






Zookeeper(一)——ZK介绍、搭建服务器、内部数据模型(如何保存数据、数据结构、节点类型与操作、数据持久化)、ZK客户端(节点数据和权限操作)、Curator的使用(Java代码操作ZK)
一、Zookeeper介绍
1、什么是 Zookeeper
Zookeeper 是一种分布式协调服务,用于管理大型主机。在分布式环境中协调和管理服务是一个复杂的过程,ZooKeeper通过其简单的架构和API解决了这个问题。ZooKeeper 能让开发人员专注于核心应用程序逻辑,而不必担心应用程序的分布式特性。
2、应用场景
- 分布式协调组件
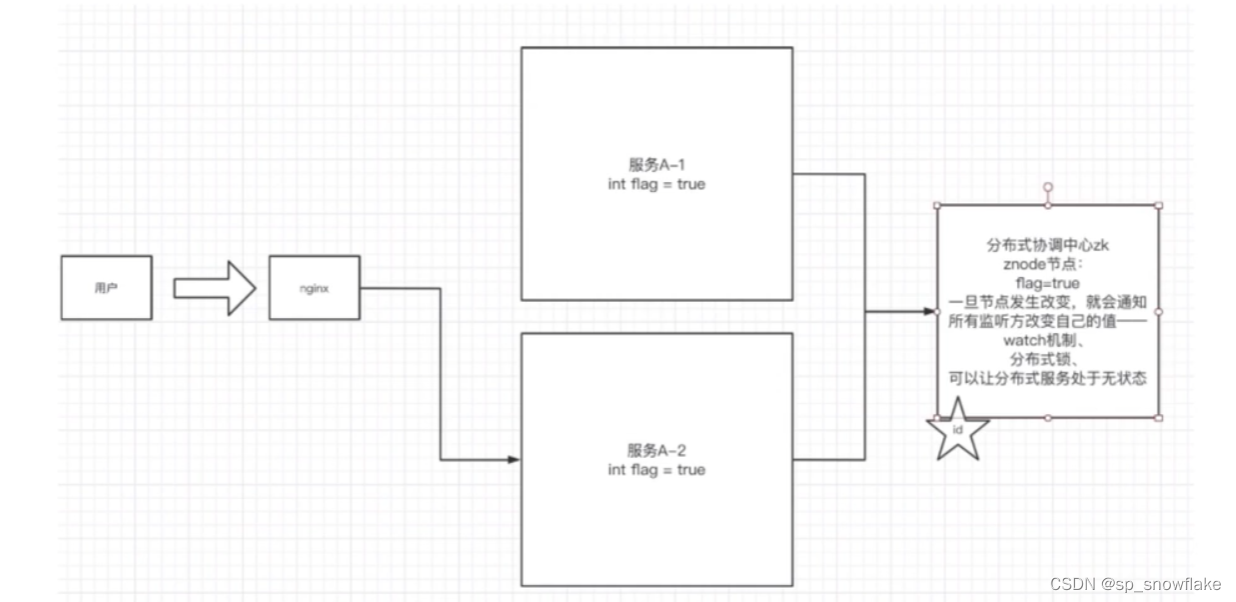
看上图,现在有两个组件,里面都有 flag 这个变量,如果修改其中一个为 false,那么另外一个并不会一起改变;那么这时候可以通过 Zookeeper 来帮我们完成这个协调的工作,一旦其中一个服务修改为 false,Zookeeper监听到以后,会通知另外的服务一起改变这个值。
