










Using Torch Models with GPUs and TPUs
Use CPU
默认情况下,所有模型将运行在CPU上。如上面的RNN示例所示,我们将导入Air Passenger数据集以及其他必要的模块。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from darts.dataprocessing.transformers import Scaler
from darts.models import RNNModel
from darts.metrics import mape
from darts.datasets import AirPassengersDataset
现在我们像这样读取和缩放数据:
# Read data:
series = AirPassengersDataset().load()
series = series.astype(np.float32)
# Create training and validation sets:
train, val = series.split_after(pd.Timestamp("19590101"))
# Normalize the time series (note: we avoid fitting the transformer on the validation set)
transformer = Scaler()
train_transformed = transformer.fit_transform(train)
val_transformed = transformer.transform(val)
series_transformed = transformer.transform(series)
接下来,我们将像这样创建我们的RNN:
my_model = RNNModel(
model="RNN",
hidden_dim=20,
dropout=0,
batch_size=16,
n_epochs=300,
optimizer_kwargs={"lr": 1e-3},
model_name="Air_RNN",
log_tensorboard=True,
random_state=42,
training_length=20,
input_chunk_length=14,
force_reset=True,
)
并将其与数据fit:
my_model.fit(train_transformed, val_series=val_transformed)
在输出中,我们可以看到没有其他处理单元用于训练我们的模型:
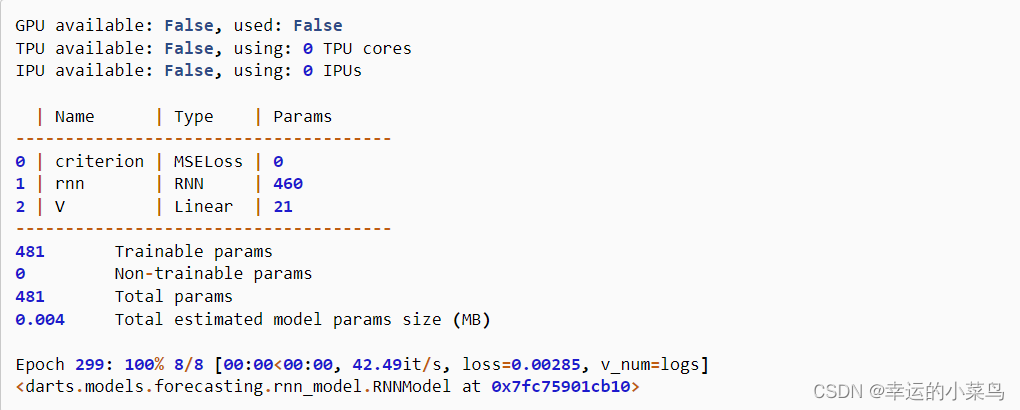
现在这个模型已经准备好开始预测了,这里就不展示了,因为它包含在本指南开头链接的示例中。
Use a GPU
就处理时间而言,gpu可以显著提高模型的性能。通过在Pytorch闪电训练器中使用加速器,我们可以享受GPU的好处。我们只需要通过PyTorch Lightning Trainer参数来指示我们的模型使用我们机器的GPU,这些参数表示为pl_trainer_kwargs字典,如下所示:
my_model = RNNModel(
model="RNN",
...
force_reset=True,
pl_trainer_kwargs={
"accelerator": "gpu",
"gpus": [0]
},
)
现在输出:
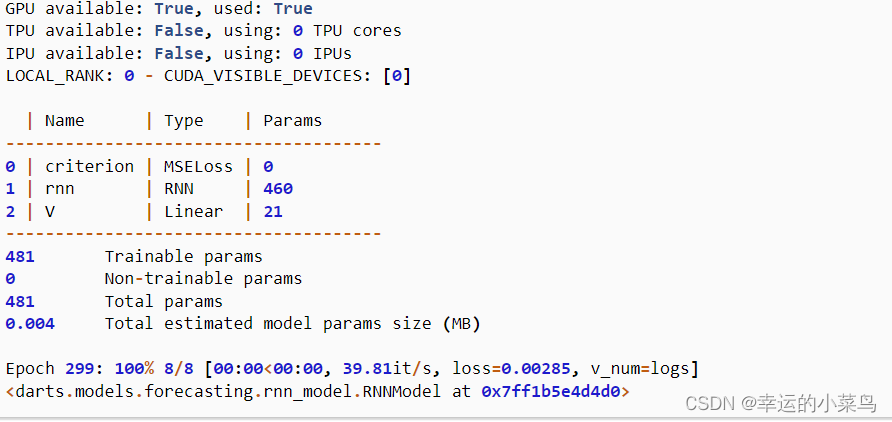
从输出中我们可以看到GPU是可用的和使用的。剩下的代码不需要任何修改,也就是说,如果我们使用的是GPU或CPU,它就无关紧要了
Use a TPU
张量处理单元(Tensor Processing Unit, TPU)是谷歌公司专门为神经网络机器学习开发的AI加速器专用集成电路(ASIC).
