ls[0:8]的递归追踪图如下(图有点丑,大家将就看下就好QAQ):
三、多重递归
在多重递归这个过程中,一个函数可能会执行多余两次的递归调用。
文件系统磁盘分析递归函数:
def disk_usage(path):
"""
Return the number of bytes used by a file/folder and any descendents.
:param path: string
:return: unsigned int
"""
total = os.path.getsize(path)
if os.path.isdir(path):
for filename in os.listdir(path):
childpath = os.path.join(path, filename)
total += disk_usage(childpath)
print(f'{total:<7} {path}')
return total
四、设计递归算法
要为给定的问题设计递归算法,考虑我们可以定义的子问题的不同方式是非常有用的,该子问题与原始问题有相同的总体结构。
递归设计有时需要重新定义原来的问题,以便找到看起来相似的子问题,通常涉及参数化函数的特征码。例如在二分查找算法时,对调用者的自然函数特征码将显示为binary_search(data, target),我们在写算法时,调用特征码binary_search(data, target, low, high)定义函数,并且使用额外的参数说明子列表作为递归过程。
五、基于递归算法的排列、组合
全排列算法:(参考博客:https://blog.csdn.net/m0_38008539/article/details/95178298)
def perm(data):
"""
full Permutation of data
:param data: list
:return: double list
"""
if len(data) == 1: # 和阶乘一样,需要有个结束条件
return [data] # 这里是双重列表
r = []
for i in range(len(data)):
s = data[:i] + data[i + 1:] # 去掉第i个元素,进行下一次的递归
p = perm(s)
for x in p:
r.append(data[i:i + 1] + x) # 一直进行累加
return r
组合算法:(在全排列算法的基础上做出的修改)
def comb(data, n):
"""
the combination of n elements in data
:param data: list
:param n: unsigned int (<=len(data))
:return: double list
"""
if n == 0: # n=0 不需要取元素
return [[]] # 这里是双重列表
r = []
for i in range(len(data)-n+1):
s = data[i] # 第i个元素作为这次递归选择的元素
rest = data[i + 1:] # 将第i个元素后面的元素放入下一次递归
p = comb(rest, n-1)
for x in p:
r.append([s] + x) # 一直进行累加
return r
















 4576
4576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