- 分布式锁
zk在实现分布式锁上,可以做到强一致性,关于分布式锁的相关知识,会在之后的ZAB协议中介绍
- 无状态化的实现
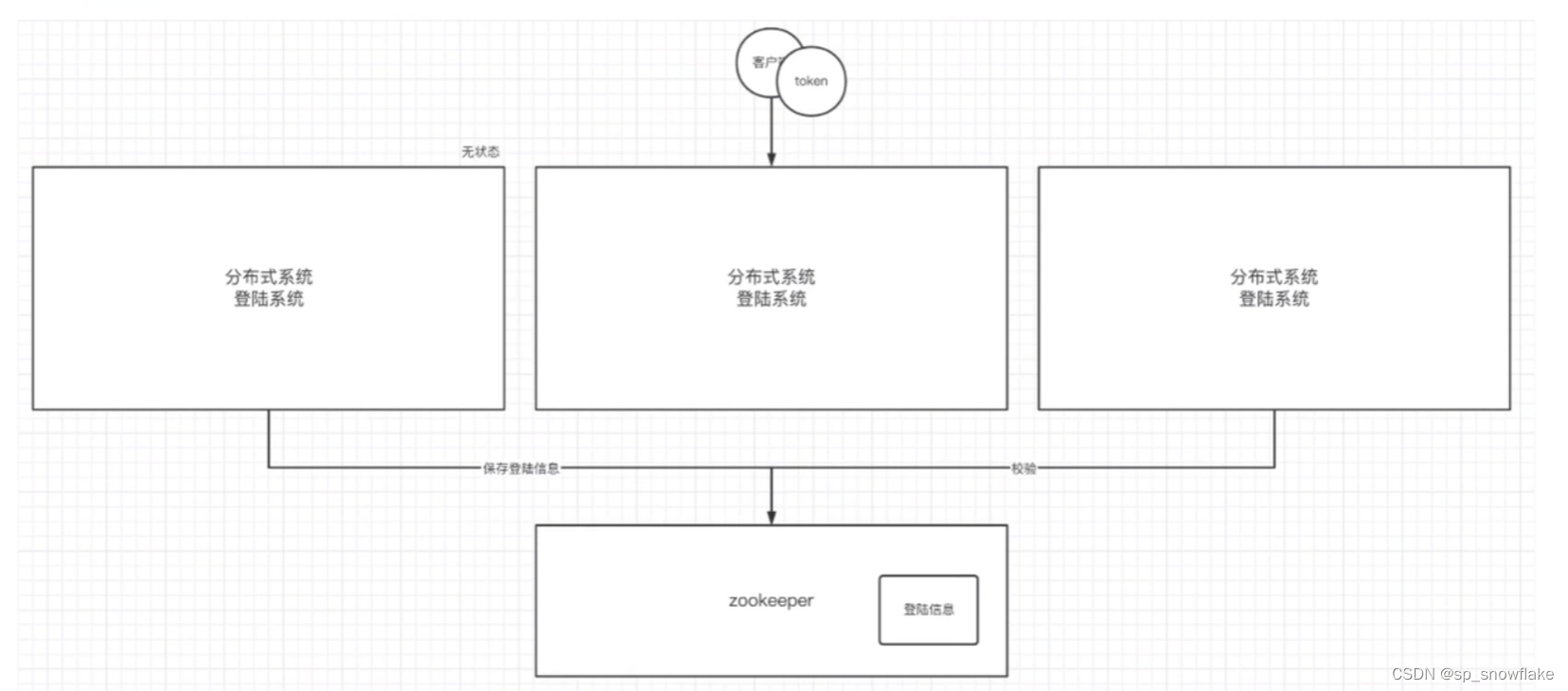
登录状态储存在数据中心 ZK 中,其他服务不关心登录,因为都在 ZK 中维护了。这里跟分布式 Session 很像。
二、搭建 Zookeeper 服务器
因为 ZK 使用 java 编写的,所以需要保证服务器已经有了 java。
1、安装 Zookeeper
然后去 ZK 的官网,找到发行的版本,下载压缩包,这里博主用的版本是 3.7.1,然后在服务器自己找个路径解压。
接着进到 bin 目录下。
在 bin 目录下可以启动 ZK,但是启动需要 ZK 的配置文件,目前还没有配置。
2、Zoo.cfg 配置文件说明
接着进到 conf 目录下:

Zoo.cfg 配置文件说明:

接着开始配置配置文件(这里可以修改下数据存储目录):
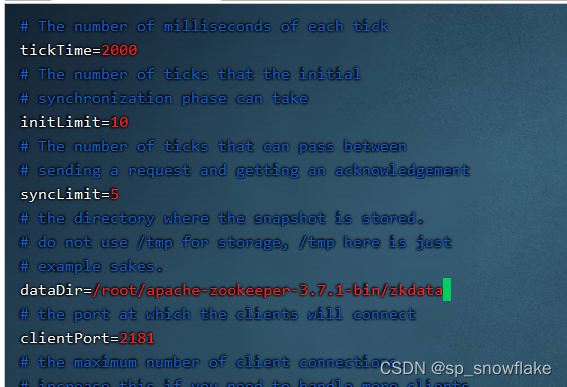
这样一个单节点的 zk 就配置好了。
然后把配置文件模板重命名为 zoo.cfg:

3、启动 ZK
接着就可以启动 zk:

如果后面不写配置文件的路径,zk也会找到那个配置文件,但是如果要配置集群,就需要写。这里演示写配置文件的路径:

下面这种就是启动成功:

4、ZK 的服务器操作命令
重命名conf中的文件zoo_sample.cfg->zoo.cfg
启动zk服务器:
./bin/zkServer.sh start ../conf/zoo.cfg
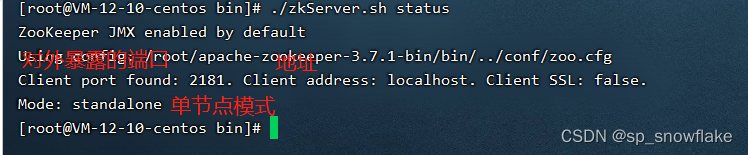
查看zk服务器的状态:
./bin/zkServer.sh status ../conf/zoo.cfg
停止服务器:
./bin/zkServer.sh stop ../conf/zoo.cfgs
5、与 zk 交互
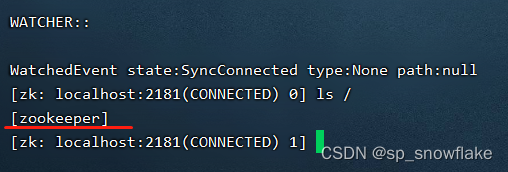
启动这个工具,然后输入 ls / 可以查看 zk 的数据结构:
三、Zookeeper 内部的数据模型
1、zk 如何保存数据的
zk中的数据是保存在节点上的,节点就是znode,多个znode之间构成一棵树的目录结构。
Zookeeper的数据模型是什么样子呢?类似于数据结构中的树,同时也很像文件系统的目录:
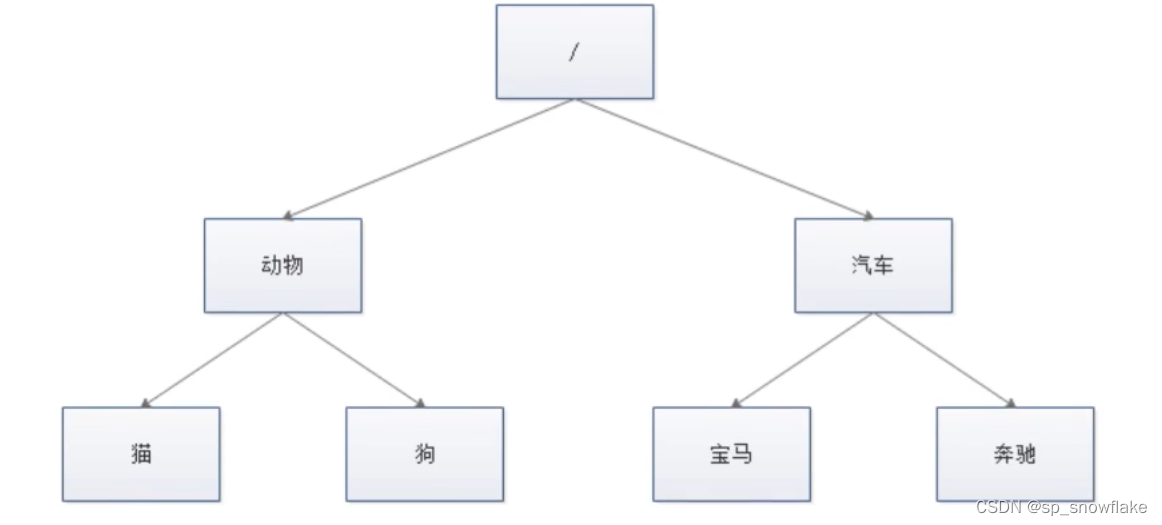
树是由节点所组成,Zookeeper的数据存储也同样是基于节点,这种节点叫做Znode。
但是不同于树的节点,Znode的引用方式是路劲引用,类似于文件路径。