有三种主要的访问TPU的方法:
- Google Colab
- Google Cloud (GCP)
- Kaggle
如果你使用TPU在谷歌Colab类型的笔记本,那么你应该首先安装这些:
!pip install cloud-tpu-client==0.10 https://storage.googleapis.com/tpu-pytorch/wheels/torch_xla-1.9-cp37-cp37m-linux_x86_64.whl
!pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchtext==0.10.0 -f https://download.pytorch.org/whl/cu111/torch_stable.html
!pip install pyyaml==5.4.1
然后指示我们的模型使用TPU或更多。在我们的例子中,我们使用了四个tpu,就像这样:
my_model = RNNModel(
model="RNN",
...
force_reset=True,
pl_trainer_kwargs={
"accelerator": "tpu",
"tpu_cores": [4]
},
)
输出:
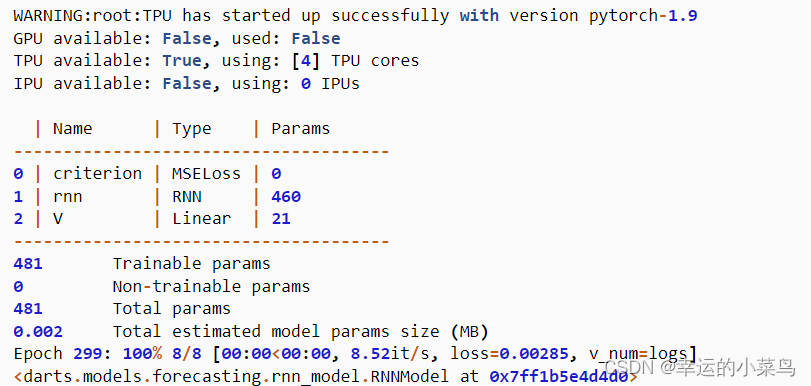
协变量
总结-TL;DR
在dart中,协变量指的是可以作为模型输入的外部数据,以帮助改善预测。在预测模型的背景下,目标是要预测/预测的序列,协变量本身不被预测。我们区分了三种协变量:
- past covariates:(根据定义)只有过去才知道的协变量(例如测量值)
- future covariates:是(根据定义)未来已知的协变量(例如,天气预报)
- static covariates:根据定义)是随时间不变的协变量。他们还没有支持的Darts,但我们正在努力!
dart中的模型在其fit()和predict()方法中接受past_covariates和/或future_covariates,这取决于它们的能力(有些模型根本不接受协变量)。目标和协变量都必须是TimeSeries对象。如果使用了不受支持的协变量,模型将产生错误。
# create one of Darts' forecasting models
model = SomeForecastingModel(...)
