






面向子空间基于规则嵌入的论文相似性比较-ysl
创新实训个人过程记录
我负责的部分是论文摘要基于语义的子空间关键词提取并且比较关键词相似度,采用bertfortokenclassification进行关键词提取。
简单介绍一下bert
首先需要知道transformer,和大多数seq2seq模型一样,transformer的结构也是由encoder和decoder组成。不一样的是多头注意力机制扩展了模型专注于不同位置的能力,给出了注意力层的多个“表示子空间”。输入向量添加了位置编码,变为基于时间步的词嵌入,加入残差网络。
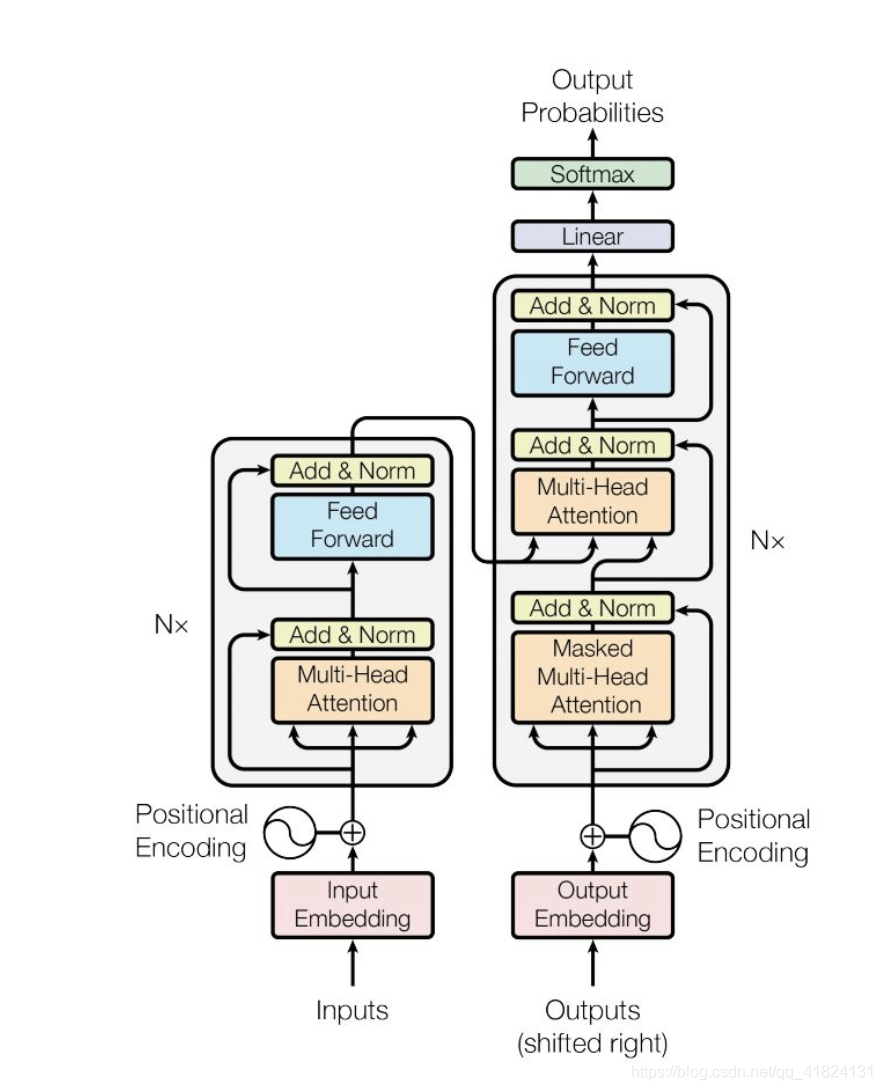
bert的结构就是双向的Transformer block连接
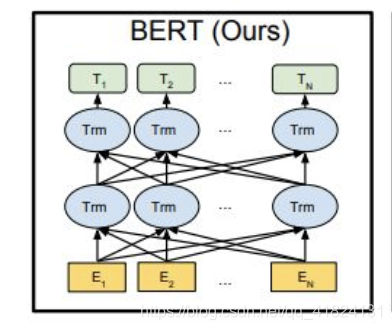
词的嵌入也加入了token embedding和position embedding(学习得出)
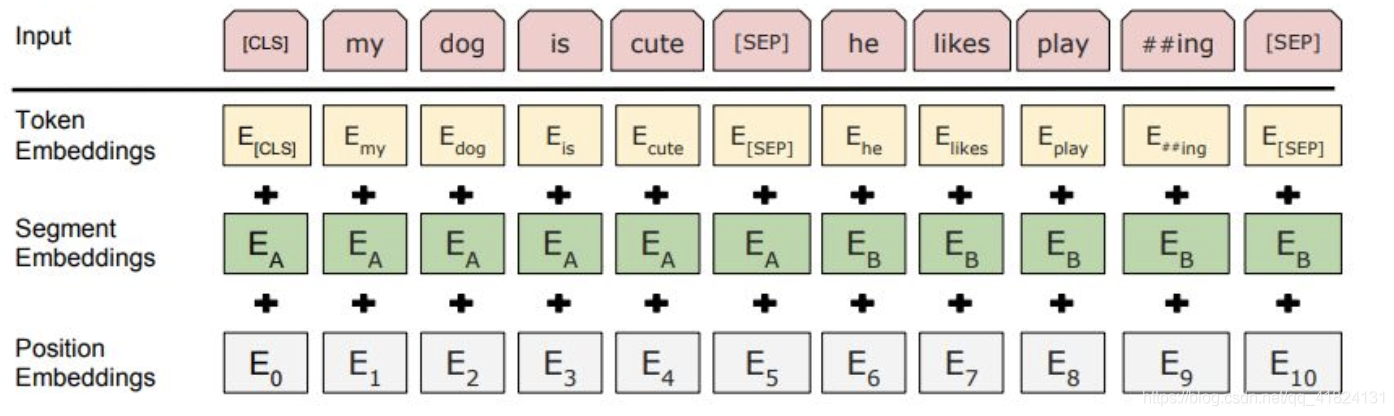
bert词性标注
BERT通过”Fill in the blank task” 以及 “Next sentence prediction” 两个任务进行预训练。在预训练模型的基础上稍加修改就可以处理多个下游任务。如下图所示,中文文本的序列标注问题,每个序列的第一个token始终是特殊分类嵌入([CLS]),剩下的每一个token代表一个汉字。BERT的input embeddings 是token embeddings, segmentation embeddings 和position embeddings的总和。其中token embeddings是词(字)向量,segment embeddings 用来区分两种句子,只有一个句子的任务(如序列标注),可以用来区分真正的句子以及句子padding的内容,而position embedding保留了每个token的位置信息。BERT的output 是每个token的encoding vector。只需要在BERT的基础上增加一层全连接层并确定全连接层的输出维度,便可把embedding vector映射到标集合。词性标注问题的标签集合即中文中所有词性的集合。
思路
通过Sem-Eval 2010关键字识别数据集训练BertForTokenClassification,输出bio标注的词序列,默认b和I为较重要词语,作为关键词输出。
主要代码
1.数据集:Sem-Eval 2010关键字识别数据集,论文基于规则判断的子空间的语句
2.数据预处理
将Sem-Eval 2010关键字识别数据集转换为BIO格式数据集。