这样的层级结构,让每一个Znode的节点拥有唯一的路径,就像命名空间一样对不同信息做出清晰的隔离。
2、zk中的 znode 是什么样的数据结构
zk中的 znode 包含了以下四个部分:
data:保存数据
acl:权限(定义了什么样的用户能够操作这个节点,且能够进行怎样的操作):
c:create 创建权限,允许在该节点下创建子节点
w:write 更新权限,允许更新该节点的数据
r:read 读取权限,允许读取该节点的内容以及子节点的列表信息
d:delete 删除权限,允许删除该节点的子节点信息
a:admin 管理者权限,允许对该节点进行acl权限设置
stat:描述当前znode的元数据
child:当前节点的子节点
3、zk 中节点的 znode 的类型
1、持久节点:创建出的节点,在会话结束后依然存在。保存数据。(默认创建的节点就是持久节点)
2、持久序号节点:创建出的节点,根据先后顺序,会在节点之后带上一个数值,越后执行数值越大,适用于分布式锁的应用场景-单调递增。
3、临时节点:临时节点是在会话结束后,自动被删除的。通过这个特性,zk可以实现服务注册与发现的效果。
那么临时节点是如何维持心跳的呢?
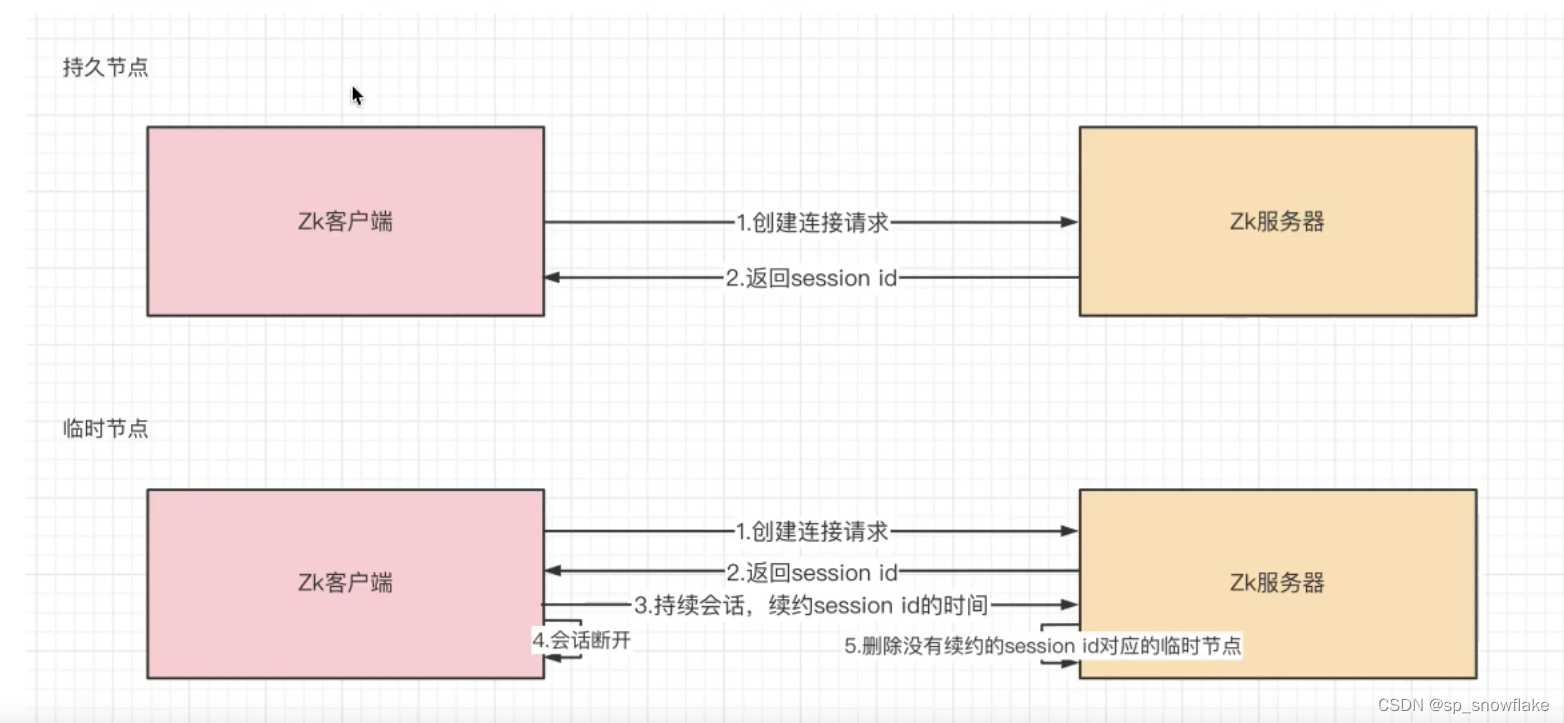
持续发送,隔多长时间发送是内部有个算法计算的。在 zk 服务器中会有一个任务不断执行,隔一段时间就执行,这个任务会去查看是否没有续约的会话 id,找到这些 id 就会全部删掉。
4、临时序号节点:跟持久序号节点相同,适用于临时的分布式锁。
