







Python_文件操作_深入
- 按文件中数据的组织形式把文件分为文本文件和二进制文件两大类
- 文本文件:存储常规字符串,由若干文本行组成,通常每行以换行符‘\n’结尾
- 二进制文件:存储字节串(bytes)形式的对象内容,通常是在bin目录下的可执行文件
1. 文件对象
- Python内置了文件对象,通过open()函数指定模式打开指定文件并创建文件对象。
- 语法:
文件对象名=open(文件名[,打开方式[,缓冲区]])
- 语法:
- 文件对象常用属性:

2.文本文件操作案例
- 通过几个实例来演示文本文件的读写操作。
- 对于read,write以及其他读写方法,当读写完成后,都会自动移动文件指针。如果需要对文件指针进行定位,可以使用seek方法,如果需要获知文件指针当前位置可以用tell方法
2.1 向文本文件中写入内容
f = open(r'C:\Users\ASUS\Desktop\sample.txt','a+')
s = '文本文件的读取方法\n文本文件的写入方法\n'
f.write(s)
f.close() # 每次io过程都要记得最后释放io流资源
- 使用上下文关键字with可以自动管理资源,无论何种原因跳出with块,总能保证文件被正确关闭,并且可以在代码块执行完毕后自动还原进入该代码块时的现场
## 对于上面的代码,建议写成如下形式:
s = '文本文件的读取方法\n文本文件的写入方法\n'
with open(r'C:\Users\ASUS\Desktop\sample.txt','a+') as f:
f.write(s)
2.2 读取并显示文本文件的前5个字节
fp=open(r'C:\Users\ASUS\Desktop\sample.txt','r')
print(fp.read(5))
fp.close()
文本文件的
2.3 读取并显示文本文件所有行
fp=open(r'C:\Users\ASUS\Desktop\sample.txt','r')
while True:
line = fp.readline()
if line == '': #读到最后一行停止while
break
print(line)
fp.close()
文本文件的读取方法
文本文件的写入方法
文本文件的读取方法
文本文件的写入方法
## 也可以写成这样:
f=open(r'C:\Users\ASUS\Desktop\sample.txt','r')
li = f.readlines()
for line in li:
print(line)
f.close()
文本文件的读取方法
文本文件的写入方法
文本文件的读取方法
文本文件的写入方法
2.4移动文件指针
- 铜鼓哟
s = '大漠孤烟直DMGYZ'
fp = open(r'C:\Users\ASUS\Desktop\sample.txt','w+')
fp.write(s)
fp.flush()
fp.close()
fp = open(r'C:\Users\ASUS\Desktop\sample.txt','r+')
fp.read(3)
'大漠孤'
fp.seek(2)
2
fp.read(1)
'漠'
fp.seek(10)
fp.read(1)
'D'
2.5读取文本文件data.txt中的所有整数,并将其按升序排序后再写入文本文件data_asc.txt中
import re
pattern = re.compile(r'\d+')
fp = open(r'C:\Users\ASUS\Desktop\data.txt','r')
lines = fp.readlines()
data = []
for line in lines:
