







前言
之前的文章介绍了数据库的大致结构,日志模块和事务。今天我们接着来介绍数据库比较重要的一部分,数据库的索引。索引的本质就像书的目录一样,是为了提升查询速度而用的。
索引常见模型
索引的常见模型大致有四种
1.hash索引:本质就是一个数组加链表,和当初介绍的hashmap的底层十分的相似,这种的支持精确查找,也就是等值查找,但是对于范围查找不是很友好,因为数组里面的值不是有序的。当你查询2到100这种数据的时候,他只能一个一个查找。
2.数组:查询的时候不管是范围查找还是等值查找都会很快,因为他是按照顺序存储数据的。但是同样,他也会有数据的弊端,那就是增加和删除数据的时候,修改索引将会非常的耗时。
3.平衡二叉搜索树:他的查询复杂度和插入复杂度都是logn,看起来是不是很适合做索引呢。但是有一个问题,如果数据量很大的话,这个树的根就会比较深,所用的数据块就会比较多,这样的话,在查询数据随机访问数据快的次数就会比较多。但是随机访问数据快耗时比较大,所以平衡二叉树也不是十分的适合
4。b+树:作为innodb的索引存储结构,他就比二叉树适合磁盘的访问方式。因为他是n叉树,所以同样的数据,他会比二叉树的根节点深度要小很多。但是他也具有平衡二叉树的特点,它算是平衡n叉树。
InnoDB 的索引模型
从上面大家可以知道,innodb 的索引采用的是n叉树,那么索引里到底存储的是什么数据呢,普通索引和主键索引又有什么区别呢。看下图
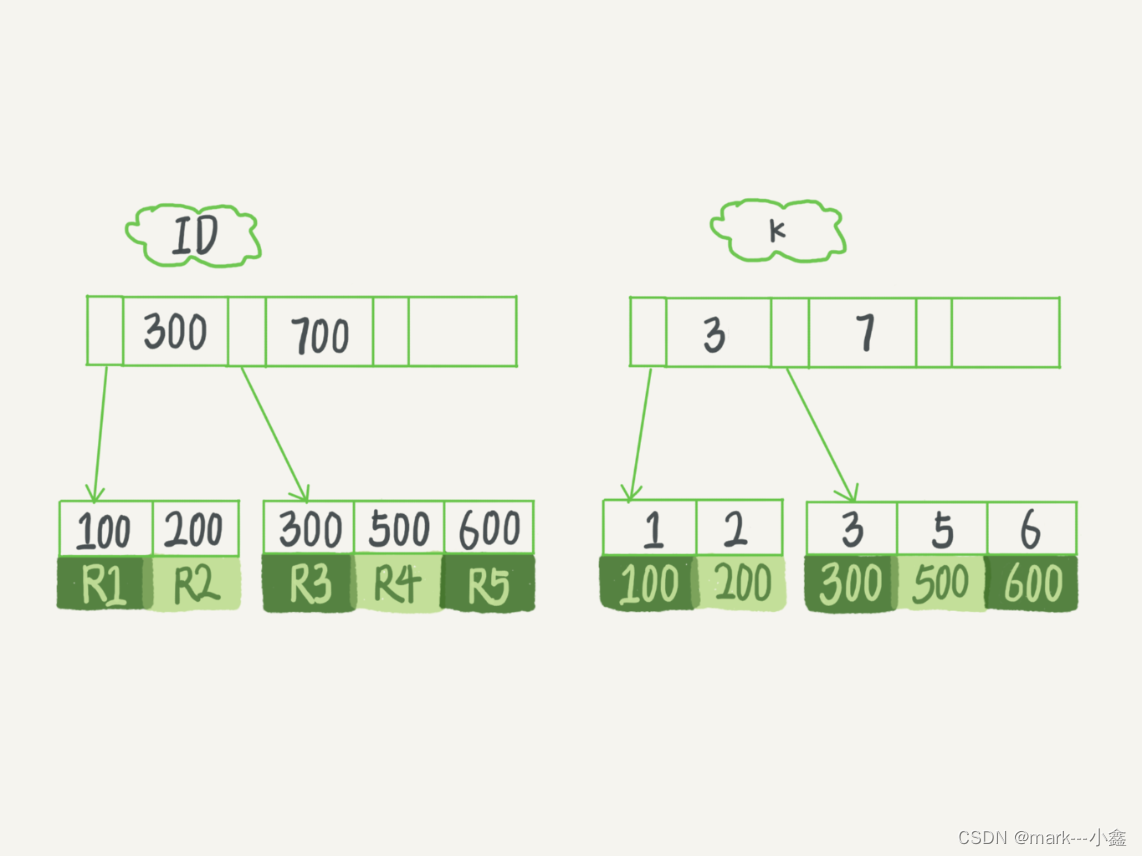
R1代表的是一行的数据。由图我们可以看出,主键索引存储的是一整行的数据,而普通索引存储的是主键索引的值,所以通过普通索引查数据的时候,现在普通索引树上面找到对应的主键索引值,然后再去主键索引树上找到对应的行记录。由此我们可以知道为什么主键索引会比普通索引快了,因为少了一次树的搜索。
索引的维护
以上面的图为例,如果在id300和500之间插入一个id为400的数据索引,在空间足够的情况下,只需要将后面的数据往后挪一个位置(其实也比较麻烦),如果数据页的大小不够,则会再申请一个数据页,将部分数据挪过去,称之为页分裂,这样两个页都没满,数据利用率就会比较低(大概降低0.5)。当然你删除数据之后,导致数据页的利用率过低,他也会进行合并。
在一些时候,有的公司会要求,创建表的时候必须以自增主键为id,这是为什么呢,这是因为一个方面是int类型只占四个字节,比较小,这样普通索引的节点数据也会比较小,节省空间。还有一个原因就是,自增的主键是追加的,不会出现我们上面的那种中间插入的方式,这样维护索引的成本会比较低,因为尾叉不需要挪动数据,复杂度会比较低。大致就是基于这两个方面,所以好多公司会要求你用自增主键。
总结
今天,我们介绍集中常见的索引模型,又重点介绍了innodb的索引模型,同时分析了为什么主键索引会比普通索引查询速度快。最后介绍了下,为什么好多公司喜欢用自增主键做索引。
















 2073
2073











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