5、Container节点(3.5.3版本新增):Container容器节点,当容器中没有任何子节点,该容器节点会被zk定期删除。
6、TTL节点:可以指定节点的到期时间,到期后被zk定时删除。只能通过系统配置zookeeper.extendedTypeEnablee=true开启。
a、create -s /xxx —— 创建持久序号节点
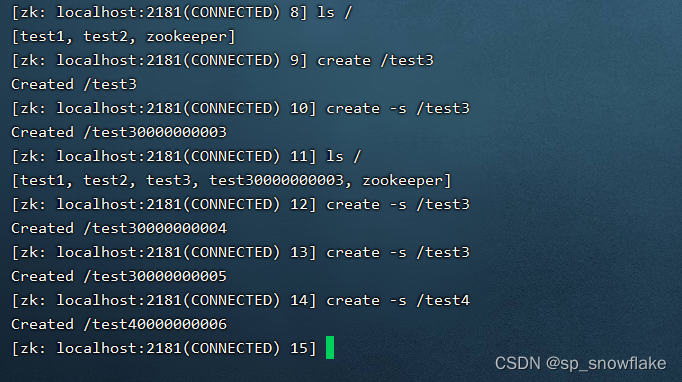
上图中是创建持久序号节点的示意图。可以看到这么创建以后,会有很长的 0 后面接着序号,这个序号是跟事务的次序有关系。
b、create -e /xxx —— 创建临时节点
c、create -e -s /xxx —— 创建临时序号节点
4、zk 的数据持久化
k的数据是运行在内存中,zk提供了两种持久化机制:
-
事务日志
zk把执行的命令以日志形式保存在dataLogDir指定的路径中的文件中(如果没有指定dataLogDir,则按照 dataDir指定的路径)。
-
数据快照
zk会在一定的时间间隔内做一次内存数据快照,把时刻的内存数据保存在快照文件中。
zk通过两种形式的持久化,在恢复时先恢复快照文件中的数据到内存中,再用日志文件中的数据做增量恢复,这样恢复的速度更快。
可以发现这种持久化机制很像 redis 的机制,因为 zk 是这一块的鼻祖,里面很多优秀的设计跟机制都被很多中间件拿来借鉴跟参考。
四、Zookeeper客户端(zkCli)的使用
1、节点与数据的操作
a、create /xxx ——创建 znode 节点