def convert(key):
sentences = ""
for line in open(train_path + "/" + filekey[key], 'r'):
sentences += (" " + line.rstrip())
tokens = sent_tokenize(sentences)
key_file = open(train_path + "/" + str(key),'r')
keys = [line.strip() for line in key_file]
key_sent = []
labels = []
for token in tokens:
z = ['O'] * len(token.split())
for k in keys:
if k in token:
if len(k.split())==1:
try:
z[token.lower().split().index(k.lower().split()[0])] = 'B'
except ValueError:
continue
elif len(k.split())>1:
try:
if token.lower().split().index(k.lower().split()[0]) and token.lower().split().index(k.lower().split()[-1]):
z[token.lower().split().index(k.lower().split()[0])] = 'B'
for j in range(1, len(k.split())):
z[token.lower().split().index(k.lower().split()[j])] = 'I'
except ValueError:
continue
for m, n in enumerate(z):
if z[m] == 'I' and z[m-1] == 'O':
z[m] = 'O'
if set(z) != {'O'}:
labels.append(z)
key_sent.append(token)
return key_sent, labels
3.加载模型
model = BertForTokenClassification.from_pretrained("bert-base-uncased", num_labels=len(tag2idx))
4.训练模型
epochs = 4
max_grad_norm = 1.0
for _ in trange(epochs, desc="Epoch"):
# TRAIN loop
model.train()