# fitting model with past and future covariates
model.fit(target=target,
past_covariates=past_covariates_train,
future_covariates=future_covariates_train)
# predict the next n=12 steps
model.predict(n=12,
series=target, # only required for Global Forecasting Models
past_covariates=past_covariates_pred,
future_covariates=future_covariates_pred)
如果您有几个协变量,希望用作过去(或未来)协变量,则必须将它们全部堆栈()到单个past_covariates(或future_covariates)对象中。
# stack two TimeSeries with stack()
past_covariates = past_covariates.stack(other_past_covariates)
# or with concatenate()
from darts import concatenate
past_covariates = concatenate([past_covariates, other_past_covariates], axis=1)
darts的预测模型期望每个目标序列都有一个过去和/或未来的协变量序列。如果使用Darts的全球预测模型之一的多个目标系列,则必须提供相同数量的专用协变量来fit()。
# fit using multiple (two) target series
model.fit(target=[target, target_2],
past_covariates=[past_covariates, past_covariates_2],
# optional future_covariates,
)
# you must give the specific target and covariate series that you want to predict
model.predict(n=12,
series=target_2,
past_covariates=past_covariates_2,
# optional future_covariates,
)
如果使用past_协变量来训练模型,则必须在预测时为predict()提供这些past_协变量。这也适用于未来协变量,其中的细微差别是,未来协变量必须在预测时间延伸到未来足够远的地方(一直延伸到预测视界n)。这可以在下面的图表中看到。past_协变量需要包括至少与目标相同的时间步,future_协变量必须包括至少相同的时间跨度加上额外的n个预测水平时间步。
训练和预测可以使用相同的’ ’ * _协变量’ ',前提是它们包含所需的时间跨度。
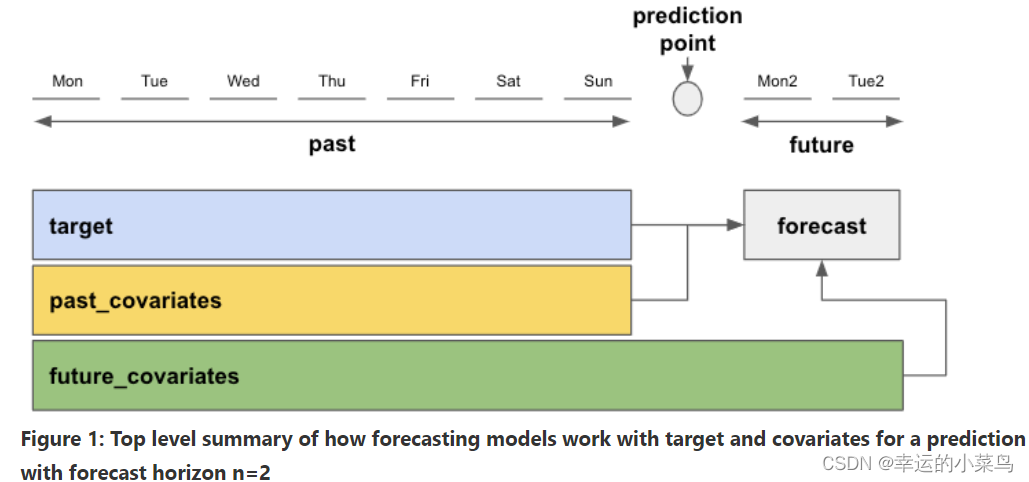
还有一些额外的细微差别需要了解。例如,Darts中的深度学习模型可以(通常)一次预测output_chunk_length点。然而,使用过去协变量训练的模型仍然有可能对某个地平线n > output_chunk_length做出预测,如果过去协变量在未来足够长的时间内都是已知的。在这种情况下,预测是通过消费过去协变量的未来值,并在目标序列上使用自回归得到的。如果你想知道更多细节,请继续阅读。
介绍–协方差是什么?