这时候再来查看节点:

b、create /xxx xx—— 存储数据

c、get /xxx 取数据

d、get -s /xxx —— 查看节点的详细信息
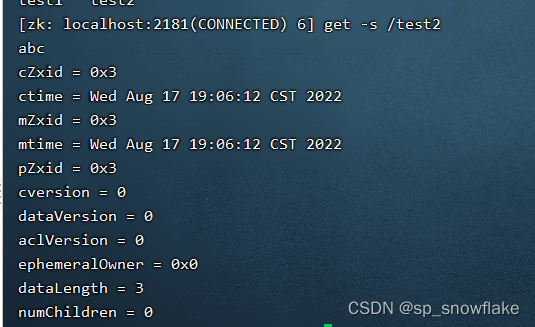
上面这些都属于节点的元数据!
节点的详细信息解释:

e、ls -R /xxx ——查询该节点下的所有子节点
这里的 -R 是递归查询
f、delete /xxx —— 删除空节点
g、deleteall /xxx —— 删除节点
h、delete -v [数据版本号] /xxx —— 乐观锁删除
2、权限操作
a、create /xxx [数据] auth:用户名:密码:权限 —— 创建一个节点并设置权限
例子:

当权限不够的账号访问该节点时的信息:

b、addauth digest 用户名:密码 —— 注册当前会话的账号和密码
五、 Curator 客户端的使用
前面都是在服务器上敲命令,那么有没有第三方工具通过 java 来操作呢?当然是有的,就是 Curator
1、Curator 介绍
Curator是Netflix公司开源的一套zookeeper客户端框架,Curator是对Zookeeper支持最好的客户端框架。Curator封装了大部分Zookeeper的功能,比如Leader选举、分布式锁等,减少了技术人员在使用Zookeeper时的底层细节开发工作。
2、引入依赖
<!--Curator-->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.12.0</version>
</dependency>
<!--Zookeeper-->