tr_loss = 0
nb_tr_examples, nb_tr_steps = 0, 0
for step, batch in enumerate(train_dataloader):
# add batch to gpu
batch = tuple(t.to(device) for t in batch)
b_input_ids, b_input_mask, b_labels = batch
# forward pass
loss = model(b_input_ids, token_type_ids=None,
attention_mask=b_input_mask, labels=b_labels)
# backward pass
loss.backward()
# track train loss
tr_loss += loss.item()
nb_tr_examples += b_input_ids.size(0)
nb_tr_steps += 1
# gradient clipping
torch.nn.utils.clip_grad_norm_(parameters=model.parameters(), max_norm=max_grad_norm)
# update parameters
optimizer.step()
model.zero_grad()
# print train loss per epoch
print("Train loss: {}".format(tr_loss/nb_tr_steps))
# VALIDATION on validation set
model.eval()
eval_loss, eval_accuracy = 0, 0
nb_eval_steps, nb_eval_examples = 0, 0
predictions , true_labels = [], []
for batch in valid_dataloader:
batch = tuple(t.to(device) for t in batch)
b_input_ids, b_input_mask, b_labels = batch
with torch.no_grad():
tmp_eval_loss = model(b_input_ids, token_type_ids=None,
attention_mask=b_input_mask, labels=b_labels)
logits = model(b_input_ids, token_type_ids=None,
attention_mask=b_input_mask)