协变量提供了额外的信息/环境,这对改进目标序列的预测很有用。目标系列是我们希望预测未来的变量。我们不预测协变量本身,只使用它们来预测目标。
协变量可以包含过去(包括现在)或未来的信息。这总是相对于我们想要预测未来的预测点(时间点)。在dart中,我们将这两种类型称为past_covariates和future_covariates。dart预测模型对* _协变量有不同的支持模式。有些人根本不支持协变量,有些人支持过去或未来的协变量,有些人两者都支持。
让我们来看一些过去和未来协变量的例子:
- past_协变量:通常是测量值(过去的数据)或时间属性
日平均测量温度(只在过去已知)
星期、月、年、… - future_协变量:通常是预测(未来已知数据)或时间属性 日平均预测温度(未来已知) 星期、月、年、…
时间属性非常强大,因为它们是提前知道的,可以帮助模型捕捉目标系列的趋势和/或季节模式。
这里有一个简单的经验法则来判断你的系列是过去的还是未来的协变量:
如果值是预先知道的,它们是未来的协变量(或可以用作过去的协变量)。如果它们不是,它们**必须*是过去的协变量。
你可以想象这样的情况,你想训练一个只支持过去协变量的模型(如TCNModel,见表1)。在这种情况下,你可以使用例如,预测的温度作为模型的过去协变量,即使你也可以访问未来的温度预测。知道这样的“过去协变量的未来值”可以让您对未来进行更深入的预测(对于dart的预测范围为> output_chunk_length的深度学习模型)。类似地,大多数消耗未来协变量的模型也可以使用“未来协变量的历史值”。
附注:如果你没有未来的值(例如测量的温度),没有什么阻止你应用dart的预测模型来预测未来的温度,然后使用它作为future_协变量。dart并没有试图为您预测协变量,因为这将引入一个额外的“隐藏”建模步骤,我们认为这最好留给用户。
支持协方差的模型
dart的预测模型在其fit()和predict()方法中接受可选的past_协变量和/或future_协变量,这取决于它们的能力。表1显示了每个模型支持的协变量类型。如果使用了不受支持的协变量,模型将产生错误。
本地预测模型(LFMs)
lfm是只能在单一目标系列上训练的模型。在dart中,这一类的大多数模型往往是更简单的统计模型(如ETS或ARIMA)。lfm只接受单个目标(和协变量)时间序列,通常在一次调用fit()时使用您提供的整个序列进行训练。在一系列训练结束后,他们还可以一次预测任何次数的预测。
全局预测模型(GFMs)
广义上讲,GFMs是“基于机器学习”的模型,它表示基于pytorch(深度学习)的模型以及回归模型。全局模型都可以在多目标(和协变量)时间序列上训练。与LFMs不同的是,GFMs对输入数据的固定长度子样本(块)进行训练和预测。
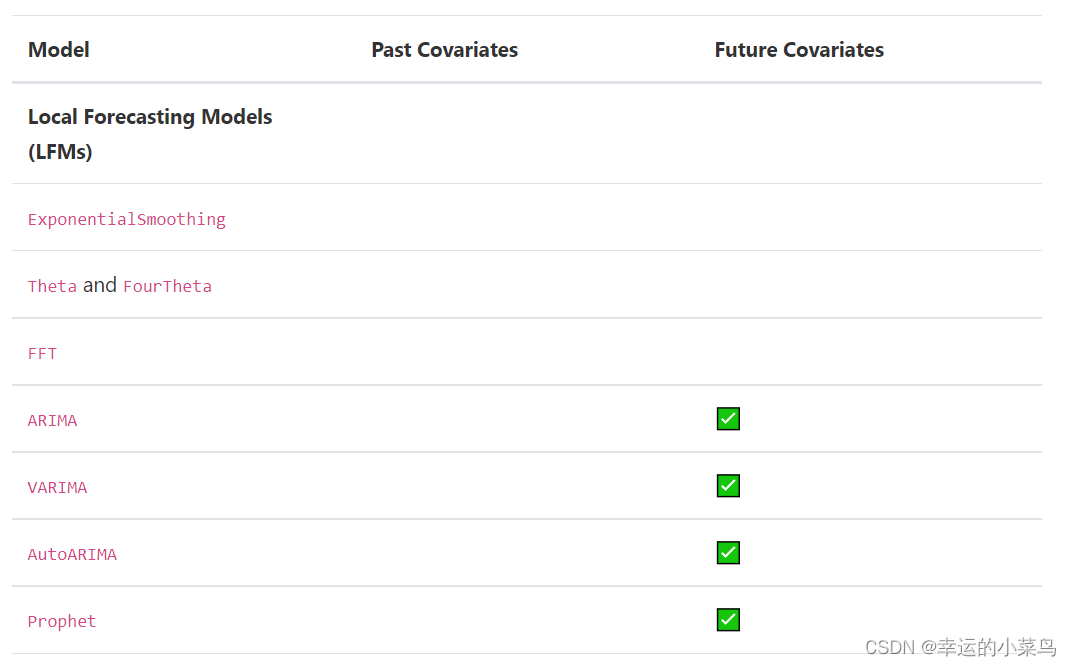
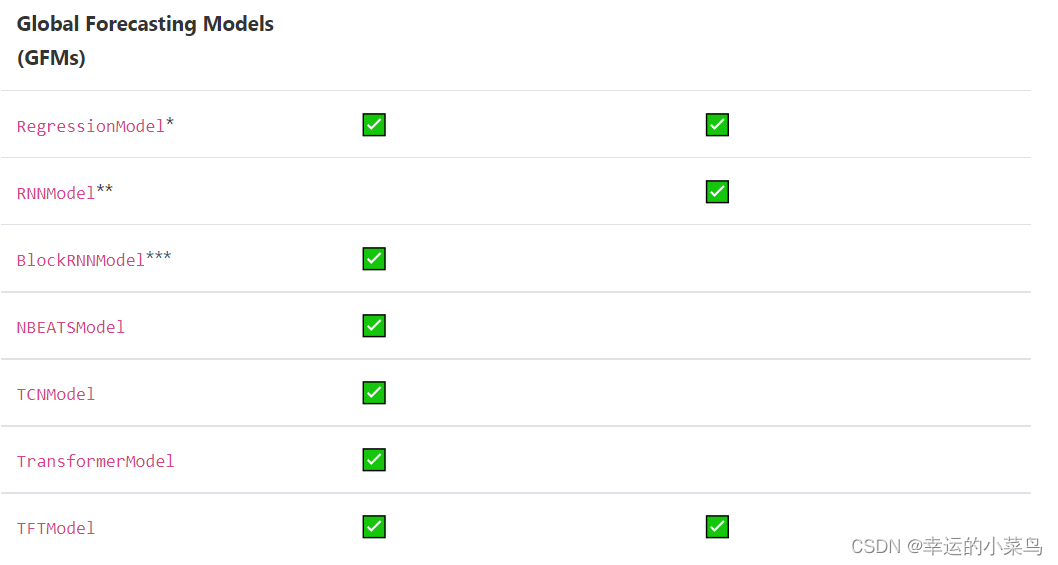