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.7.1</version>
</dependency>
配置文件:
配置curator基本连接信息
# 重试次数
curator.retryCount=5
curator.elapsedTimeMs=5000
# 集群/单机 链接地址
curator.connectString=IP:2181
# 会话超时时间
curator.sessionTimeoutMs=60000
# 链接超时时间
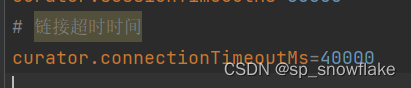
curator.connectionTimeoutMs=4000
3、代码配置
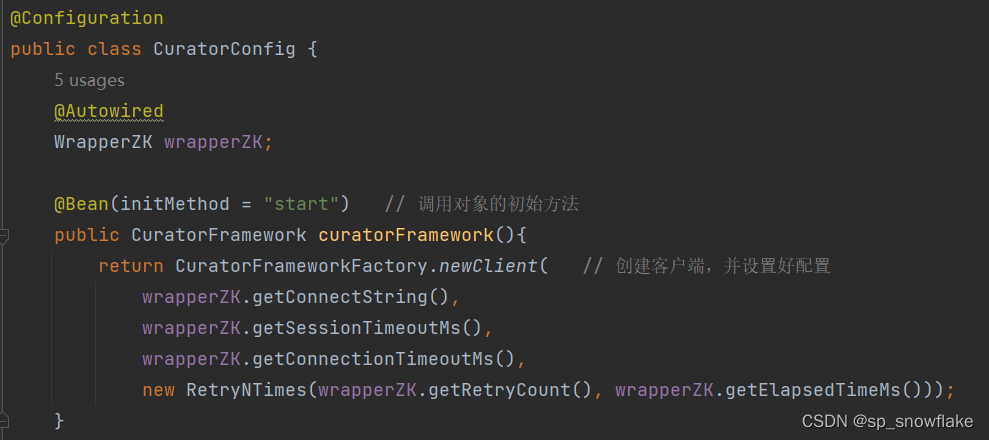
a、注入参数
先把配置文件里面的参数注入进来:
然后初始化:
4、java 代码操作 ZK
a、添加持久节点 / 临时序号节点
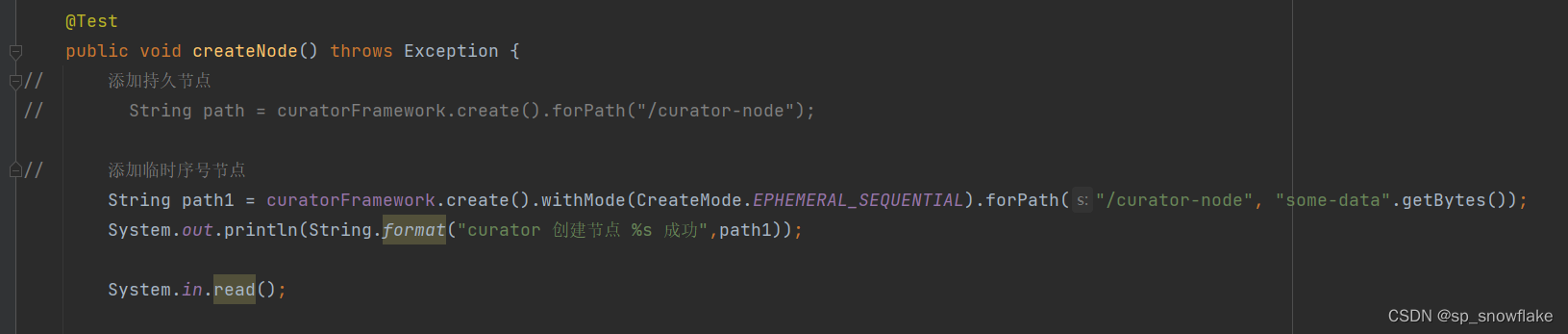
结果:

如果有报以下这个错误:

是因为链接时间设置的太短,设置长一点:
b、获取节点数据
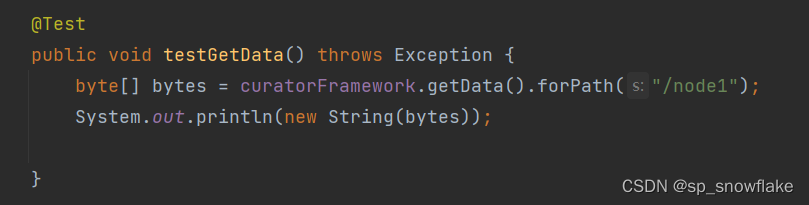
因为这个节点没有数据,所以返回的是 IP:

c、给节点设置值
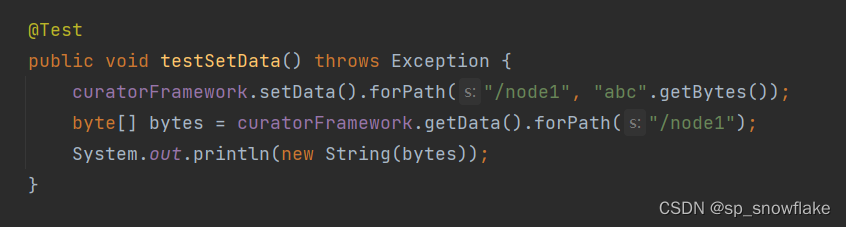
结果:
d、创建子节点,如果该子节点的父节点不存在,把父节点也一并创建

e、删除节点,如果有需要一并把子节点也删除
















 977
977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