logits = logits.detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()
predictions.extend([list(p) for p in np.argmax(logits, axis=2)])
true_labels.append(label_ids)
tmp_eval_accuracy = flat_accuracy(logits, label_ids)
eval_loss += tmp_eval_loss.mean().item()
eval_accuracy += tmp_eval_accuracy
nb_eval_examples += b_input_ids.size(0)
nb_eval_steps += 1
eval_loss = eval_loss/nb_eval_steps
print("Validation loss: {}".format(eval_loss))
print("Validation Accuracy: {}".format(eval_accuracy/nb_eval_steps))
pred_tags = [tags_vals[p_i] for p in predictions for p_i in p]
valid_tags = [tags_vals[l_ii] for l in true_labels for l_i in l for l_ii in l_i]
print("F1-Score: {}".format(f1_score(pred_tags, valid_tags)))
训练结果
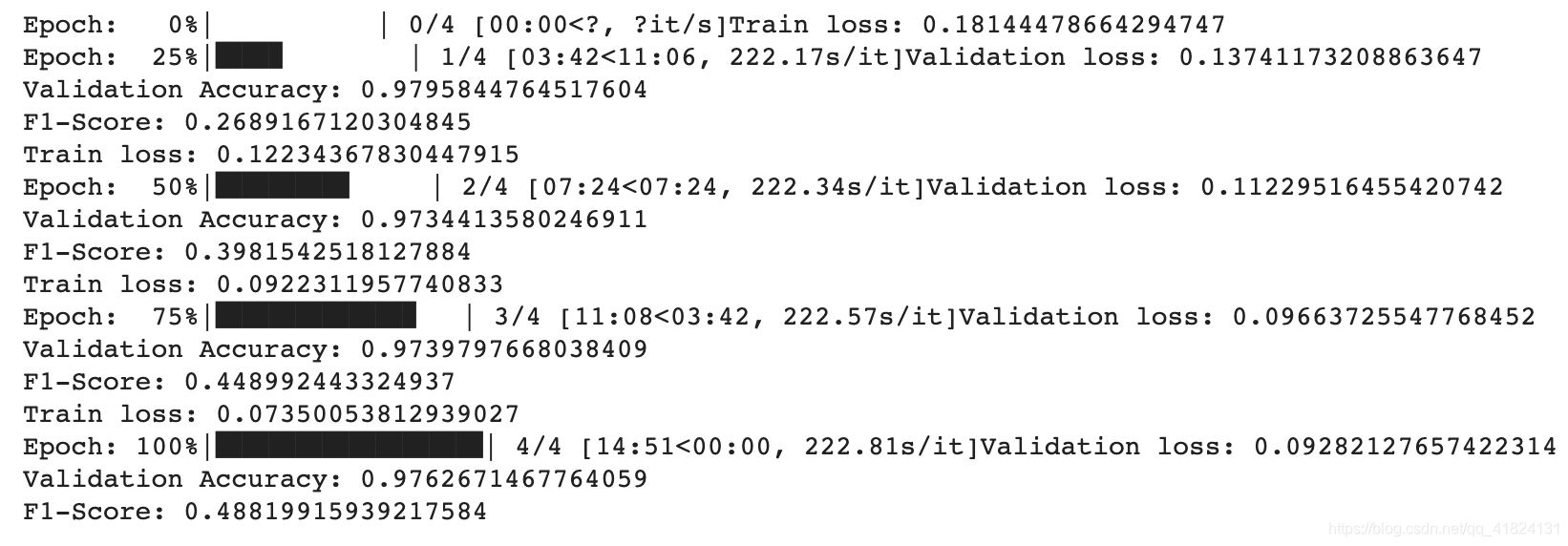
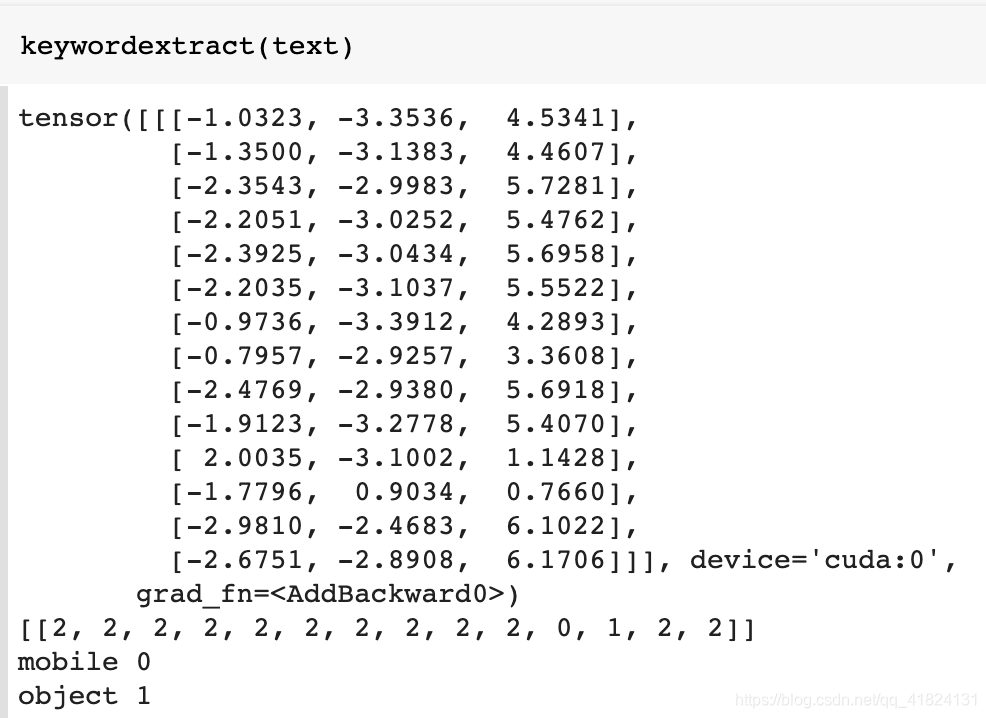
4.关键词提取
tensor为类别loss,数组为输出序列bio,最后两行为关键词结果
存在问题
属于bi分类的词语较少,提取出的关键词数量较少,所以需要其他基于统计信息的方法进行关键词的补充,尝试kea算法,tfidf,textrank等进行补充。
参考
https://cloud.tencent.com/developer/article/1454904
https://zhuanlan.zhihu.com/p/46652512
https://github.com/ibatra/BERT-Keyword-Extractor
以及链接中的论文














 276
276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