*回归模型包括随机森林,线性回归模型和LightGBMModel。回归模型是一种特殊的GFM,它可以使用协变量(过去和/或未来)和过去目标的任意滞后来进行预测。
**包含LSTM和GRU的RNNModel;相当于DeepAR的概率版本
*** BlockRNNModel包括LSTM和GRU
快速指南如何使用协变量与dart的预测模型
使用协变量与dart的预测模型是非常简单的。他们只是需要满足一些要求。
就像目标系列一样,过去和/或未来的每一个协变量系列都必须是TimeSeries对象。当您使用过去和/或未来协变量使用fit()训练模型时,您必须提供与predict()相同类型的协变量。根据模型的选择和预测地平线n的长度,对协变量可能有不同的时间跨度要求。您可以在下一小节中找到这些需求。
*如果它们包含所需的时间跨度,您甚至可以使用相同的’ ’ _covariates ’ '来拟合和预测。这是因为dart将基于目标时间轴为你“智能”地分割它们。
# create one of Darts' forecasting model
model = SomeForecastingModel(...)
# fit the model
model.fit(target,
past_covariates=past_covariate,
future_covariates=future_covariates)
# make a prediction with the same covariate types
pred = model.predict(n=1,
series=target, # this is only required for GFMs
past_covariates=past_covariates,
future_covariates=future_covariates)
要使用多个过去和/或未来的协变量与你的目标,你必须将它们全部堆叠到一个单独的TimeSeries:
# stack() time series
past_covariates = past_covariates.stack(past_covariates2)
# or concatenate()
from darts import concatenate
past_covariates = concatenate([past_covariates, past_covariates2, ...], axis=1)
GFMs可以在多个目标序列上训练。您必须为fit()使用的每个目标TimeSeries提供一个协变量TimeSeries。在预测时,你必须指定你想要预测的目标系列,并提供相应的协变量:
from darts.models import NBEATSModel
# multiple time series
all_targets = [target1, target2, ...]
all_past_covariates = [past_covariates1, past_covariates2, ...]