matchResult = pattern.findall(line) # 得到的是存放了多个数字的数组
for i in matchResult:
data.append(int(i))
data.sort()
print(data)
fp.close()
fw = open(r'C:\Users\ASUS\Desktop\data_asc.txt','w')
fw.writelines(str(data))
[12, 41, 51, 123, 456]
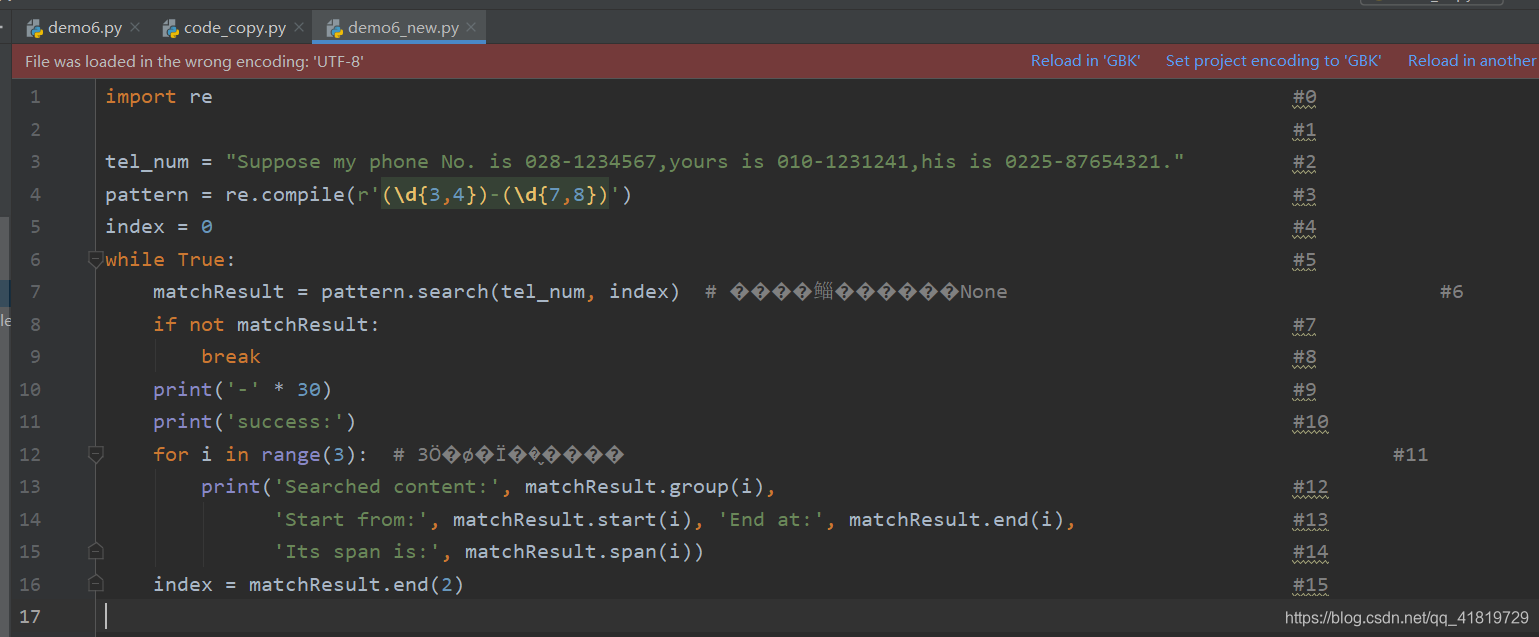
2.6 编写程序,保存为demo6.py,运行后生成文件 demo6_new.py,其中的内容与demo6.py一致,但是在每行的行尾加上了行号
filename = 'demo6.py'
with open(filename, 'r', encoding='UTF-8') as fp:
lines = fp.readlines()
lines = [line.rstrip() + ' ' * (100 - len(line)) + '#' + str(index) + '\n' for index, line in enumerate(lines)]
with open(filename[:-3] + '_new.py', 'w') as fp:
fp.writelines(lines)
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-52-1f094e103c11> in <module>
1 filename = 'demo6.py'
----> 2 with open(filename, 'r', encoding='UTF-8') as fp:
3 lines = fp.readlines()
4 lines = [line.rstrip() + ' ' * (100 - len(line)) + '#' + str(index) + '\n' for index, line in enumerate(lines)]
5 with open(filename[:-3] + '_new.py', 'w') as fp:
FileNotFoundError: [Errno 2] No such file or directory: 'demo6.py'
- 在IDEL中效果如下:

3.二进制文件操作案例
在操作二进制文件时需要对其进行序列化和反序列化
- Python中常用的序列化模块由struct,pickle,json,marshal和shelve,其中oikle由C语言实现的cPickle,速度相比较其他模块块将近1000倍!优先考虑使用
3.1 使用pickle模块
- dump(arg,file_object):向目标文件写入二进制数据
- load(file_object):从目标文件中读二进制数据加载到当前程序内存
- 在程序中第一次使用得到数据个数,然后文件指针后移到文件content区域
- 使用while 或 for +load依次从上向下读取文件内容
使用pickle模块写入二进制文件
import pickle
f = open('sample_pickle.dat','wb') # 注意打开方式要加上'b'
n = 7
i = 13000000
a = 99.056
s= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 272
272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