# create a GFM model, train and predict
model = NBEATSModel(input_chunk_length=1, output_chunk_length=1)
model.fit(all_targets,
past_covariates=all_past_covarites)
pred = model.predict(n=1,
series=all_targets[0],
past_covariates=all_past_covariates[0])
局部和全局预测模型的协变量时间跨度要求
dart的“本地”和“全球”预测模型如何进行训练和预测存在差异。具体来说,它们如何提取/使用fit()和predict()期间提供的数据。
根据你使用的模型和你的预测视界n的长度,对你的协变量可能有不同的时间跨度要求。
本地预测模型(LFMs)
lfm通常在一次调用fit()时提供的整个目标和future_covariates系列(如果支持)上进行训练。它们还可以对目标结束后的预测视界n进行一次预测。
对’ ’ fit() ’ ‘和’ ’ predict() ’ '使用相同的未来协变量序列的时间跨度要求:
- future_协变量:至少与目标相同的时间跨度加上目标结束后的下一个n个时间步
全局预测模型(GFMs)
GFMs在目标和* _协变量系列(如果支持)的固定长度块(子样本)上训练和预测。每个块包含一个输入块(代表样本的过去)和一个输出块(代表样本的未来)。这些块的长度必须在模型创建时用参数input_chunk_length和output_chunk_length指定(一个显著的例外是RNNModel,它总是使用output_chunk_length为1)。
根据你的预测地平线n,该模型可以一次性预测,也可以通过预测未来的多个区块进行自动回归。这就是为什么用past_协变量进行预测时,你必须提供额外的“你的past_协变量的未来值”的原因。
对’ ’ fit() ’ ‘和’ ’ predict() ’ '使用相同的过去和/或未来协变量序列的时间跨度要求:
- with n <= output_chunk_length:
- past_covariates: at least the same time span as target
- future_协变量:至少与目标相同的时间跨度加上目标结束后的下一个output_chunk_length时间步长
- with n > output_chunk_length:
- past_协变量:至少与目标相同的时间跨度加上目标结束后的下一个n - output_chunk_length时间步
- future_协变量:至少与目标相同的时间跨度加上目标结束后的下一个n个时间步
如果你想知道更多关于在全球预测模型中如何在幕后使用协变量的细节,请阅读我们的火炬预测模型指南(基于PyTorch的GFMs)。它给出了一个循序渐进的解释训练和预测过程中使用我们的火炬预测模型之一。
例子
- Past covariates with GFMs
- Past and future covariates with TFTModel
- Past and future covariates with RegressionModels
常见问题
- Darts只是对其他库的包装吗?
- 不。当它有意义时,我们重用现有的实现(例如,从统计预测),但我们经常编写我们自己的实现(例如,神经网络)。此外,dart模型通常比原来的模型拥有更多的功能。例如,与原始版本不同,我们的N-BEATS实现支持多元时间序列、过去的协变量和概率预测。
- dart看起来是个很棒的项目,我能贡献点什么吗?
- 绝对的!我们一直欢迎来自社区的贡献。如果你做出了贡献,你将会在名人墙(也就是更新日志)中得到认可!贡献不只是代码,也可以是文档。此外,我们也很乐意在Github上以问题的形式收到建议。贡献者最好从贡献指南开始。
- 我有一些想法,为dart贡献一个新的模型,这是可能的吗?
- 的来说,是的,我们确实欢迎新模型的参考实现。然而,我们正在松散地过滤,以保持那些经典的模型,或令人信服地显示(例如,在一篇论文或其他形式的证据中)在某些方面是最先进的。
- 如何让dart在谷歌Colab上工作?
- Colab可能对最近版本的pyyaml有问题。在安装dart之前安装pyyaml 5.4.1可以解决这些问题:
!pip install pyyaml==5.4.1
- 我的预测中出现了一些nan,我该怎么办?
通常这意味着两种情况之一:
- 在训练数据中有一些nan(目标或协变量)。这是最常见的情况,它将导致大多数模型总是预测nan。
- 训练模型会导致一些数值发散。如果您使用的是神经网络,请确保您的数据得到了适当的扩展,如果问题仍然存在,请尝试降低学习率。
- 我的预测模型给出了不好的结果,你能帮忙吗?
- 获得好的预测不仅仅是调用fit()/predict()函数,还涉及到一些数据科学工作,以理解哪些方法是合适的。我们不能给出一般的答案,但是如果你有重要的预测问题或需要帮助使你的预测产业化,Unit8提供技术咨询。欢迎随时与我们联系。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









